入门大数据---Sqoop基本使用
一、Sqoop 基本命令
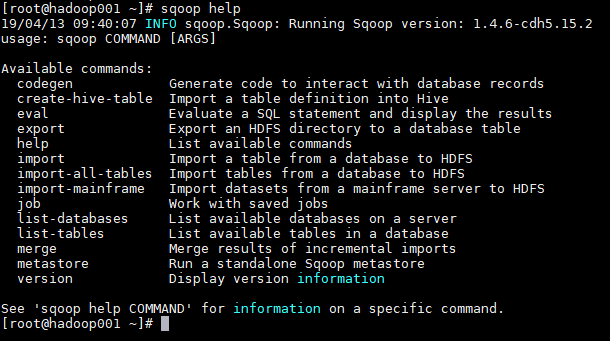
1. 查看所有命令
# sqoop help
2. 查看某条命令的具体使用方法
# sqoop help 命令名
二、Sqoop 与 MySQL
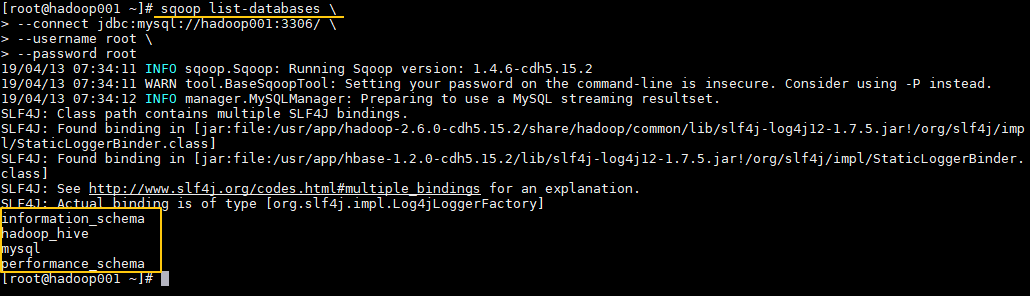
1. 查询MySQL所有数据库
通常用于 Sqoop 与 MySQL 连通测试:
sqoop list-databases \
--connect jdbc:mysql://hadoop001:3306/ \
--username root \
--password root
2. 查询指定数据库中所有数据表
sqoop list-tables \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root
三、Sqoop 与 HDFS
3.1 MySQL数据导入到HDFS
1. 导入命令
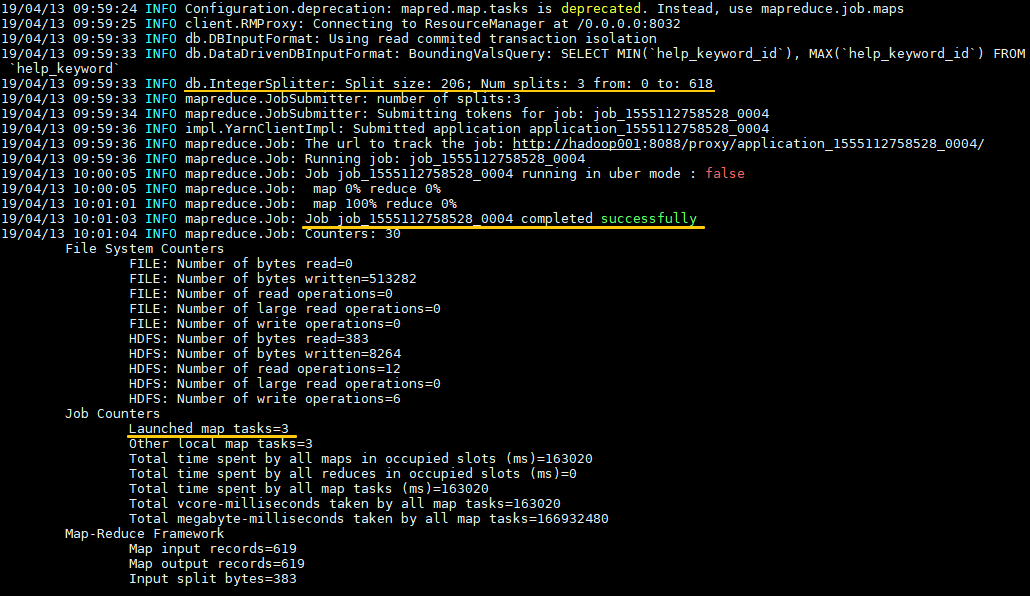
示例:导出 MySQL 数据库中的 help_keyword 表到 HDFS 的 /sqoop 目录下,如果导入目录存在则先删除再导入,使用 3 个 map tasks 并行导入。
注:help_keyword 是 MySQL 内置的一张字典表,之后的示例均使用这张表。
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--delete-target-dir \ # 目标目录存在则先删除
--target-dir /sqoop \ # 导入的目标目录
--fields-terminated-by '\t' \ # 指定导出数据的分隔符
-m 3 # 指定并行执行的 map tasks 数量
日志输出如下,可以看到输入数据被平均 split 为三份,分别由三个 map task 进行处理。数据默认以表的主键列作为拆分依据,如果你的表没有主键,有以下两种方案:
- 添加
-- autoreset-to-one-mapper参数,代表只启动一个map task,即不并行执行; - 若仍希望并行执行,则可以使用
--split-by <column-name>指明拆分数据的参考列。
