hadoop+zookeeper集群高可用搭建
hadoop+zookeeper集群高可用搭建
Senerity 发布于 2016/12/12 09:19
Hadoop集群搭建步骤
1. 架构图
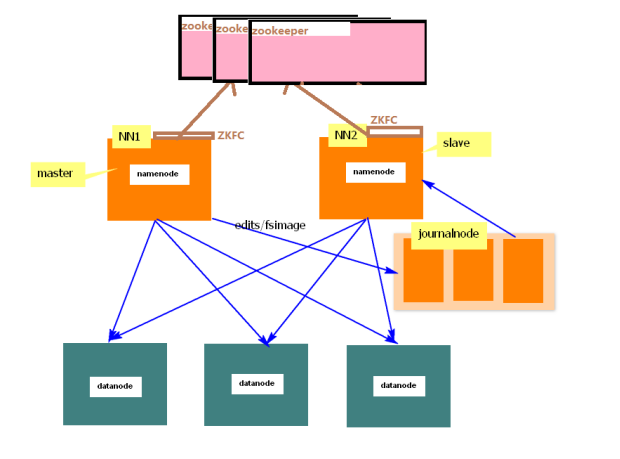
2. 准备5台机器
centosa: 192.168.42.128
centosb: 192.168.42.129
centosc: 192.168.42.130
centosd: 192.168.42.133
centose: 192.168.42.134
namenode: centosa, centosb
datanode: centosc, centosd, centose
journalnode: centosc, centosd, centose
ResourceManager: centosb
NodeManager: centosc, centosd, centose
zookeeper:centosc ,centosd ,centose
3. 5台机器分别修改主机名和IP的映射
1) 修改主机名

2) IP映射

4. 所有机器关闭防火墙
[root@centosa ~]# service iptables stop
...
5. 安装JDK配置JAVA_HOME环境变量(推荐 .bashrc)
...
6. 所有机器彼此做SSH免密码登陆
方法一,手动配置:
1) 在centosa机器生成公私密钥对
[root@centosa ~]# ssh-keygen -t dsa -P "" -f ~/.ssh/id_dsa
2) 把公钥上传给其它机器
[root@centosa ~]# scp .ssh/id_dsa.pub centosb: ~/
[root@centosa ~]# scp .ssh/id_dsa.pub centosc: ~/
[root@centosa ~]# scp .ssh/id_dsa.pub centosd: ~/
[root@centosa ~]# scp .ssh/id_dsa.pub centose: ~/
3) 在所有机器上把公钥添加到自己的信任列表
centosa:
[root@centosa ~]# cat ~/.ssh/id_dsa.pub>> .ssh/authorized_keys
centosb:
[root@centosb ~]# cat ~/id_dsa.pub>> .ssh/authorized_keys
centosc:
[root@centosc ~]# cat ~/id_dsa.pub>> .ssh/authorized_keys
centosd:
[root@centosd~]# cat ~/id_dsa.pub>> .ssh/authorized_keys
centose:
[root@centose ~]# cat ~/id_dsa.pub>> .ssh/authorized_keys
(到此,centosa可以免密码登录自己和其它机器)
4) 在其它机器上重复以上(1)(2)(3)步
方法二,使用脚本(推荐),脚本如下:
|shellscripts
|bin
|add_auth.sh:
#!/bin/bash
cat ~/id_dsa.pub >> ~/.ssh/authorized_keys
rm -rf ~/id_dsa.pub
exit
|ssh.sh:
#!/bin/bash
rm -rf ~/.ssh
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
exit
|sbin
|add_auth.sh:
#!/bin/bash
for i in $@; do
if [ ! $HOSTNAME = $i ] ;then
echo 'upload id_dsa.pub file to '$i'~/'
scp ~/.ssh/id_dsa.pub $i:~/
echo 'login on '$i
ssh root@$i ./shellscripts/bin/add_auth.sh
fi
done
|ssh.sh:
#!/bin/bash
rm -rf .ssh
for i in $@; do
echo ' Add authentication files to other files...'
