Pyspider的简单介绍和初使用
Pyspider
Pyspider是由国人(binux)编写的强大的网络爬虫系统
Ptspider带有强大的WebUi / 脚本编辑器 / 任务监控器 / 项目管理器以及结果处理器。他支持多种数据库后端 / 多种消息队列 / Javascript 渲染页面爬去。使用起来非常方便
基本功能
- 提供了方便易用的 WebUi 系统,可视化的编写和调试爬虫
- 提供爬去进度监控 / 爬去结果查看 / 爬虫项目管理等功能
- 支持多种后端数据库,如:MySQL / MongoDB / Rides 等
- 支持多种消息队列,如:RabbimMQ / Beanstalk / Redis / Kombu
- 提供优先级控制 / 失败重试 / 定时抓取等
- 对接了PhantonJS。可以抓取Javascript 渲染的页面
- 支持单机和分布式部署,支持 Docker 部署
Pyspider 和 Scrapy
Pyspider - 提供了 WebUi ,爬虫编写 / 调试都是在WebUi 中进行的。
Scrapy - 原生是不具备这个功能的,他采用的代码和命令行的操作,但是可以通过对接Portia 实现可视化配置
Pyspider - 调试非常便捷,WebUi 操作便捷直观
Scrapy - 是使用parse 命令进行调试,方便程度不及Pyspider
Pyspider - 支持PhantomJS 来进行Javascript 渲染页面的采集。
Scrapy - 可以对接Scrapy-Splash组件实现,不过需要额外的配置
Pyspider - 中内置了pyquery 作为选择器
Scrapy - 对接了 Xpath / CSS 选择器和正则
Pyspider - 的可扩展程度不足,可配置化程度不高。
Scrapy - 可以通过对接Middleware / Pipelinc / Extension 等组件来实现非常强大的功能。模块之间的耦合度低,可扩展性高
如果要快速实现一个页面的抓取,推荐使用 Pyspider ,开发更便捷 ,如:爬去某个新闻网站内容
如果要对应反爬程度很大,规模较大的爬去。推荐使用 Scrapy ,如:封IP / 封账号风险大,高频率验证的网站