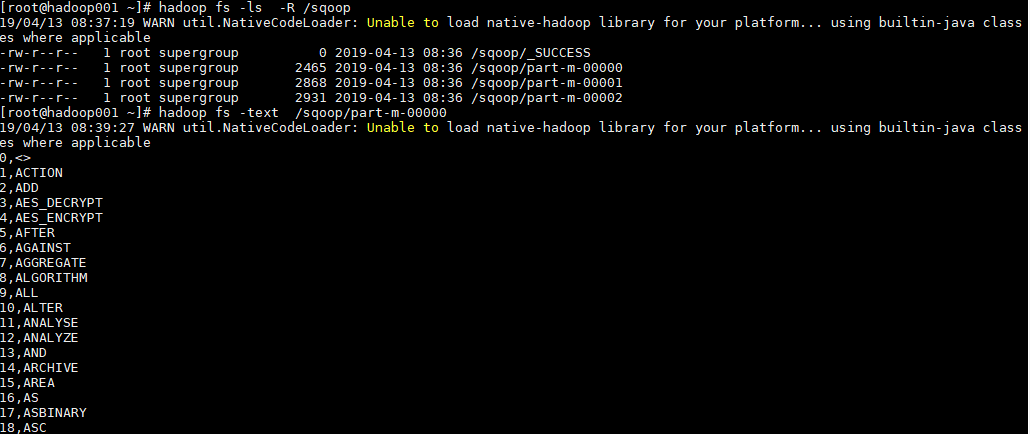
2. 导入验证
# 查看导入后的目录
hadoop fs -ls -R /sqoop
# 查看导入内容
hadoop fs -text /sqoop/part-m-00000
查看 HDFS 导入目录,可以看到表中数据被分为 3 部分进行存储,这是由指定的并行度决定的。
3.2 HDFS数据导出到MySQL
sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hdfs \ # 导出数据存储在 MySQL 的 help_keyword_from_hdf 的表中
--export-dir /sqoop \
--input-fields-terminated-by '\t'\
--m 3
表必须预先创建,建表语句如下:
CREATE TABLE help_keyword_from_hdfs LIKE help_keyword ;
四、Sqoop 与 Hive
4.1 MySQL数据导入到Hive
Sqoop 导入数据到 Hive 是通过先将数据导入到 HDFS 上的临时目录,然后再将数据从 HDFS 上 Load 到 Hive 中,最后将临时目录删除。可以使用 target-dir 来指定临时目录。
1. 导入命令
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--delete-target-dir \ # 如果临时目录存在删除
--target-dir /sqoop_hive \ # 临时目录位置
--hive-database sqoop_test \ # 导入到 Hive 的 sqoop_test 数据库,数据库需要预先创建。不指定则默认为 default 库
--hive-import \ # 导入到 Hive
--hive-overwrite \ # 如果 Hive 表中有数据则覆盖,这会清除表中原有的数据,然后再写入
-m 3 # 并行度
导入到 Hive 中的 sqoop_test 数据库需要预先创建,不指定则默认使用 Hive 中的 default 库。
# 查看 hive 中的所有数据库
hive> SHOW DATABASES;
# 创建 sqoop_test 数据库
hive> CREATE DATABASE sqoop_test;
2. 导入验证