ssh root@$i ./shellscripts/bin/ssh.sh
done
1) 把脚本文件夹shellscripts上传到centosa
2) 修改脚本权限
[root@centosa ~]# chmod -R 777 ~/shellscripts/
3) 把shellscripts上传给其它机器
[root@centosa ~]# scp -r ~/shellscripts centosb:~/
[root@centosa ~]# scp -r ~/shellscripts centosc:~/
[root@centosa ~]# scp -r ~/shellscripts centosd:~/
[root@centosa ~]# scp -r ~/shellscripts centose:~/
4) 执行脚本, 实现自己免登录自己,只需要在一台机器上执行该命令即可
[root@centosa ~]#
./shellscripts/sbin/ssh.sh centosa centosb centosc centosd centose
5) 执行脚本, 实现自己免登录其它机器,需要在各机器上分别执行该命令
[root@centosa ~]#
./shellscripts/sbin/add_auth.sh centosb centosc centosd centose
[root@centosb ~]#
./shellscripts/sbin/add_auth.sh centosa centosc centosd centose
[root@centosc ~]#
./shellscripts/sbin/add_auth.sh centosa centosb centosd centose
[root@centosd ~]#
./shellscripts/sbin/add_auth.sh centosa centosb centosc centose
[root@centose ~]#
./shellscripts/sbin/add_auth.sh centosa centosb centosc centosd
7. 解压hadoop-2.6.0到/usr
1) 配置core-site.xml(注意: hadoop配置文件不支持中文注释,请删除)
[root@centosa ~]# vi /usr/hadoop-2.6.0/etc/hadoop /core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value> //mycluster是对namenode做命名服务
</property>
<property>
<name>fs.trash.interval</name> //开启回收站
<value>10</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.6.0/tmp-${user.name}</value>
</property>
<property>
<name>net.topology.script.file.name</name>
<value>/usr/hadoop-2.6.0/etc/hadoop/rack.sh</value>//机架,需要创建
</property>
创建机架文件:
[root@centosa ~]# vi /usr/hadoop-2.6.0/etc/hadoop/rack.sh
while [ $# -gt 0 ] ; do
nodeArg=$1
exec</usr/hadoop-2.6.0/etc/hadoop/topology.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ] ; then
result="${ar[1]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/default_rack"
else
echo -n "$result "
fi
done
给机架添加可执行权限:
[root@centosa ~]# chmod u+x /usr/hadoop-2.6.0/etc/hadoop/rack.sh
创建topology.data文件
[root@centosa ~]# vi /usr/hadoop-2.6.0/etc/hadoop/topology.data
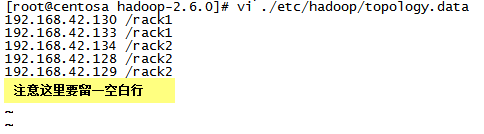
测试机架:
[root@centosa hadoop-2.6.0]# ./etc/hadoop/rack.sh 192.168.42.130

2) 配置hdfs-site.xml
[root@centosa ~]# vi /usr/hadoop-2.6.0/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
< name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
< name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>centosa:8020</value>
</property>
<property>
< name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>centosb:8020</value>
</property>
<property>
< name>dfs.namenode.http-address.mycluster.nn1</name>
<value>centosa:50070</value>
</property>
<property>
< name>dfs.namenode.http-address.mycluster.nn2</name>
<value>centosb:50070</value>
</property>
<property>
< name>dfs.namenode.shared.edits.dir</name>
<value>
qjournal://centosb:8485;centosc:8485;centosd:8485/mycluster
</value>
</property>
<property>
< name>dfs.client.failover.proxy.provider.mycluster</name>
<value>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
</value>
</property>
<property>
< name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
< name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
3) 配置slaves文件
[root@centosa ~]# vi /usr/hadoop-2.6.0/etc/hadoop/slaves
centosc
centosd
centose
4) 配置yarn-site.xml
