透过源码分析ArrayList运作原理
List接口的主要实现类ArrayList,是线程不安全的,执行效率高;底层基于Object[] elementData 实现,是一个动态数组,它的容量能动态增加和减少。可以通过元素下标访问对象,使用于快速检索场景时使用。
基于JDK1.8,通过ArrayList几个常用的方法,分析ArrayList原理。
属性及继承关系
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
private static final long serialVersionUID = 8683452581122892189L;
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;
private int size;
}
ArrayList继承AbstractList类,并实现List接口;
RandomAccess:是一个标记接口,继承了RandomAccess接口的集合支持随机快速访问
Cloneable:继承Cloneable接口,重写clone()方法,能实现拷贝功能
Serializable:支持序列化,可存储和传输
空构造函数及带参构造函数
ArrayList()
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
当我们new ArrayList()时会初始化elementData属性为空数组{},此时底层的数组并没有被实例化,所以操作ArrayList其实就是围绕elementData这个数组而进行。
ArrayList(int initialCapacity)
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
当使用带参构造函数 initialCapacity ;可以从源码看出如果 initialCapacity 大于 0 ,会实例化一个指定长度的Object数组赋值给elementData ;如果 initialCapacity 等于 0 则依然赋值为空;否则抛出异常信息。
通过以上两个构造函数,可以很明确ArrayList底层其实是一个Object[] 数组,而调用ArrayList提供的方法,其实就是操作数组。
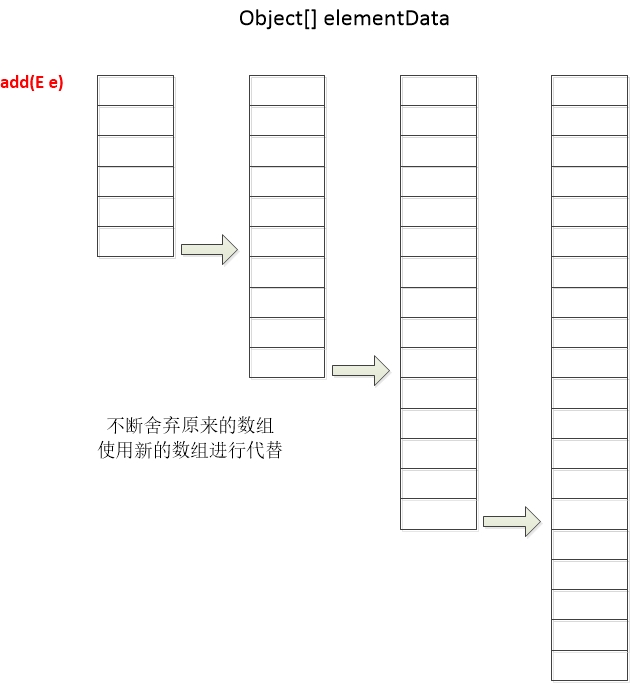
add(E e)
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
add(E e) 方法的作用是添加一个元素到列表末尾,方法第一行调用ensureCapacityInternal(size + 1); 代码如下:
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
判断elementData为空数组时则返回DEFAULT_CAPACITY, minCapacity这两个中的最大值,接着调用ensureExplicitCapacity(minCapacity);代码如下:
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
可以看出这里其实就是判断是否需要进行扩容,条件是当我们所需要的数组长度减去数组的长度大于0时,会调用grow(minCapacity)进行扩容;代码如下:
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
声明一个newCapacity属性,值为原数组长度的1.5倍且进行判断,如果扩容后的长度减去我们需要的数组长度小于0则使用扩容后的长度,如果扩容后的长度减去MAX_ARRAY_SIZE大于0则使用Integer的最大值(Integer.MAX_VALUE) ,这里的MAX_ARRAY_SIZE 实则是Integer.MAX_VALUE - 8,接下来就是拷贝一个新的数组
通过add(E e)方法的源代码,又可以很明确知道当我们在对ArrayList集合添加元素的时候,其实会对底层elementData数组的长度进行判断并动态调整且产生一个新的数组回来
remove(int index)
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null;
return oldValue;
}
remove(int index)方法的作用是按照索引位置删除并返回元素;第一行代码rangeCheck(index);检查索引是否越界,代码如下:
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
E oldValue = elementData(index);获取指定下标的数据,计算出需要移动的位置,调用native方法进行数组移动,改变size长度,且将--size位置置空等待GC回收,最终返回之前的值
get(int index)
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
get(int index)方法的作用是获取指定下标的元素;第一步检查索引是否合法,根据下标获取elementData数组中的数据并返回
set(int index, E element)
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
set(int index, E element)方法的作用是设置指定下标的元素值;第一步检查索引是否合法,然后获取之前的值,并将之前下标的值更改为当前数据,返回老数据
透过源码分析ArrayList运作原理的更多相关文章
- 追源索骥:透过源码看懂Flink核心框架的执行流程
li,ol.inline>li{display:inline-block;padding-right:5px;padding-left:5px}dl{margin-bottom:20px}dt, ...
