基于树莓派与YOLOv3模型的人体目标检测小车(一)
项目介绍:
本科毕业选的深度学习的毕设,一开始只是学习了一下YOLOv3模型, 按照作者的指示在官网上下载下来权重,配好环境跑出来Demo,后来想着只是跑模型会不会太单薄,于是想了能不能做出来个比较实用的东西(因为模型优化做不了)。于是乎做一个可以检测人体的可操控移动小车的想法就诞生了。
实现的功能:1. 控制小车行进,并实时检测人体目标。
2. 作为家庭监控,可以将出现在摄像头中的人体目标通过微信发到手机上,并可以人为决定是否通过蜂鸣器发出警报。
大致的工作包括:1. YOLOv3 tiny 模型的训练
2. Darknet模型到tensorflow模型再到NCS(神经计算加速棒)模型的两次转化
3. 小车控制以及视频流直播程序
4. 微信报警程序
一 、环境搭建
一、安装NVIDIA显卡驱动
1.删除旧的驱动。
原来Linux默认安装的显卡驱动不是英伟达的驱动,所以先把旧得驱动删除掉。
sudo apt-get purge nvidia*
2.禁止自带的nouveau nvidia驱动。
2.1 打开配置文件:
sudo gedit /etc/modprobe.d/blacklist-nouveau.conf
2.2填写禁止配置的内容:
blacklist nouveau``options nouveau modeset=0
2.3更新配置文件:
sudo update-initramfs -u
重启电脑!
2.4检查设置
(因为禁止了显卡的驱动,这时你的电脑分辨率会变成800*600,图标格式将会很不和谐,当然通过这个可以看出,是否完成这上面的操作)
lsmod | grep nouveau
*如果屏幕没有输出则禁用nouveau成功
3 正式安装
法一:ppa源安装(原生安装)
1.添加Graphic Drivers PPA
sudo add-apt-repository ppa:graphics-drivers/ppa``sudo apt-get update
2.查看合适的驱动版本:
ubuntu-drivers devices
3.在这里我选择合适的396版本:
sudo apt-get install nvidia-driver-396
重启电脑!
4.安装成功检查:
sudo nvidia-smi``sudo nvidia-settings
*最直接的方法是进入到系统的“软件和更新”,点击进入到“附加驱动”,选择你需要安装的英伟达驱动,然后点击“应用更改”,便能进行安装了。注意的是这个方法适合网速较好的环境下进行。
二、安装CUDA
1、官网下载:https://developer.nvidia.com/cuda-90-download-archive
我的如下:
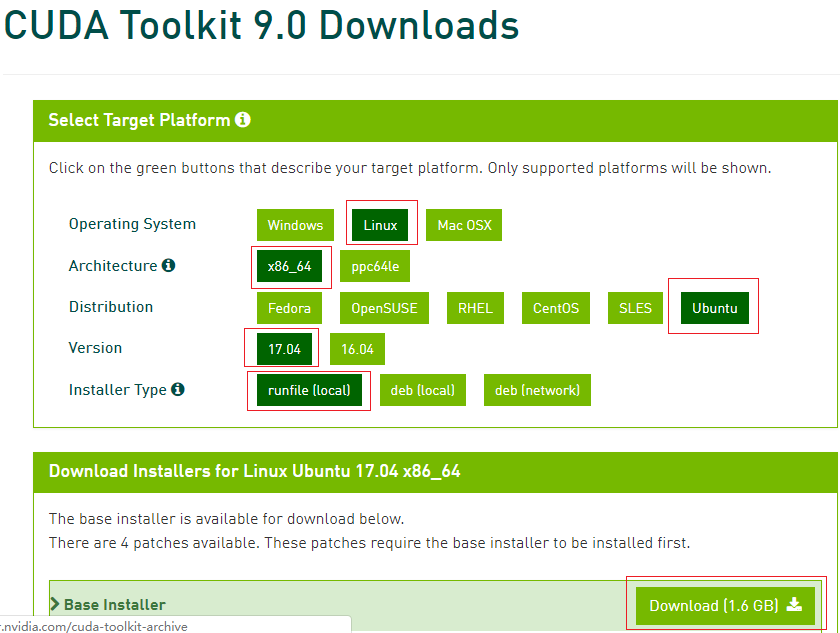
2、安装依赖库
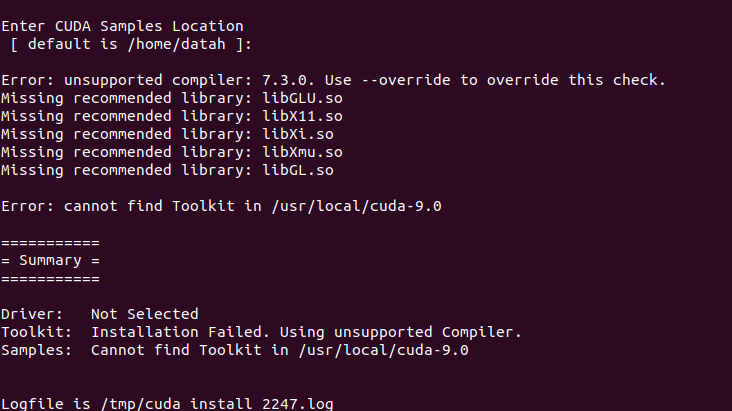
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
否则将会报错:
3、注意C++\G++版本
CUDA9.0要求GCC版本是5.x或者6.x,其他版本不可以,需要自己进行配置,通过以下命令才对gcc版本进行修改。
查看版本:
g++ --version
版本安装:
sudo apt-get install gcc-5
sudo apt-get install g++-5
通过命令替换掉之前的版本:
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 50
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-5 50
最后记得再次查看版本是否修改成功。
4、运行run文件
sudo sh cuda_9.0.176_384.81_linux.run
安装协议可以直接按q跳到最末尾,注意一项:
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 384.81?