Pyspider 架构
Pyspider 架构主要分为 Scheduler(调度器)/ Fetcher(抓取器)/ Processer(处理器)三个部分,整个爬去过程受到 Monitor(监控器)的监控,抓取的结果被 Result Worker(结果处理器)处理
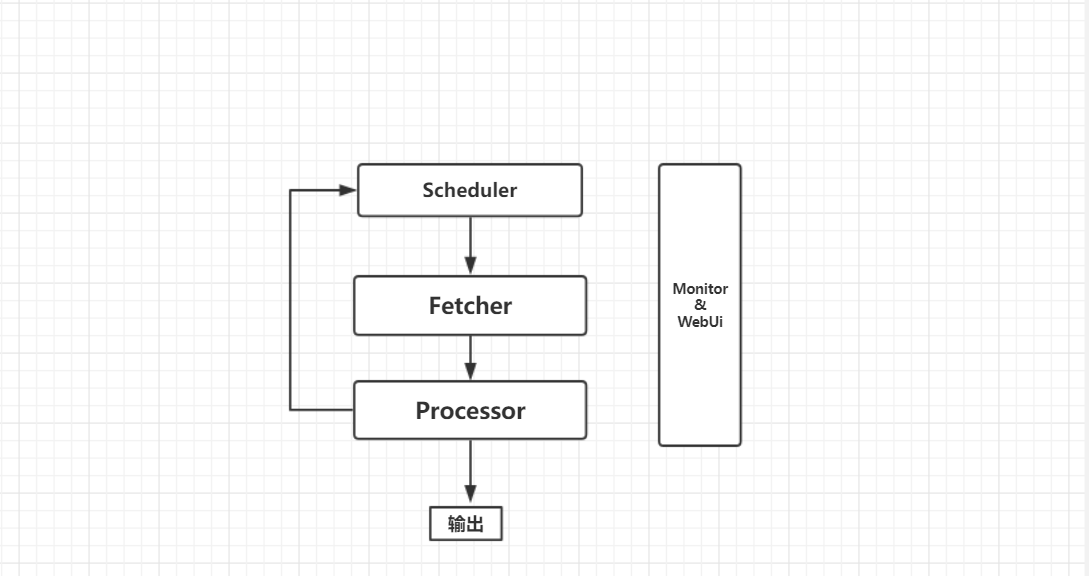
Scheduler 发起任务调度,Fetcher 负责抓取网页内容,Processer负责解析网页,然后将新生成的 Request 发送给 Scheduler 进行调度,将生成的提取结果输出保存
执行逻辑
Pyspider 的任务执行流程逻辑很清晰。
- 每个 Pyspider 的项目对应一个python 脚本,该脚本中定义了一个 Handler 类,他有一个 on_start() 方法,爬去守底线调用 on_start() 方法生成最初的抓取任务。然后发送给 Scheduler 进行调度
- Scheduler 将抓取任务分发给 Fetcher 进行抓取,Fetcher 执行并得到响应,随后将响应发送给 Processer
- Processer 处理响应并提取出新的 URL 生成新的抓取任务,然后通过消息队列的方式通知 Schduler 当前抓取任务执行情况,并将新生成的抓取任务发送给 Scheduler 。如果生成了新的提取结果,则将其发送到结果队列等待Result Worker 处理
- Scheduler 接收到新的的抓取任务,然后查询数据库,判断其如果是新的抓取任务或者是需要重试的任务就继续进行调度,然后将其返回给 Fetcher 进行抓取
- 不断重复以上工作。直到所有的人物都执行完毕,抓取结束
- 抓取结束后。程序会回调 on_start() 方法,这里可以定义后处理过程
Pyspider基本使用
环境准备:
- Pyspider
- PhantomJS
- MongoDB
- Pymongo
在下载Pyspider 时会遇到报错

在 https://www.lfd.uci.edu/~gohlke/pythonlibs/#pycurl 中下载python 对应的版本及计算机位数
切换目录至下载文件所在目录。进入cmd。进行安装
