吴裕雄--天生自然HADOOP操作实验学习笔记:单节点伪分布式安装
实验目的
了解java的安装配置
学习配置对自己节点的免密码登陆
了解hdfs的配置和相关命令
了解yarn的配置
实验原理
1.Hadoop安装
Hadoop的安装对一个初学者来说是一个很头疼的事情,要一步安装好整个hadoop集群难度特别大,所以一个快捷的学习方法是边安装边学习,安装的时候,先搭建单节点伪分布式,然后再搭建完全分布式,最后搭建高可用的分布式集群,如果有兴趣,还可以研究怎么使用CDH搭建超大规模的集群。
安装之前,首先需要懂一个概念:hadoop有三个部分,hdfs、mapreduce、yarn,其中mapreduce就是一堆java的jar包,不需要安装,而hdfs和yarn是需要安装的。伪分布式在一个节点上安装,实际上是将hdfs的namenode、secondary namenode、datanode和yarn的nodemanager、resource manager放在一台节点上。
安装伪分布式的步骤在Hadoop官网上有介绍,我们就按照官网的介绍一步一步来。
首先安装java;
配置当前用户自己对自己的免密码登陆;
安装Hadoop并配置相关配置文件。
2.Hadoop配置文件说明:
1、dfs.hosts 记录即将作为datanode加入集群的机器列表
2、mapred.hosts 记录即将作为tasktracker加入集群的机器列表
3、dfs.hosts.exclude mapred.hosts.exclude 分别包含待移除的机器列表
4、master 记录运行辅助namenode的机器列表
5、slave 记录运行datanode和tasktracker的机器列表
6、hadoop-env.sh 记录脚本要用的环境变量,以运行hadoop
7、core-site.xml hadoop core的配置项,例如hdfs和mapreduce常用的i/o设置等
8、hdfs-site.xml hadoop守护进程的配置项,包括namenode、辅助namenode和datanode等
9、mapred-site.xml mapreduce守护进程的配置项,包括jobtracker和tasktracker
10、hadoop-metrics.properties 控制metrics在hadoop上如何发布的属性
11、log4j.properties 系统日志文件、namenode审计日志、tasktracker子进程的任务日志的属性
3.格式化HDFS文件系统
在能够使用之前,全新的HDFS安装需要进行格式化。通过创建存储目录和初始版本的namenode持久数据结构,格式化进程将创建一个空的文件系统。由于namenode管理所有的文件系统元数据,datanode可以动态加入和离开集群。所以初始的格式化进程不涉及到datanode。同样原因,创建文件系统时也无需指定大小,这是有集群中的datanode数目决定的,在文件系统格式化之后的很长时间内都可以根据需要增加。
格式化HDFS是一个快速操作。以hdfs用户身份运行一下命令:
hdfs namenode -format
4.启动和停止守护进程
Hadoop自带脚本。可以运行命令并在整个集群范围内启动和停止守护进程。为使用这些脚本(在sbin目录下),需要告诉Hadoop集群中有哪些机器。文件slaves正式用于此目的,该文件包含了机器主机名或IP地址的列表,每行代表一个机器信息。文件slaves列举了可以运行的datanode和节点管理器的机器。文件驻留在Hadoop配置目录下,尽管通过修改hadoop-env.sh中的HADOOP_SLAVES设置可能会将文件放在别的地方(并赋予一个别的名称)。并且,不需要将该文件分发给工作节点,因为仅有运行在namenode和资源管理器上的控制脚本使用它。
1)以HDFS用户身份运行以下命令可以启动HDFS守护进程:
start-dfs.sh
namenode和辅助namenode运行所在的机器通过向Hadoop配置询问机器主机名来决定。通过以下命令,脚本能够找到namenode的主机名。
hdfs getconf -namenodes
默认情况下,该命令从fs.defaultFS中找到namenode的主机名。更具体一些,start-dfs.sh脚本所做的事情如下:
1.在每台机器上启动一个namenode,这些机器由执行hdfs getconf -namenodes得到的返回值所确定。
2.在slaves文件列举的每台机器上启动一个datanode。
3.在每台机器上启动一个辅助namenode,这些由执行hdfs get conf-secondarynamenodes得到的返回值所确定。
2)YARN守护进程以相同方式启动,通过以yarn用户的身份在托管资源管理器的机器上运行以下 命令:
start-yarn.sh
这种情况下,资源管理器总是和start-yarn.sh脚本运行在同意机器上。脚本明确完成以下事情:
1.在本地机器上启动一个资源管理器。
2.在slaves文件列举的每台机器上启动一个节点管理器。
同样,还提供了stop-dfs.sh和stop-yarn.sh脚本用于停止由相应的启动脚本启动的守护进程。
实验环境
1.操作系统
操作机1:Linux_Centos
操作机2:Windows_7
操作机1默认用户名:root,密码:123456
操作机2默认用户名:hongya,密码:123456
步骤1:使用xshell进行连接
1.1进入操作机2,点击xshell,新建会话。
名称:standalone
主机:90.10.10.42
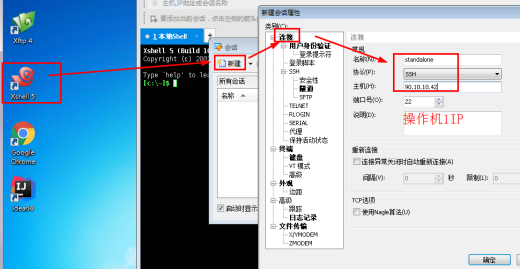
1.2点击“用户身份验证”,输入用户名和密码,点击确定。
用户名:root
密码:123456

