【Spark】Spark必不可少的多种集群环境搭建方法
Local模式运行环境搭建
小知识
Local模式常用语本地开发测试,分为Local单线程和Local-cluster多线程,也被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,直接运行在本地,便于调试,通常用来验证开发出来的应用程序逻辑上有没有问题。
其中N代表可以使用N个线程,每个线程拥有一个core。 N是一个正整数,表示启动多少个线程来模拟spark的集群的运行。如果不指定N,则默认是1个线程(该线程有1个core)。
如果是local[*],表示使用与CPU核实相等个数的线程数来运行spark的程序 (Run Spark locally with as many worker threads as logical cores on your machine.)
搭建步骤
一、上传压缩包并解压
将编译后的压缩包上传到/export/softwares目录下并解压,这里有编译CDH版本Spark的方法
cd /export/softwares
tar -zxvf spark-2.2.0-bin-2.6.0-cdh5.14.0.tgz -C ../servers/
二、修改Spark配置文件
复制出一份即可
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
cp spark-env.sh.template spark-env.sh
三、启动验证进入Spark-shell
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
./bin/spark-shell --master local
退出
:quit
四、运行Spark自带的测试jar包
bin/spark-submit \ 通过spark-submit脚本来执行任务
> --class org.apache.spark.examples.SparkPi \ 指定我们main方法所在的程序
> --master local[2] \ 指定master所在的服务器
> --executor-memory 1G \ executor分配内存
> --total-executor-cores 2 \ 一共给分配多少个CPU核数
> /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \ 指定我们需要运行的jar包的路径
> 100 参数,迭代计算次数
standAlone模式运行环境搭建
搭建步骤
一、修改配置文件
修改spark-env.sh,添加指定内容
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
vim spark-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
export SPARK_MASTER_HOST=node01
export SPARK_MASTER_PORT=7077
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
修改slaves文件
cp slaves.template slaves
vim slaves
node02
node03
修改spark-defaults.conf
为了方便调试开发,一般都会经过配置将spark程序的运行日志保存到HDFS上,方便运行程序之后的开发调试
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/spark_log
spark.eventLog.compress true
在HDFS上穿件日志文件存放的目录
hdfs dfs -mkdir -p /spark_log
三、将配置好的安装包分发到其他机器
cd /export/servers/
scp -r spark-2.2.0-bin-2.6.0-cdh5.14.0/ node02:$PWD