然后重新打开cmd,进行pip install pyspider,如果安装途中出现了。错误多试几次。即可
运行 pyspider -- pyspider all
启动的时候可能一直卡在result_worker starting 或者 出现报错
ValueError: Invalid configuration: - Deprecated option 'domaincontroller': use 'http_authenticator
如果出现卡顿状态。在出现 result_worker starting 之前 使用 CTRL + C 终止。在次启动即可。

如果出现了报错。原因是因为WsgiDAV发布了版本 pre-release 3.x。在安装包中找到pyspider的资源包,然后找到webui文件里面的webdav.py文件打开,修改第209行即可。
目标位置 : 'domaincontroller': NeedAuthController(app),
更改为 : http_authenticator':{
'HTTPAuthenticator':NeedAuthController(app),
},
再次输入pyspider all 即可
打开浏览器127.0.0.1:5000或者http://localhost:5000/ 打开pyspider的web UI界面,
创建项目
create --> Project Name --> Start URL(s) -- > create
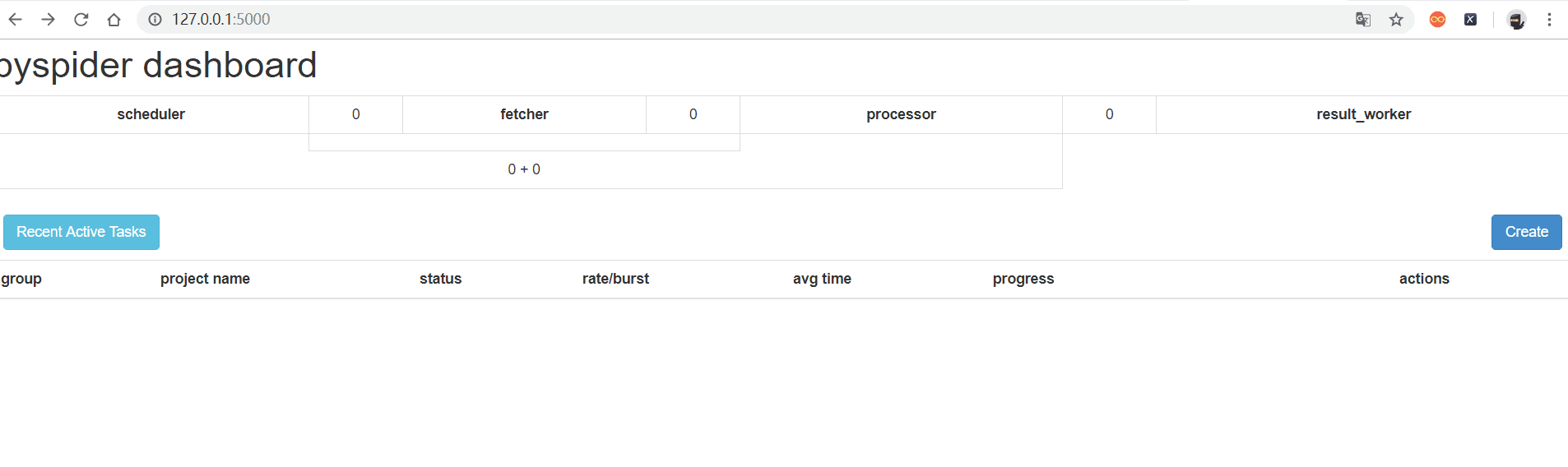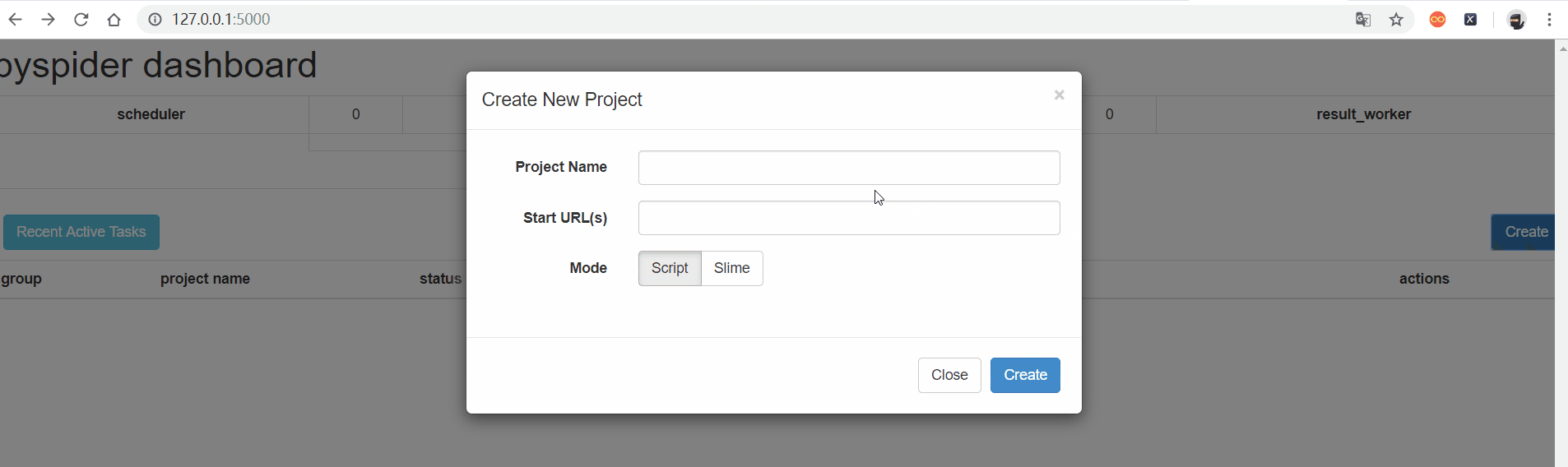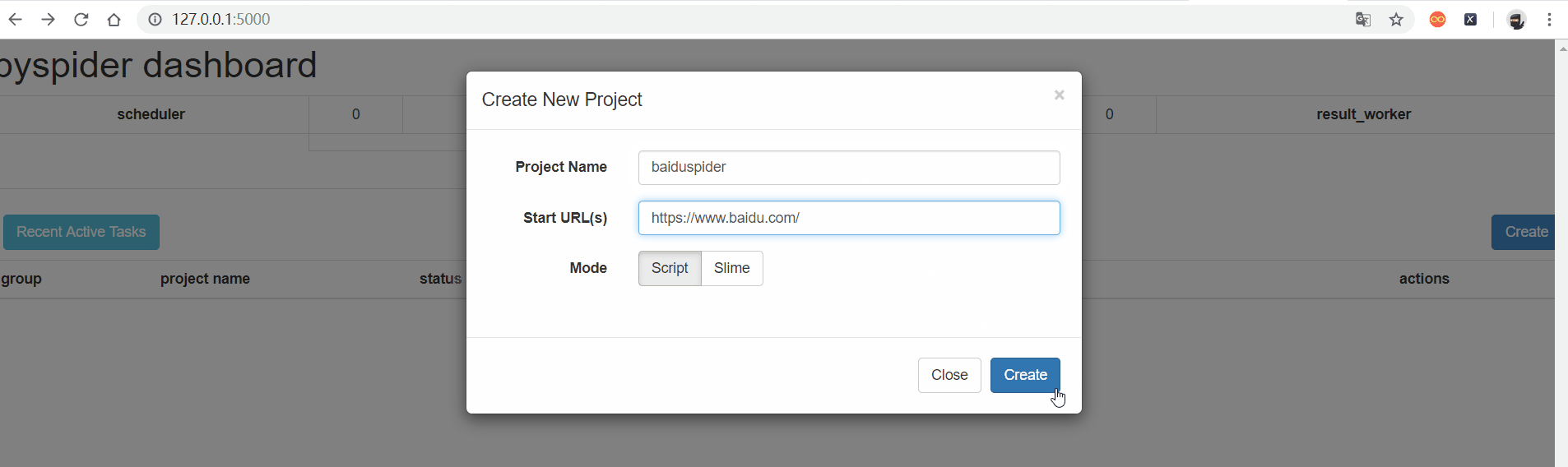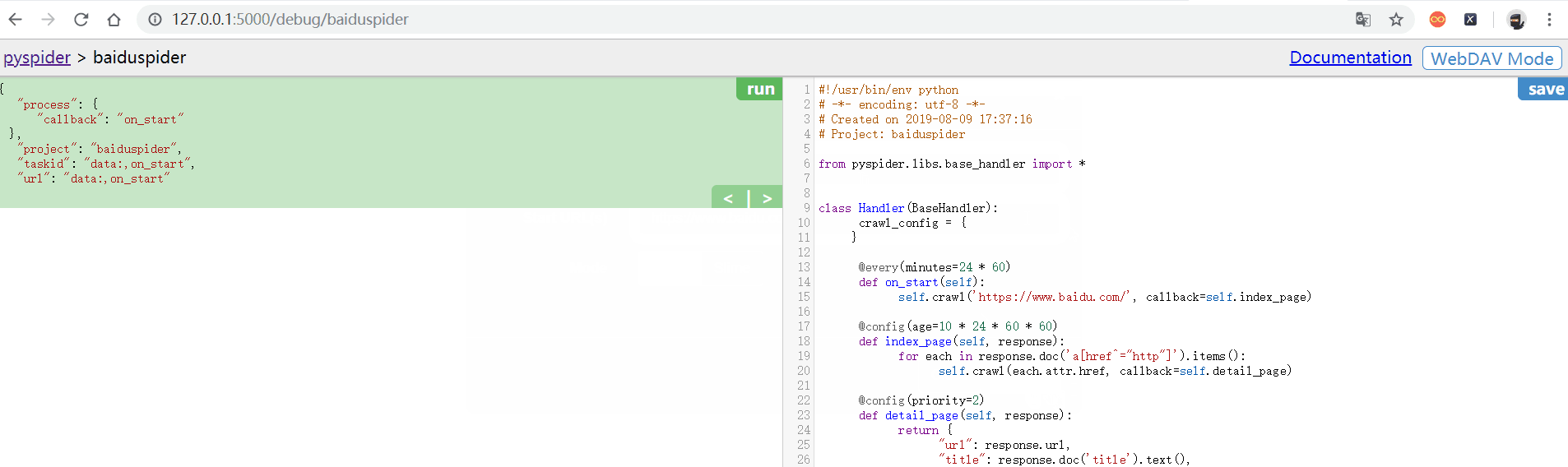
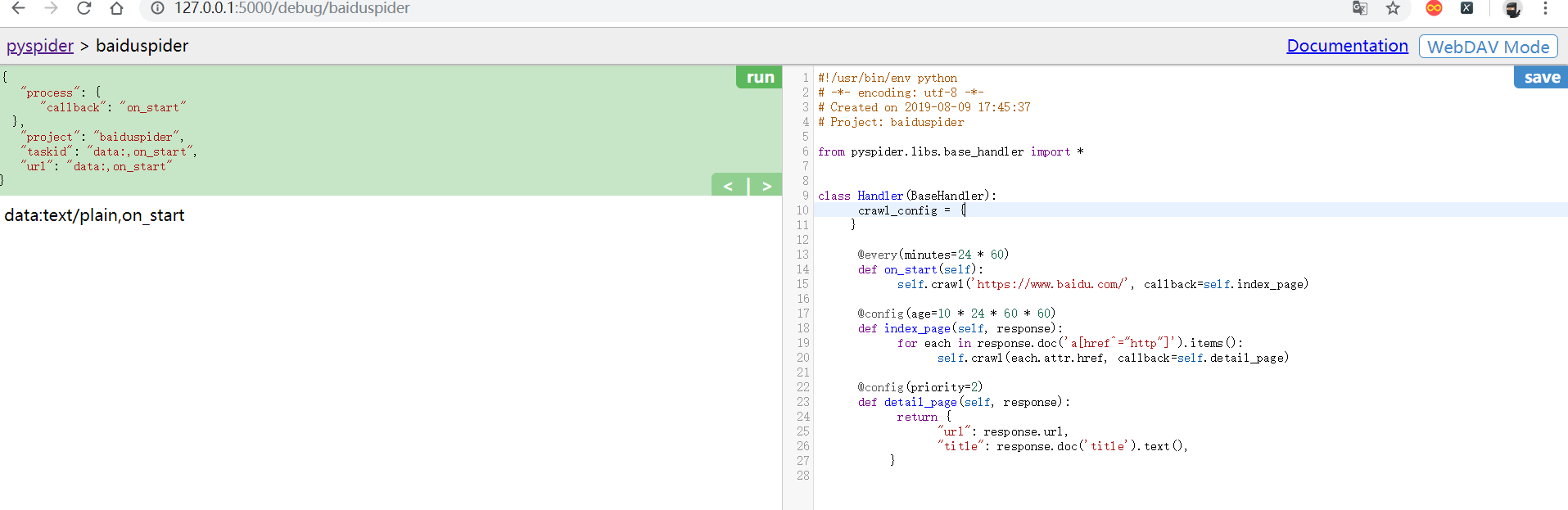
在上面的页面中:
- 左侧为代码调试界面
- RUN为单步调试爬虫程序,
- 左侧下半部分可以预览当前的爬虫页面
- 右侧部分为代码编辑和保存