# 查看 sqoop_test 数据库的所有表
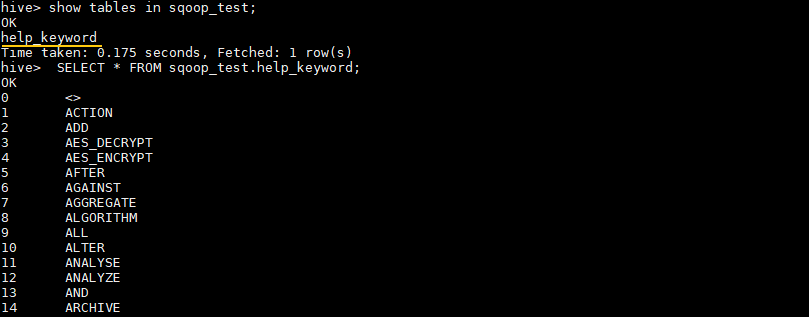
hive> SHOW TABLES IN sqoop_test;
# 查看表中数据
hive> SELECT * FROM sqoop_test.help_keyword;
3. 可能出现的问题
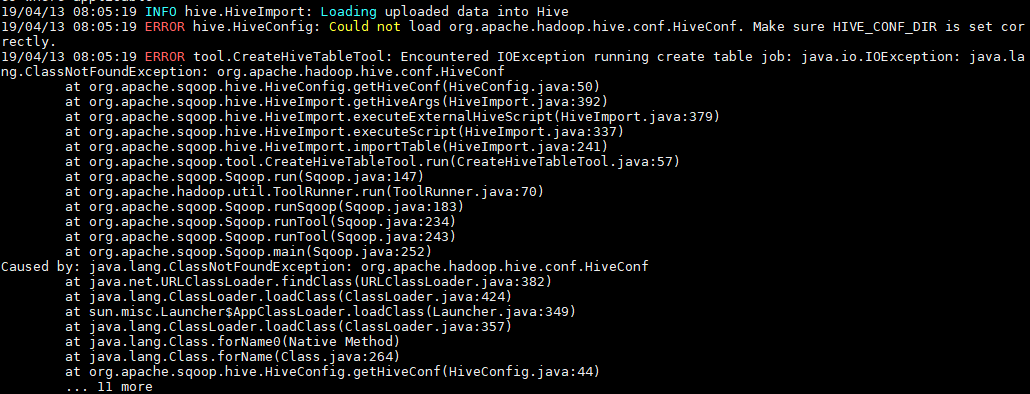
如果执行报错 java.io.IOException: java.lang.ClassNotFoundException: org.apache.hadoop.hive.conf.HiveConf,则需将 Hive 安装目录下 lib 下的 hive-exec-**.jar 放到 sqoop 的 lib 。
[root@hadoop001 lib]# ll hive-exec-*
-rw-r--r--. 1 1106 4001 19632031 11 月 13 21:45 hive-exec-1.1.0-cdh5.15.2.jar
[root@hadoop001 lib]# cp hive-exec-1.1.0-cdh5.15.2.jar ${SQOOP_HOME}/lib
4.2 Hive 导出数据到MySQL
由于 Hive 的数据是存储在 HDFS 上的,所以 Hive 导入数据到 MySQL,实际上就是 HDFS 导入数据到 MySQL。
1. 查看Hive表在HDFS的存储位置
# 进入对应的数据库
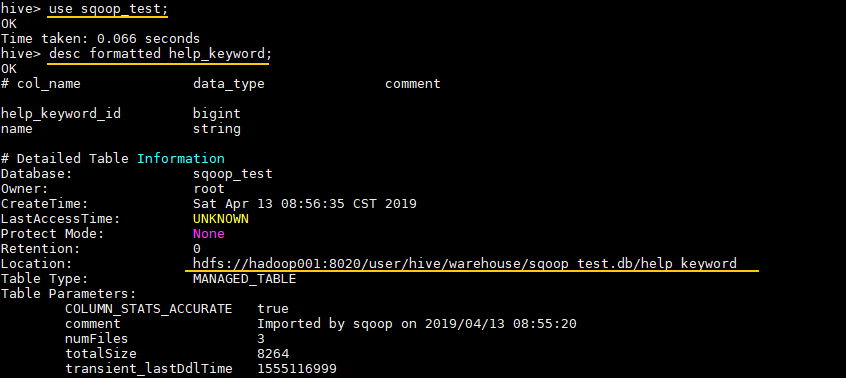
hive> use sqoop_test;
# 查看表信息
hive> desc formatted help_keyword;
Location 属性为其存储位置:
这里可以查看一下这个目录,文件结构如下:

3.2 执行导出命令
sqoop export \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword_from_hive \
--export-dir /user/hive/warehouse/sqoop_test.db/help_keyword \
-input-fields-terminated-by '\001' \ # 需要注意的是 hive 中默认的分隔符为 \001
--m 3
MySQL 中的表需要预先创建:
CREATE TABLE help_keyword_from_hive LIKE help_keyword ;
五、Sqoop 与 HBase
本小节只讲解从 RDBMS 导入数据到 HBase,因为暂时没有命令能够从 HBase 直接导出数据到 RDBMS。
5.1 MySQL导入数据到HBase
1. 导入数据
将 help_keyword 表中数据导入到 HBase 上的 help_keyword_hbase 表中,使用原表的主键 help_keyword_id 作为 RowKey,原表的所有列都会在 keywordInfo 列族下,目前只支持全部导入到一个列族下,不支持分别指定列族。
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \ # 待导入的表
--hbase-table help_keyword_hbase \ # hbase 表名称,表需要预先创建
--column-family keywordInfo \ # 所有列导入到 keywordInfo 列族下
--hbase-row-key help_keyword_id # 使用原表的 help_keyword_id 作为 RowKey
导入的 HBase 表需要预先创建:
# 查看所有表
hbase> list
# 创建表
hbase> create 'help_keyword_hbase', 'keywordInfo'
# 查看表信息
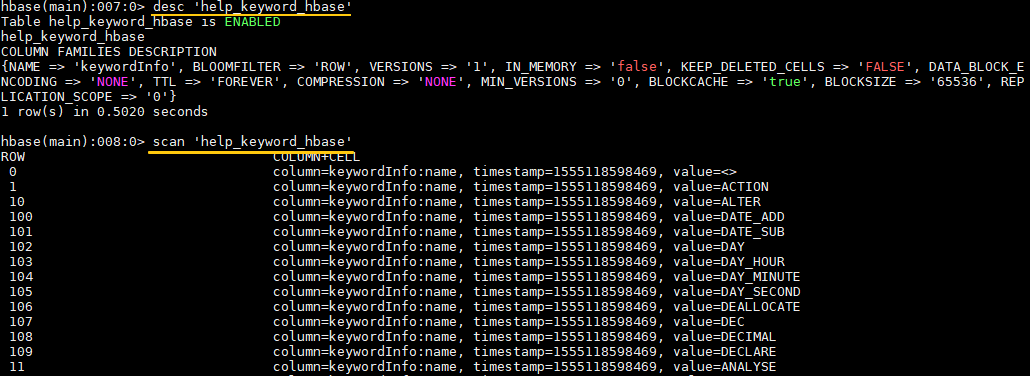
hbase> desc 'help_keyword_hbase'
2. 导入验证
使用 scan 查看表数据:
六、全库导出
Sqoop 支持通过 import-all-tables 命令进行全库导出到 HDFS/Hive,但需要注意有以下两个限制:
- 所有表必须有主键;或者使用
--autoreset-to-one-mapper,代表只启动一个map task; - 你不能使用非默认的分割列,也不能通过 WHERE 子句添加任何限制。
第二点解释得比较拗口,这里列出官方原本的说明:
- You must not intend to use non-default splitting column, nor impose any conditions via a
WHEREclause.
