SK-learn实现k近邻算法【准确率随k值的变化】-------莺尾花种类预测
代码详解:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from pylab import mpl # 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
#读取数据
iris = load_iris() #分出训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.3,random_state=22) #数据标准化,防止异常点的影响
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test) #创建画布
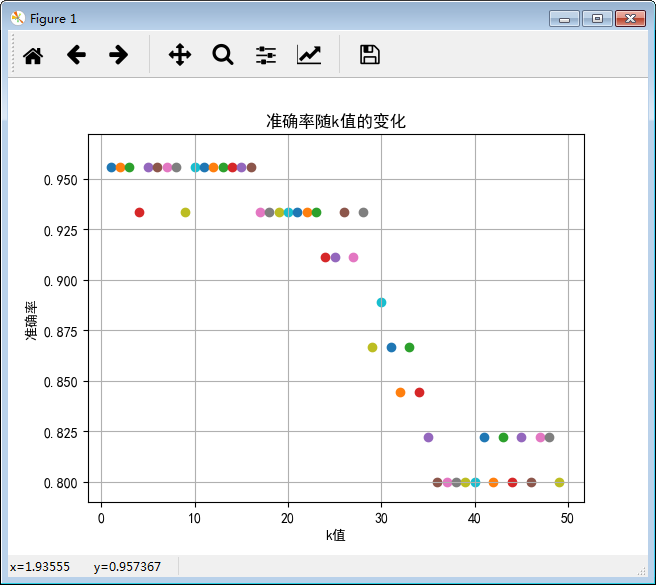
plt.figure()
plt.title("准确率随k值的变化")
#打开交互
plt.ion()
#网格
plt.grid()
#x轴和y轴标注
plt.ylabel("准确率")
plt.xlabel("k值") #循环k的取值从1到50
for k in range(1,50):
# plt.cla()
#定义一个k分类算法对象
estimator = KNeighborsClassifier(n_neighbors=k)
#训练
estimator.fit(x_train,y_train) #用测试集测试准确率
y_predict = estimator.predict(x_test)
score = estimator.score(x_test, y_test)
#画散点图
plt.scatter(k,score)
plt.pause(0.1) print("预测结果为:",y_predict)
print("对比真实值和预测值:",y_test)
print("准确率:",score) #关闭交互模式,并最后显示图像
plt.ioff()
plt.show()
SK-learn实现k近邻算法【准确率随k值的变化】-------莺尾花种类预测的更多相关文章
- 1.K近邻算法
(一)K近邻算法基础 K近邻(KNN)算法优点 思想极度简单 应用数学知识少(近乎为0) 效果好 可以解释机器学习算法使用过程中的很多细节问题 更完整的刻画机器学习应用的流程 图解K近邻算法 上图是以 ...
- Python3入门机器学习 - k近邻算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代 ...
- 02-16 k近邻算法
目录 k近邻算法 一.k近邻算法学习目标 二.k近邻算法引入 三.k近邻算法详解 3.1 k近邻算法三要素 3.1.1 k值的选择 3.1.2 最近邻算法 3.1.3 距离度量的方式 3.1.4 分类 ...
- k近邻算法(KNN)
k近邻算法(KNN) 定义:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. from sklearn.model_selection ...
- R语言学习笔记—K近邻算法
K近邻算法(KNN)是指一个样本如果在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.即每个样本都可以用它最接近的k个邻居来代表.KNN算法适 ...
- 机器学习(四) 分类算法--K近邻算法 KNN (上)
一.K近邻算法基础 KNN------- K近邻算法--------K-Nearest Neighbors 思想极度简单 应用数学知识少 (近乎为零) 效果好(缺点?) 可以解释机器学习算法使用过程中 ...
- 机器学习(1)——K近邻算法
KNN的函数写法 import numpy as np from math import sqrt from collections import Counter def KNN_classify(k ...
- python 机器学习(二)分类算法-k近邻算法
一.什么是K近邻算法? 定义: 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别. 来源: KNN算法最早是由Cover和Hart提 ...
- GridSearchCV网格搜索得到最佳超参数, 在K近邻算法中的应用
最近在学习机器学习中的K近邻算法, KNeighborsClassifier 看似简单实则里面有很多的参数配置, 这些参数直接影响到预测的准确率. 很自然的问题就是如何找到最优参数配置? 这就需要用到 ...
随机推荐
- Python第十一章-常用的核心模块03-json模块
python 自称 "Batteries included"(自带电池, 自备干粮?), 就是因为他提供了很多内置的模块, 使用这些模块无需安装和配置即可使用. 本章主要介绍 py ...
- CSS躬行记(2)——伪类和伪元素
一.伪类选择器 伪选择器弥补了常规选择器的不足,能够实现一些特殊情况下的样式,例如在鼠标悬停时或只给字符串中的第一个字符指定样式.与类选择器类似,可以从HTML元素的class属性中查看到,但伪选择器 ...
- 2.Metasploit数据库配置及扫描模块介绍
01.Metasploit数据库配置及扫描模块介绍 信息收集 信息收集是渗透测试中首先要做的重要事项之一,目的是尽可能多的查找关于目标的信息,我们掌握的信息越多,渗透成功的机会越大.在信息 ...
- JVM类加载过程详细分析
双亲委派加载模型 为什么需要双亲委派加载模型 主要是为了安全,避免用户恶意加载破坏JVM正常运行的字节码文件,比如说加载一个自己写的java.util.HashMap.class.这样就有可能造成包冲 ...
- Linux基础:Day04
进程管理1.操作系统基础 调用:kernel通过给应用程序提供system call方式来提供硬件资源: 注意:这个应用程序也包括库文件: 库文件是运行在ring 0上的一段程序代码,不对客户直接 ...
- 【Linux】Apache服务配置
一. URL 统一资源定位符 http://www.sina.com.cn:80/admin/index.html 二. 环境安装 LAMP 源码包编译安装 版本可以自定义 生产环境 安全 稳定 开发 ...
- 2017蓝桥杯取位数(C++B组)
题目: 标题:取数位求1个整数的第k位数字有很多种方法.以下的方法就是一种.// 求x用10进制表示时的数位长度 int len(int x){ if(x<10) return 1; retur ...
- Android 图片裁剪库 uCrop
引语 晚上好,我是猫咪,我的公众号「程序媛猫咪」会推荐 GitHub 上好玩的项目,挖掘开源的价值,欢迎关注我. 现在 Android 开发,离不开图片,必然也需要图片裁剪功能,这个实现可以调用系统的 ...
- js骚操作骂人不带脏
前言 很多小伙伴们觉得javaScript很简单,下面的这行 javaScript代码可能会让你怀疑人生. (!(~+[])+{})[--[~+""][+[]]*[~+[]] + ...
- Scala函数式编程(六) 懒加载与Stream
前情提要 Scala函数式编程指南(一) 函数式思想介绍 scala函数式编程(二) scala基础语法介绍 Scala函数式编程(三) scala集合和函数 Scala函数式编程(四)函数式的数据结 ...