在创建好项目时。pyspider 就已经帮我生成了一小段代码(右侧部分),这里的 Handler 就是 pyspider 爬虫的主类。可以在这里定义爬虫 / 解析 / 存储的逻辑,整个爬虫只需要一个 Handler 就可以完成
在 Handler 类中:
crawl_config -- 这个类属性可以将整个项目的配置统一写在这个(代理 等),配置之后全局生效
on_start() -- 这是爬虫入口,初时的爬取请求会在这里产生,该方法通过调用crawl() 方法即可新建一个爬取请求,它的第一个参数为爬取的 URL,这里会自动生成为创建项目时输入的 URL,crawl() 还有有一个参数为 callback,它指定了这个页面爬取完毕后使用哪个方法进行解析
index_page() -- 结合上面代码。发现。on_start() 方法。爬取结束后。将 response 交给 index_page()解析。index_page() 对接了 pyquery,直接使用 doc()来解析页面,解析后进行了便利。调用了 crawl() 方法。又生成了新的爬取请求,同时又指定了 callback
detail_page() -- 同样接收了 response 作为参数。detail_page() 爬取的是详情页的信息,就不会产生新的请求,只对response 对象做解析,解析之后将结果以字典的形式返回
在点击 RUN 时。如果出现了报错:
HTTP 599: SSL certificate problem: self signed certificate in certificate chain
在 crawl 方法中加入忽略证书验证的参数,validate_cert=False

如果出现了:
[E 160329 14:00:56 base_handler:194] crawl() got unexpected keyword argument: ['validate_cert']
无法匹配到 validate_cert 参数,那么则是 PySpider 本身的问题,可以在GitHub下载0.4.0版本
https://github.com/binux/pyspider
下载完毕后进行解压。将 pyspider 下的所有文件目录 更新到之前的 pyspider 中