全库导出到 HDFS:
sqoop import-all-tables \
--connect jdbc:mysql://hadoop001:3306/数据库名 \
--username root \
--password root \
--warehouse-dir /sqoop_all \ # 每个表会单独导出到一个目录,需要用此参数指明所有目录的父目录
--fields-terminated-by '\t' \
-m 3
全库导出到 Hive:
sqoop import-all-tables -Dorg.apache.sqoop.splitter.allow_text_splitter=true \
--connect jdbc:mysql://hadoop001:3306/数据库名 \
--username root \
--password root \
--hive-database sqoop_test \ # 导出到 Hive 对应的库
--hive-import \
--hive-overwrite \
-m 3
七、Sqoop 数据过滤
7.1 query参数
Sqoop 支持使用 query 参数定义查询 SQL,从而可以导出任何想要的结果集。使用示例如下:
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--query 'select * from help_keyword where $CONDITIONS and help_keyword_id < 50' \
--delete-target-dir \
--target-dir /sqoop_hive \
--hive-database sqoop_test \ # 指定导入目标数据库 不指定则默认使用 Hive 中的 default 库
--hive-table filter_help_keyword \ # 指定导入目标表
--split-by help_keyword_id \ # 指定用于 split 的列
--hive-import \ # 导入到 Hive
--hive-overwrite \ 、
-m 3
在使用 query 进行数据过滤时,需要注意以下三点:
必须用
--hive-table指明目标表;如果并行度
-m不为 1 或者没有指定--autoreset-to-one-mapper,则需要用--split-by指明参考列;SQL 的
where字句必须包含$CONDITIONS,这是固定写法,作用是动态替换。
7.2 增量导入
sqoop import \
--connect jdbc:mysql://hadoop001:3306/mysql \
--username root \
--password root \
--table help_keyword \
--target-dir /sqoop_hive \
--hive-database sqoop_test \
--incremental append \ # 指明模式
--check-column help_keyword_id \ # 指明用于增量导入的参考列
--last-value 300 \ # 指定参考列上次导入的最大值
--hive-import \
-m 3
incremental 参数有以下两个可选的选项:
- append:要求参考列的值必须是递增的,所有大于
last-value的值都会被导入; - lastmodified:要求参考列的值必须是
timestamp类型,且插入数据时候要在参考列插入当前时间戳,更新数据时也要更新参考列的时间戳,所有时间晚于last-value的数据都会被导入。
通过上面的解释我们可以看出来,其实 Sqoop 的增量导入并没有太多神奇的地方,就是依靠维护的参考列来判断哪些是增量数据。当然我们也可以使用上面介绍的 query 参数来进行手动的增量导出,这样反而更加灵活。
八、类型支持
Sqoop 默认支持数据库的大多数字段类型,但是某些特殊类型是不支持的。遇到不支持的类型,程序会抛出异常 Hive does not support the SQL type for column xxx 异常,此时可以通过下面两个参数进行强制类型转换:
- --map-column-java<mapping> :重写 SQL 到 Java 类型的映射;
- --map-column-hive <mapping> : 重写 Hive 到 Java 类型的映射。
示例如下,将原先 id 字段强制转为 String 类型,value 字段强制转为 Integer 类型:
$ sqoop import ... --map-column-java id=String,value=Integer
参考资料
入门大数据---Sqoop基本使用的更多相关文章
- 入门大数据---Sqoop简介与安装
一.Sqoop 简介 Sqoop 是一个常用的数据迁移工具,主要用于在不同存储系统之间实现数据的导入与导出: 导入数据:从 MySQL,Oracle 等关系型数据库中导入数据到 HDFS.Hive.H ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
- 入门大数据---MapReduce-API操作
一.环境 Hadoop部署环境: Centos3.10.0-327.el7.x86_64 Hadoop2.6.5 Java1.8.0_221 代码运行环境: Windows 10 Hadoop 2.6 ...
