2. 引用计数法(Reference Counting)
- 1960年,George E. Collins 在论文中发布了引用计数的GC算法。
引用计数法意如了一个概念,那就是“计数器”,计数器表示的是对象的人气指数,
也就是有多少程序引用了这个对象(被引用书),计数器是无符号的整数。
在引用计数法中并没有mutator明确启动GC的语句。引用计数法与mutator的执行密切相关,它在mutator的处理过程中通过增减计数器的指来进行内存管理。
可以说将内存管理和mutator同时运行正式引用计数法的一大特征。
在两种情况下,计数器的值会发生增减。
生成新对象
-> 伪代码实现生产新对象 new_obj(size){
obj = pickup_chunk(size, $free_list) if(obj == NULL)
allocation_fail()
else
obj.ref_cnt = 1 # 将新生成对象的计数器置为1
return obj
}
- 在引用计数法中,除了链接到空闲链表的对象,其他所有对象都是活动对象。
- 也就是说
pickup_chunk返回NULL就意味着堆中没有合适大小的分块了。分配也就无法进行下去了。
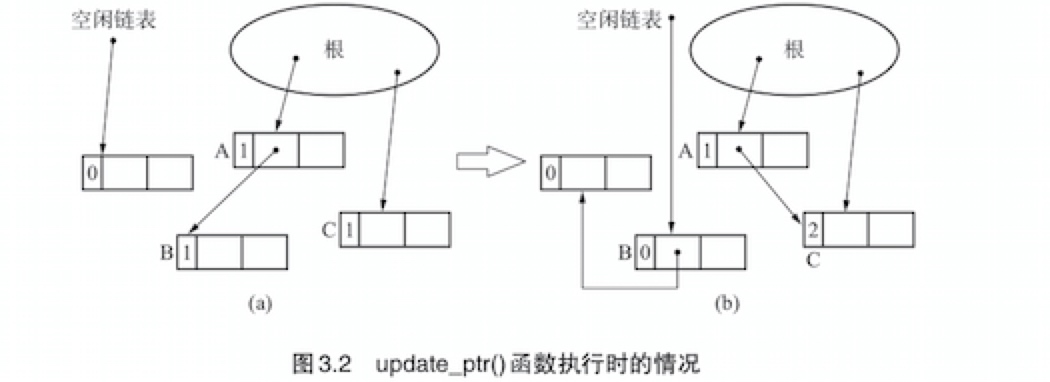
更新指针
-> 伪代码实现更新指针 update_ptr(ptr, obj) {
inc_ref_cnt(obj) # 对指针ptr新引用的对象(obj)的计数器进行增量操作
dec_ref_cnt(*ptr) # 对指针ptr之前引用的对象(*ptr)的计数器进行减量操作
*ptr = obj # 更新指针,将指针指向新的对象
}
inc_ref_cnt(obj){
obj.ref_cnt++ # 对新引用的对象obj的计数器进行增量操作
}
dec_ref_cnt(obj){
obj.ref_cnt-- # 对新引用的对象obj的计数器进行减量操作
if(obj.ref_cnt == 0) # 如果对象的计数器值减为0
for(child: children(obj)) #递归对所有自对象进行减量操作
dec_ref_cnt(*child)
reclaim(obj) # 将obj连接到空列表
}
- 之所以先吊用
inc_ref_cnt()后调用dec_ref_cnt(),是为了处理*ptr和obj是同一对象时的情况。 - 如果反过来先调用
dec_ref_cnt()后调用inc_ref_cnt(),同时*ptr和obj又是同一对象的话,执行dec_ref_cnt()的时候*ptr的计数器值就有可能因变为0而已经被回收了,这样一来,下面再执行inc_ref_cnt()的时候obj已经被回收了,可能会引发重大BUG。 - 因此我们通过先对obj的计数器进行增量操作来回避这种BUG。

- 之所以先吊用
优点
可即刻回收垃圾
- 在引用计数法中,每个对象始终都知道自己的被引用数(就是计数器的值)。当被引用数的值为0的时候,对象马上就会把自己作为空闲空间链接到空闲链表上。也就是说,不会产生垃圾碎片。
最大暂停时间短
- 只有当通过mutator更新指针时程序才会执行垃圾回收。也就是说每次通过执行mutator生成的垃圾都会被立刻回收。因而大幅度的消减了mutator的最大暂停时间
没有必要延指针查找
- 在分布式环境中,如果要沿着各个计算节点之间的指针进行查找,成本就会增大,因此需要极力控制沿指针查找的次数。所以,有一种做法是在各个计算节点内回收垃圾时使用GC标记-清除算法,在考虑到节点间的引用关系时则采用引用计数法。
