Tensorflow系列专题(四):神经网络篇之前馈神经网络综述
目录:
- 神经网络前言
- 神经网络
- 感知机模型
- 多层神经网络
- 激活函数
- Logistic函数
- Tanh函数
- ReLu函数
- 损失函数和输出单元
- 损失函数的选择
- 均方误差损失函数
- 交叉熵损失函数
- 输出单元的选择
- 线性单元
- Sigmoid单元
- Softmax单元
- 损失函数的选择
- 参考文献
一.神经网络前言
从本章起,我们将正式开始介绍神经网络模型,以及学习如何使用TensorFlow实现深度学习算法。人工神经网络(简称神经网络)在一定程度上受到了生物学的启发,期望通过一定的拓扑结构来模拟生物的神经系统,是一种主要的连接主义模型(人工智能三大主义:符号主义、连接主义和行为主义)。本章我们将从最简单的神经网络模型感知器模型开始介绍,首先了解一下感知器模型(单层神经网络)能够解决什么样的问题,以及它所存在的局限性。为了克服单层神经网络的局限性,我们必须拓展到多层神经网络,围绕多层神经网络我们会进一步介绍激活函数以及反向传播算法等。本章的内容是深度学习的基础,对于理解后续章节的内容非常重要。
深度学习的概念是从人工神经网络的研究中发展而来的,早期的感知器模型只能解决简单的线性分类问题,后来发现通过增加网络的层数可以解决类似于“异或问题”的线性不可分问题,这种多层的神经网络又被称为多层感知器。对于多层感知器,我们使用BP算法进行模型的训练[1],但是我们发现BP算法有着收敛速度慢,以及容易陷入局部最优等缺点,导致BP算法无法很好的训练多层感知器。另外,当时使用的激活函数也存在着梯度消失的问题,这使得人工神经网络的发展几乎陷入了停滞状态。为了让多层神经网络能够训练,学者们探索了很多的改进方案,直到2006年Hinton等人基于深度置信网络(DBN)提出了非监督贪心逐层训练算法,才让这一问题的解决有了希望,而深度学习的浪潮也由此掀起。