1.3会话已经建立,选中之后,点击“连接”。可以看到连接成功。

步骤2:添加映射,免密码登陆
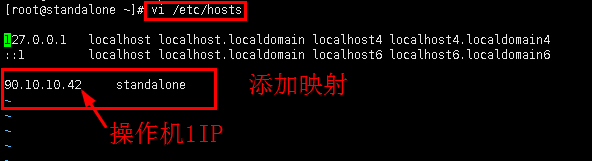
2.1添加映射。
vi /etc/hosts
2.2免密码登陆。
ssh-keygen
输入后,会提示创建.ssh/id_rsa、id_rsa.pub的文件,其中第一个为密钥,第二个为公钥。过程中会要求输入密码,为了ssh访问过程无须密码,可以直接回车 。
将公钥写入standalone认证文件。
ssh-copy-id standalone

步骤3:解压安装Hadoop,配置Hadoop-env.sh
3.1首先解压安装包,并将其复制到/home/hadoop/tmp/目录下。
tar -zxvf /opt/pkg/hadoop-2.6.0-cdh5.5.2.tar.gz -C /home/hadoop/tmp/

3.2进入配置文件目录,在hadoop安装目录的/etc/hadoop下。
cd /home/hadoop/tmp/hadoop-2.6.0-cdh5.5.2/etc/hadoop
ls

3.3修改hadoop-env.sh配置。
vim hadoop-env.sh
修改JDK路径为:
export JAVA_HOME=/home/hadoop/tmp/soft/jdk1.8.0_121