缺点
计数器的增减处理繁重
- 虽然不能一概而论,不过大多数情况下指针都会频繁地更新。特别是有根的指针。
计数器需要占用很多位
- 用于引用计数的计数器最大必须能数完堆中所有对象的引用数。
- 比如,加入我们用的是32位机器,那么就可能要让2的32次方个对象同时引用同一对象。考虑到这种情况,就有必要确保各对象的计数器有32位大小。
实现繁琐复杂
- 进行指针更新的update_ptr()函数是在mutator这边调用的。需要把所有的
*ptr=obj重写成update_ptr(ptr,obj).这个任务繁重而又容易遗漏。
- 进行指针更新的update_ptr()函数是在mutator这边调用的。需要把所有的
循环引用无法回收
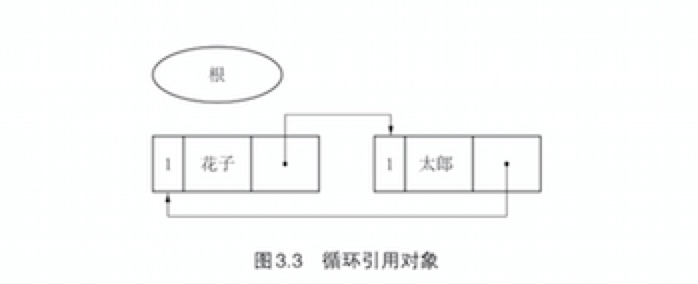 
- 没有其他对象引用他们,但他们互相引用,计数器都为1,无法被回收。
如何改良引用计数法
1. 延迟引用计数法
延迟引用计数法(Deferred Reference Counting)是L. Peter Deutsch和G. Bobrow为了解决“计数器的增减处理繁重”的缺点而研究出来的。
计数器值增减处理繁重的原因之一是从根的引用变化频繁。因此,我们就让从根引用的指针的变化不反映在计数器上。比如,我们把重写全局变量指针的update_ptr($ptr, obj)改写成*$ptr=obj。
如上,这样依赖即使频繁的重写堆中对象的引用关系,对象的计数器值也不会有所变化,因而大大改善了“计数器值的增减处理繁重”这一缺点。
然而,这样会使计数器没有正确的表现出对象的被引用数,出现对象仍在活动却被错当成垃圾回收了。于是,我们在延迟引用计数法中使用ZCT(Zero Count Table)。 ZCT是一个表,它会事前记录下计数器值在dec_ref_cnt()函数的作用下变为0的对象。
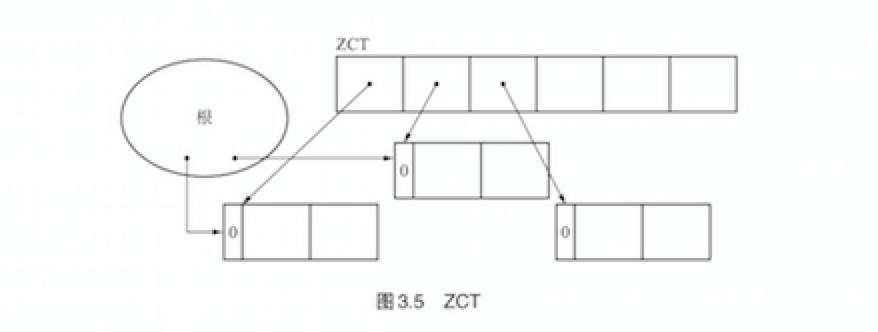 

因为计数器值为0的对象啊你个不一定都是垃圾,所以暂时先将这些对象保留。所以我们需要修改dec_ref_cnt()函数使其适应延迟引用计数法。
dec_crf_cnt(obj){
obj.ref_cnt--
if(obj.ref_cnt == 0)
if(is_full($zct) == True)
scan_zct()
push($zct, obj)
}
当obj的计数器为0时,把obj添加到$zct。不过,如果$zct爆满那么首先要通过scan_zct()函数来减少$zct中的对象。
我们也修正一下new_obj()函数, 当无法分配大小合适的分块时,先执行scan_zct()
new_obj(size){
obj = pickup_chunk(size, $free_list)
if(obj == NULL)
scan_zct()
obj = pickup_chunk(size, $free_list)
if(obj == NULL)
allocation_fail()
obj.ref_cnt = 1
return obj
}
下面是scan_zct()的实现
scan_zct(){
for(r: $roots)
(*r).ref_cnt++ # 先把所有通过根直接引用的对象的计数器都增量
for(obj : $zct) # 然后遍历zct,把所有计数器为0的对象都回收并从$zct删除
if (obj.ref_cnt == 0)