scp -r spark-2.2.0-bin-2.6.0-cdh5.14.0/ node03:$PWD
四、启动Spark程序
在第一台服务器执行以下命令
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
sbin/start-all.sh
sbin/start-history-server.sh
五、页面访问
访问Spark:http://node01:8080/
查看spark任务的历史日志:http://node01:4000/
六、进入Spark-shell测试启动
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
bin/spark-shell --master spark://node01:7077
:quit
七、运行Spark自带的测试jar包
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
500
HA模式运行环境搭建
搭建步骤
一、停止Spark集群
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
sbin/stop-all.sh
sbin/stop-history-server.sh
二、修改配置文件
修改Spark-env.sh
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
vim spark-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
# 注释这行
# export SPARK_MASTER_HOST=node01
export SPARK_MASTER_PORT=7077
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
# 添加这行
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"
剩下修改slaves文件、spark-defaults.conf在搭建standAlone集群已经修改
三、配置文件分发到其他服务器
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
scp spark-env.sh node02:$PWD
scp spark-env.sh node03:$PWD
四、启动Spark集群
在node01启动
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
sbin/start-all.sh
sbin/start-history-server.sh
可以在node02和node03都启动master节点
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
sbin/start-master.sh
这样 http://node02:8080/ 和http://node03:8080/都可以访问
五、进入Spark-shell
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/
bin/spark-shell --master spark://node01:7077,node02:7077,node03:7077
:quit
六、运行Spark自带的测试jar包
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077,node02:7077,node03:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
100
On Yarn模式运行环境搭建
官方文档说明
http://spark.apache.org/docs/latest/running-on-yarn.html
http://spark.apache.org/docs/latest/running-on-yarn.html#configuration