本章内容主要包括五个部分,第一部分我们介绍一下神经网络的基本结构,从基本的感知器模型到多层的神经网络结构;第二部分介绍神经网络中常用的激活函数;第三部分介绍损失函数和输出单元的选择;第四部分介绍神经网络模型中的一个重要的基础知识——反向传播算法;最后我们使用TensorFlow搭建一个简单的多层神经网络,实现mnist手写数字的识别。
二.神经网络
- 感知机模型
感知器(Perceptron)是一种最简单的人工神经网络,也可以称之为单层神经网络,如图1所示。感知器是由Frank Rosenblatt在1957年提出来的,它的结构很简单,输入是一个实数值的向量,输出只有两个值:1或-1,是一种两类线性分类模型。
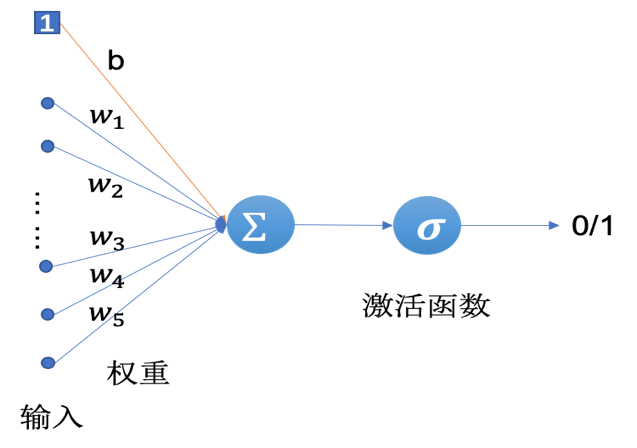
图1 感知器模型
如图3-1所示,感知器对于输入的向量先进行了一个加权求和的操作,得到一个中间值,假设该值为,则有:
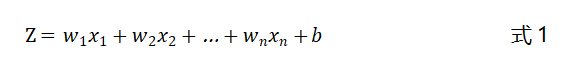
接着再经过一个激活函数得到最终的输出,该激活函数是一个符号函数:
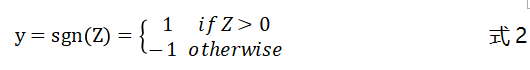
公式1中的可以看做是一个阈值(我们通常称之为偏置项),当输入向量的加权和大于该阈值时(两者之和)感知器的输出为1,否则输出为-1。
2.多层神经网络
感知器只能解决线性可分的问题,以逻辑运算为例:
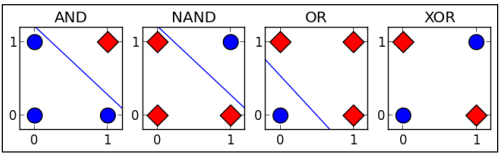
图2 逻辑运算
感知器可以解决逻辑“与”和逻辑“或”的问题,但是无法解决“异或”问题,因为“异或”运算的结果无法使用一条直线来划分。为了解决线性不可分的问题,我们需要引入多层神经网络,理论上,多层神经网络可以拟合任意的函数(本书配套的GitHub项目中有相关资料供参考)。