remove($zct, obj)
delete(obj)
for(r: $roots) # 再把所有通过根直接引用的对象的计数器都减量
(*r).ref_cnt--
}
delete(obj){
for(child: children(obj)
(*child).ref_cnt--
if((*child.ref_cnt == 0)
delete(*child)
reclaim(obj)
}
delete()函数对obj的子对象的计数器进行减量操作,对计数器变为0的对象执行delete()函数,最后回收obj。
优点
- 在延迟引用计数法中,程序延迟了根引用的计数,将垃圾一起回收。通过延迟,减轻了因根引用频繁发生变化而导致的计数器增减所带来的额外负担。
缺点
- 首先是失去了引用计数法的一大优点 ---- 可即刻回收垃圾。
- 另外,
scan_zct()函数导致最大暂停时间延长,执行scan_zct()函数所花费的时间与$zct的大小成正比。$zct越大,要搜索的对象就越多,妨碍mutator运作的时间也就越长,要缩短这个时间,就要缩小$zct,但这样一来调用scan_zct()函数的频率就会增加,也压低了吞吐量。很明显这样就本末倒置了。
2. Sticky引用计数法
Sticky引用计数法是用来减少计数器位宽的。
如果我们的计数器位数为5,那么这个计数器最多只能数到2的5次方减1,也就是31个引用数。如果此对象被大于31个对象引用,那么计数器就会溢出。
针对计数器溢出,需要暂停对计数器的管理。对于这种情况,我们主要有两种方法。
什么都不做
很多研究表明,很多对象一生成马上就死了。也就是说,在很多情况下,计数器的值都会在0到1的范围内变化,鲜少出现5位计数器溢出这样的情况。
其次,计数器溢出的对象成为垃圾的可能性也很低,也就是说,不增减计数器的值,就把它那么放着也不会有什么大问题。
综上,对于计数器溢出的对象,什么也不做也不失为一个可用的方法。
使用GC标记-清除算法进行管理
这里使用的GC标记-清除算法和以往有所不同
mark_sweep_for_counter_overflow(){
reset_all_ref_cnt() # 在标记前就把所有的对象的计数器设置为0
mark_phase()
sweep_phase()
}
maek_phase(){
for(r : $root)
push(*r, $mark_stack) # 先把所有根直接引用的对象的计数器都标为1
# 然后在把计数器为1的对象的子对象都标为一
# 这样就把循环引用的对象和计数器溢出的对象都归到垃圾里了
while(is_empty($mark_stack) == FALSE)
obj = pop($mark_stack)
obj.ref_cnt++
if(obj.ref_cnt == 1)
for(child : children(obj))
push(*child, $mark_stack)
}
sweep_phase(){
sweeping = $heap_top
while(sweeping < $heap_end) # 遍历堆,回收计数器为0的垃圾
if(sweeping.ref_cnt == 0)
reclaim(sweeping)
sweeping += sweeping.size
}
这里的GC标记-清除法和真正的标记清除法主要有3点不同
- 一开始就把所有对象的计数器都设为0
- 不标记对象,而是对计数器进行增量操作
- 为了对计数器进行增量操作,算法对活动对象进行了不止一次的搜索