(y)es/(n)o/(q)uit: n # 安装NVIDIA加速图形驱动程序,这里选择n
5、添加环境变量
进行环境的配置,打开环境变量配置文件
sudo gedit ~/.bashrc
在末尾把以下配置写入并保存:
#CUDA
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
最后执行:
source ~/.bashrc
6、安装测试
在安装的时候也也相应安装了一些cuda的一些例子,可以进入例子的文件夹然后使用make命令执行。
例一:
1.进入例子文件
cd /usr/local/cuda-8.0/samples/1_Utilities/deviceQuery
2.执行make命令
sudo make
\3. 第三步
./deviceQuery
如果结果有GPU的信息,说明安装成功。
例二:
\1. 进入例子对应的文件夹
cd NVIDIA_CUDA-9.0_Samples/5_Simulations/fluidsGL
2.执行make
make clean && make
\3. 运行
./fluidsGL
当执行这个例子,我们会看到流动的图,刚开始可能看不到黑洞,需要等待一小段时间。不过记得用鼠标点击下绿色的画面。

三、安装cuDNN
1、官网下载:https://developer.nvidia.com/rdp/form/cudnn-download-survey
这个需要注册账号,拿自己的邮箱注册即可。
只需下载下面3个安装包即可

2、顺序执行下面3个安装命令:
sudo dpkg -i libcudnn7_7.0.3.11-1+cuda9.0_amd64.deb``sudo dpkg -i libcudnn7-dev_7.0.3.11-1+cuda9.0_amd64.deb``sudo dpkg -i libcudnn7-doc_7.0.3.11-1+cuda9.0_amd64.deb
3、安装测试
输入以下命令:
cp -r /usr/src/cudnn_samples_v7/ $HOME``cd $HOME/cudnn_samples_v7/mnistCUDNN``make clean && make``./mnistCUDNN
最终如果有提示信息:“Test passed! ”,则说明安装成功!
四、安装TensorFlow
1.pip直接安装
pip install tensorflow_gpu-1.9.0
五、安装darknet
打开YOLOv3官网,https://pjreddie.com/darknet/,按着教程一步一步的照做。
把项目克隆到本地,编译
git clone https://github.com/pjreddie/darknet
cd darknet
make
下载已经训练好的yolov3权重,或者直接wget,如果下载速度太慢可以去百度找一下。
wget https://pjreddie.com/media/files/yolov3.weights
下载完之后就可以使用权重模型来进行测试了。
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
这里不会弹出来检测的图片是因为没有安装OpenCV,检测的结果会在项目文件夹下生成predictions.png.
如果你有摄像头,你也可以直接通过视频测试模型
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
六、总结
至此已完成了,模型训练端的环境搭建,下一篇文章将介绍如何利用YOLOv3模型训练自己的数据集。
基于树莓派与YOLOv3模型的人体目标检测小车(一)的更多相关文章
- 目标检测-基于Pytorch实现Yolov3(1)- 搭建模型
原文地址:https://www.cnblogs.com/jacklu/p/9853599.html 本人前段时间在T厂做了目标检测的项目,对一些目标检测框架也有了一定理解.其中Yolov3速度非常快 ...
- 基于候选区域的深度学习目标检测算法R-CNN,Fast R-CNN,Faster R-CNN
参考文献 [1]Rich feature hierarchies for accurate object detection and semantic segmentation [2]Fast R-C ...