On Yarn有两种部署模式:
Client Mode —— In client mode, the driver runs in the client process, and the application master is only used for requesting resources from YARN. Driver程序运行在客户端进程里面,appmaster仅仅用于资源的申请
Cluster Mode —— the Spark driver runs inside an application master process which is managed by YARN on the cluster, and the client can go away after initiating the application. Spark驱动程序在应用程序主进程中运行,应用程序主进程由集群上的YARN管理,客户端可以在启动应用程序后离开。 适用于实际工作环境
tips
如果Spark程序是运行在yarn上,就不需要Spark集群了,只需要找任意一台服务器配置Spark的客户端提交任务到yarn集群上即可
如果yarn集群不够,可以在hadoop的配置文件yarn-site.xml中添加两个配置并重启yarn集群,用来跳过yarn集群资源的检查
<property>
<name> yarn.nodemanager.pmem-check-enabled</name
<value>false</value>
</property>
<property>
<name> yarn.nodemanager.vmem-check-enabled</name
<value>false</value>
</property>
搭建步骤
一、三台机器都修改spark-env.sh
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
vim spark-env.sh
添加以下配置
export HADOOP_CONF_DIR=/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
export YARN_CONF_DIR=/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf
scp spark-env.sh node02:$PWD
scp spark-env.sh node03:$PWD
二、三台机器添加spark环境变量
vim /etc/profile
export SPARK_HOME=/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
export PATH=:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
source /etc/profile
三、任务提交
1.Client模式
① 步骤
在node03服务器执行以下命令
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
10
② 任务提交过程解析
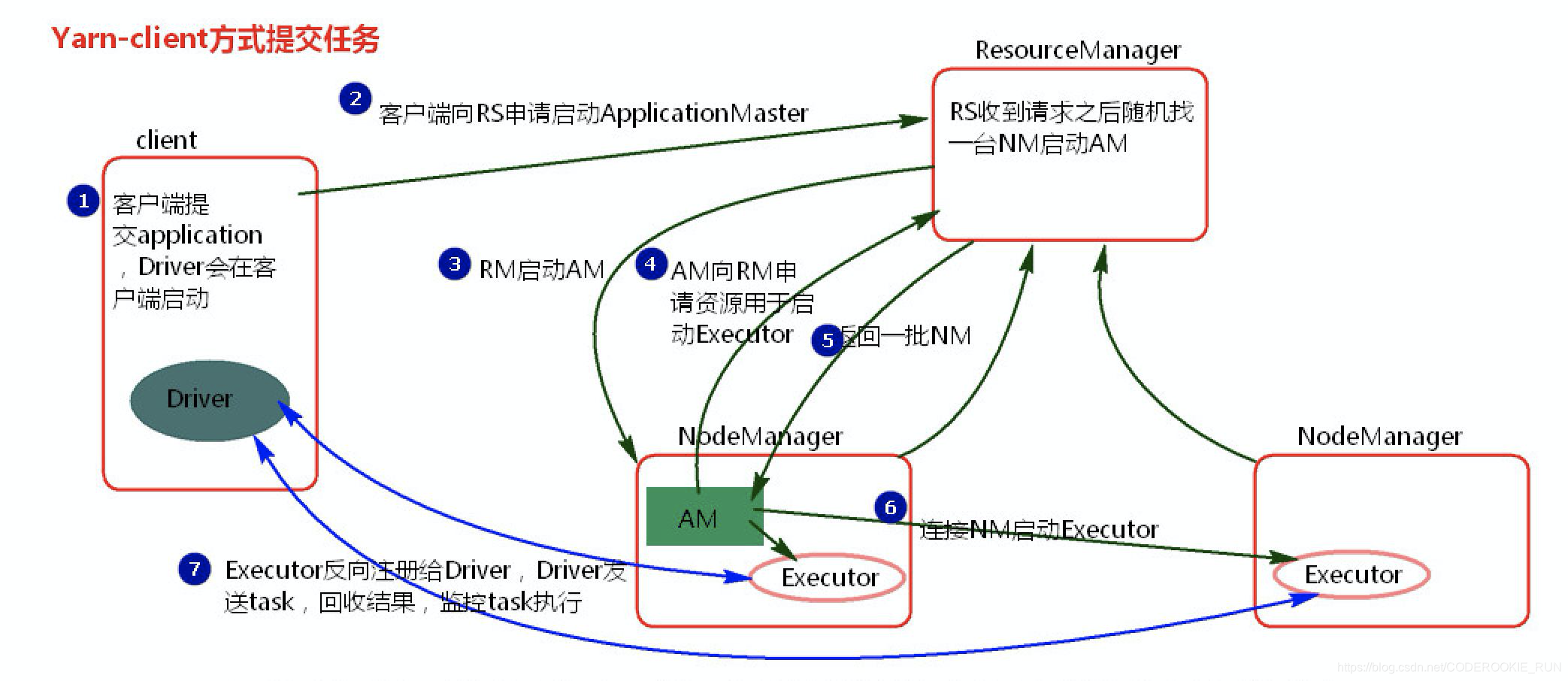
Client模式更适用于测试,因为Driver运行在本地,会与yarn集群中的Executor进行大量的通信,如此一来会造成客户机网卡流量的大量增加。
注意: ApplicationMaster有launchExecutor和申请资源的功能,并没有作业调度的功能。
2.Cluster模式
① 步骤
在node03执行以下命令
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
10
② 任务提交过程分析
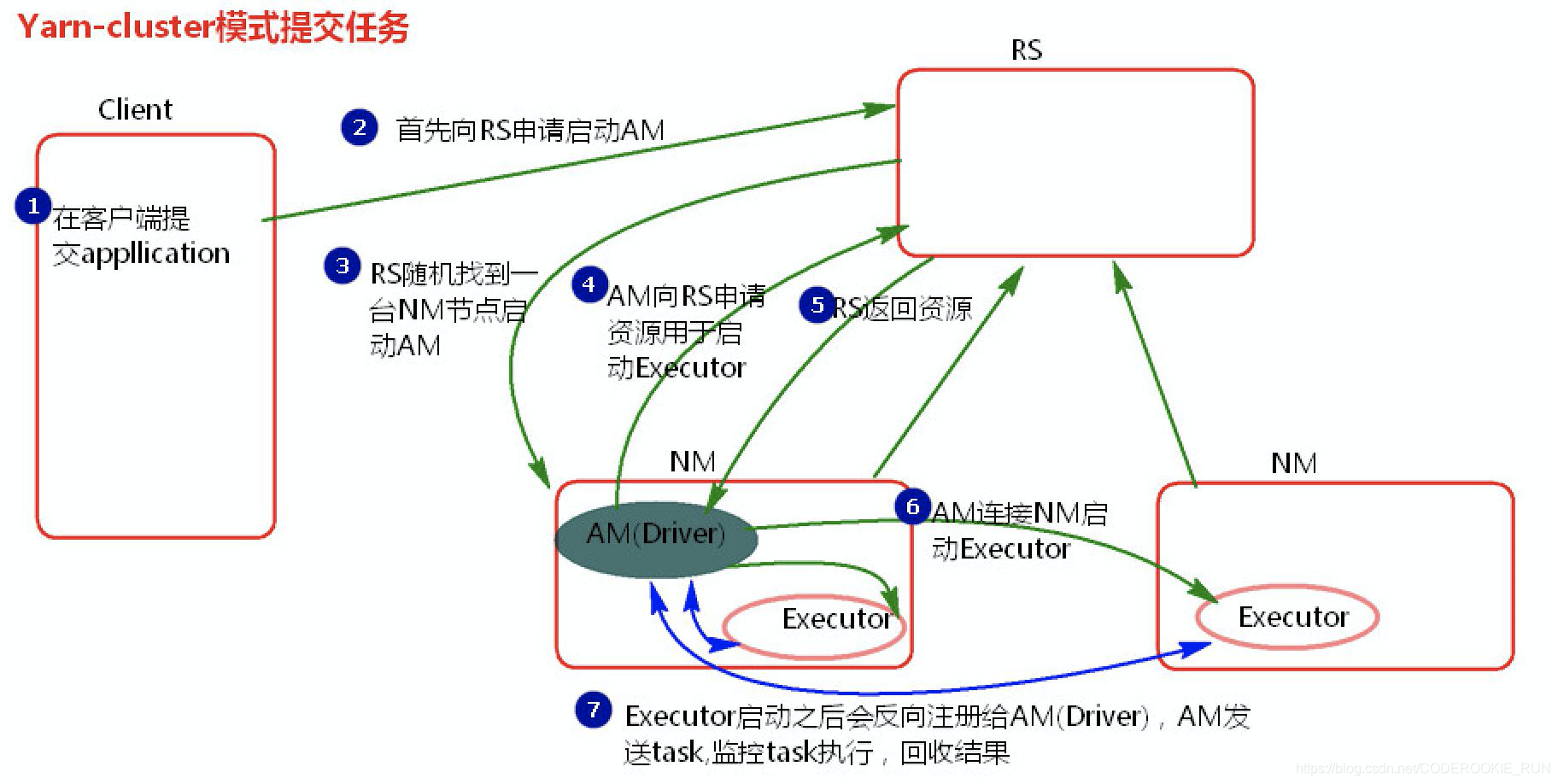
Cluster模式主要用于实际工作当中,因为Driver运行在Yarn集群的某一台NodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后看不到日志,只能通过yarn查看日志