优点
能回收计数器溢出的对象,也能回收循环引用的垃圾
缺点
- 在进行标记之前,必须重置所有的对象和计数器。
- 因为在查找对象时没有设置标志位而是把计数器进行增量,所以需要多次(次数和被引用数一致)查找活动对象。所以标记需要花费更多的时间,也就是说吞吐量会更小。
3. 1位引用计数法
1位引用计数法(1bit Reference Counting) 是Sticky引用计数法的一个极端例子。因为计数器只有1位大小。
这个方法是基于“几乎没有对象是被共有的,所有对象都能被马上回收”这一基础而提出的。考虑到这一点,即使计数器只有1位,通过用0表示被引用数为1,用1表示被引用数大于等于2。这样也能有效率的进行内存管理。
引用计数法一般会让对象持有计数器,但W.R.Stoye,T.J.W.Clarke,A.C.Norman三个人想出了1位引用计数法,以此来让指针持有计数器。
因为只有1位,所以叫“标签”更为合适。
我们分别称引用数为0的状态我们称为UNIQUE, 处于UNIQUE状态下的指针为”UNIQUE指针“;引用数为1的状态我们称为MULTIPLE,处于MULTIPLE状态下的指针为“MULTIPLE指针”。
那么我们要如何实现这个算法呢?因为指针通常默认为4字节对齐,所以没法利用低2位。只要好好利用这个性质,就能确保拿出1位来用作内存管理。
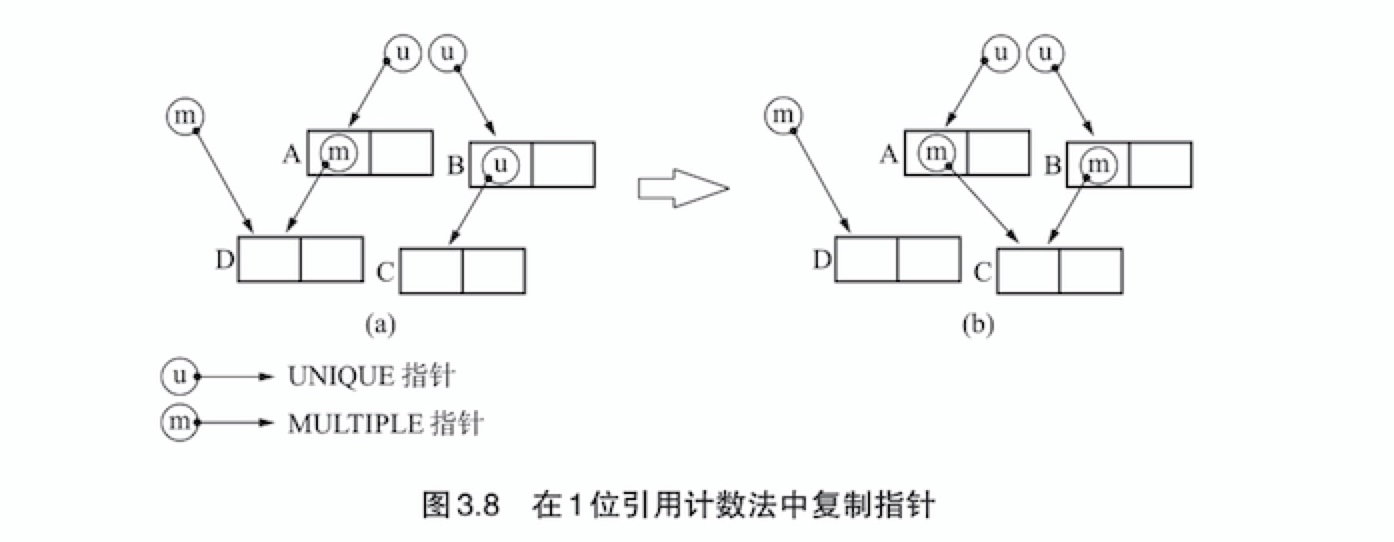 

基本上,1位引用计数法也是在更新指针的时候进行内存管理的不过它不像以往那样要制定引用的对象来更新指针,而是通过复制某个指针来更新指针的。进行这项操作的就是copy_ptr()。
copy_ptr(dest_ptr, src_ptr){
delete_ptr(dest_ptr) # 首先尝试回收dest_ptr引用的对象
*dest_ptr = *src_ptr
set_multiple_tag(dest_ptr) # 将dest_ptr的标签更新为MULTIPLE
if(tag(src_ptr) == UNIQUE)
set_multiple_tag(src_ptr)
}
delete_ptr(ptr){
# 只有当指针ptr的标签是UNIQUE时,才会回收这个指针引用的对象。
# 因为当标签时MULTIPLE时,还可能存在其他引用这个对象的指针,所以它无法回收对象。
if(tag(ptr) == UNIQUE)
reclaim(*ptr)
}
把mutator中的udpate_ptr()函数调用全换成copy_ptr()函数就能实现1位引用计数法。
优点
- 1位引用计数法的优点,是不容易出现高速缓存缺失。它不需要在更新计数器或者说(标签)的时候读取要引用的对象。比如在图3.8中完全没有读取C和D,指针的复制过程就完成了。
- 因为没必要给计数器流出多余的空间,所以节省了内存消耗量。
缺点
1位引用计数法的缺点和Sticky引用计数法的缺点基本一样。必须想办法处理计数器溢出的对象。
4. 部分标记-清除算法
部分标记-清除法是由Rafael D.Lins于1992年研究出来的。
这个算法是为了解决引用计数法存在的不能回收循环垃圾的问题。
如果直接利用GC标记-清除法去回收“有循环引用的垃圾”的话,一般来说这种垃圾应该很少,单纯的GC标记-清除算法又是以全部堆为对象的,所以会产生许多无用的搜索。
对此,我们想了个新方法,那就是只对“可能有循环引用的对象群“使用GC标记-清除算法,对其他对象进行内存管理时使用引用计数法。像这样只对一部分对象使用GC标记清除算法的方法,就叫做“部分标记-清除算法(Partial Mark & Sweep)”