与单层神经网络相比,多层神经网络除了有输入层和输出层以外,还至少需要有一个隐藏层,如图3所示是含有一个隐藏层的两层神经网络:
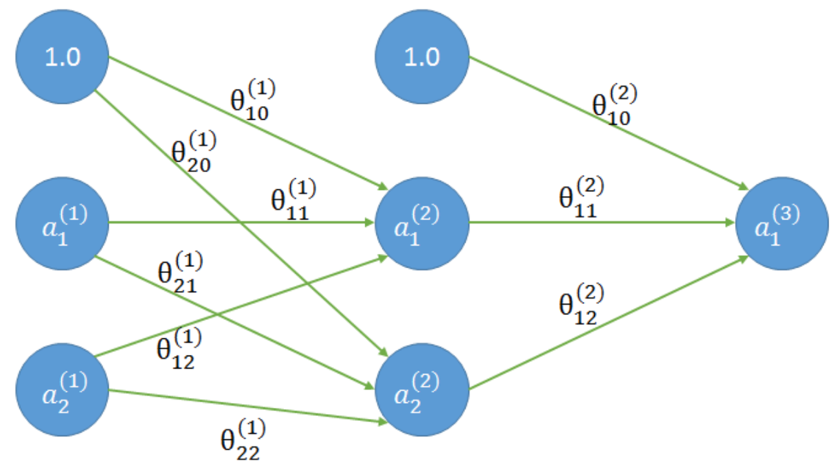
图3 两层神经网络
为了更直观的比较一下单层神经网络和多层神经网络的差别,我们利用TensorFlow PlayGround来演示两个例子。TensorFlow PlayGround是Google推出的一个深度学习的可视化的演示平台:http://playground.tensorflow.org/。
我们首先看一个线性可分的例子,如图4所示。图的右侧是数据可视化后的效果,数据是能够用一条直线划分的。从图中可以看到,我们使用了一个单层神经网络,输入层有两个神经元,输出层只有一个神经元,并且使用了线性函数作为激活函数。
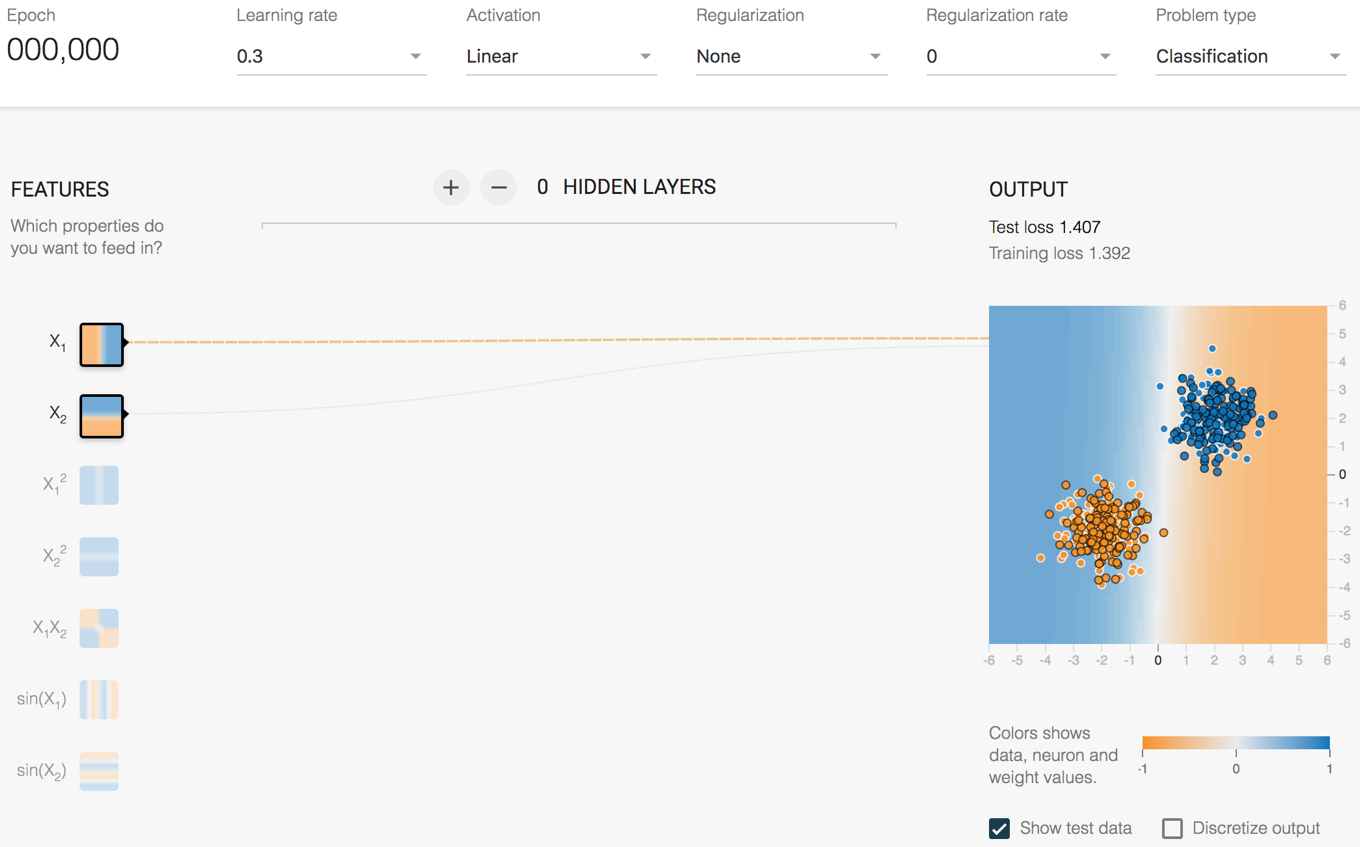
图4 TensorFlow PlayGround示例:线性可分的数据
我们点击开始训练的按钮,最终的分类结果如图5所示:
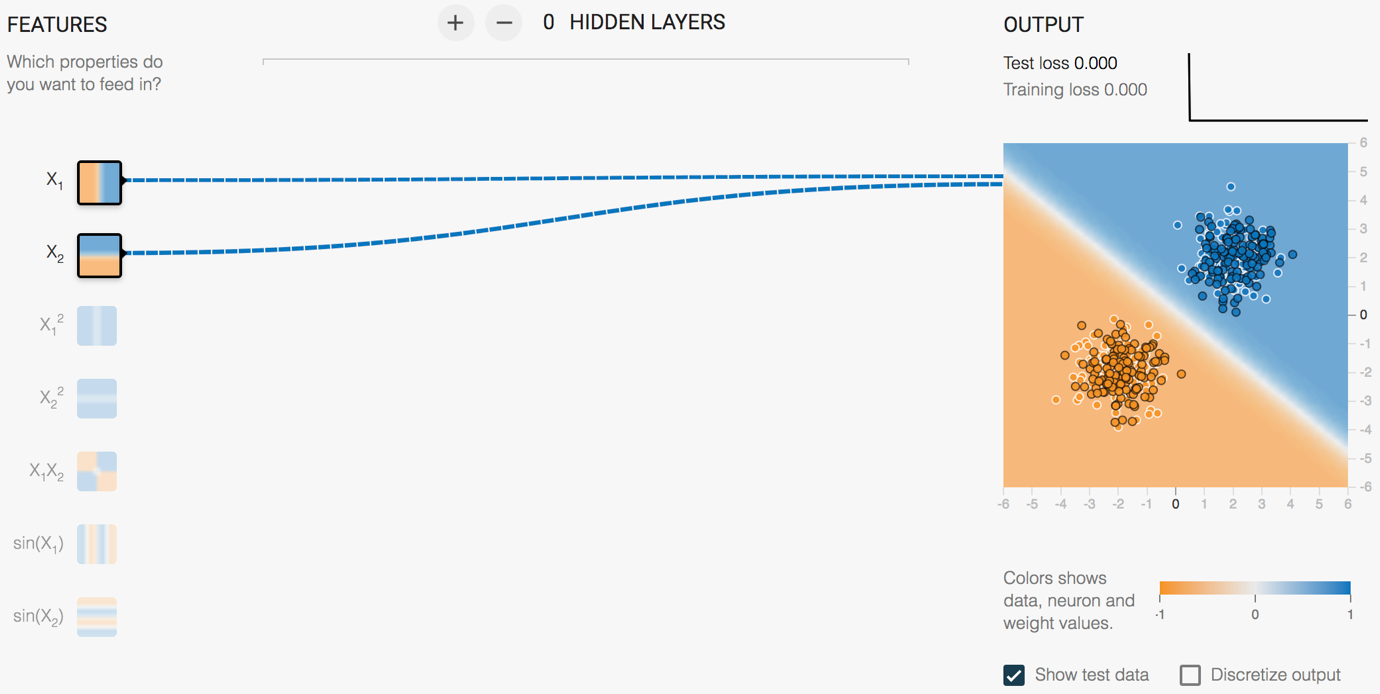
图5 TensorFlow playground示例:线性可分的数据
在上面的例子里我们使用单层神经网络解决了一个线性可分的二分类问题,接下来我们再看一个线性不可分的例子,如图6所示:
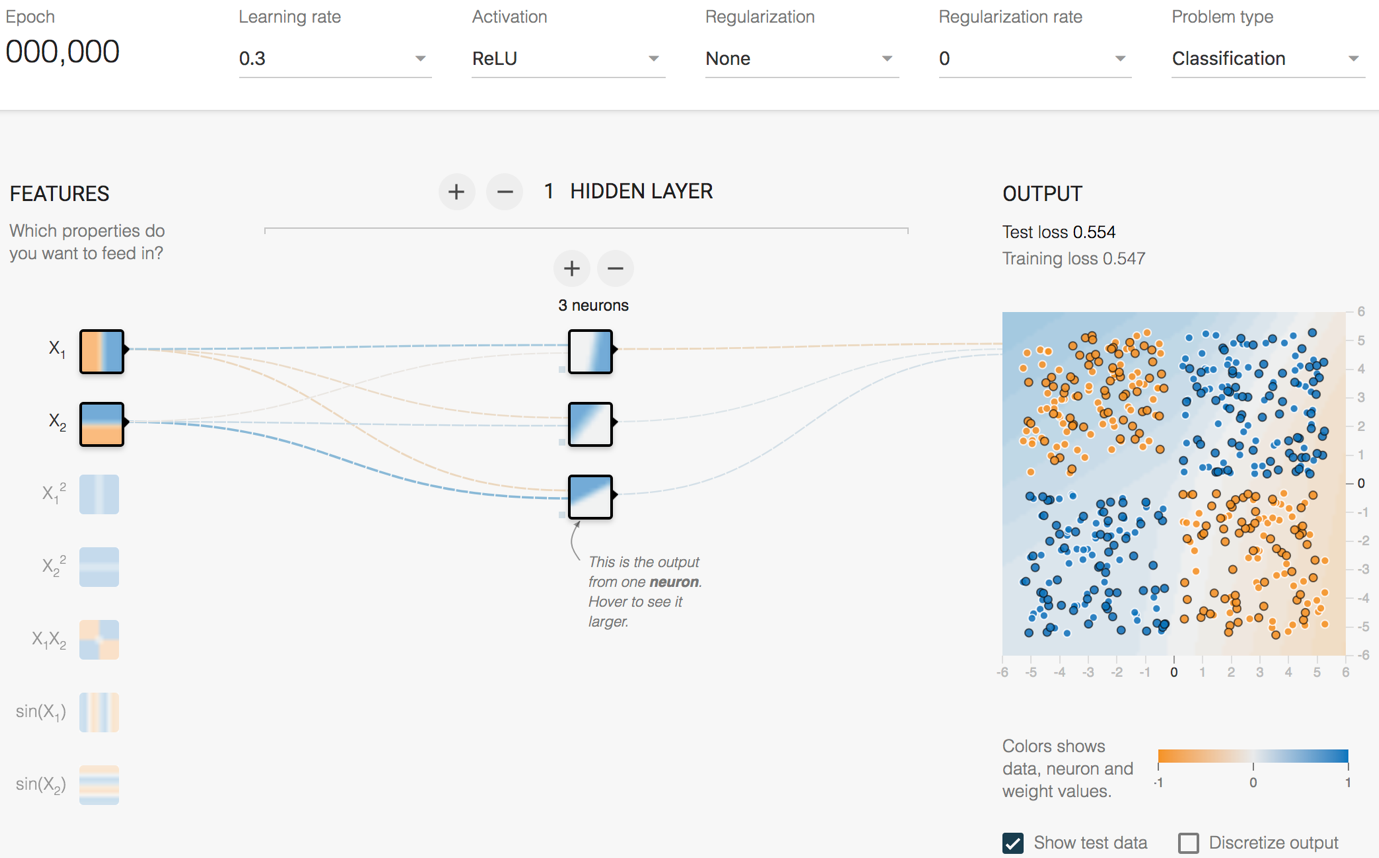
图6 TensorFlow playground示例:线性不可分的数据
在这个例子里,我们使用了一组线性不可分的数据。为了对这组数据进行分类,我们使用了一个含有一层隐藏层的神经网络,隐藏层有四个神经元,并且使用了一个非线性的激活函数ReLU。要想对线性不可分的数据进行分类,我们必须引入非线性的因素,即非线性的激活函数,在下一小节里,我们会再介绍一些常用的激活函数。
