Lucene学习笔记一
Lucene课件
1.全文检索
1.1常见的全文检索
在window系统中,可以指定磁盘中的某一个位置来搜索你想要得到的东西。这个功能是windows比较常用的功能。在这个界面中能搜索的内容有*.*,*.bat,可以搜索文件中的内容。

在myeclipse中,点击Help->Help Contents,可以利用搜索功能找到你要查询的帮助文档。
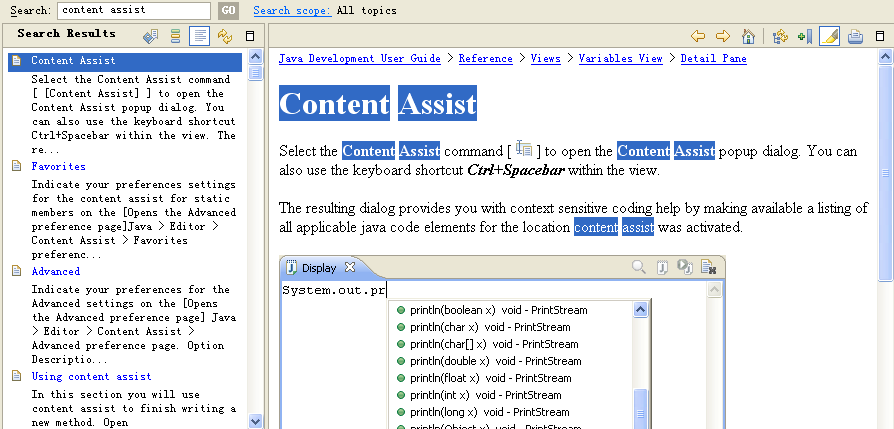
在myeclipse中,点击Search->File,在Containing text中可以指定要查找的内容,在File name patterns中可以用*.java来表示要查找的内容来自所有java文件,或者*.*表示要查找的文件来自全部的文件。这个功能非常常用。

在百度和google 中,可以搜索互联网中的信息,有:网页、pdf、word音频、视频等内容。
在bbs系统中,有搜索文章的功能。
以上的查询功能都相似,都是查询的文本内容,查询方法也相似即找出含有指定字符串的资源。只不过是查询的范围不一样。(硬盘、帮助文件、互联网)
1.2全文检索的概念
从大量的信息中快速、准确地查找出要的信息
搜索的内容是文本信息(不是多媒体)
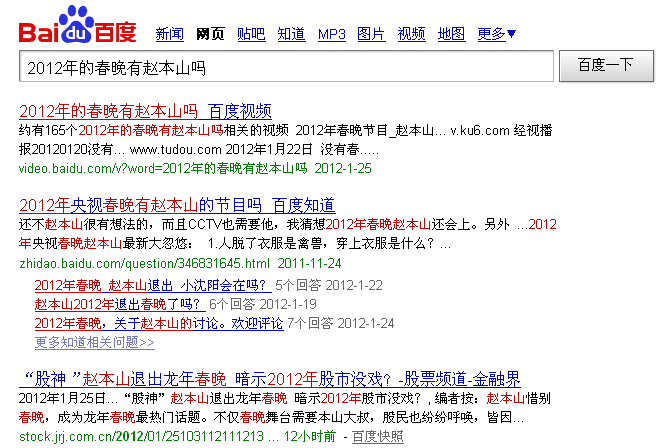
搜索的方式:不是根据语句的意思进行处理。如果要搜索的文本为”2012年的春晚有赵本山吗”,那么含有这些词(2012年、春晚、赵本山)就能搜索出来。每一个词都是关键词。
全面、快速、准确是衡量全文检索系统的关键指标。
概括:
只处理文本
不处理语义