- 从定时器的选型,到透过源码看XXL-Job(下)
透过源码看xxl-job (注:本文基于xxl-job最新版v2.0.2, quartz版本为 v2.3.1. 以下提到的调度中心均指xxl-job-admin项目) 上回说到,xxl-job是一个中 ...
- 【转】MaBatis学习---源码分析MyBatis缓存原理
[原文]https://www.toutiao.com/i6594029178964673027/ 源码分析MyBatis缓存原理 1.简介 在 Web 应用中,缓存是必不可少的组件.通常我们都会用 ...
- Kafka源码分析及图解原理之Producer端
一.前言 任何消息队列都是万变不离其宗都是3部分,消息生产者(Producer).消息消费者(Consumer)和服务载体(在Kafka中用Broker指代).那么本篇主要讲解Producer端,会有 ...
- Guava 源码分析(Cache 原理 对象引用、事件回调)
前言 在上文「Guava 源码分析(Cache 原理)」中分析了 Guava Cache 的相关原理. 文末提到了回收机制.移除时间通知等内容,许多朋友也挺感兴趣,这次就这两个内容再来分析分析. 在开 ...
- 深入源码分析SpringMVC底层原理(二)
原文链接:深入源码分析SpringMVC底层原理(二) 文章目录 深入分析SpringMVC请求处理过程 1. DispatcherServlet处理请求 1.1 寻找Handler 1.2 没有找到 ...
- php中foreach源码分析(编译原理)
php中foreach源码分析(编译原理) 一.总结 编译原理(lex and yacc)的知识 二.php中foreach源码分析 foreach是PHP中很常用的一个用作数组循环的控制语句.因为它 ...
- 通过源码分析Java开源任务调度框架Quartz的主要流程
通过源码分析Java开源任务调度框架Quartz的主要流程 从使用效果.调用链路跟踪.E-R图.循环调度逻辑几个方面分析Quartz. github项目地址: https://github.com/t ...
- Robotium源码分析之运行原理
从上一章<Robotium源码分析之Instrumentation进阶>中我们了解到了Robotium所基于的Instrumentation的一些进阶基础,比如它注入事件的原理等,但Rob ...
随机推荐
- DEX文件解析---2、Dex文件checksum(校验和)解析
一.checksum介绍 checksum(校验和)是DEX位于文件头部的一个信息,用来判断DEX文件是否损坏或者被篡改,它位于头部的0x08偏移地址处,占用4个字节,采用小端序存储. ...
- xadmin theme
我在user的adminx中设置了为True之后,我的主题还是加载不出来,具体没找到原因,网上也没有找到相应的资料,不过通过尝试,可以根据需要,添加自己需要的主题,操作如下: 1.找到xadmin文件 ...
- java.lang.reflect.UndeclaredThrowableException: null Caused by: org.apache.zookeeper.KeeperException$UnimplementedException: KeeperErrorCode = Unimplemented for
java.lang.reflect.UndeclaredThrowableException: null at org.springframework.util.ReflectionUtils. ...
- selenium+chromdriver 动态网页的爬虫
# 获取加载更多的数据有 2 种方法# 第一种就是直接找数据接口, 点击'加载更多' 在Network看下, 直接找到数据接口 # 第二种方法就是使用selenium+chromdriver # se ...
- Go 的 http 包的源码,通过代码我们可以看到整个的 http 处理过程
func (srv *Server) Serve(l net.Listener) error {defer l.Close() var tempDelay time.Duration // how l ...
- Spring MVC启动流程分析
本文是Spring MVC系列博客的第一篇,后续会汇总成贴子. Spring MVC是Spring系列框架中使用频率最高的部分.不管是Spring Boot还是传统的Spring项目,只要是Web项目 ...
- layui的弹出层的title的自定义html
layui的弹出层的title的自定义html //在这里面输入任何合法的js语句 layer.open({ type: 1 //Page层类型 ,area: ['500px', '300px' ...
- 有关KMP算法
KMP算法: 此算法的本质是首先对于模板字符串进行计算,生成一个数组(next数组),该数组反映了模板字符串的情况. 例: S: ABADACABABCD P: ABAB 当我们查询到P3与S3(B和 ...
- C# lock 语法糖实现原理--《.NET Core 底层入门》之自旋锁,互斥锁,混合锁,读写锁
在多线程环境中,多个线程可能会同时访问同一个资源,为了避免访问发生冲突,可以根据访问的复杂程度采取不同的措施 原子操作适用于简单的单个操作,无锁算法适用于相对简单的一连串操作,而线程锁适用于复杂的一连 ...
- Python专题——详解enumerate和zip
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是Python专题的第7篇文章,我们继续介绍迭代相关. enumerate 首先介绍的是enumerate函数. 在我们日常编程的过程当 ...