- 基于深度学习的安卓恶意应用检测----------android manfest.xml + run time opcode, use 深度置信网络(DBN)
基于深度学习的安卓恶意应用检测 from:http://www.xml-data.org/JSJYY/2017-6-1650.htm 苏志达, 祝跃飞, 刘龙 摘要: 针对传统安卓恶意程序检测 ...
- CVPR2020|3D-VID:基于LiDar Video信息的3D目标检测框架
作者:蒋天园 Date:2020-04-18 来源:3D-VID:基于LiDar Video信息的3D目标检测框架|CVPR2020 Brief paper地址:https://arxiv.org/p ...
- EGADS介绍(二)--时序模型和异常检测模型算法的核心思想
EDADS系统包含了众多的时序模型和异常检测模型,这些模型的处理会输入很多参数,若仅使用默认的参数,那么时序模型预测的准确率将无法提高,异常检测模型的误报率也无法降低,甚至针对某些时间序列这些模型将无 ...
- .NET - 基于事件的异步模型
注:这是大概四年前写的文章了.而且我离开.net领域也有四年多了.本来不想再发表,但是这实际上是Active Object模式在.net中的一种重要实现方法,因此我把它掏出来发布一下.如果该模型有新的 ...
- 基于Pre-Train的CNN模型的图像分类实验
基于Pre-Train的CNN模型的图像分类实验 MatConvNet工具包提供了好几个在imageNet数据库上训练好的CNN模型,可以利用这个训练好的模型提取图像的特征.本文就利用其中的 “im ...
- word2vec 中的数学原理具体解释(五)基于 Negative Sampling 的模型
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单.高效,因此引起了非常多人的关注. 因为 word2vec 的作者 Tomas ...
- word2vec 中的数学原理具体解释(四)基于 Hierarchical Softmax 的模型
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单.高效,因此引起了非常多人的关注.因为 word2vec 的作者 Tomas M ...
随机推荐
- ndk-stack使用方法(转)
最近在mac上编译android 版本,各种崩溃让人蛋疼,网上学习了下ndk-stack使用方法. 自己备忘下: 1.运行终端. 跳转到你android sdk 目录 因为你的adb 在里面. 如 c ...
- Flutter跨平台框架的使用-iOS最新版
科技引领我们前行 [前言] 1:先简单的介绍下Flutter,它是一款跨平台应用SDK,高性能跨平台实现方案(暂时讨论iOS和Android), 它不同于RN,少了像RN的JS中间桥接层,所以它的性能 ...
- linux入门系列16--文件共享之Samba和NFS
前一篇文章"linux入门系列15--文件传输之vsftp服务"讲解了文件传输,本篇继续讲解文件共享相关知识. 文件共享在生活和工作中非常常见,比如同一团队中不同成员需要共同维护同 ...
- 压力测试(三)-自定义变量和CSV可变参数实操
1.Jmeter用户自定义变量实战 简介:什么是用户自定义变量,怎样使用 为什么使用:很多变量在全局中都有使用,或者测试数据更改,可以在一处定义,四处使用 比如服务器地址 1.线程组->add ...
- 2020年春招面试必备Spring系列面试题129道(附答案解析)
前言 关于Spring的知识总结了个思维导图分享给大家 1.不同版本的 Spring Framework 有哪些主要功能? 2.什么是 Spring Framework? Spring 是一个 ...
- Python 绘图 - Bokeh 柱状图小试(Stacked Bar)
背景 在 Bokeh 初探之后,学习使用它来做个图 目标 做一个柱状图,支持多个 y 数据源,即有堆叠效果的柱状图 stacked bar 实现 单数据源 简单的柱状图 参考 Handling Cat ...
- SpringBoot入门系列(四)整合模板引擎Thymeleaf
前面介绍了Spring Boot的优点,然后介绍了如何快速创建Spring Boot 项目.不清楚的朋友可以看看之前的文章:https://www.cnblogs.com/zhangweizhong/ ...
- 并发工具类的使用 CountDownLatch,CyclicBarrier,Semaphore,Exchanger
1.CountDownLatch 允许一个或多个线程等待直到在其他线程中执行的一组操作完成的同步辅助. A CountDownLatch用给定的计数初始化. await方法阻塞,直到由于countDo ...
- 第六章、Vue项目预热
6-5. (1). (2).引入reset.css及border.css (3).解决手机点击延迟300ms的问题 a.安装 b.引入fastclick 6-2.项目的整体架构 src--->整 ...
- jwt的token如何使用
JWT简介: JWT(JSON WEB TOKEN):JSON网络令牌,JWT是一个轻便的安全跨平台传输格式,定义了一个紧凑的自包含的方式在不同实体之间安全传输信息(JSON格式).它是在Web环境下 ...