搜索时英文不区分大小写
结果列表有相关度排序
1.3全文检索的应用场景
1.3.1站内搜索
通常用于在大量数据出现的系统中,找出你想要的资料。常见的有
bbs的关键字搜索
baidu贴吧林志玲、胡汉三
商品网站的搜索等
中关村在线商品的名称、电脑硬件名称(CPU)
文件管理系统
对文件的搜索功能。Window的文件搜索
1.3.2垂直搜索
是针对某个行业的搜索引擎
是搜索引擎的细分和延伸
是针对网页库中的专门信息的整合
其特点是专、深、精,并具有行业色彩
可以应用于购物搜索、房产搜索、人才搜索
1.4全文检索与数据库搜索的区别
1.4.1数据库的搜索
类似:select * from 表名where 字段名like ‘%关键字%’
例如:select * from article where content like’%here%’
结果: where here shere
缺点:
搜索效果比较差
在搜索的结果中,有大量的数据被搜索出来,有很多数据是没有用的。
查询速度在大量数据的情况下是很难做到快速的。
1.4.2全文检索
搜索结果按相关度排序:意味着只有前几个页面对于用户来说是比较有用的,其他的结果与用户想要的答案很可能相差甚远。数据库搜索是做不到相关度排序的。
因为全文检索是采用引索的方式,所以在速度上肯定比数据库方式like要快。
所以数据库不能代替全文检索。
1.5Lucene简介
全文检索只是一个概念,而具体实现有很多框架,lucene是其中的一种。Lucene的主页http://lucene.apache.org/。本文用的是3.0.1版本。
2.Lucene大致结构
2.1互联网搜索结构框图
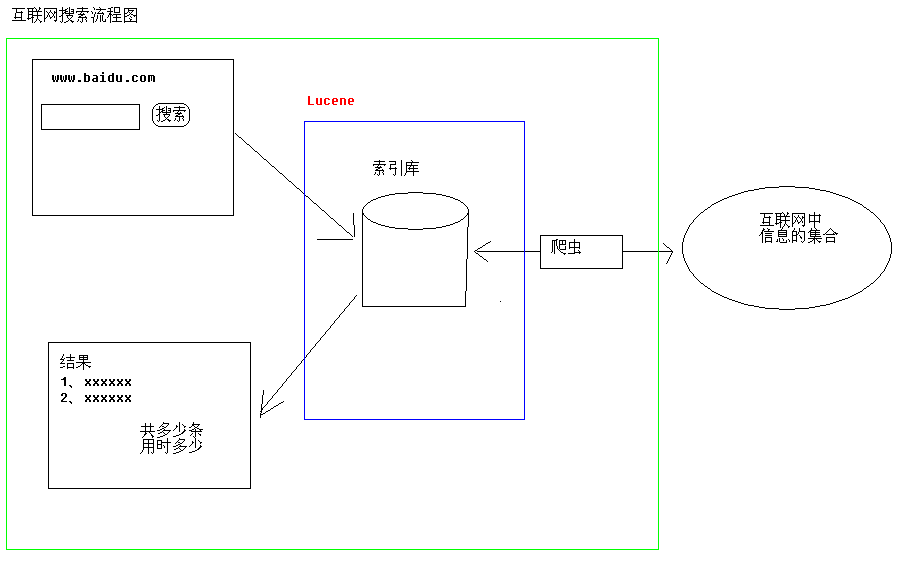
说明:
当用户打开www.baidu.com网页搜索某些数据的时候,不是直接找的网页,而是找的百度的索引库。索引库里包含的内容有索引号和摘要。当我们打开www.baidu.com时,看到的就是摘要的内容。
百度的索引库的索引和互联网的某一个网站对应。
当用户数据要查询的关键字,返回的页面首先是从索引库中得到的。
点击每一个搜索出来的内容进行相关网页查找,这个时候才找的是互联网中的网页。
2.2lucene的大致结构框图
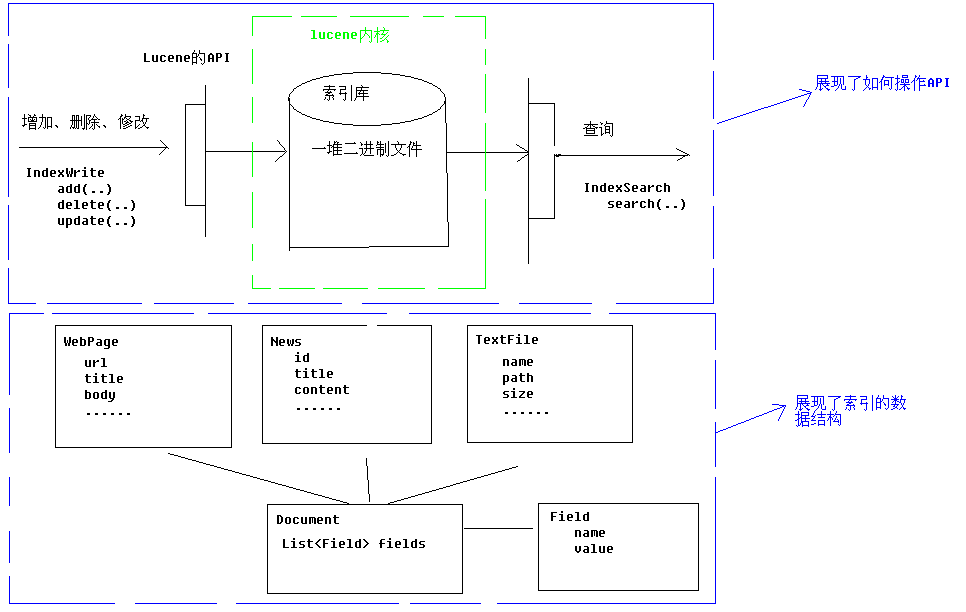
说明:
在数据库中,数据库中的数据文件存储在磁盘上。索引库也是同样,索引库中的索引数据也在磁盘上存在,我们用Directory这个类来描述。
我们可以通过API来实现对索引库的增、删、改、查的操作。
在数据库中,各种数据形式都可以概括为一种:表。在索引库中,各种数据形式也可以抽象出一种数据格式为Document。
Document的结构为:Document(List<Field>)
Field里存放一个键值对。键值对都为字符串的形式。
对索引库中索引的操作实际上也就是对Document的操作。
3.第一个lucene程序
3.1准备lucene的开发环境
搭建lucene的开发环境,要准备lucene的jar包,要加入的jar包至少有:
lucene-core-3.1.0.jar
(核心包)lucene-analyzers-3.1.0.jar
(分词器)lucene-highlighter-3.1.0.jar
(高亮器)lucene-memory-3.1.0.jar
(高亮器)
3.2建立索引
3.2.1开发代码

