[ICRA 2019]Multi-Task Template Matching for Object Detection, Segmentation and Pose Estimation Using Depth Images
简介
创新点

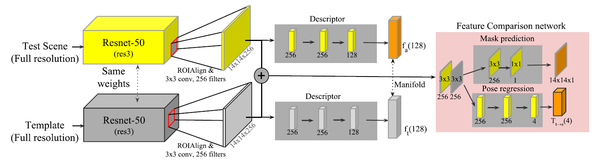
方法
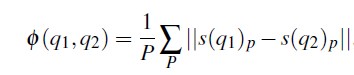
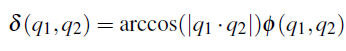
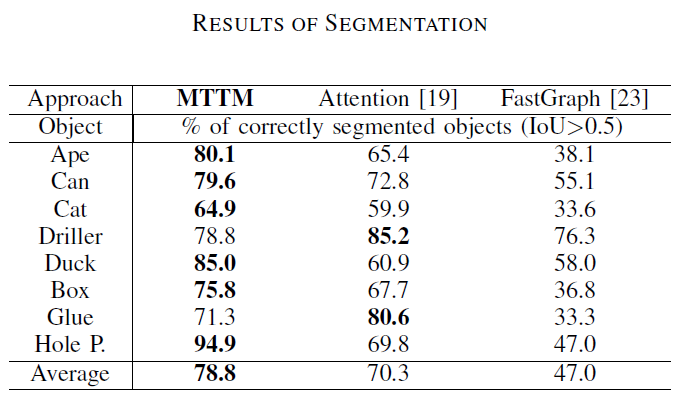
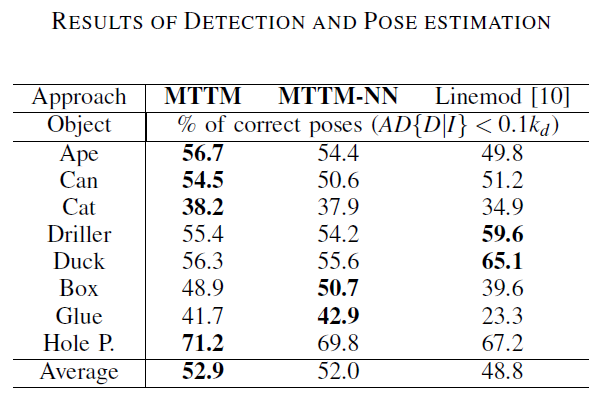
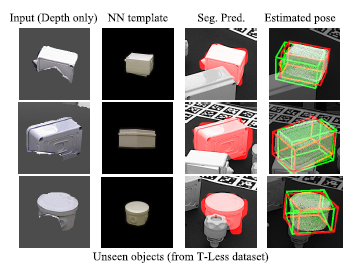
实验和结果


[ICRA 2019]Multi-Task Template Matching for Object Detection, Segmentation and Pose Estimation Using Depth Images的更多相关文章
- OpenCV Template Matching Subpixel Accuracy
OpenCV has function matchTemplate to easily do the template matching. But its accuracy can only reac ...
- [ICCV 2019] Weakly Supervised Object Detection With Segmentation Collaboration
新在ICCV上发的弱监督物体检测文章,偷偷高兴一下,贴出我的poster,最近有点忙,话不多说,欢迎交流- https://arxiv.org/pdf/1904.00551.pdf http://op ...
- ICRA 2019最佳论文公布 李飞飞组的研究《Making Sense of Vision and Touch: Self-Supervised Learning of Multimodal Representations for Contact-Rich Tasks》获得了最佳论文
机器人领域顶级会议 ICRA 2019 正在加拿大蒙特利尔举行(当地时间 5 月 20 日-24 日),刚刚大会公布了最佳论文奖项,来自斯坦福大学李飞飞组的研究<Making Sense of ...
- 读论文系列:Object Detection NIPS2015 Faster RCNN
转载请注明作者:梦里茶 Faster RCNN在Fast RCNN上更进一步,将Region Proposal也用神经网络来做,如果说Fast RCNN的最大贡献是ROI pooling layer和 ...