不过它又个特点,执行一般的GC标记-清除算法的目的时查找活动对象,而执行部分标记-清除算法的目的则是查找非活动对象。
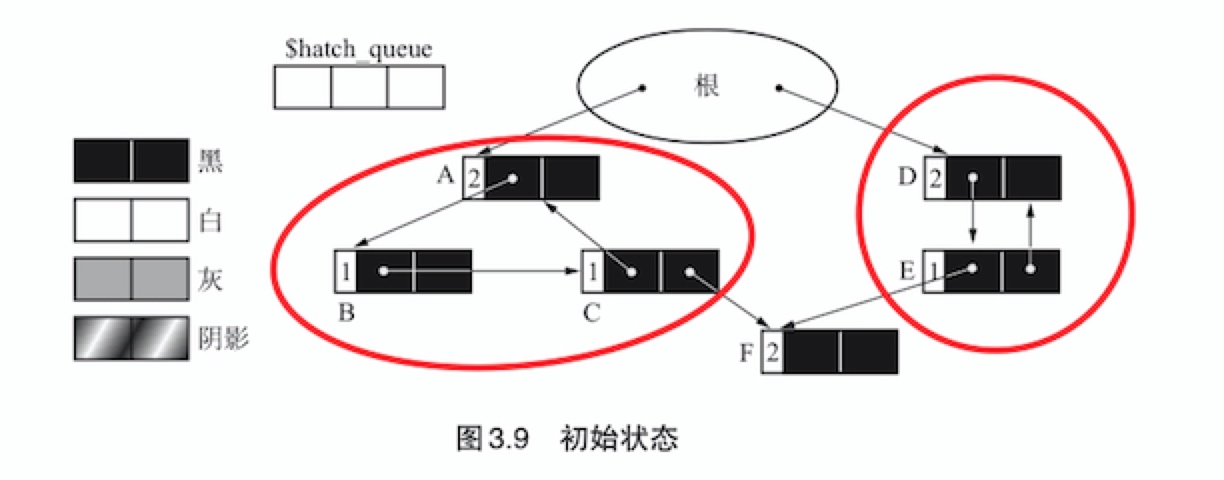 

在部分标记-清除算法中,对象会被涂成4种不同的颜色来进行管理,每种颜色的含义如下:
- 黑(BLACK):绝对不是垃圾的对象(对象产生时的初始颜色)
- 白(WHITE):绝对是垃圾的对象
- 灰(GRAY):搜索完毕的对象
- 阴影(HATCH):可能是循环垃圾的对象
在上图中,有循环引用的对象群是ABC和DE,其中A和D由根引用。此外,这个由C和E引用F。所有的对象的颜色都还是初始状态下的黑色。
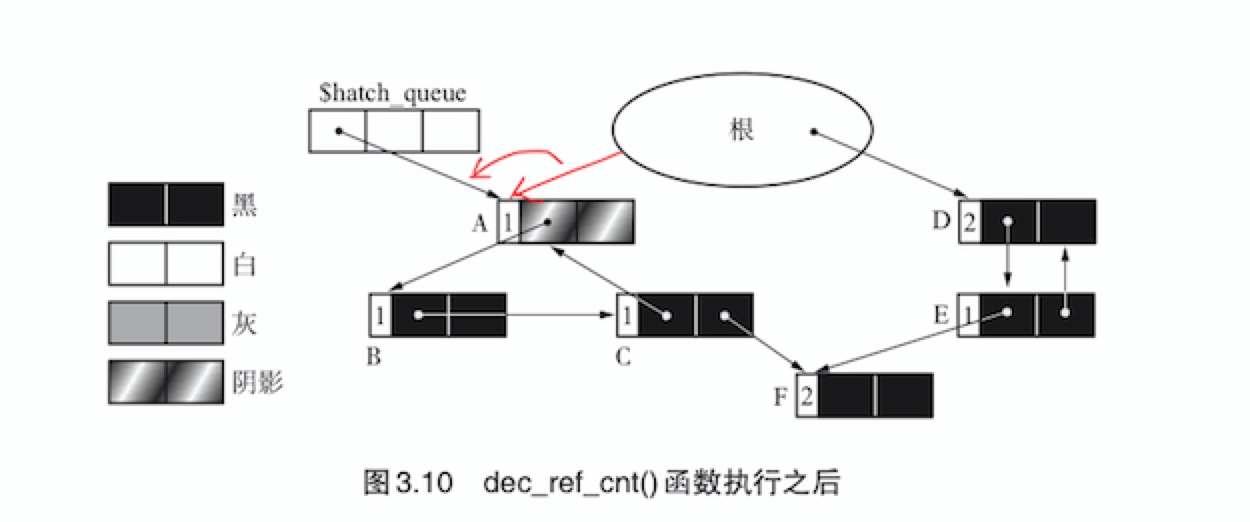
接下来,通过mutator删除由根到对象A的引用。因此我们需要在
update_ptr()函数中调用dec_ref_cnt()函数对指针进行减量操作。dec_ref_cnt(obj){
obj.ref_cnt--
if(obj.ref_cnt == 0)
delete(obj) # 引用计数器为0的就可以直接删除了
else if(obj.color != HATCH) # 引用计数器且不是阴影的不为0的先假定为循环垃圾对象
obj.color = HATCH # 因此涂上阴影
enqueue(obj, $hatch_queue) # 然后把对象放到阴影对象中
}
dec_ref_cnt()函数执行之后的堆状态如下
我们也需要修改
new_obj()函数new_obj(size){
obj = pickup_chunck(size)
if(obj != NULL)
obj.color = BLACK # 新分配的对象绝对不是垃圾,因此直接涂黑
obj.ref_cnt = 1
return obj
else if(is_empty($hatch_queue) == FALSE) # 阴影队列有对象的话就尝试释放
scan_hatch_queue() # 扫描释放
return new_obj(size) # 释放后再重新分配对象
else
allocation_fail()
}
scan_hatch_queue()函数会持续在队列中寻找阴影对象scan_hatch_queue(){
obj = dequeue($hatch_queue)
if(obj.color == HATCH)
paint_gray(obj) # 查找对象进行计数器的减量操作
scan_gray(obj) #
collect_hwite(obj)
else if(is_empty($hatch_queue) == FALSE)
scan_hatch_queue() # 直到找到阴影对象前一直从队列中取出数据
}
当obj没有被涂上阴影的时候,就意味着obj没有形成循环引用。此时程序不会对obj做任何操作,而是在此调用
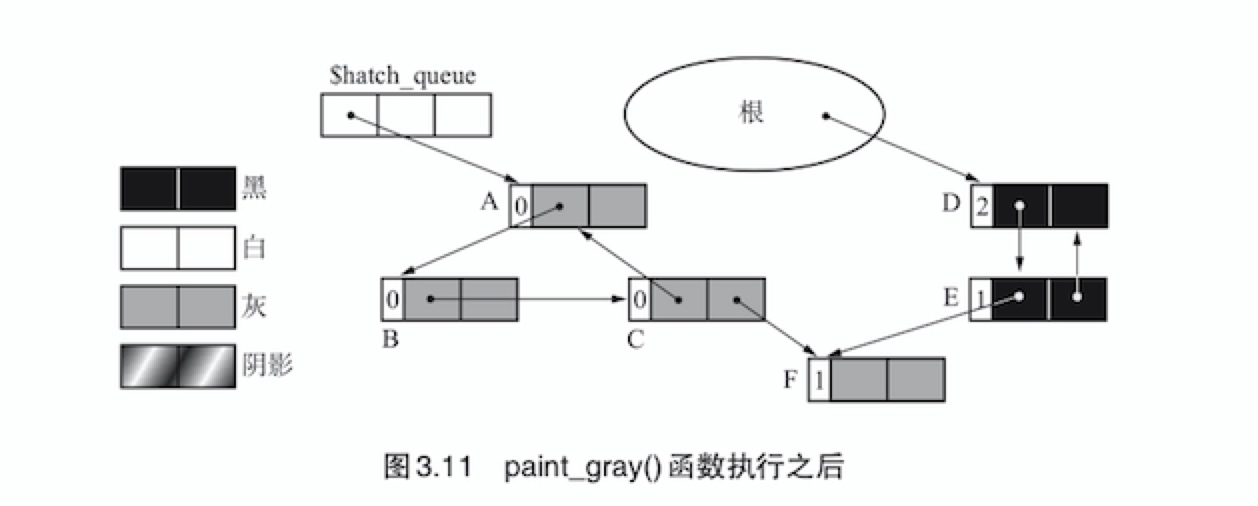
scan_hatch_queue()函数。paint_gray()干的事情非常简单,只是查找对象进行计数器的减量操作而已paint_gray(obj){
if(obj.color == (BLACK | HATCH)
obj.color = GRAY
for(child : children(obj))