3.2.2代码说明
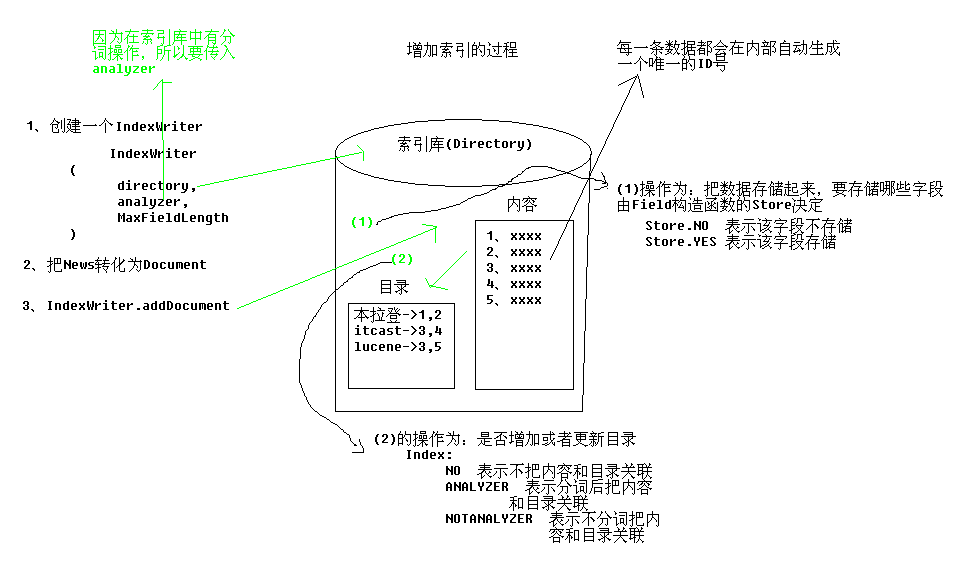
步骤:
创建IndexWriter对象
把JavaBean转化为Document
利用IndexWriter.addDocument方法增加索引
关闭资源
3.3搜索
3.3.1搜索代码


3.3.2代码说明
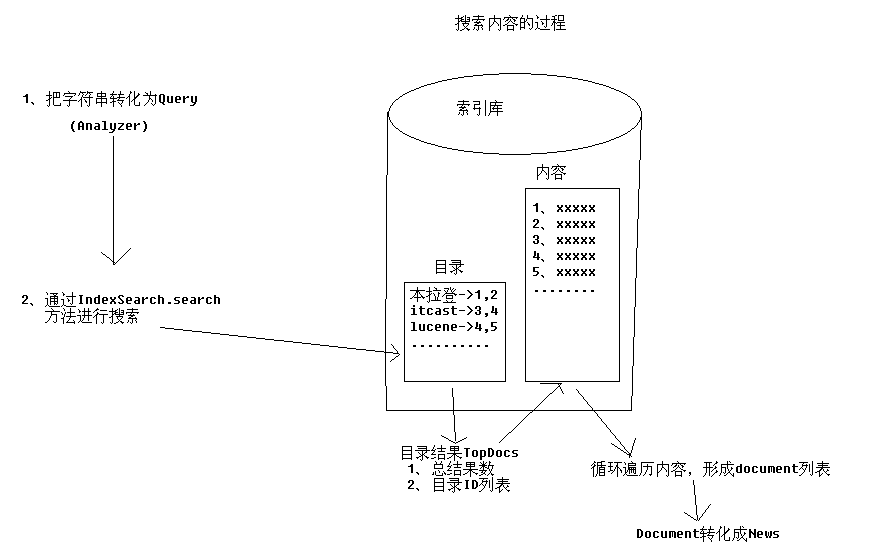
步骤:
创建IndexSearch
创建Query对象
进行搜索
获得总结果数和前N行记录ID列表
根据目录ID列表把Document转为为JavaBean并放入集合中。
循环出要检索的内容
3.4例子说明
执行两次建立引索
说明:执行两次同样的JavaBean数据增加的引索都能成功,说明JavaBean中的ID不是唯一确定索引的标示。在lucene中,唯一确定索引的标示(目录ID)是由lucene内部生成的。
在搜索的时候,可以尝试用”Lucene”或者”lucene”来测试,结果是一样的。因为分词器把输入的关键字都变成小写。
在建立索引和搜索索引的时候都用到了分词器。
在索引库中存放的有目录和内容两大类数据。
Store这个参数表明是否将内容存放到索引库内容中。
Index这个参数表明是否存放关键字到索引目录中。
4.索引库的操作
4.1保持数据库与索引库的同步
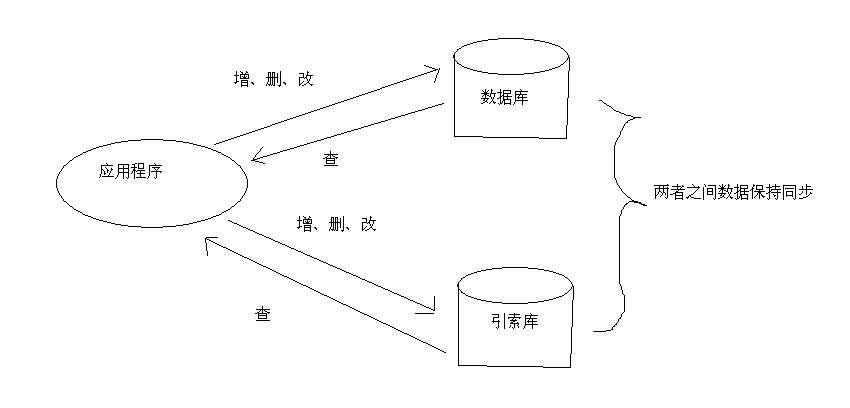
说明:在一个系统中,如果索引功能存在,那么数据库和索引库应该是同时存在的。这个时候需要保证索引库的数据和数据库中的数据保持一致性。可以在对数据库进行增、删、改操作的同时对索引库也进行相应的操作。这样就可以保证数据库与索引库的一致性。
4.2工具类DocumentUtils