保存退出。
步骤4:配置hdfs并启动
4.1在相同目录下,我们修改core-site.xml的配置。
vim core-site.xml
添加内容:
<property>
<!-- 配置集群的地址,这个standalone是本地ip -->
<name>fs.defaultFS</name>
<value>hdfs://standalone:9000</value>
</property>
<property>
<!-- hadoop数据存放目录,修改为用户目录下不存在的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/data/hadoop</value>
</property>
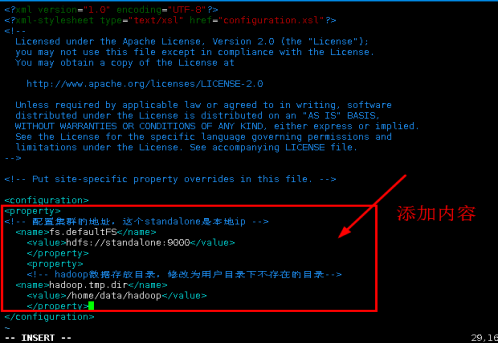
保存退出。
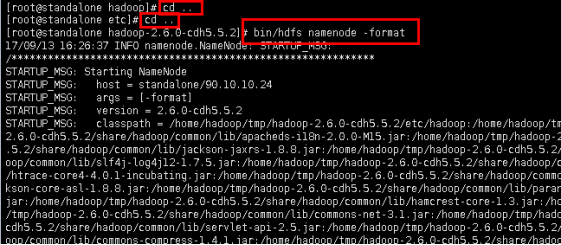
4.2进入hadoop安装目录,如果是第一次启动,需要先格式化namenode(注意,namenode只能格式化一次,在bin目录下执行)
cd ..
退回到Hadoop目录下
cd ..
格式化namenode
bin/hdfs namenode -format
4.3在sbin目录下启动HDFS。
sbin/start-dfs.sh
查看进程
jps
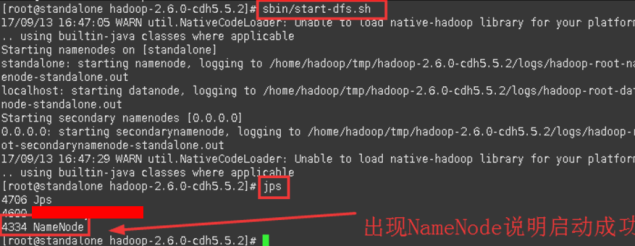
4.4等待启动完成后,就可以配置yarn了,在配置之前先去浏览器页面检查HDFS是否启动成功,输入namenode的ip+端口号50070。实验中操作机1 的IP为:90.10.10.42(以实验IP为准)。
输入URL:90.10.10.42:50070

出现这个页面代表hdfs安装成功。
步骤5:配置yarn并验证
5.1进入配置目录etc/hadoop/,查看mapred配置文件,发现没有mapred-site.xml。
进入安装目录
cd etc/hadoop
查看
ls
显示当前路径
pwd

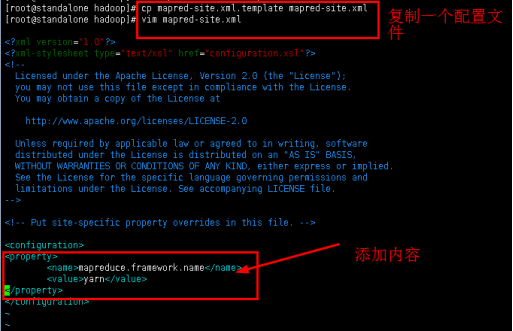
5.2复制配置文件并命名为mapred-site.xml,然后修改配置文件。
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
添加内容:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
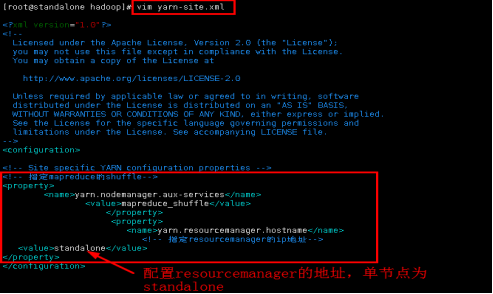
5.3修改yarn-site.xml的配置内容。
vim yarn-site.xml
添加内容:
<!-- 指定mapreduce的shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定resourcemanager的ip地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>standalone</value>
</property>
5.4启动yarn。
进入Hadoop安装目录
cd ../..
sbin目录下启动yarn命令
sbin/start-yarn.sh

5.5等待启动完成后,就可以去浏览器页面检查是否启动成功,输入刚刚节点的ip:8088,实验中操作机1 的IP为:90.10.10.42。
输入URL:90.10.10.42:8088