(*child).ref_cnt--
paint_gray(*child)
}
程序会把黑色或者阴影对象涂成灰色,对子对象进行计数器减量操作,并调用
paint_gray()函数。把对象涂成灰色是为了防止程序重复搜索。paint_gray()函数执行后的状态如下图
这里
paint_gray()函数按对象A、B、C、F的顺序进行了搜索。下图详细展示了这一过程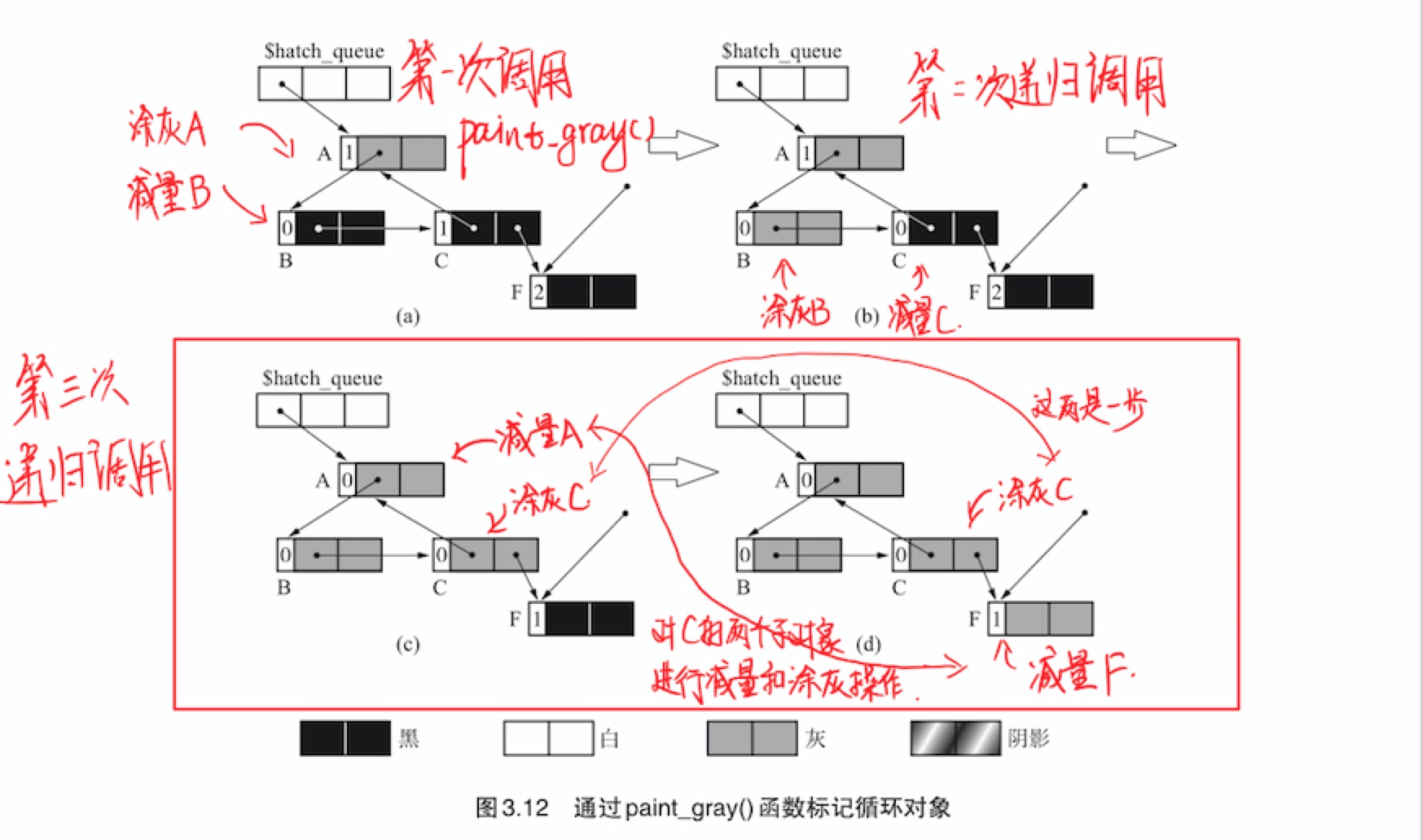 
部分标记-清除算法的特征就是要涂色的对象和要进行计数器减量的对象不是同一对象,据此就可以很顺利的回收循环垃圾。
执行晚
paint_gray()函数以后,下一个要执行的就是scan_gray()函数。它会搜索灰色对象,把计数器值为0的对象涂成白色。scan_gray(obj){
if(obj.color == GRAY) # 对所有涂灰的对象进行操作
if(obj.ref_cnt > 0)
paint_black(obj) # 计数器大于0的,说明还被他人引用,那就涂黑
else
obj.color = WHITE # 其余计数器为0的,标为垃圾并检查他们的子对象
for(child : children(obj))
scan_gray(*child)
}
在这里,程序会从对象A开始搜索,但是只搜索灰色对象,如果对象的计数器值为0,程序就会把这个对象涂成白色,在查找这个对象的子对象。所以A、B、C都被涂成了白色。
paint_black(obj){
obj.color = BLACK
for(child : children(obj))
(*child).ref_cnt++
if((*child).color != BLACK)
paint_black(*child)
}
paint_black()函数在这里进行的操作就是:从那些可能被涂成了灰色的有循环引用的的对象群中,找出已知不是垃圾的对,并将其回归原处。所以F被涂成了黑色。如果F有子对象的话,都会被涂为黑色。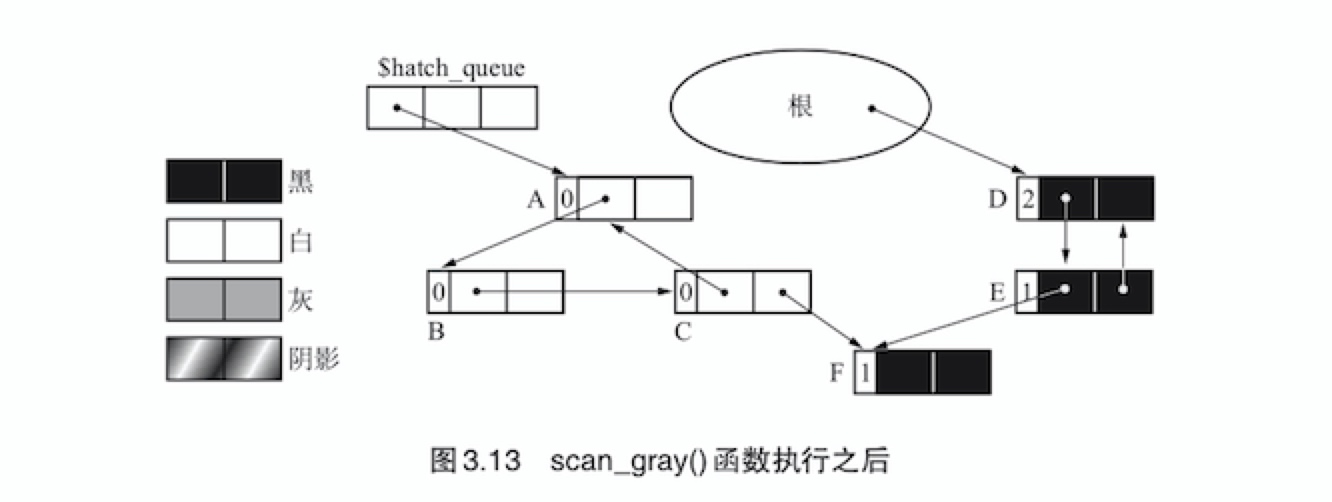 
剩下就是通过
collect_white()函数回收白色对象。collect_white(obj){
if(obj.color == WHITE)
obj.color = BLACK # 将白色对象标为黑色
for(child : children(obj))
collect_white(*child)
reclaim(obj) # 并将对象连接到空表上
}
该函数只会查找白色对象进行回收。循环垃圾也可喜的被回收了。
这就是部分呢标记-清除算法,通过这个算法就能将引用计数法过去一直让人感到棘手的"有循环引用的垃圾"回收了。
限定搜索对象
部分标记-清除算法的优点,就是要把搜索的对象限定在阴影对象及其子对象,也就是可能是循环垃圾的对象中。
当满足下面两种情况时,就会产生循环垃圾。
- 产生循环引用
- 删除从外部到循环引用的引用
部分标记-清除算法中用dec_ref_cnt()函数来检查这个值。如果对象啊你个的计数器值减量后不为0,说明这个对象可能是循环引用的一份子。这时会先让这个对象连接到队列,以方便之后搜索它。
paint_gray()函数的要点
在paint_gray()函数中,函数对obj的子对象执行计数器减量,并递归的调用paint_gray()函数。而没有对obj自身的计数器并没有被执行减量,这点非常重要。
如果这里不是对obj子对象的计数器执行减量,而是对obj的计数器执行减量会怎么样?