如果。出现了web 预览页面大小问题。可以在 C:\Python36\Lib\site-packages\pycparser\webui\static\debug.min.css 中 找到 iframe ,将其替换为 iframe{border-width:0;width:100%;height:900px !important}
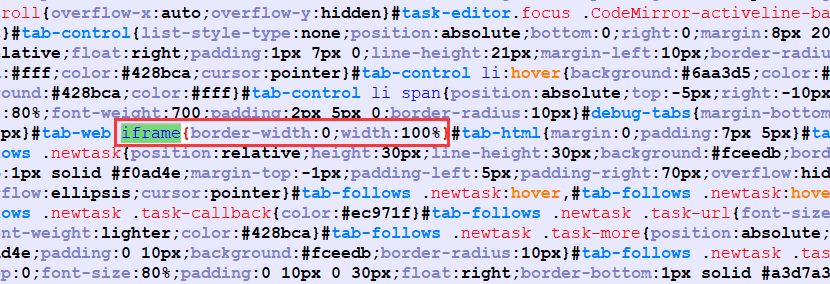
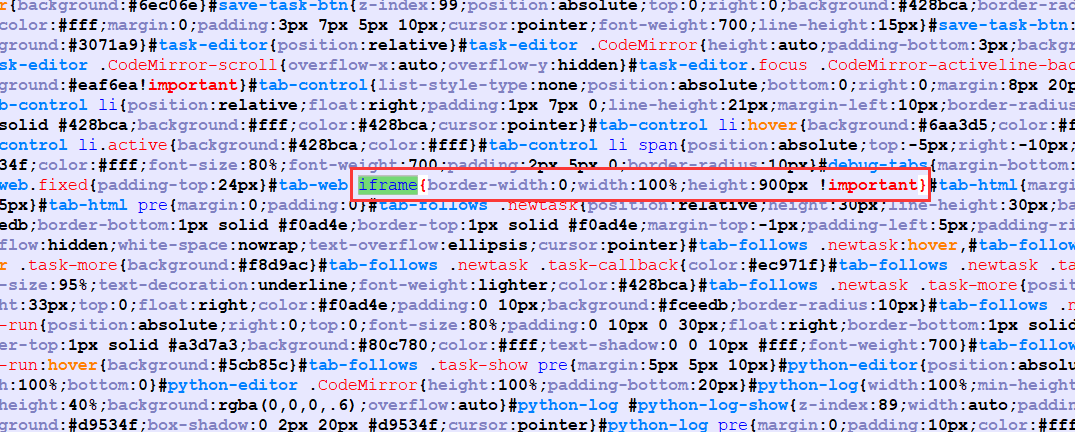
更改完毕后。清空浏览器缓存,重启浏览器即可。
案列:
以去哪网为案列
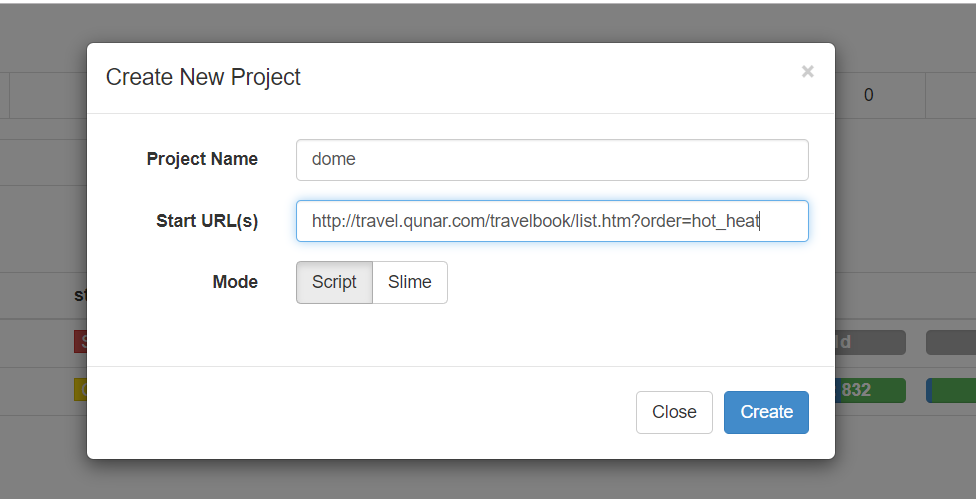
点击RUN。调用on_start()方法。生成新的请求(follows提示),点击follows,在点击小箭头。发起请求
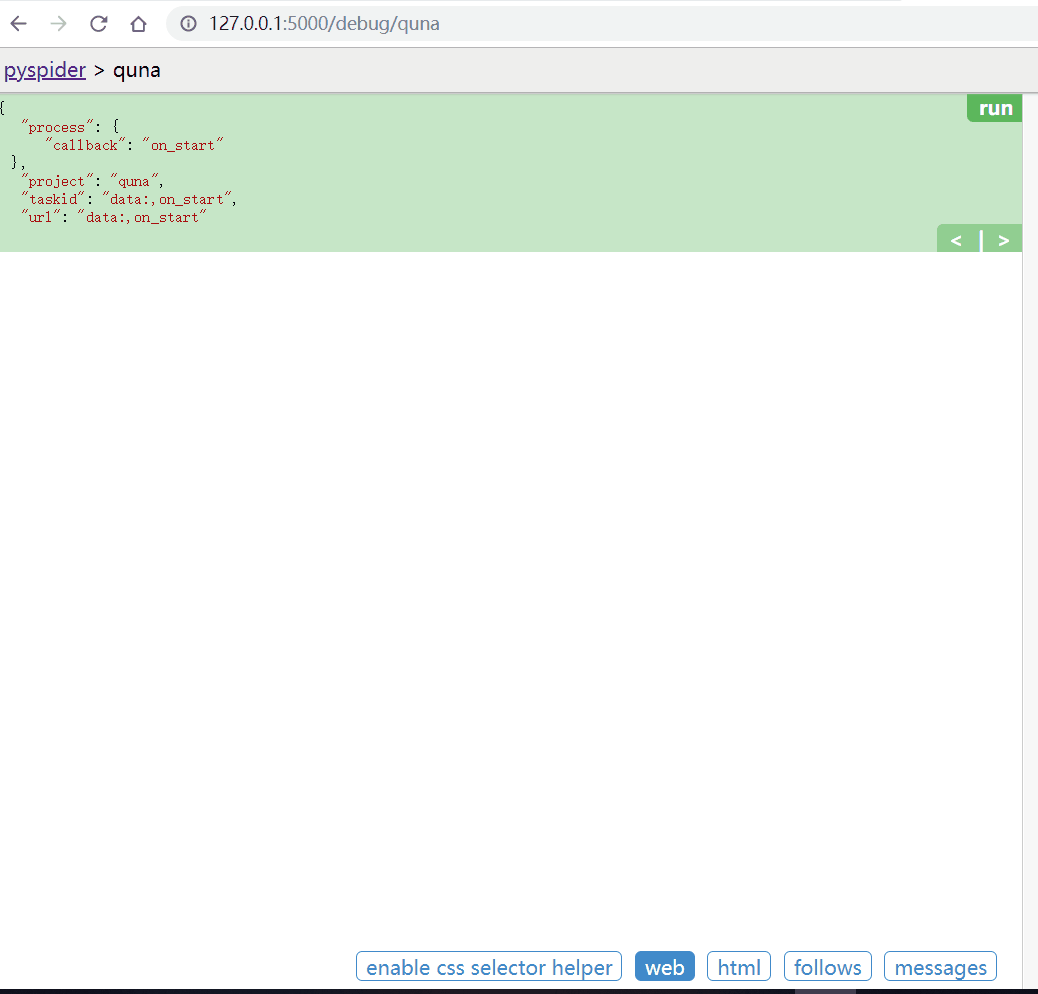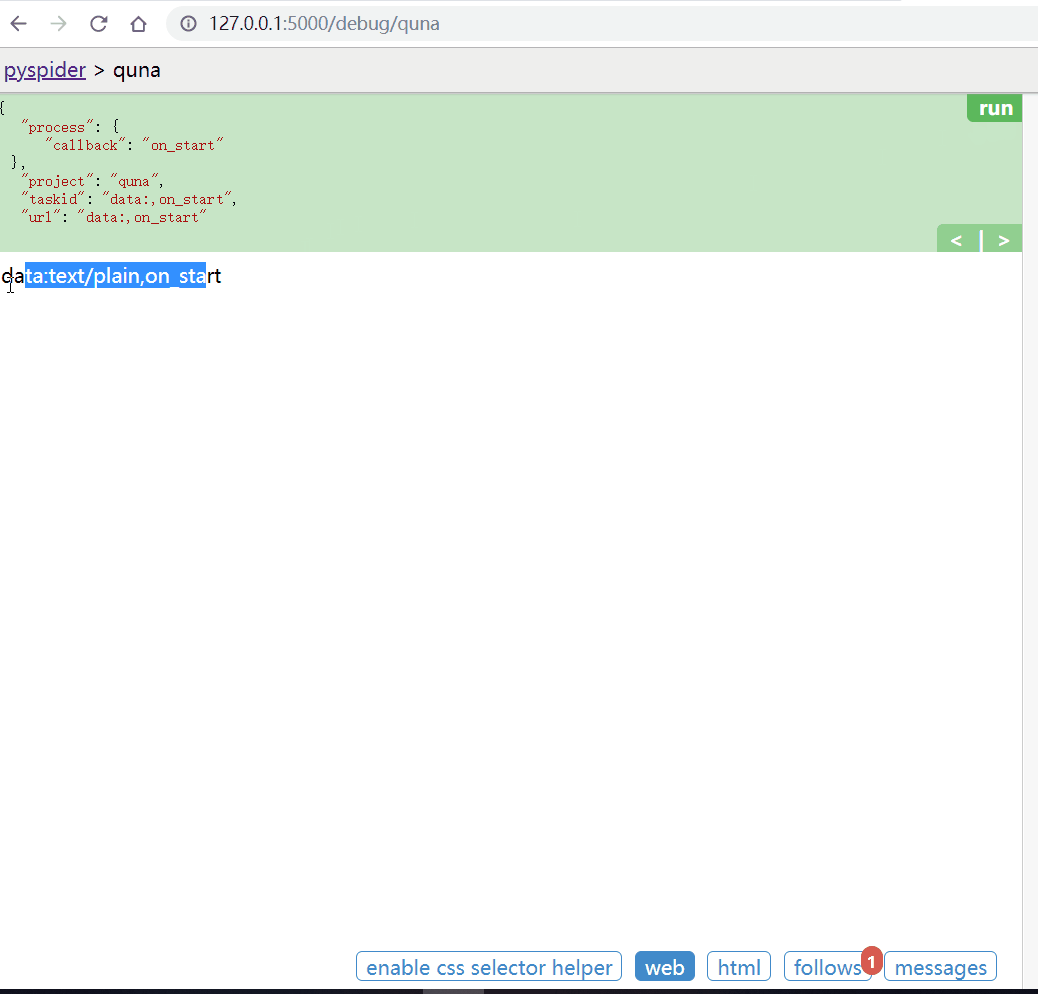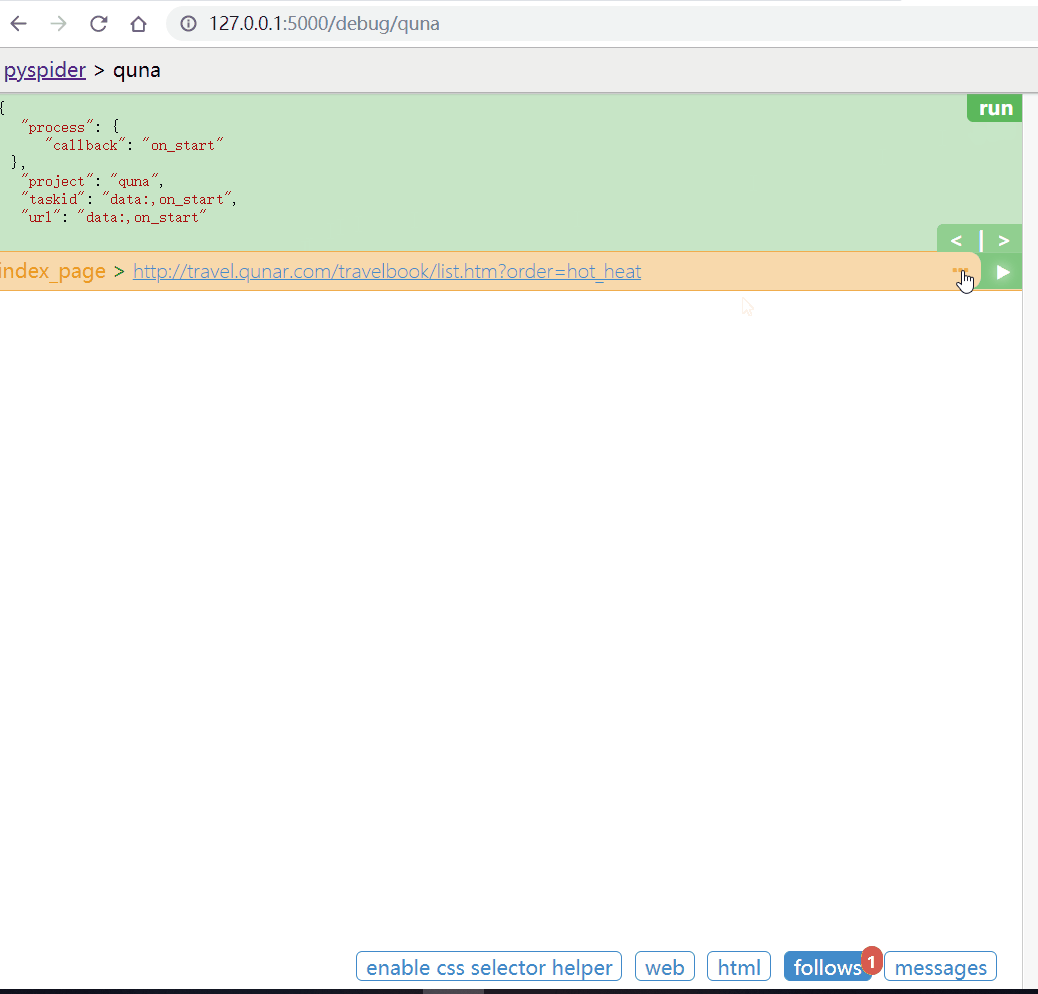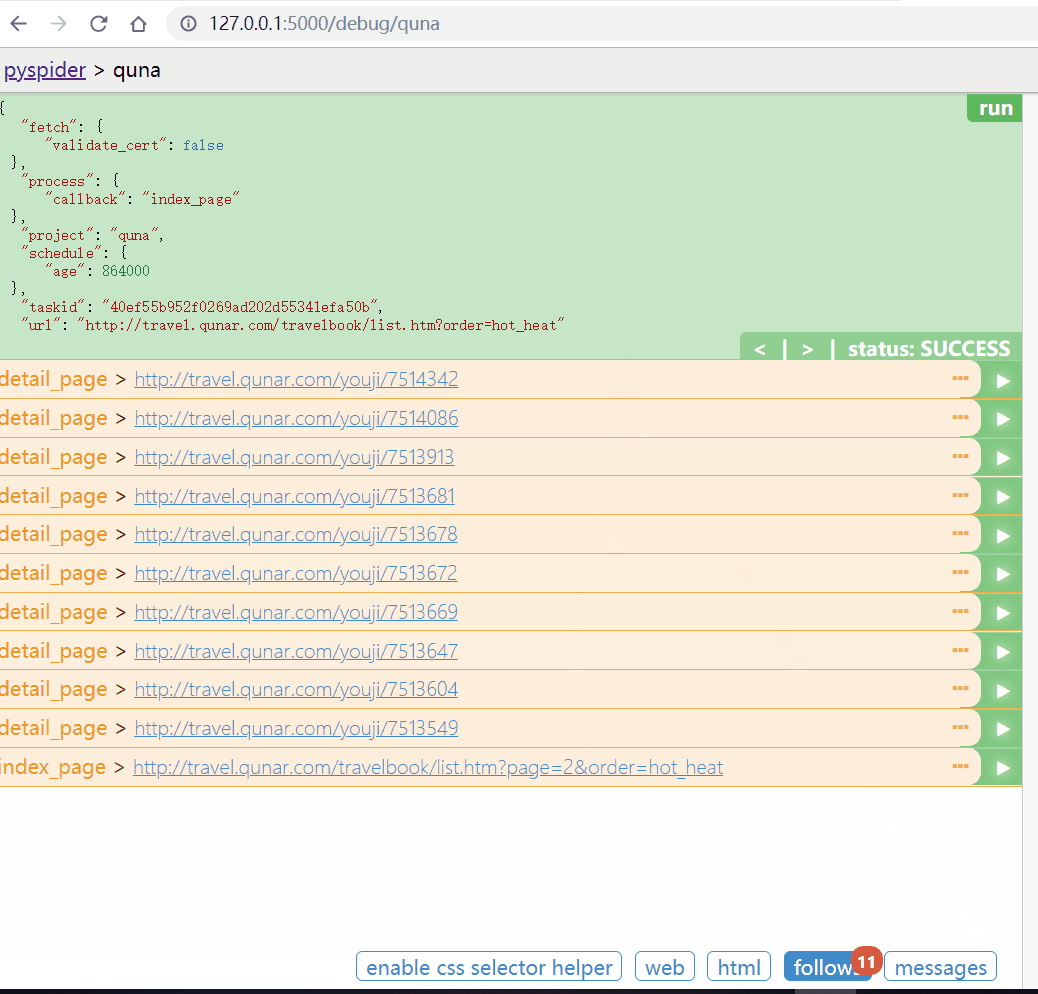
可以点击web / html 预览页面和查看源代码
可以使用spider 提供的 CSS选择器来定位某个标签。来进行查找内容
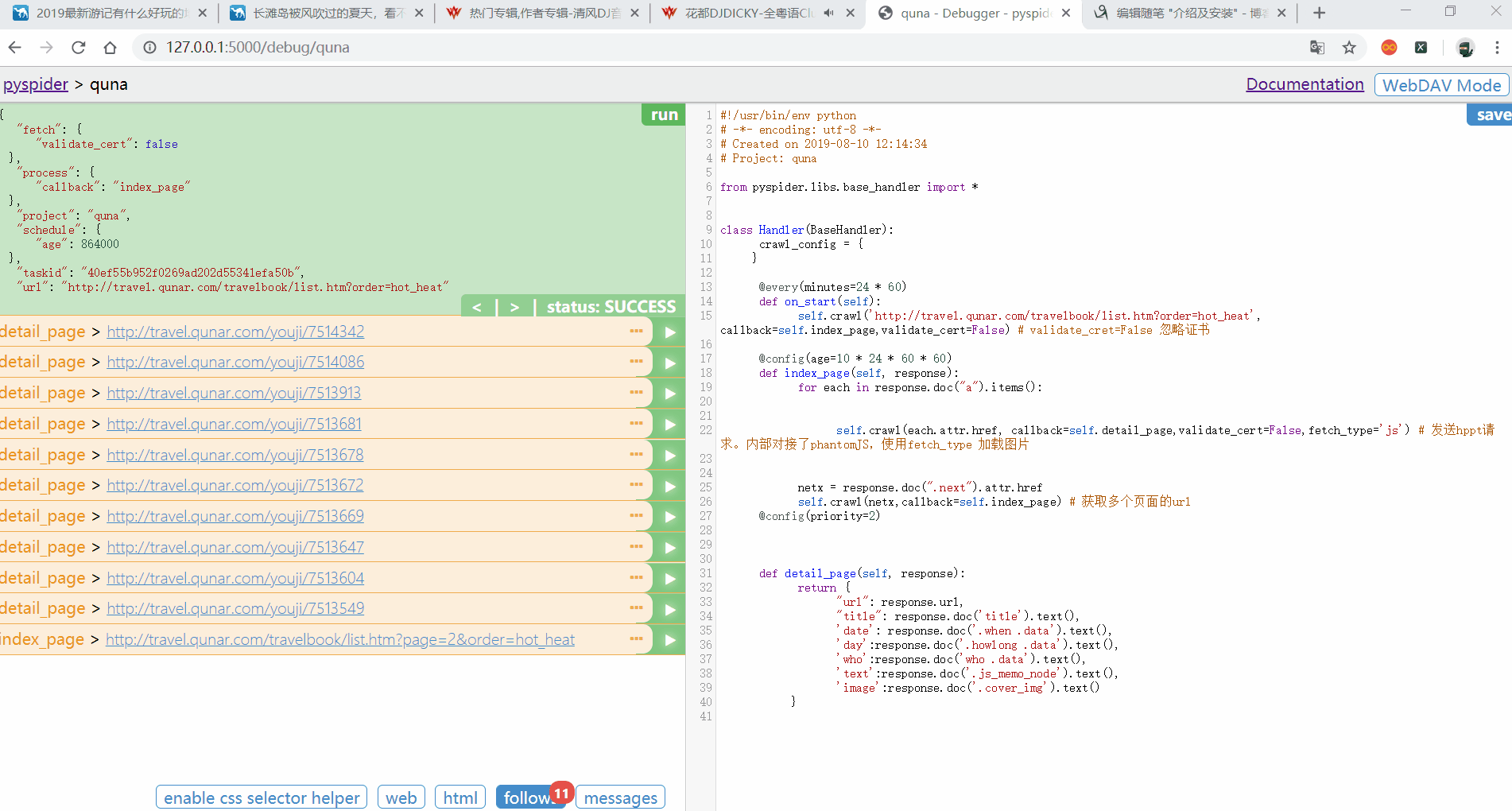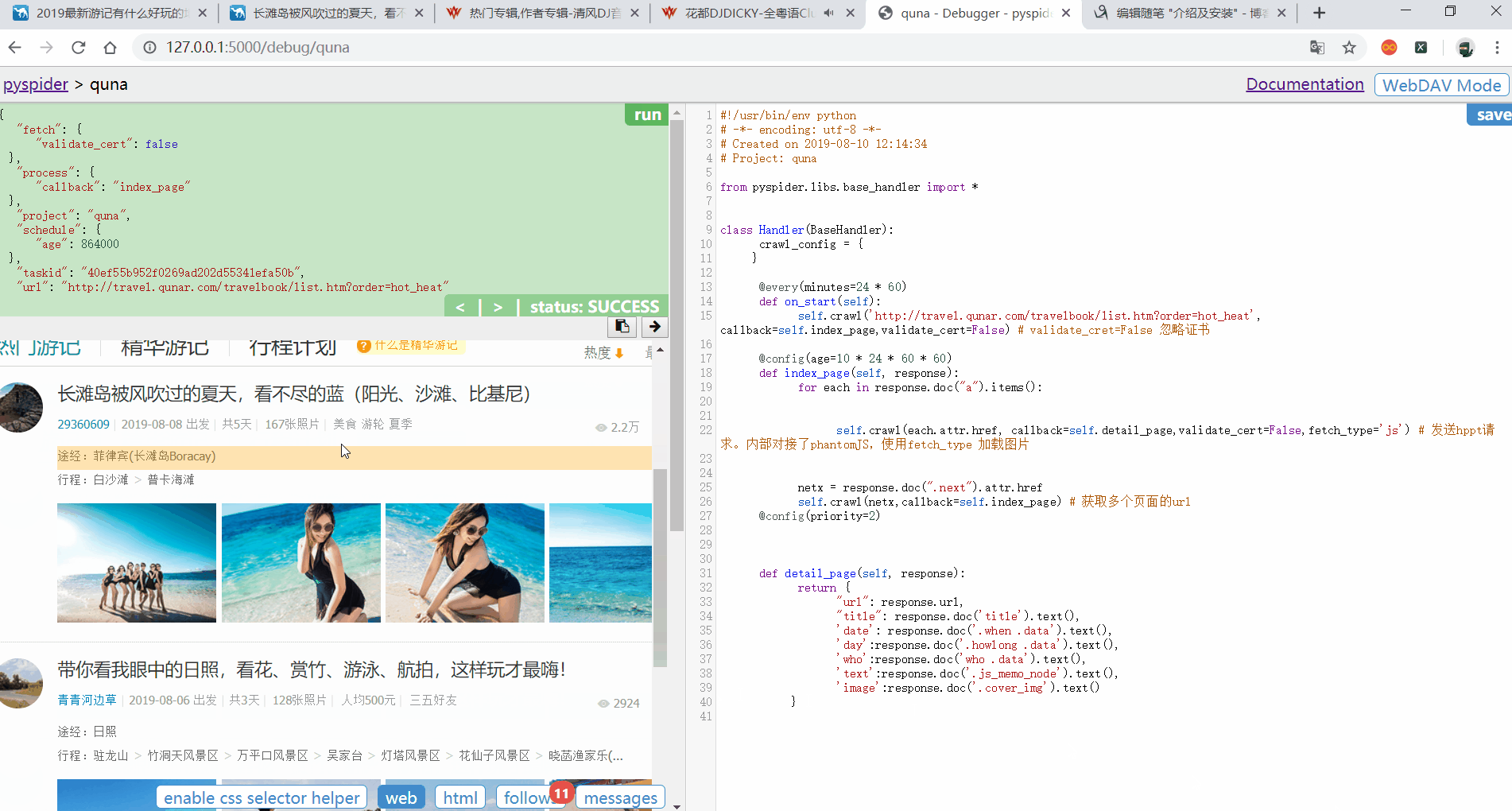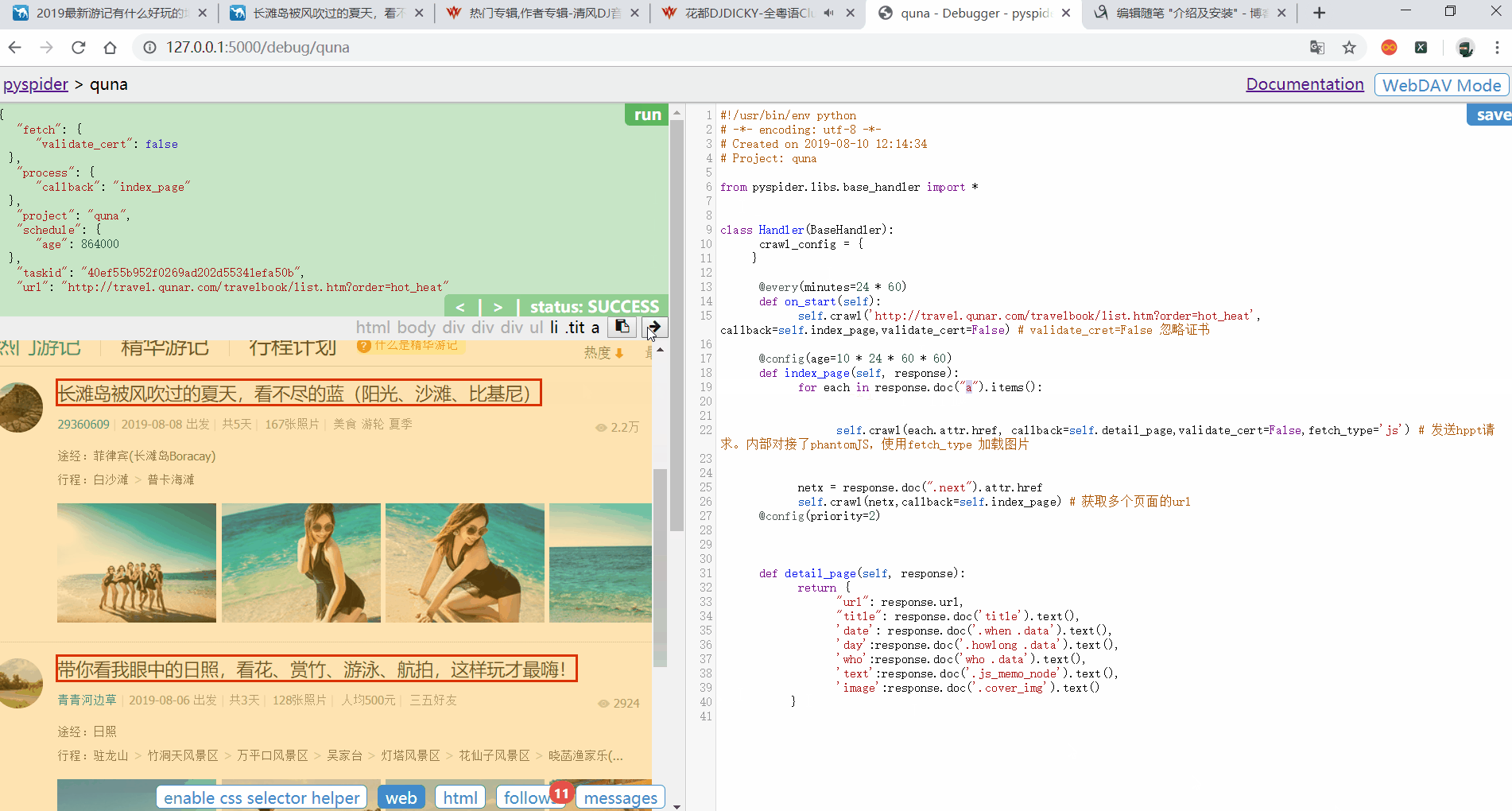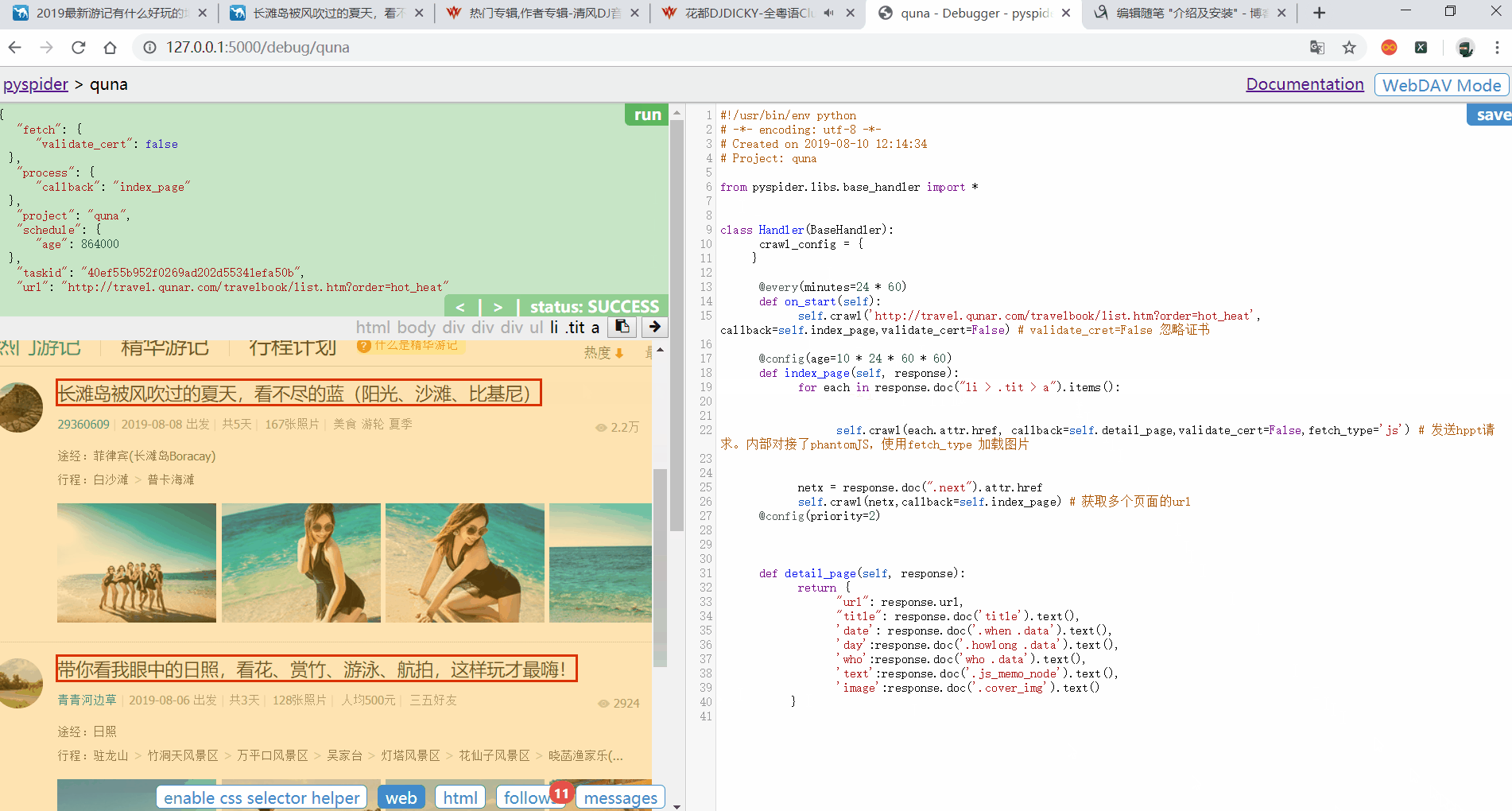
点击Save后。点击RUN,获取当前页面的所有URL(代码之前写好的。会出现不同现象)
由于要获取多个页面的信息。所以在代码部分。需要添加,会看到最有最后一条是第二页的URL
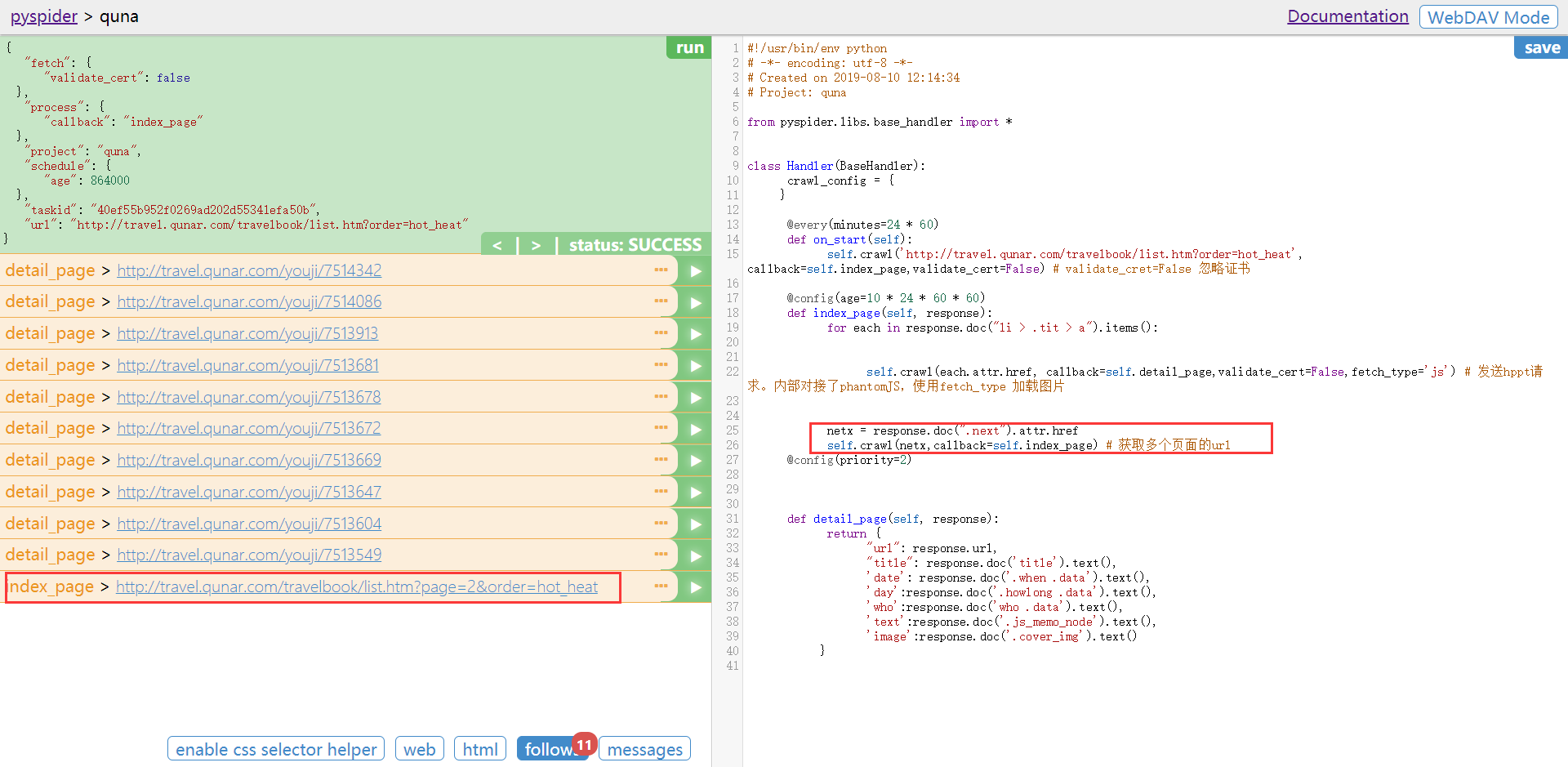
点击其中的某一条后的小箭头。点击RUN。返回详情页的信息