说明:在对索引库进行操作时,增、删、改过程要把一个JavaBean封装成Document,而查询的过程是要把一个Document转化成JavaBean。在进行维护的工作中,要反复进行这样的操作,所以我们有必要建立一个工具类来重用代码。
注:在使用Document的过程中,如图所示:


什么情况下使用Index.NOT_ANALYZED
当这个属性的值代表的是一个不可分割的整体,例如ID
什么情况下使用Index.ANALYZED
当这个属性的值代表的是一个可分割的整体
4.3LuceneConfig
LuceneConfig这个类把Directory和Analyzer进行了包装。因为在创建IndexWriter时,需要用到这两个类,而管理索引库的操作都要用到IndexWriter这个类,所以我们对Directory和Analyzer进行了包装

4.4管理索引库
4.4.1增加
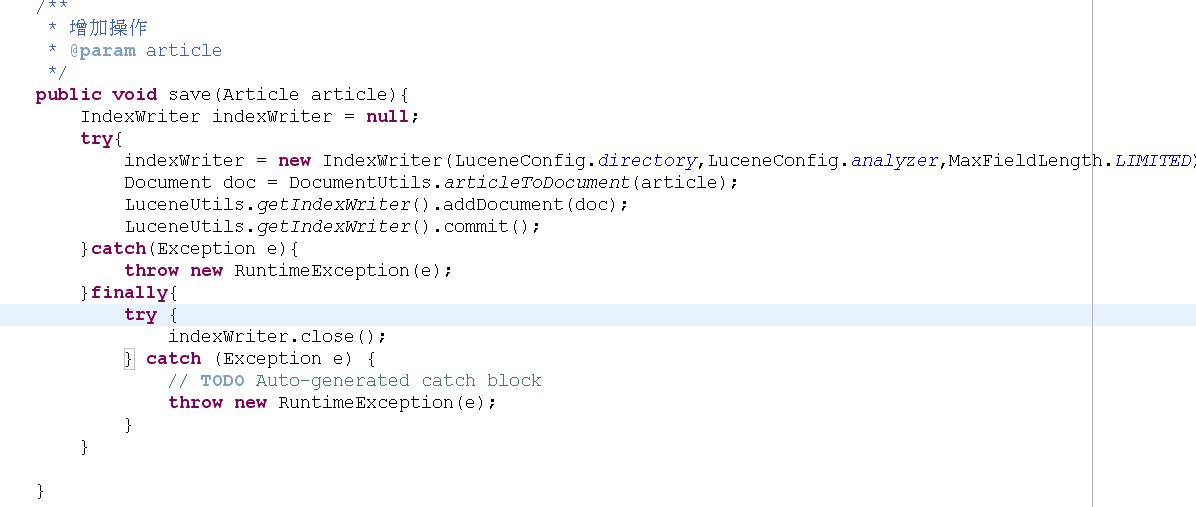
说明:在程序的最后必须在finally中写关闭资源的操作。因为这里有IO流的读写操作。
4.4.2删除
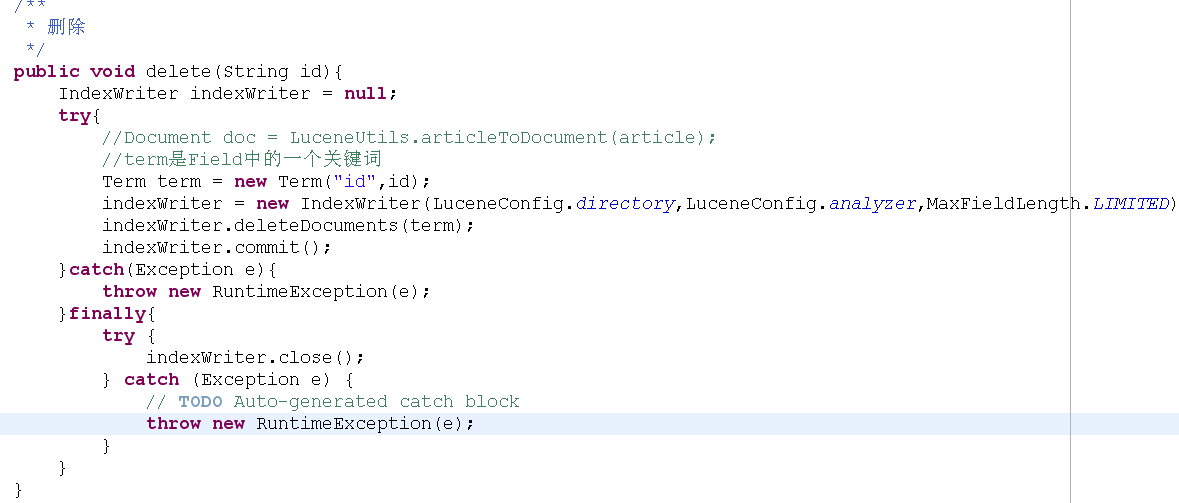
说明:indexWriter.deleteDocuments的参数为Term.Term指关键词。因为ID的索引保存类型为Index.NOT_ANALYZED,因为直接写ID即可。
4.4.3修改