[root@centosa ~]# vi /usr/hadoop-2.6.0/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>centosb</value>
</property>
5) 配置mapred-site.xml
[root@centosa ~]# vi /usr/hadoop-2.6.0/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6) 把./etc/hadoop/*下的所有文件同步到其它机器
[root@centosa hadoop-2.6.0]#
scp ./etc/hadoop/* centosb:/usr/hadoop-2.6.0/etc/hadoop/
scp ./etc/hadoop/* centosc:/usr/hadoop-2.6.0/etc/hadoop/
scp ./etc/hadoop/* centosd:/usr/hadoop-2.6.0/etc/hadoop/
scp ./etc/hadoop/* centose:/usr/hadoop-2.6.0/etc/hadoop/
到此,配置完成。
8. 启动步骤
1) 先启动centosc centosd centose 上的journalnode
[root@centosc hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start journalnode
[root@centosd hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start journalnode
[root@centose hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start journalnode
2) 格式化centosa上的namenode
[root@centosa hadoop-2.6.0]# ./bin/hdfs namenode -format
3) 启动centosa上的namenode
[root@centosa hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start namenode
4) 引导格式化centosb上的namenode
[root@centosb hadoop-2.6.0]# ./bin/hdfs namenode bootstrapStandby
5) 启动centosb上的namenode
[root@centosb hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start namenode
6) 启动centosc centosd centose上的dataname
[root@centosc hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start datanode
[root@centosd hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start datanode
[root@centose hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start datanode
到此为止:HDFS的集群搭建成功,但是默认情况下namenode都处于standby模式
该模式下是不允许用户对hdfs做任何修改动作。
9. [root@centosa hadoop-2.6.0]# ./bin/hdfs haadmin –help
Usage: DFSHAAdmin [-ns <nameserviceId>]
[-transitionToActive< serviceId> [--forceactive]]
[-transitionToStandby< serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>]
[-getServiceState< serviceId>]
[-checkHealth< serviceId>]
[-help <command>]
1) 让centosa(namenode nn1)变成Active活跃节点
[root@centosa hadoop-2.6.0]# ./bin/hdfs haadmin -transitionToActive nn1
目前 centosa(nn1)处于Active模式, centosb(nn2)处于Standby模式
2) 将centosa变成Standy模式 centosb 变成Active模式
[root@centosa hadoop-2.6.0]# ./bin/hdfs haadmin -failover --forceactive nn1 nn2
10. 在centosb上启动 yarn
[root@centosb hadoop-2.6.0]# ./sbin/start-yarn.sh
11. 停止hadoop集群
1) 在centosa上执行./sbin/stop-dfs.sh
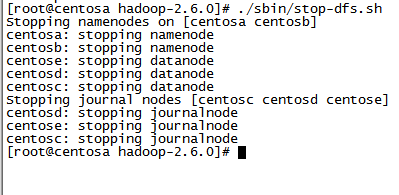
2) 在centosb上执行./sbin/stop-yarn.sh

12. 搭建zookeeper (centosc ,centosd ,centose)
1) 上传zookeeper-3.4.6.tar.gz到centosc,centosd,centose
2) 解压zookeeper-3.4.6.tar.gz
[root@centosc ~]# tar -zxf zookeeper-3.4.6.tar.gz -C /usr
[root@centosd ~]# tar -zxf zookeeper-3.4.6.tar.gz -C /usr
[root@centose ~]# tar -zxf zookeeper-3.4.6.tar.gz -C /usr
3) 在centosc上配置zoo.cfg

4) 同步./conf/zoo.cfg文件到centosd, centose
[root@centosc zookeeper-3.4.6]# scp ./conf/zoo.cfg centosd:/usr/zookeeper-3.4.6/conf/
[root@centosc zookeeper-3.4.6]# scp ./conf/zoo.cfg centose:/usr/zookeeper-3.4.6/conf/
5) 创建/usr/zookeeper-3.4.6/zkdata目录
[root@centosc zookeeper-3.4.6]# mkdir /usr/zookeeper-3.4.6/zkdata
[root@centosd zookeeper-3.4.6]# mkdir /usr/zookeeper-3.4.6/zkdata
[root@centose zookeeper-3.4.6]# mkdir /usr/zookeeper-3.4.6/zkdata