利用CSS选择器进行定位。在 detail_page 方法中进行获取详细信息
在项目首页中可以看到下面所展示
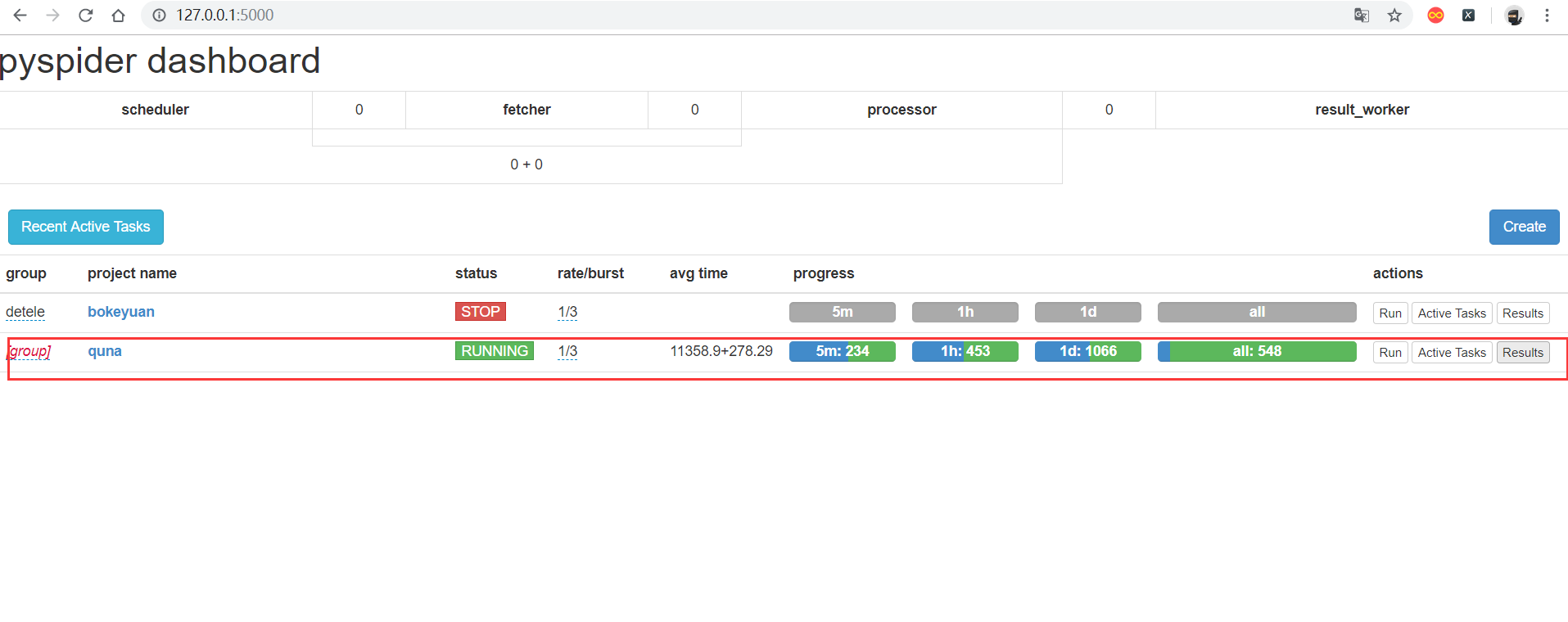
- group :定义分组。方便管理
- rate / burst :代表当前的爬取速率,rate代码一秒发出多少个请求,burst相当于流量控制中的令牌算法的令牌数量。rate / burst 越大。爬取速率越快。
- progress :5m / 1h / 1d 代表最近5分钟 / 1小时 / 一天内的请求情况。all 代表所有的请求情况,颜色不同代表不同的状态,蓝色代表等待被执行的请求,绿色代表成功的请求,黄色代表请求失败后等在重试的请求,红色代表失败次数过多而被忽略的请求
- run :执行
- Actice Tasks :查看最近请求的详细情况
- Result :查看爬取结果
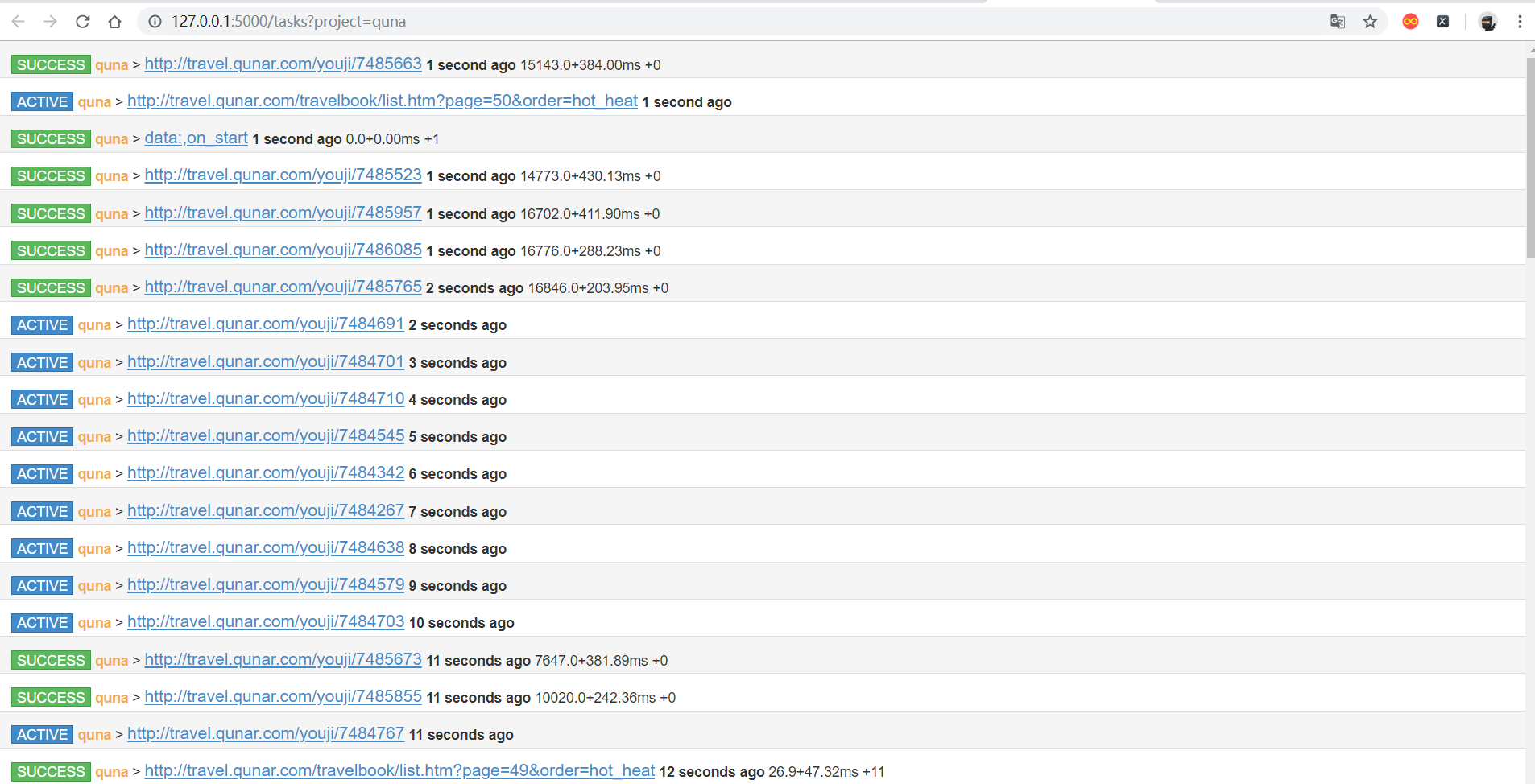

以上就是pyspider 的使用
Pyspider的简单介绍和初使用的更多相关文章
- K8S Kubernetes 简单介绍 转自 http://time-track.cn/kubernetes-trial.html Kubernetes初体验
这段时间学习了一下 git jenkins docker 最近也在看 Kubernetes 感觉写得很赞 也是对自己对于K8S 有了进一步得理解 感谢 倪 大神得Blog 也希望看到这篇Bl ...
- 简单介绍一下R中的几种统计分布及常用模型
统计学上分布有很多,在R中基本都有描述.因能力有限,我们就挑选几个常用的.比较重要的简单介绍一下每种分布的定义,公式,以及在R中的展示. 统计分布每一种分布有四个函数:d――density(密度函数) ...
- 【转载】JMeter学习(一)工具简单介绍
JMeter学习(一)工具简单介绍 一.JMeter 介绍 Apache JMeter是100%纯JAVA桌面应用程序,被设计为用于测试客户端/服务端结构的软件(例如web应用程序).它可以用来测试静 ...
- JMeter学习工具简单介绍