本模式下的ApplicationMaster除了launchExecutor和申请资源的功能外,也拥有了任务调度的功能。
停止集群任务命令:yarn application -kill applicationID
四、访问历史日志界面
http://node01:8088/cluster/app/applicationId
【Spark】Spark必不可少的多种集群环境搭建方法的更多相关文章
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- Spark 2.2.0 分布式集群环境搭建
集群机器: 1台 装了 ubuntu 14.04的 台式机 1台 装了ubuntu 16.04 的 笔记本 (机器更多时同样适用) 1.需要安装好Hadoop分布式环境 参照:Hadoop分类 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十一)定制一个arvo格式文件发送到kafka的topic,通过Structured Streaming读取kafka的数据
将arvo格式数据发送到kafka的topic 第一步:定制avro schema: { "type": "record", "name": ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- Ant概念
Ant是基于Java的.可以跨平台的项目编译和生成工具.
- numpy basic sheatsheet
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库.NumPy 通常与 SciPy(Scien ...
- 中国剩余定理(CRT)
只看懂了CRT,EXCRT待补.... 心得:记不得这是第几次翻CRT了,每次都有迷迷糊糊的.. 中国剩余定理用来求解类似这样的方程组: 求解的过程中用到了同余方程. x=a1( mod x1) x= ...
- [GO] mac安装GO 初次尝试
其实试了好多方法,我用的是下面这种方法,简单快捷! 安装homebrew 在终端输入命令 ruby -e "$(curl -fsSL https://raw.githubuserconten ...
- .NET 4 实践 - 使用dynamic和MEF实现轻量级的AOP组件 (4)
转摘 https://www.cnblogs.com/niceWk/archive/2010/07/23/1783394.html 借花献佛 前面我们介绍了构成DynamicAspect绝大部分的类, ...
- 推荐一个小而美的Python代码格式化工具
代码可读性是评判代码质量的标准之一,有一个衡量代码质量的标准是 Martin 提出的 “WFT” 定律,即每分钟爆出 “WTF” 的次数.你在读别人代码或者做 Code Review 的时候有没有 “ ...
- 数值计算方法实验之Hermite 多项式插值 (Python 代码)
一.实验目的 在已知f(x),x∈[a,b]的表达式,但函数值不便计算,或不知f(x),x∈[a,b]而又需要给出其在[a,b]上的值时,按插值原则f(xi)= yi(i= 0,1…….,n)求出简单 ...
- 关于json转义中文
服务器传递或者程序传递中,不识别读取到的JSON数据中 \u开头的数据. PHP 生成JSON的时候,必须将汉字不转义为 \u开头的UNICODE数据. 网上很多,但是其实都是错误的,正确的方法是在j ...
- gin请求数据校验
前言 最近优化gin+vue的前后端分离项目代码时候,发现代码中对请求数据的校验比较繁琐,于是想办法简化它.最终我发现了go-playground/validator开源库很好用. 优化前代码 代码如 ...
- tp5--开启与关闭调试模式
https://www.cnblogs.com/finalanddistance/p/8906000.html TP5 显示错误信息 在TP5中,我们运行的代码有错误无法执行时,只显示页面错误,而 ...