最终的分类结果如图7所示。
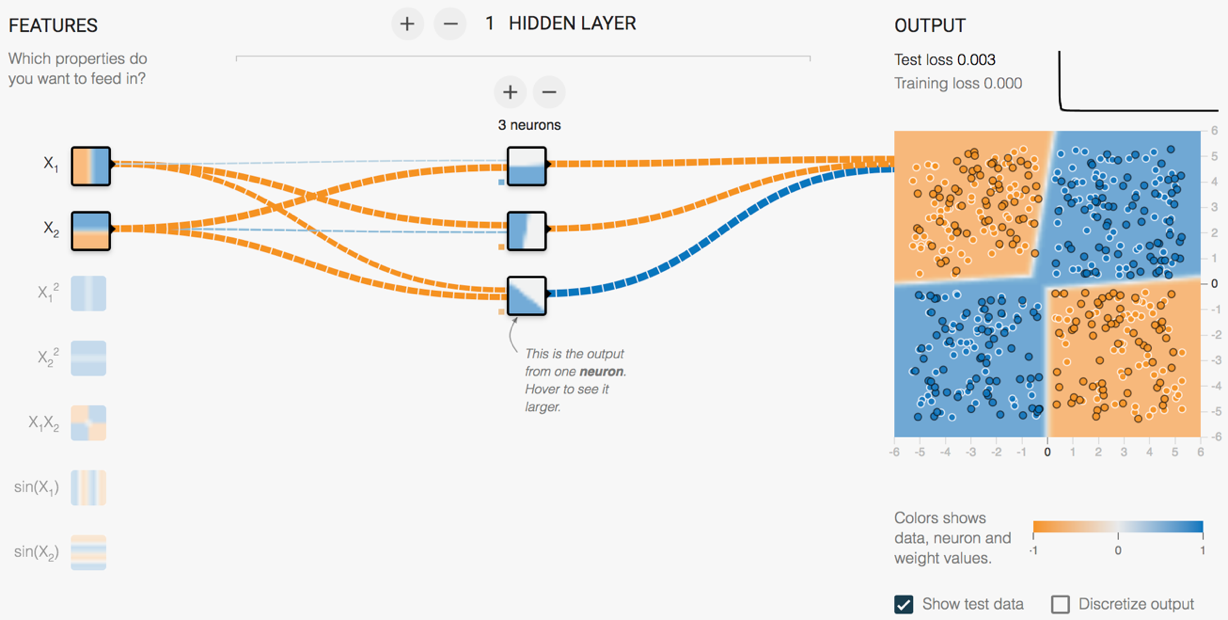
图7 TensorFlow playground示例:线性不可分的数据
感兴趣的读者可以尝试使用线性的激活函数,看会是什么样的效果,还可以尝试其它的数据,试着增加网络的层数和神经元的个数,看看分别对模型的效果会产生什么样的影响。
三.激活函数
为了解决非线性的分类或回归问题,我们的激活函数必须是非线性的函数,另外我们使用基于梯度的方式来训练模型,因此激活函数也必须是连续可导的。
- Logistic函数
Logistic函数(又称为sigmoid函数)的数学表达式和函数图像如图8所示:
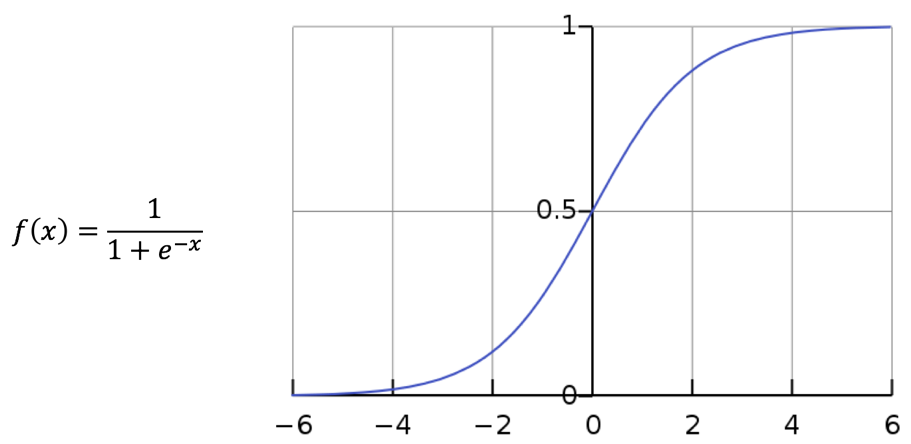
图8 Logistic函数表达式及函数图像
Logistic函数在定义域上单调递增,值域为,越靠近两端,函数值的变化越平缓。因为Logistic函数简单易用,以前的神经网络经常使用它作为激活函数,但是由于Logistic函数存在一些缺点,使得现在的神经网络已经很少使用它作为激活函数了。它的缺点之一是容易饱和,从函数图像可以看到,Logistic函数只在坐标原点附近有很明显的梯度变化,其两端的函数变化非常平缓,这会导致我们在使用反向传播算法更新参数的时候出现梯度消失的问题,并且随着网络层数的增加问题会越严重。
- Tanh函数
Tanh函数(双曲正切激活函数)的数学表达式和函数图像如图9所示:
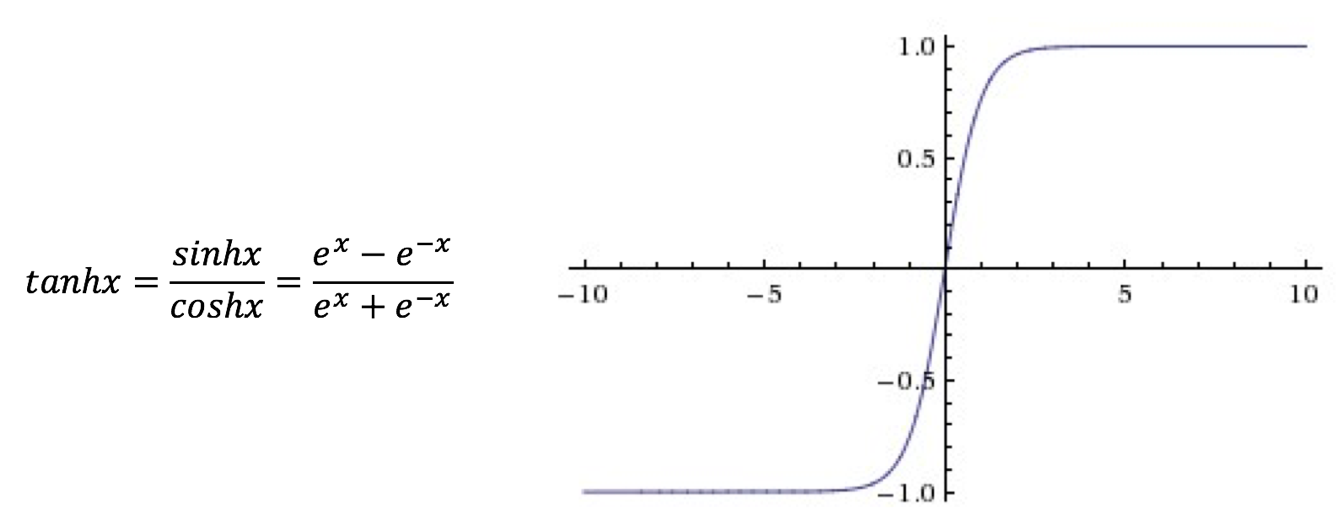
图9 Tanh函数表达式及函数图像
Tanh函数很像是Logistic函数的放大版,其值域为。在实际的使用中,Tanh函数要优于Logistic函数,但是Tanh函数也同样面临着在其大部分定义域内都饱和的问题。
- ReLu函数