JMeter学习工具简单介绍 一.JMeter 介绍 Apache JMeter是100%纯JAVA桌面应用程序,被设计为用于测试客户端/服务端结构的软件(例如web应用程序).它可以用来测试静态 ...
- Pyspider爬虫简单框架——链家网
pyspider 目录 pyspider简单介绍 pyspider的使用 实战 pyspider简单介绍 一个国人编写的强大的网络爬虫系统并带有强大的WebUI.采用Python语言编写,分布式架构, ...
- Java泛型使用的简单介绍
目录 一. 泛型是什么 二. 使用泛型有什么好处 三. 泛型类 四. 泛型接口 五. 泛型方法 六. 限定类型变量 七. 泛型通配符 7.1 上界通配符 7.2 下界通配符 7.3 无限定通配符 八. ...
- [原创]关于mybatis中一级缓存和二级缓存的简单介绍
关于mybatis中一级缓存和二级缓存的简单介绍 mybatis的一级缓存: MyBatis会在表示会话的SqlSession对象中建立一个简单的缓存,将每次查询到的结果结果缓存起来,当下次查询的时候 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(4) NumPy基础: ndarray简单介绍
一.NumPy 是什么 NumPy 是 Python 科学计算的基础包,它专为进行严格的数字处理而产生.在之前的随笔里已有更加详细的介绍,这里不再赘述. 利用 Python 进行数据分析(一)简单介绍 ...
随机推荐
- netty权威指南学习笔记一——NIO入门(3)NIO
经过前面的铺垫,在这一节我们进入NIO编程,NIO弥补了原来同步阻塞IO的不足,他提供了高速的.面向块的I/O,NIO中加入的Buffer缓冲区,体现了与原I/O的一个重要区别.在面向流的I/O中,可 ...
- 【转】R语言函数总结
原博: R语言与数据挖掘:公式:数据:方法 R语言特征 对大小写敏感 通常,数字,字母,. 和 _都是允许的(在一些国家还包括重音字母).不过,一个命名必须以 . 或者字母开头,并且如果以 . 开头, ...
- 本地登录ftp的时候报530错误