出现这个界面代表yarn启动成功。
吴裕雄--天生自然HADOOP操作实验学习笔记:单节点伪分布式安装的更多相关文章
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase学生选课案例
实验目的 复习hbase的shell操作和javaAPI操作 了解javaWeb项目的MVC设计 学会dao(数据库访问对象)和service层的代码编写规范 学会设计hbase表格 实验原理 前面我 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase的javaAPI应用
实验目的 进一步了解hbase的操作 熟悉使用IDEA进行java开发 熟悉hbase的javaAPI 实验原理 前面已经了解通过hbase的shell操作hbase,确实比较难以使用,另外通过hiv ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce和yarn命令
实验目的 了解集群运行的原理 学习mapred和yarn脚本原理 学习使用Hadoop命令提交mapreduce程序 学习对mapred.yarn脚本进行基本操作 实验原理 1.hadoop的shel ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:pig简介
实验目的 了解pig的该概念和原理 了解pig的思想和用途 了解pig与hadoop的关系 实验原理 1.Pig 相比Java的MapReduce API,Pig为大型数据集的处理提供了更高层次的抽象 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:安装zookeeper集群
实验目的 了解zookeeper的概念和原理 学会安装zookeeper集群并验证 掌握zookeeper命令使用 实验原理 1.Zookeeper介绍 ZooKeeper是一个分布式的,开放源码的分 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:hbase微博案例
实验目的 熟悉hbase表格设计的方法 熟悉hbase的javaAPI 通过API理解掌握hbase的数据的逻辑视图 了解MVC的服务端设计方式 实验原理 上次我们已经初步设计了学生选课案例的,具体功 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:使用hive操作hbase
实验目的 熟悉hive和hbase的操作 熟悉hadoop.hbase.hive.zookeeper的关系 熟练大数据环境的搭建 学会分析日志排除问题 实验原理 1.hive整合hbase原理 前面大 ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:mapreduce代码编程
实验目的 深入了解mapreduce的底层 了解IDEA的使用 学会通过本地和集群环境提交程序 实验原理 1.回忆mapreduce模型 前面进行了很多基础工作,本次实验是使用mapreduce的AP ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:分布式及RPC通信简介
实验目的 掌握GOF设计模式的代理模式 了解掌握socket编程.java反射.动态代理 了解NIO.多线程 掌握hadoop的RPC框架使用API 实验原理 1.什么是RPC 在hadoop出现以前 ...
随机推荐
- 【前端之BOM和DOM】
" 目录 #. window对象介绍 #. window子对象 1. 浏览器对象 navigator 2. 屏幕对象 screen 3. 历史 history 4. 地址(URL) loc ...
- python练习:编写一个程序,要求用户输入一个整数,然后输出两个整数root和pwr,满足0<pwr<6,并且root**pwr等于用户输入的整数。如果不存在这样一对整数,则输入一条消息进行说明。
python练习:编写一个程序,要求用户输入一个整数,然后输出两个整数root和pwr,满足0<pwr<6,并且root**pwr等于用户输入的整数.如果不存在这样一对整数,则输入一条消息 ...
- C语言:求n(n<10000)以内的所有四叶玫瑰数。-将字符串s1和s2合并形成新的字符串s3,先取出1的第一个字符放入3,再取出2的第一个字符放入3,
//函数fun功能:求n(n<10000)以内的所有四叶玫瑰数并逐个存放到result所指数组中,个数作为返回值.如果一个4位整数等于其各个位数字的4次方之和,则称该数为函数返回值. #incl ...
- Leader:这样的 Bug 你也写的出来???
Hello~各位读者新年好!不知道大家春节假期是否已延长,小黑哥刚接到通知,假期延长到 2 月 2 号,另外回去之后需要在家办公,自行隔离两周.还没试过在家办公,小黑哥就怕到时候生物钟还没调整过来,一 ...
- 四种常见的数据结构、LinkedList、Set集合、Collection、Map总结
四种常见的数据结构: 1.堆栈结构: 先进后出的特点.(就像弹夹一样,先进去的在后进去的低下.) 2.队列结构: 先进先出的特点.(就像安检一样,先进去的先出来 ...
- Fluent_Python_Part2数据结构,04-text-byte,文本和字节序列
文本和字节序列 人使用文本,计算机使用字节序列 1. 大纲: 字符.码位和字节表述 bytes.bytearray和memoryview等二进制序列的独特特性 全部Unicode和陈旧字符集的编解码器 ...
- HTTP接口调用方式
1.get方式,设置调用方式为get,参数直接在url中包含,直接调用获取返回值即可 2.post方式,content为application/x-www-form-urlencoded ,参数格式 ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 网格系统实例:堆叠的水平
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- 转载和补充:Oracle中的一些特殊字符
oracle通配符,运算符的使用 用于where比较条件的有: 等于:=.<.<=.>.>=.<> 包含:in.not in exists.not exists 范 ...
- request库解析中文
官网地址: http://cn.python-requests.org/zh_CN/latest/ 高级用法 本篇文档涵盖了 Requests 的一些高级特性. 会话对象 会话对象让你能够跨请求保持某 ...