ReLU函数(又称修正线性单元或整流线性单元)是目前最受欢迎,也是使用最多的激活函数,其数学表达式和函数图像如图10所示:
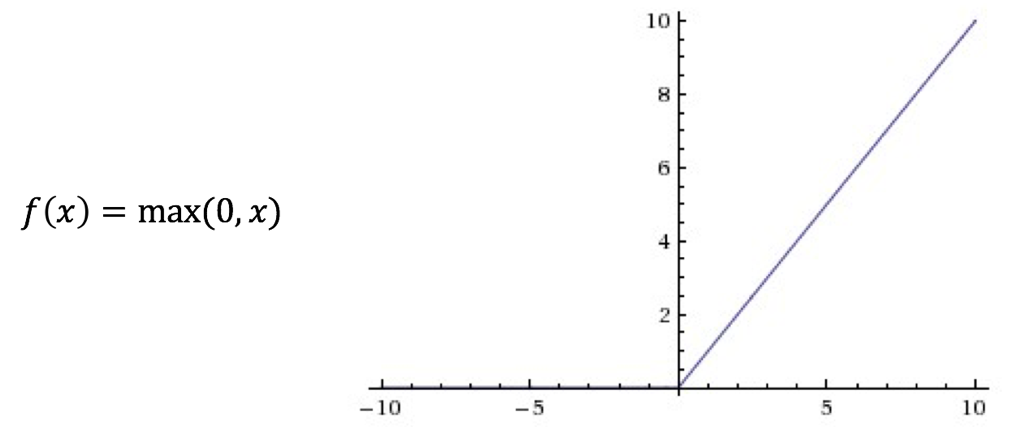
图10 ReLU函数表达式及函数图像
ReLU激活函数的收敛速度相较于Logistic函数和Tanh函数要快很多,ReLU函数在轴左侧的值恒为零,这使得网络具有一定的稀疏性,从而减小参数之间的依存关系,缓解过拟合的问题,并且ReLU函数在轴右侧的部分导数是一个常数值1,因此其不存在梯度消失的问题。但是ReLU函数也有一些缺点,例如ReLU的强制稀疏处理虽然可以缓解过拟合问题,但是也可能产生特征屏蔽过多,导致模型无法学习到有效特征的问题。
除了上面介绍的三种激活函数以外,还有很多其它的激活函数,包括一些对ReLU激活函数的改进版本等,但在实际的使用中,目前依然是ReLU激活函数的效果更好。现阶段激活函数也是一个很活跃的研究方向,感兴趣的读者可以去查询更多的资料,包括本书GitHub项目中给出的一些参考资料等。
四.损失函数和输出单元
损失函数(Loss Function)又称为代价函数(Cost Function),它是神经网络设计中的一个重要部分。损失函数用来表征模型的预测值与真实类标之间的误差,深度学习模型的训练就是使用基于梯度的方法最小化损失函数的过程。损失函数的选择与输出单元的选择也有着密切的关系。
- 损失函数的选择
1.1 均方误差损失函数
均方误差(Mean Squared Error,MSE)是一个较为常用的损失函数,我们用预测值和实际值之间的距离(即误差)来衡量模型的好坏,为了保证一致性,我们通常使用距离的平方。在深度学习算法中,我们使用基于梯度的方式来训练参数,每次将一个批次的数据输入到模型中,并得到这批数据的预测结果,再利用这批预测结果和实际值之间的距离更新网络的参数。均方误差损失函数将这一批数据的误差的期望作为最终的误差值,均方误差的公式如下:
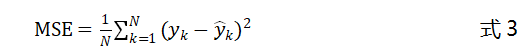
上式中为样本数据的实际值,为模型的预测值。为了简化计算,我们一般会在均方误差的基础上乘以,作为最终的损失函数:
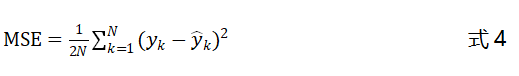
1.2交叉熵损失函数
交叉熵(Cross Entropy)损失函数使用训练数据的真实类标与模型预测值之间的交叉熵作为损失函数,相较于均方误差损失函数其更受欢迎。假设我们使用均方误差这类二次函数作为代价函数,更新神经网络参数的时候,误差项中会包含激活函数的偏导。在前面介绍激活函数的时候我们有介绍,Logistic等激活函数很容易饱和,这会使得参数的更新缓慢,甚至无法更新。交叉熵损失函数求导不会引入激活函数的导数,因此可以很好地避免这一问题,交叉熵的定义如下:
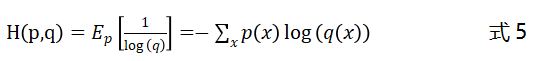
上式中为样本数据的真实分布,为模型预测结果的分布。以二分类问题为例,交叉熵损失函数的形式如下:
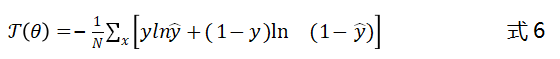
上式中为真实值,为预测值。对于多分类问题,我们对每一个类别的预测结果计算交叉熵后求和即可。
- 输出单元的选择
2.1 线性单元
线性输出单元常用于回归问题,当输出层采用线性单元时,收到上一层的输出后,输出层输出一个向量。线性单元的一个优势是其不存在饱和的问题,因此很适合采用基于梯度的优化算法。
2.2 Sigmoid单元
Sigmoid输出单元常用于二分类问题,Sigmoid单元是在线性单元的基础上,增加了一个阈值来限制其有效概率,使其被约束在区间之中,线性输出单元的定义为:

上式中是Sigmoid函数的符号表示,其数学表达式在3.2.1节中有介绍。
2.3 Softmax单元
