【python】利用jieba中文分词进行词频统计
以下代码对鲁迅的《祝福》进行了词频统计:
import io
import jieba
txt = io.open("zhufu.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(15):
word, count = items[i]
print (u"{0:<10}{1:>5}".format(word, count))
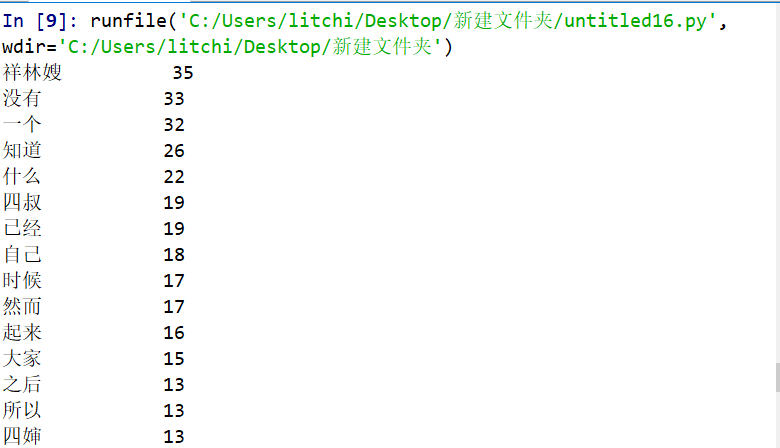
结果如下:
并把它生成词云
from wordcloud import WordCloud
import PIL.Image as image
import numpy as np
import jieba # 分词
def trans_CN(text):
# 接收分词的字符串
word_list = jieba.cut(text)
# 分词后在单独个体之间加上空格
result = " ".join(word_list)
return result with open("zhufu.txt") as fp:
text = fp.read()
# print(text)
# 将读取的中文文档进行分词
text = trans_CN(text)
mask = np.array(image.open("xinxing.jpg"))
wordcloud = WordCloud(
# 添加遮罩层
mask=mask,
font_path = "msyh.ttc"
).generate(text)
image_produce = wordcloud.to_image()
image_produce.show()
效果如下:

【python】利用jieba中文分词进行词频统计的更多相关文章
- Python大数据:jieba 中文分词,词频统计
# -*- coding: UTF-8 -*- import sys import numpy as np import pandas as pd import jieba import jieba. ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- python安装Jieba中文分词组件并测试
python安装Jieba中文分词组件 1.下载http://pypi.python.org/pypi/jieba/ 2.解压到解压到python目录下: 3.“win+R”进入cmd:依次输入如下代 ...
- python库--jieba(中文分词)
import jieba 精确模式,试图将句子最精确地切开,适合文本分析:全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义:搜索引擎模式,在精确模式的基础上,对长词再次切 ...
- 【python】一篇文章里的词频统计
一.环境 1.python3.6 2.windows系统 3.安装第三方模块 pip install wordcloud #词云展示库 pip install jieba #结巴分词 pip inst ...
- jieba中文分词
jieba中文分词¶ 中文与拉丁语言不同,不是以空格分开每个有意义的词,在我们处理自然语言处理的时候,大部分情况下,词汇是对句子和文章的理解基础.因此需要一个工具去把完整的中文分解成词. ji ...
- python利用jieba进行中文分词去停用词
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词. 分词模块jieba,它是python比较好用的分词模块.待分词的字符串可以是 unicod ...
- jieba中文分词(python)
问题小结 1.安装 需要用到python,根据python2.7选择适当的安装包.先下载http://pypi.python.org/pypi/jieba/ ,解压后运行python setup.py ...
- Python分词模块推荐:jieba中文分词
一.结巴中文分词采用的算法 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合对于未登录词,采 ...
随机推荐
- 【Python】2.17学习笔记 移位运算符,逻辑运算符
移位运算符 左移运算符 \(<<\),将对应的二进制数末尾补一颗零,高位自然溢出(遁入虚无 print( 5 << 2 ) 把\(5\)的二进制数左移两位 即把\(101\)变 ...
- libfastcommon总结(〇)
libfastcommon提供众多基础功能,该系列笔记将进行学习介绍. load_local_host_ip_addrs 进行加载主机上所有网卡的IPv4的地址. iniLoadFromFile 从文 ...
- main.c(53): error: #268: declaration may not appear after executable statement in block
这个问题是在编译STM32的程序时遇到的,这个错误的原因是对于变量的声明不能放在可执行语句后面,必须在主函数开头声明变量.在程序中声明一个变量时,需要在可执行语句之前声明,否则会出现以上错误.
- httpServletRequest.getCharacterEncoding()取出来是个null,怎么办?
因为浏览器没有把正确的编码方式给服务器端. 目前,许多浏览器在Content-Type头中不会指定字符编码方式,那么容器就会使用"ISO-8859-1"方式解析POST数据,而此时 ...
- SpringMVC框架——集成RESTful架构
REST:Representational State Transfer 资源表现层状态转换 Resources 资源 Representation 资源表现层 State Transfer 状态转换 ...
- Journal of Proteome Research | Current understanding of human metaproteome association and modulation(人类宏蛋白质组研究近期综述)(解读人:李巧珍)
文献名:Current understanding of human metaproteome association and modulation(人类宏蛋白质组研究近期综述) 期刊名:J Prot ...
- c# 使用Newtonsoft.Json解析JSON数组
一.获取JSon中某个项的值 要解析格式: [{"VBELN":"10","POSNR":"10","RET_ ...
- 图解kubernetes控制器StatefulSet核心实现原理
StatefulSet是k8s中有状态应用管理的标准实现,今天就一起来了解下其背后设计的场景与原理,从而了解其适用范围与场景 1. 基础概念 首先介绍有状态应用里面的需要考虑的一些基础的事情,然后在下 ...
- Chrome80调整SameSite策略对IdentityServer4的影响以及处理方案(翻译)
首先,好消息是Goole将于2020年2月份发布Chrome 80版本.本次发布将推进Google的"渐进改良Cookie"策略,打造一个更为安全和保障用户隐私的网络环境. 坏消息 ...
- 洛谷 P3935 Calculating 题解
原题链接 一看我感觉是个什么很难的式子-- 结果读完了才发现本质太简单. 算法一 完全按照那个题目所说的,真的把质因数分解的结果保留. 最后乘. 时间复杂度:\(O(r \sqrt{r})\). 实际 ...