- 论文阅读笔记五十三:Libra R-CNN: Towards Balanced Learning for Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1904.02701.pdf github:https://github.com/OceanPang/Libra_R-CNN 摘要 相比模型的结构 ...
- 读论文系列:Object Detection ICCV2015 Fast RCNN
Fast RCNN是对RCNN的性能优化版本,在VGG16上,Fast R-CNN训练速度是RCNN的9倍, 测试速度是RCNN213倍:训练速度是SPP-net的3倍,测试速度是SPP-net的3倍 ...
- Viola–Jones object detection framework--Rapid Object Detection using a Boosted Cascade of Simple Features中文翻译 及 matlab实现(见文末链接)
ACCEPTED CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION 2001 Rapid Object Detection using a B ...
- object detection 总结
1.基础 自己对于YOLOV1,2,3都比较熟悉. RCNN也比较熟悉.这个是自己目前掌握的基础2.第一步 看一下2019年的井喷的anchor free的网络3.第二步 看一下以往,引用多的网路4. ...
- 论文阅读之 DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation
DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation Xia ...
随机推荐
- webpack在用dev-server的时候怎么配置多入口文件
类似下面这样就可以了,entry设置为对象 每个入口设置为属性,属性的值是一个数组,就可以像单入口一样往这个数组添加entry: { Profile: [ 'webpack-dev-server/cl ...
- wxpython(2)--按钮,位图按钮,滑动块,微调控制器
本文介绍按钮,位图按钮,滑动块,微调控制器**.. 按钮 基本按钮 创建一个按钮,绑定点击事件,点击后修改Label 123456789101112131415161718 import wx cla ...
- Sed 实记 · laoless's Blog
sed编辑命令 p 打印匹配行 = 打印文件行号 a 在定位行之后追加文本 i 在定位行之前插入文本 d 删除定位行 c 用新文本替换定位文本 s 使用替换模式替换相应模式 r 从另一个文件读取文本 ...
- C2C的道德边界:沦为从假运单到假病条的供假渠道
你可能刚开始学会不去看网购平台上商品回评中的虚假好评,却又要开始应对同事在朋友圈等平台买来的虚开病假条带来的困扰.最近各大媒体包括党报热传的网购病假条事件,再度将人们的目光集中在这个C2C模式之上.从 ...
- Unity中使用C#的null条件运算符?.的注意事项
Introduction: 在C#6及以上版本中,加入了一项特别好用的运算符:Null条件运算符?.和?[]可以用来方便的执行判空操作,当运算符左侧操作数不为null时才会进行访问操作,否则直接返回n ...
- Java版飞机订票系统
关注微信公众号:Worldhello 回复 飞机订票系统 可获得系统源代码并可加群讨论交流 数据结构课程设计题目: [飞机订票系统] 通过此系统可以实现如下功能 ...
- Samtec与Neoconix达成合作并和II-VI推出新产品
序言:Samtec近日动作不断, 近日Samtec与Neoconix达成合作并和II-VI推出新产品,以下是详细内容. Samtec与Neoconix签订Neoconix PCBeam 技术授权协议, ...
- 7-8 jmu-python-从列表中删除元素 (15 分)
删除列表中所有符合条件的值. 输入格式: 输入n,代表要测试n次.每次测试:首先,输入1行字符串(字符串内的元素使用空格分隔)然后,输入要删除的元素x. 输出格式: 输出删除元素x后的每行字符串.如果 ...
- Eureka 注册中心看这一篇就够了
服务注册中心是服务实现服务化管理的核心组件,类似于目录服务的作用,主要用来存储服务信息,譬如提供者 url 串.路由信息等.服务注册中心是微服务架构中最基础的设施之一. 在微服务架构流行之前,注册中心 ...
- vue项目按需加载的3种方式
本文重要是路由打包优化: 原理:利用webpack对代码进行分割是懒加载的前提,懒加载就是异步调用组件,需要时候才下载. 1.vue异步组件技术 vue-router配置路由,使用vue的异步组件技术 ...