Softmax输出单元适用于多分类问题,可以将其看作是Sigmoid函数的扩展。对于Sigmoid输出单元的输出,我们可以认为其值为模型预测样本为某一类的概率,而Softmax则需要输出多个值,输出值的个数对应分类问题的类别数。Softmax函数的形式如下:

我们以一个简单的图示来解释Softmax函数的作用,如图3-11所示。原始输出层的输出为,,,增加了Softmax层后,最终的输出为:
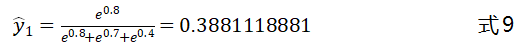
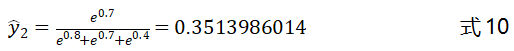
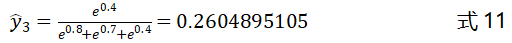
上式中、和的值可以看做是分类器预测的结果,值的大小代表分类器认为该样本属于该类别的概率,、和的和为1。
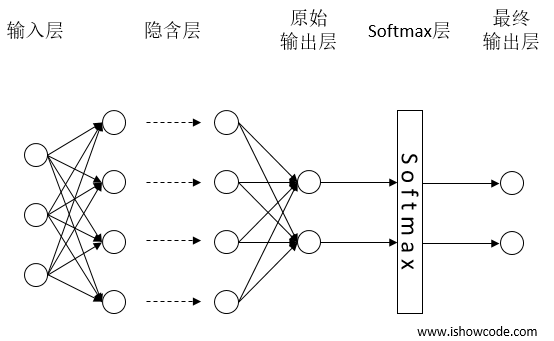
图11 Softmax输出单元
需要注意的是,Softmax层的输入和输出的维度是一样的,如果不一致,可以通过在Softmax层的前面添加一层全连接层来解决问题。
接下来将介绍第四部分:神经网络模型中的一个重要的基础知识——反向传播算法;与第五部分:使用TensorFlow搭建一个简单的多层神经网络,实现mnist手写数字的识别。
五.参考文献
1.《Parallel Distributed processing》. Rumelhart & McCelland . 1986
Tensorflow系列专题(四):神经网络篇之前馈神经网络综述的更多相关文章
- TensorFlow系列专题(七):一文综述RNN循环神经网络
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习.深度学习的知识! 目录: 前言 RNN知识结构 简单循环神经网络 RNN的基本结构 RNN的运算过程 ...