bad_paint_gray(obj){
if(obj.color == (BLACK | HATCH)
obj.ref_cnt--
obj.color = GRAY
for(child : children(obj))
bad_paint_gray(*child)
}
事实上,用bad_paint_gray()函数也能正常的回收循环垃圾,但是在下面的情况中,就会出错
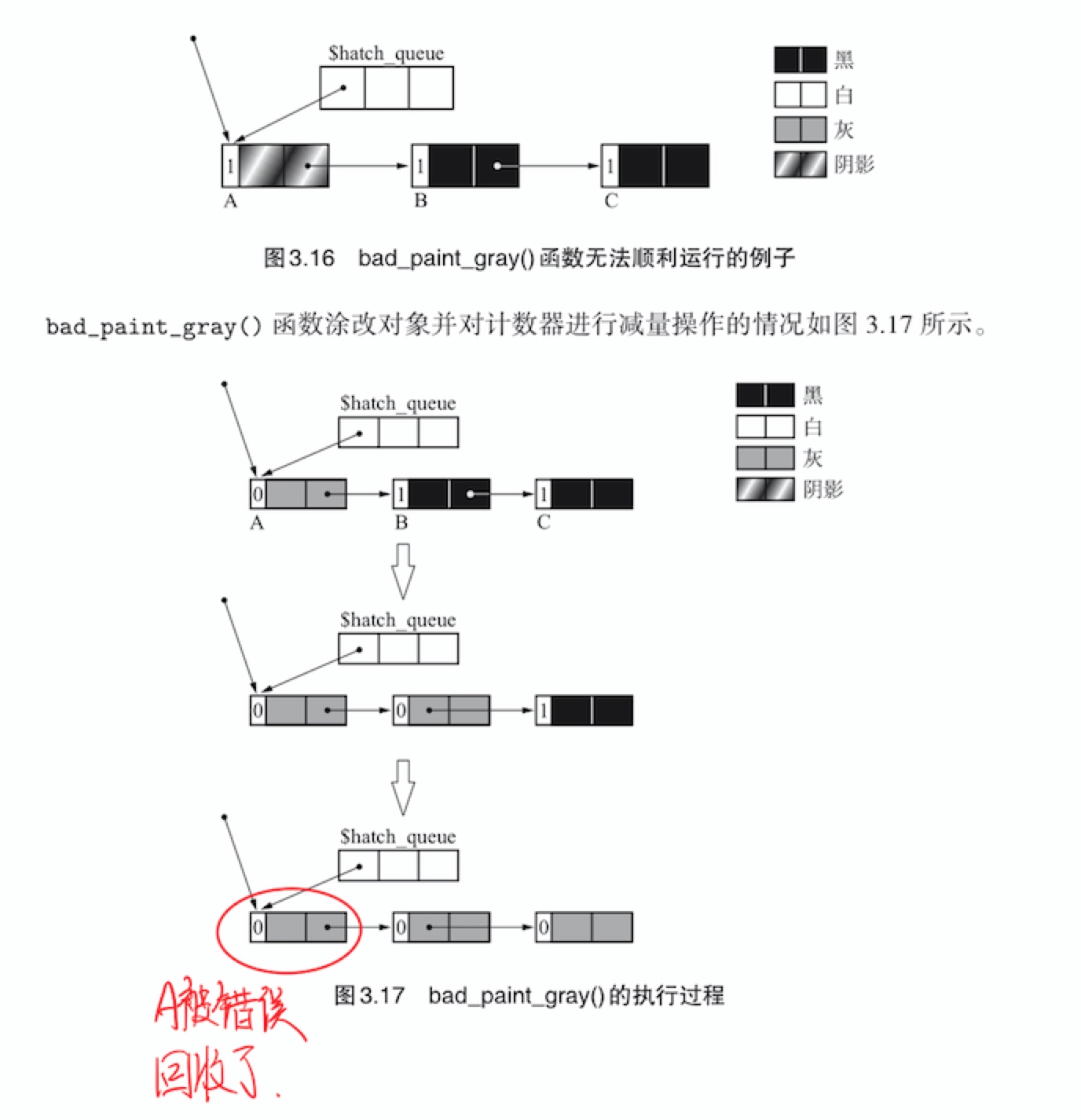 

之所以会发生这种情况,是因为bad_paint_gray()函数突然把已经进入队列的对象(也就是对象A)的计数器减量了(在进入队列的过程中dec_ref_cnt()函数中已经减量了),在这个阶段,程序无法判别对象A是否形成了循环引用。只能从A找到B,然后再查找C,再由C到A,才能知道A到C是循环的。
部分标记-清除算法的局限性
部分标记-清除算法从队列搜索对象所付出的成本太大了,被队列记录的对象毕竟是候选垃圾,所以要搜索的对象绝对不在少数。
这个算法总计需要查找三次对象,也就是说从队列取出的阴影对象分别执行一次paint_gray(),scan_gray(),collect_hwite()函数,这大大增加了内存管理所花费的时间。
此外,搜索对象还害得引用计数法的一大优点----最大暂停时间短荡然无存。
2. 引用计数法(Reference Counting)的更多相关文章
- Welcome-to-Swift-16自动引用计数(Automatic Reference Counting)
Swift使用自动引用计数(ARC)来跟踪并管理应用使用的内存.大部分情况下,这意味着在Swift语言中,内存管理"仍然工作",不需要自己去考虑内存管理的事情.当实例不再被使用时, ...