6) 分别在centosc, centosd, centose上执行:
echo '服务器编号'>> /usr/zookeeper/zkdata/myid
[root@centosc zookeeper-3.4.6]# echo '1' >> ./zkdata/myid
[root@centosd zookeeper-3.4.6]# echo '2' >> ./zkdata/myid
[root@centose zookeeper-3.4.6]# echo '3' >> ./zkdata/myid
13. 在前面的基础上,在hadoop的hdfs-site.xml中添加如下配置,并同步到其它机器
[root@centosa hadoop-2.6.0]# vi ./etc/hadoop/hdfs.site.xml
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>centosc:2181,centosd:2181,centose:2181</value>
</property>
同步到其它机器:

到此, 集群配置完成。
14. 集群启动一
1) 首先启动zookeeper
[root@centosc zookeeper-3.4.6]# ./bin/zkServer.sh start zoo.cfg
[root@centosd zookeeper-3.4.6]# ./bin/zkServer.sh start zoo.cfg
[root@centose zookeeper-3.4.6]# ./bin/zkServer.sh start zoo.cfg
2) 在centosa上执行./sbin/start-dfs.sh
[root@centosd hadoop-2.6.0]# ./sbin/start-dfs.sh
此时namenode, datanode, journalnode, zkfc会自动启动,但是ZK还没有启动
3) 注册namenode到zookeeper 只需要在任意一台namenode上执行
[root@centosa hadoop-2.6.0]# ./bin/hdfs zkfc –formatZK
4) 在centosa上执行./sbin/stop-dfs.sh 再重新启动,此时ZK才会启动
[root@centosd hadoop-2.6.0]# ./sbin/stop-dfs.sh
[root@centosd hadoop-2.6.0]# ./sbin/start-dfs.sh
5) 启动yarn, 必须登录centosb启动
[root@centosb hadoop-2.6.0]# ./sbin/start-yarn.sh
如果集群启动不成功,可能是namenode数据不一致导致,请登录centosa,centosb删除/usr/hadoop-2.6.0/tmp-${user.name}目录之后,参考集群启动二。
15. 集群启动二
1) 分别登陆centosc, centosd, centose启动zookeeper服务
[root@centosc zookeeper-3.4.6]# ./bin/zkServer.sh start zoo.cfg
[root@centosd zookeeper-3.4.6]# ./bin/zkServer.sh start zoo.cfg
[root@centose zookeeper-3.4.6]# ./bin/zkServer.sh start zoo.cfg
2) 分别登陆centosc,centosd,centose启动journalnode
[root@centosc hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start journalnode
[root@centosd hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start journalnode
[root@centose hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start journalnode
3) 格式化centosa上的namenode
[root@centosa hadoop-2.6.0]# ./bin/hdfs namenode –format
4) 启动centosa上的namenode
[root@centosa hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start namenode
5) 引导格式化centosb上的namenode
[root@centosb hadoop-2.6.0]# ./bin/hdfs namenode bootstrapStandby
6) 启动centosb上的namenode
[root@centosb hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start namenode
7) 注册namenode到zookeeper 只需要在任意一台namenode上执行
[root@centosa hadoop-2.6.0]# ./bin/hdfs zkfc -formatZK
8) 分别在两个namenode上启动zkfc监视器
[root@centosa hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start zkfc
[root@centosb hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start zkfc
9) 分别登陆centosc,centosd,centose启动datanode
[root@centosc hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start datanode
[root@centosd hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start datanode
[root@centose hadoop-2.6.0]# ./sbin/hadoop-daemon.sh start datanode
10) 启动yarn, 必须登录centosb启动
[root@centosb hadoop-2.6.0]# ./sbin/start-yarn.sh
到此,zookeeper+hadoop集群搭建完毕
hadoop+zookeeper集群高可用搭建的更多相关文章
- kudu集群高可用搭建
首先咱得有KUDU安装包 这里就不提供直接下载地址了(因为有5G,我 的服务器网卡只有4M,你们下的很慢) 这里使用的是CDH版本 官方下载地址http://archive.cloudera.com/ ...
- fastdfs+nginx集群高可用搭建的一些坑!!记录一下
首先我这里是三台节点,都搭tracker和storage,然后使用nginx做负载,只建一个group1,三个tracker! 搭建步骤比较麻烦,里面有很多坑需要注意,步骤就不啰嗦了,这里主要记录几个 ...