root@instance-iyi104bj:~# ftp localhost Connected to localhost. (vsFTPd ) Name (localhost:root): roo ...
- Mongodb集群形式探究-一主一从一仲裁。
主节点(primary)与从节点(secondary)和仲裁节点(arbiter)具有存储数据的两个成员的三个成员副本集具有: ●一个主节点. ●一个从节点. 从节点可以在选举中成为主节点. ...
- PHP ~ 原生语法 ~ 根据从数据库查询数据之后快速输出 某个属性的值到 到页面
一,根据 id 来查询单个的数据 <?php require_once '../../conn.php'; $sql = "select * from blogarticle wher ...
- Arduino --structure
The elements of Arduino (C++) code. Sketch loop() setup() Control Structure break continue do...whil ...
- iOS延迟执行方法
swift 4.0中dispatch_async,dispatch_after的使用 2018年03月28日 16:15:44 xiao_yuly 阅读数:3576 版权声明:本文为博主原创文章,未经 ...
- jquery散记
感觉jquery的用法都要忘没了,简单捡一下 1.window.onload与$(document).ready的区别 ()编写个数 window.onload = function(){} //不能 ...
- Python __name__="__main__"的作用
该语句加在模块的最后,可以让这个模块,即可以被别人import,又可以直接运行. fibo.py文件: def fibo(): pass # fibo函数的内容 if __name__==" ...
- 51nod 1305:Pairwise Sum and Divide
1305 Pairwise Sum and Divide 题目来源: HackerRank 基准时间限制:1 秒 空间限制:131072 KB 分值: 5 难度:1级算法题 收藏 关注 有这样一段 ...