- Python中的引用计数法
目录 引用计数法 增量操作 计数器溢出的问题 减量操作 终结器 插入计数处理 引用计数法 增量操作 如果对象的引用数量增加,就在该对象的计数器上进行增量操作.在实际中它是由宏Py_INCREF() 执 ...
- JVM探究 面试题 JVM的位置 三种JVM:HotSpot 新生区 Young/ New 养老区 Old 永久区 Perm 堆内存调优GC的算法有哪些?标记清除法,标记压缩,复制算法,引用计数法
JVM探究 面试题: 请你弹弹你对JVM的理解?Java8虚拟机和之前的变化更新? 什么是OOM?什么是栈溢出StackOverFlowError?怎么分析 JVM的常用调优参数有哪些? 内存快照如何 ...
- (20)Cocos2d-x中的引用计数(Reference Count)和自动释放池(AutoReleasePool)
引用计数 引用计数是c/c++项目中一种古老的内存管理方式.当我8年前在研究一款名叫TCPMP的开源项目的时候,引用计数就已经有了. iOS SDK把这项计数封装到了NSAutoreleasePool ...
- 弱引用?强引用?未持有?额滴神啊-- Swift 引用计数指导
ARC ARC 苹果版本的自动内存管理的编译时间特性.它代表了自动引用计数(Automatic Reference Counting).也就是对于一个对象来说,只有在引用计数为0的情况下内存才会被释放 ...
- JavaScript垃圾收集-标记清除和引用计数
JavaScript具有自动垃圾收集机制,执行环境会负责管理代码执行过程中使用的内存. 垃圾收集机制原理:垃圾收集器会按照固定的时间间隔(或代码执行中预定的收集时间), 周期性地执行这一操作:找出那些 ...
- 【Netty官方文档翻译】引用计数对象(reference counted objects)
知乎有关于引用计数和垃圾回收GC两种方式的详细讲解 https://www.zhihu.com/question/21539353 原文出处:http://netty.io/wiki/referenc ...
- Reference Counting GC (Part one)
目录 引用计数法 计数器值的增减 new_obj()和update_ptr()函数 new_obj()生成对象 update_ptr()更新指针ptr,对计数器进行增减 优点 可即可回收垃圾 最大暂停 ...
- iOS开发--引用计数与ARC
以下是关于内存管理的学习笔记:引用计数与ARC. iOS5以前自动引用计数(ARC)是在MacOS X 10.7与iOS 5中引入一项新技术,用于代替之前的手工引用计数MRC(Manual Refer ...
随机推荐
- jQuery学习(三)
jQuery文档操作方法 1.内部追加内容 选择器追加到内容 append(content)在当前jQuery对象内部所包含的DOM对象的内部的最后追加content对应的内容,其中content可以 ...
- Spring AOP 中 advice 的四种类型 before after throwing advice around
spring AOP(Aspect-oriented programming) 是用于切面编程,简单的来说:AOP相当于一个拦截器,去拦截一些处理,例如:当一个方法执行的时候,Spring 能够拦截 ...
- jxl读取设置过数据有效性的xls文件报错
//在用jxl读入excel时,一直报如下错误: Warning: Cannot read drop down range Unrecognized token 43 Exception in thr ...
- Git三招
一.Git提交指令 git init git第一次使用在当前文件夹初始化一个git仓库,第二次不需要 git add . 把当前文件夹所有文件添加到缓存区中. 可以选特定的文件夹或文件.将后面的.改变 ...
- JDBC连接MySql例子
1.注册MySql连接驱动 2.设置连接MySql连接字符串.用户名和密码 3.获取数据库连接 代码如下: // 加载驱动 Class.forName("com.mysql.jdbc.Dri ...
- 【协作式原创】查漏补缺之Go并发问题(单核多核)
主要回答一下几个问题 1.单核并发问题 2.多核并发问题 2.几个不正确的同步案例 1.单核并发问题 先看一段go(1.11)代码: 单核CPU,1万个携程,每个携程执行100次+1操作, 思考n最终 ...
- input、raw_input区别,运算符,运算优先级,多变赋值方式
目录 1. Python2中的input.raw_input赋值方式和Python3中的input赋值方式的差别 2. 运算符 3. python运算符优先级 4. 格式化输出 5. 链式赋值 6. ...
- Servlet 学习(五)
重定向redirect 1.使用方法 response.sendRedirect("/应用名/ 访问资源名"); response.sendRedirect(request.get ...
- linux磁盘管理1-分区格式化挂载,swap,df,du,dd
一些基础 硬盘接口类型 ide 早期家庭电脑 scsi 早期服务器 sata 目前家庭电脑 sas 目前服务器 raid卡--阵列卡 网卡绑定 ABI 应用程序与OS之间的底层接口 API 应用程序调 ...
- Linux系统的发展历史和学习前景介绍
2020年了,我想来跟大家聊聊Linux运维这一行业,从几个方面说下行业的现状.如何学好Linux和如何成为专业运维人员以及云服务对于Linux运维的影响. 一.linux行业状况 我们都知道从199 ...