- Rabbitmq集群高可用测试
Rabbitmq集群高可用 RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡. Rabbit模式大概分为以下三种:单一模式.普通模 ...
- 浅谈MySQL集群高可用架构
前言 高可用架构对于互联网服务基本是标配,无论是应用服务还是数据库服务都需要做到高可用.对于一个系统而言,可能包含很多模块,比如前端应用,缓存,数据库,搜索,消息队列等,每个模块都需要做到高可用,才能 ...
- bitmq集群高可用测试
Rabbitmq集群高可用 RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡. Rabbit模式大概分为以下三种:单一模式.普通模 ...
- 集群高可用之lvs+keepalive
集群高可用之lvs+keepalive keepalive简介: 负载均衡架构依赖于知名的IPVS内核模块,keepalive由一组检查器根据服务器的健康情况动态维护和管理服务器池.keepalive ...
- mysql集群高可用架构
前言 高可用架构对于互联网服务基本是标配,无论是应用服务还是数据库服务都需要做到高可用.对于一个系统而言,可能包含很多模块,比如前端应用,缓存,数据库,搜索,消息队列等,每个模块都需要做到高可用,才能 ...
- RabbitMQ从零到集群高可用(.NetCore5.0) -高可用集群构建落地
系列文章: RabbitMQ从零到集群高可用(.NetCore5.0) - RabbitMQ简介和六种工作模式详解 RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列 ...
- openstack pike 集群高可用 安装 部署 目录汇总
# openstack pike 集群高可用 安装部署#安装环境 centos 7 史上最详细的openstack pike版 部署文档欢迎经验分享,欢迎笔记分享欢迎留言,或加QQ群663105353 ...
随机推荐
- vquery 一些应用
// JavaScript Document function myAddEvent(obj,sEv,fn){ if(obj.attachEvent){ obj.attachEvent('on'+sE ...
- js 图片实现无缝滚动
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Unity 随机数与随机种子
随机数几乎应用于游戏开发的方方面面,例如,随机生成的地图,迷宫,怪物属性等,在Unity中,使用随机数非常方便: // // 摘要: // Return a random integer number ...
- React hooks详解
此篇文章仅是对hooks入门的总结,老鸟略过吧~ React从16.8.X以后增加了一个新特性,react hooks 让我们看看这个新特性又带来了哪些惊喜呢~以下内容我们采取不同方式创建组件来进行对 ...
- [C++]那些年被虐的STL
首先很感谢**P1135奇怪的电梯 **[2.14补充:此题已被AC!然后将被我花式虐[From语]哈哈哈哈哈哈哈哈哈哈好嗨哟感觉人生已经到达了巅峰感觉人生已经到达了高潮]这道题了!在做这道题的我大致 ...
- (11)nc命令(每周一个linux命令)
nc(netcat)实用程序几乎可用于所有涉及TCP或UDP的事情.它可以打开TCP连接,发送UDP数据包,监听任意TCP和UDP端口,进行端口扫描,处理IPv4和IPv6.与telnet不同,nc可 ...
- 为 .net 生态贡献力量——制作并上传 nuget 包(内有独家彩蛋)
前言 nuget 是 .net 的常用包管理器,目前已经内置到 Visual Studio 2012 以后的版本.大多数 .net 包都托管在 nuget.org,包括 .net core 框架基础包 ...
- Java——Collection集合
##Collection集合 1.Collection集合是单列集合 2.Collection是所有单列集合最顶层的接口,定义了所有单列集合的共性方法 任意的单列集合都可以使用Collection接口 ...
- Python第六章-函数01-函数的概念和使用
函数 为了便于程序的维护和更好的实现模块化,好的程序都会分解为很多函数. 可以这么说,对于任何的编程语言,函数都是一个非常重要的概念. python 不仅简化了函数的定义过程,而且还大量借鉴了其他函数 ...
- Apple的Core ML3简介——为iPhone构建深度学习模型(附代码)
概述 Apple的Core ML 3是一个为开发人员和程序员设计的工具,帮助程序员进入人工智能生态 你可以使用Core ML 3为iPhone构建机器学习和深度学习模型 在本文中,我们将为iPhone ...