- 入门大数据---Flume整合Kafka
一.背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合 ...
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
- 入门大数据---Kylin是什么?
一.Kylin是什么? Apache Kylin是一个开源的.分布式的分析型数据仓库,提供Hadoop/Spark 上的SQL查询接口及多维度分析(OLAP)能力以支持超大规模的数据,最初由eBay开 ...
随机推荐
- PHP AES加解密(兼容php5,php7)
最近在工作中负责对接API,对方要求对业务数据进行AES 算法(256,ECB,补码方式:PKCS5Padding)加密. 加密算法要求如下: 算法AES/ECB/PKCS5Padding 密钥长度2 ...
- Java Word中的文本、图片替换功能
Word中的替换功能以查找指定文本然后替换为新的文本,可单个替换或全部替换.以下将要介绍的内容,除常见的以文本替换文本外,还将介绍使用不同对象进行替换的方法,具体可包括: 1. 指定字符串内容替换文本 ...
- 大型可视化项目用什么工具好呢?——不如了解一下阿里云DataV尊享版
随着信息化的发展和进步,可视化大屏开始为社会各行业提供全面应用.目前越来越多的需求显示希望大屏能够更直观的还原出所要展示数据可视化的真实场景,让整个项目更立体.更有科技感,让项目在面对复杂操作时能灵活 ...
- (Java实现) 装载问题
2.装载问题 [问题描述] 有一批共n个集装箱要装上艘载重量为c的轮船,其中集装箱i的重量为wi.找出一种最优装载方案,将轮船尽可能装满,即在装载体积不受限制的情况下,将尽可能重的集装箱装上轮船. [ ...
- Java实现 LeetCode 430 扁平化多级双向链表
430. 扁平化多级双向链表 您将获得一个双向链表,除了下一个和前一个指针之外,它还有一个子指针,可能指向单独的双向链表.这些子列表可能有一个或多个自己的子项,依此类推,生成多级数据结构,如下面的示例 ...
- 第八届蓝桥杯JavaB组国(决)赛真题
解题代码部分来自网友,如果有不对的地方,欢迎各位大佬评论 题目1.平方十位数 题目描述 由0~9这10个数字不重复.不遗漏,可以组成很多10位数字. 这其中也有很多恰好是平方数(是某个数的平方). 比 ...
- Java实现 洛谷 P1914 小书童——密码
import java.util.Scanner; public class Main { private static Scanner cin; public static void main(St ...
- Dockerfile 解析
Dockerfile Dockerfile是用来构建Docker镜像的构建文件,是由一系列参数和命令构成的脚本. 构建的三个步骤:1.编写Dockerfile文件 2.docker build 3 ...
- Python学习之斐波那契数列实现篇
描述 一个斐波那契序列,F(0) = 0, F(1) = 1, F(n) = F(n-1) + F(n-2) (n>=2),根据n的值,计算斐波那契数F(n),其中0≤n≤1000. 输入 输入 ...
- App自动化测试框架学习探索--从零开始设计
App自动化测试框架学习探索--从零开始设计---持续更新中,敬请关注 1 批量执行app自动化测试使用多线程设计思路: 1)并发级别选择用methods 2)采用@Test多线程,数据提供类dp单线 ...