- TensorFlow系列专题(五):BP算法原理
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/ ,学习更多的机器学习.深度学习的知识! 一.反向传播算法简介 二.前馈计算的过程 第一层隐藏层的计算 第 ...
- TensorFlow系列专题(六):实战项目Mnist手写数据集识别
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习.深度学习的知识! 目录: 导读 MNIST数据集 数据处理 单层隐藏层神经网络的实现 多层隐藏层神经 ...
- TensorFlow系列专题(九):常用RNN网络结构及依赖优化问题
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习.深度学习的知识! 目录: 常用的循环神经网络结构 多层循环神经网络 双向循环神经网络 递归神经网络 ...
- TensorFlow系列专题(十四): 手把手带你搭建卷积神经网络实现冰山图像分类
目录: 冰山图片识别背景 数据介绍 数据预处理 模型搭建 结果分析 总结 一.冰山图片识别背景 这里我们要解决的任务是来自于Kaggle上的一道赛题(https://www.kaggle.com/c/ ...
- TensorFlow系列专题(八):七步带你实现RNN循环神经网络小示例
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习.深度学习的知识! [前言]:在前面的内容里,我们已经学习了循环神经网络的基本结构和运算过程,这一小节 ...
- TensorFlow系列专题(二):机器学习基础
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/ ,学习更多的机器学习.深度学习的知识! 目录: 数据预处理 归一化 标准化 离散化 二值化 哑编码 特征 ...
- TensorFlow系列专题(十一):RNN的应用及注意力模型
磐创智能-专注机器学习深度学习的教程网站 http://panchuang.net/ 磐创AI-智能客服,聊天机器人,推荐系统 http://panchuangai.com/ 目录: 循环神经网络的应 ...
- TensorFlow系列专题(十三): CNN最全原理剖析(续)
目录: 前言 卷积层(余下部分) 卷积的基本结构 卷积层 什么是卷积 滑动步长和零填充 池化层 卷积神经网络的基本结构 总结 参考文献 一.前言 上一篇我们一直说到了CNN[1]卷积层的特性,今天 ...
随机推荐
- JVM性能优化系列-(7) 深入了解性能优化
7. 深入了解性能优化 7.1 影响系统性能的方方面面 影响系统性能的因素有很多,以下列举了常见的一些系统性能优化的方向: 7.2 常用的性能评价和测试指标 响应时间 提交请求和返回该请求的响应之间使 ...
- 3——PHP 简单运算符的使用
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- 线程中断 interrupt 和 LockSupport
本文章将要介绍的内容有以下几点,读者朋友也可先自行思考一下相关问题: 线程中断 interrupt 方法怎么理解,意思就是线程中断了吗?那当前线程还能继续执行吗? 判断线程是否中断的方法有几个,它们之 ...
- go语言指南之映射练习
练习:映射 实现 WordCount.它应当返回一个映射,其中包含字符串 s 中每个“单词”的个数.函数 wc.Test 会对此函数执行一系列测试用例,并输出成功还是失败. 你会发现 strings. ...
- idea 报Сannot Run Git runnerw.exe: AttachConsole failed with error 6
报错:Сannot Run Git runnerw.exe: AttachConsole failed with error 6 解决方案:指向Git 的git.exe文件所在的安装目录,配置上就可以 ...
- Python基础-求两个字符串最长公共前轴
最长公共前缀,输入两个字符串,如果存在公共前缀,求出最长的前缀,如果没有输出no.如“distance”和“discuss”的最长公共前缀是“dis”. s1 = input('请输入第1个字符串-- ...
- mac 工具推荐
传送门: https://github.com/jaywcjlove/awesome-mac/blob/master/README-zh.md
- Iterator接口(遍历器)和for/of循环
在javascript中表示“集合”的数据结构,主要有Array,Object,Map,Set. Iterator(遍历器)接口是为各种不同的数据结构提供了统一的访问机制.任何数据结构具有Iterat ...
- 一起学习vue源码 - Object的变化侦测
作者:小土豆biubiubiu 博客园:www.cnblogs.com/HouJiao/ 掘金:https://juejin.im/user/58c61b4361ff4b005d9e894d 简书:h ...
- JavaFX之多个FXML加载和通信
前言 在使用了FXML设计布局后,新的问题随之而来,当一个程序需要多个界面时,我们不可能在一个FXML中写出全部布局,这样太过于臃肿不易查看和维护(当然非要这么做也是可以的),这里就涉及到如何在一个F ...