说明:lucene的更新操作与数据库的更新操作是不一样的。因为在更新的时候,有可能变换了关键字的位置,这样分词器对关键字还得重新查找,而且还得在目录和内容中替换,这样做的效率比较低,所以lucene的更新操作是删除和增加两步骤来完成的。
5.IndexWriter
5.1Hibernate的SessionFactory
说明:在Hibernate中,一般保持一个数据库就只有一个SessionFactory。因为在SessionFactory中维护二级缓存,而SessionFactory又是线程安全的。所以SessionFactory是共享的。
5.2lucene的IndexWriter
说明:如果同时在一个索引库中同时建立两个IndexWriter,例如:

这样的代码会出现如下异常:

而lucene的目录结构:

会出现write.lock这个文件。因为当一个IndexWriter在进行读索引库操作的时候,lucene会为索引库,以防止其他IndexWriter访问索引库而导致数据不一致,直到IndexWriter关闭为止。
结论:同一个索引库只能有一个IndexWriter进行操作。
5.3封装IndexWriter的类LuceneUtils

注:这里用单例模式做比较好。
6.索引库的优化
当执行创建索引多次时,索引库的文件如图所示:(索引里内容是一样的)
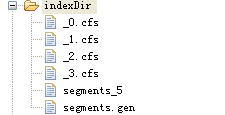
从图中可以看出来,每执行一次就生成一个cfs文件。当执行delete操作时,会生成如图所示的结构:
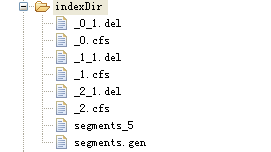
从图中可以看出来,lucene在执行删除的时候,是先把要删除的元素形成了一个文件del文件,然后再和cfs文件进行整合得出最后结果。
结论:如果增加、删除反复操作很多次,就会造成文件大量增加,这样检索的速度也会下降,所以我们有必要去优化索引结构。使文件的结构发生改变从而提高效率。
6.1手动合并文件

在执行完上述代码后,索引库的结构为:
可以看出把该合并的项都合并了。把del文件彻底全部删除掉了。
6.2自动合并文件

LuceneUtils.getIndexWriter().setMergeFactor(3)意思为当文件的个数达到3的时候,合并成一个文件。如果没有设置这个值,则使用默认的情况:10
6.3内存索引库
6.3.1特点
在内存中开辟一块空间,专门为索引库存放。这样有以下几个特征:
因为索引库在内存中,所以访问速度更快。
在程序退出时,索引库中的文件也相应的消失了。
如果索引库比较大,必须得保证足够多的内存空间。
6.3.2编码

在执行完这段代码以后,并没有在磁盘上出现索引库。所以单独使用内存索引库没有任何意义。
6.3.3文件索引库与内存索引库的结合
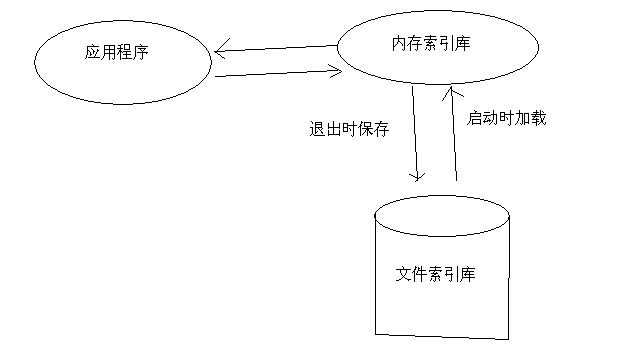
当应用程序启动的时候,从文件索引库加载文件到内存索引库。应用程序直接与内存索引库交互。当应用程序退出的时候,内存索引库把数据再次保存到文件索引库,完成文件的保存工作。

说明:
Directory
ramdirectory = new
RAMDirectory(filedirectory);把filedirectory这个索引库加载到ramdirectory内存库中IndexWriter的构造函数:

True 重新创建一个或者覆盖(选择)
False 追加
7.分词器
7.1英文分词器
步骤:Creates
a searcher searching the index in the named directory
切分关键词
Creates
a
searcher
searching
the
index
the
named
directory
去除停用词
停用词:有些词在文本中出现的频率非常高。但对本文的语义产生不了多大的影响。例如英文的a、an、the、of等。或中文的”的、了、呢等”。这样的词称为停用词。停用词经常被过滤掉,不会被进行索引。在检索的过程中,如果用户的查询词中含有停用词,系统会自动过滤掉。停用词可以加快索引的速度,减少索引库文件的大小。
Creates
searcher
searching
index
named
directory
转为小写(搜索时不区分大小写,因为分词器会帮你转化)
creates
searcher
searching
index
named
directory
7.2中文分词器
7.2.1单字分词
Analyzer
analyzer2 = new ChineseAnalyzer();
把汉字一个字一个字分解出来。效率比较低。
7.2.2二分法分词
Analyzer
analyzer3 = new CJKAnalyzer(Version.LUCENE_30);
把相邻的两个字组成词分解出来,效率也比较低。而且很多情况下分的词不对。
7.2.3词库分词(IKAnalyzer)
Analyzer
analyzer4 = new IKAnalyzer();
基本上可以把词分出来(经常用的分词器)
7.2.4词库的扩充
“传智播客的本拉登被击毙了”分此后的结果为:
传、智、播、客、本拉登、拉登、击毙
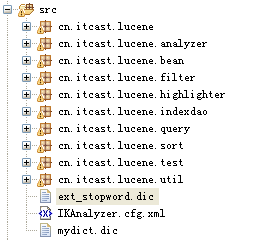
如图:
ext_stopword.dic为停止词的词库,词库里的词都被当作为停止词使用。
IKAnalyzer.cfg.xml为IKAnalyzer的配置文件。

Key为ext_stopwords
为停止词所在的位置。
Key为ext_dict为配置自己的扩展字典所在的位置。如图所示可以在mydict.dic中添加自己所需要的词。如:”传智播客”
添加完以后分词器分”“传智播客的本拉登被击毙了”结果为:
传智播客、本拉登、拉登、击毙
7.2.5修改LuceneConfig类

以后用的分词库为IKAnalyzer中文分词库。
8.查询索引库
8.1查询

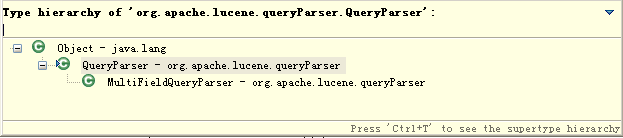
说明:这是QueryParser的继承结构,在这里我们用的是MultiFieldQueryParser.这个类的好处可以选择多个属性进行查询。而QueryParser只能选择一个。
8.1.1分页

说明:
在全文检索系统中,一般查询出来的内容比较多,所以必须将查询出来的内容进行分页处理。
原理同hibernate的分页查询。在hibernate的分页查询中,有两个参数:
int firstResult
当前页的第一行在数据库里的行数
int maxResult
每页显示的页数
返回值不仅包括查询结果,还应该有总记录数,用SearchResult来封装
8.1.2搜索方式

使用查询字符串
QueryParser->Query对象
可以使用查询条件
“lucene AND
互联网”都出现符合查询条件
“lucene OR
互联网”只要出现其一就符合查询条件
自己创建与配置Query对象
关键词查询(TermQuery)

注:因为保存引索的时候是通过分词器保存,所以所有的因为在索引
库里都为小写,所以lucene必须得小写,不然查询不到。如果使用
查询字符串进行查询,对应的语法格式为:title:lucene
查询所有文档

如果使用查询字符串,对应语法:*:*
范围查询

如果使用查询字符串,
第一个:id:[5 TO
15]
第二个:
id:{5 TO 15}
注:在lucene中,处理数字是不能直接写入的,要进行转化。NumberStringTools帮助类给出了转化工具:

在工具类DocumentUtils中也做相应的转化:


通配符查询

如果使用查询字符串:title:lucen?
短语查询

上面的0代表第0个位置
上面的1代表第3个位置
使用查询字符串:title:"lucene
? ? 互联网"
Boolean查询
可以把多个查询条件组合成一个查询条件

如图为:同时满足title中有lucene关键字和ID为5到15的所有索引数据。不包括5和15
使用查询字符串:+id:{5
TO 15} +title:lucene
注意:
1、单独使用MUST_NOT
没有意义
2、MUST_NOT和MUST_NOT
无意义,检索无结果
3、单独使用SHOULD:结果相当于MUST
4、SHOULD和MUST_NOT:
此时SHOULD相当于MUST,结果同MUST和MUST_NOT
5、MUST和SHOULD:此时SHOULD无意义,结果为MUST子句的检索结果
8.2过滤

利用indexSearch.search的重载函数的过滤器参数实现对结果的过滤。从这里可以看出这是一个范围过滤器。第二个参数与第三个参数为5,15。但是lucene会把这两个参数当作字符串来对待。所以这样搜索结果为0。
进行如下处理:

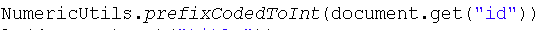
凡是数字类型的都必须经过这样的方式进行处理。

凡是日期类型的都必须经过这样的方式进行处理。这样才能保证结果的正确性。
8.3排序
8.3.1相关度得分
实验一:
在索引库中内容完全相同的情况下,用几个关键词搜索,看是否得分相同。
结果:
同一个关键词得分对于所有的Document是一样的。但是不同的关键词的分数不一样。关键词和文本内容匹配越多,得分越高。也就是相关度得分就高
实验二:
再插入一个Document,在其中的content中增加一个关键词,然后保存到索引库中。如图:

在content中,google的后面又加了一个词”互联网”。然后再进行搜索,这个时候,id为26的被排到了第一位。相关度得分最高。因为其他的Document在content中匹配”互联网”只有一处,而id为26的有两处。
结果:
同一个关键词如果在所有匹配的文本中的相关度得分不一样,按照相关度得分从高到低的顺序排列。
实验三:
如果想从百度上排名第一,就得控制相关度得分。在lucene中,可以人为控制相关度得分。如图:

利用Document.setBoost可以控制得分。默认值为1
结论:
利用Document.setBoost可以人为控制相关度得分,从而把某一个引索内容排到最前面。
8.3.2按照某个字段进行排序

如图所示的代码,重载了indexSearcher.search方法。在这个方法中,Sort对象就是指定的按照id升序排列。SortField.INT指定了ID的类型。类型不一样,大小的比较就不一样。

上面代码查询出来以后是按照id的升序排列。

这个代码为按照id的降序排列。其中最后一个参数为reverse
Reverse为false
升序(默认)
Reverse
为true
降序
注:按照某个字段进行排序与相关度得分没有关系。
8.4高亮
用户在百度的首界面输入要搜索的关键字,比如:林志玲,如图所示:
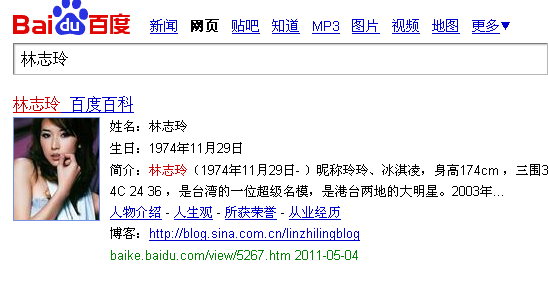
从上图可以看出林志玲这个关键词变成了红色,这就是高亮。
8.4.1高亮的作用
使关键字的颜色和其他字的颜色不一样,这样关键字就比较突出。
方法:在关键字周围加上前缀和后缀
<font
color=’red’>林志玲</font>
生成摘要(从关键词出现最多的地方截取一段文本),可以配置要截取文本的字符数量。
8.4.2编程步骤
创建和配置高量器

一个高亮器的创建需要两个条件:
Formatter 要把关键词显示成什么样子
Scorer 查询条件
Fragmenter设置文本的长度。默认为100。
如果文本的内容长度超过所设定的大小,超过的部分将显示不出来。
使用高亮器

getBestFragment为得到高亮后的文本。
参数:
分词器。
如果是英文:StandardAnalyzer
如果是中文:IKAnalyzer
在哪个属性上进行高亮
要高亮的内容
9.Lucene的核心API介绍
9.1建立索引的API
5.1.1IndexWriter
利用这个类可以对索引库进行增、删、改操作。
利用构造方法IndexWriter
indexWriter = new
IndexWriter(directory,LuceneConfig.analyzer,MaxFieldLength.LIMITED)可以构造一个IndexWriter的对象。addDocument 向索引库中添加一个Document
updateDocument 更新一个Document
deleteDocuments 删除一个Document
5.1.2
Directory
指向索引库的位置,有两种Directory
5.1.2.1FSDirectory
通过FSDirectory.open(new
File("./indexDir"))建立一个indexDir的文件夹,而这个文件夹就是索引库存放的位置。通过这种方法建立索引库时如果indexDire文件夹不存在,程序将自动创建一个,如果存在就用原来的这个。
通过这个类可以知道所建立的索引库在磁盘上,能永久性的保存数据。这是优点
缺点为因为程序要访问磁盘上的数据,这个操作可能引发大量的IO操作,会降低性能。
5.1.2.2RAMDirectory
通过构造函数的形式Directory
ramdirectory = new RAMDirectory(fsdirectory)可以建立RAMDirectory。这种方法建立的索引库会在内存中开辟一定的空间,通过构造函数的形式把fsdirectory移动到内存中。
这种方法索引库中的数据是暂时的,只要内存的数据消失,这个索引库就跟着消失了。
因为程序是在内存中跟索引库交互,所以利用这种方法创建的索引的好处就在效率比较高,访问速度比较快。
5.1.3
Document
通过无参的构造函数可以创建一个Document对象。Document
doc = new Document();一个Directory是由很多Document组成的。用户从客户端输入的要搜索的关键内容被服务器端包装成JavaBean,然后再转化为Document。这个转化过程的代码如下:

5.1.4
Field
Field相当于JavaBean的属性。
Field的用法为:
new
Field("title",article.getTitle(),Store.YES,Index.ANALYZED)
第一个参数为属性
第二个参数为属性值
第三个参数为是否往索引库里存储
第四个参数为是否更新引索
NO
不进行引索ANALYZED
进行分词引索NOT_ANALYZED
进行引索,把整个输入作为一个词对待。
5.1.5
MaxFieldLength
能存储的最大长度
在IndexWriter的构造方法里使用
值为:
LIMITED
限制的最大长度值为10000UNLIMITED 没有限制的最大长度(一般不使用)
Lucene学习笔记一的更多相关文章
- Lucene学习笔记(更新)
1.Lucene学习笔记 http://www.cnblogs.com/hanganglin/articles/3453415.html
- Apache Lucene学习笔记
Hadoop概述 Apache lucene: 全球第一个开源的全文检索引擎工具包 完整的查询引擎和搜索引擎 部分文本分析引擎 开发人员在此基础建立完整的全文检索引擎 以下为转载:http://www ...
- Lucene学习笔记
师兄推荐我学习Lucene这门技术,用了两天时间,大概整理了一下相关知识点. 一.什么是Lucene Lucene即全文检索.全文检索是计算机程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明 ...
- Lucene学习笔记: 四,Lucene索引过程分析
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后 ...
- Lucene学习笔记1(V7.1)
Lucene是一个搜索类库,solr.nutch和elasticsearch都是基于Lucene.个人感觉学习高级搜索引擎应用程序之前 有必要了解Lucene. 开发环境:idea maven spr ...
- Lucene学习笔记:基础
Lucence是Apache的一个全文检索引擎工具包.可以将采集的数据存储到索引库中,然后在根据查询条件从索引库中取出结果.索引库可以存在内存中或者存在硬盘上. 本文主要是参考了这篇博客进行学习的,原 ...
- Lucene学习笔记: 五,Lucene搜索过程解析
一.Lucene搜索过程总论 搜索的过程总的来说就是将词典及倒排表信息从索引中读出来,根据用户输入的查询语句合并倒排表,得到结果文档集并对文档进行打分的过程. 其可用如下图示: 总共包括以下几个过程: ...
- lucene学习笔记:三,Lucene的索引文件格式
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- lucene学习笔记:二,Lucene的框架
Lucene总的来说是: 一个高效的,可扩展的,全文检索库. 全部用Java实现,无须配置. 仅支持纯文本文件的索引(Indexing)和搜索(Search). 不负责由其他格式的文件抽取纯文本文件, ...
- Lucene学习笔记:一,全文检索的基本原理
一.总论 根据http://lucene.apache.org/java/docs/index.html定义: Lucene是一个高效的,基于Java的全文检索库. 所以在了解Lucene之前要费一番 ...
随机推荐
- php 裁剪图片并处理png图片背景变黑
/*TODO 图片裁剪*/ function img_cutting($file_old,$file_new,$h,$w){ $image = $file_old; // 原图 $dir = 'xxx ...
- 【C语言】分别用下标法,地址法和指针法输出数组中的全部元素
#include<stdio.h> int main() { ] = { ,,,, }; int i, * p; printf("下标法:\n"); ; i < ...
- 如何使用git和github
转载:https://www.cnblogs.com/cxscode/p/8325064.html 如何用git将项目代码上传到github 先上常用语句 git add . git commit - ...
- RedHat7.0 网络源的配置
RedHat7.0 yum源的配置 写这篇随笔的目的 为了记录自己的操作,能够为以后的再次配置提供参考 因为网上的教程都有些年代了,为了方便其他同学方便配置 提高下自己的写作水平 参考资料 RedHa ...
- Atcoder Beginner Contest145E(01背包记录路径)
#define HAVE_STRUCT_TIMESPEC#include<bits/stdc++.h>using namespace std;int a[3007],b[3007];int ...
- QBImagePickerController 不可选择照片流中照片
因为QBImagePickerController使用的ALAssetsLibrary方式来读取图片,如果采用默认方式去执行,那么根据url读取到的asset会为空,这时候我们就 需要特殊处理 [se ...
- http的长连接和短连接(史上最通俗!)
1.以前的误解 很久之前就听说过长连接的说法,而且还知道HTTP1.0协议不支持长连接,从HTTP1.1协议以后,连接默认都是长连接.但终究觉得对于长连接一直懵懵懂懂的,有种抓不到关键点的感觉. 今天 ...
- python中,字符串前的u,b,r字符的含义
1.字符串前加 u 例:u"我是含有中文字符组成的字符串." 作用: 后面字符串以 Unicode 格式 进行编码,一般用在中文字符串前面,防止因为源码储存格式问题,导致再次使用时 ...
- springboot学习4使用日志:logback
springboot学习4使用日志:logback 一.基本知识说明 SpringBoot默认使用logback作为日志框架 ,所以引入起步依赖后就可以直接使用logback,不需要其他依赖. Spr ...
- EasyUI tree的三种选中状态
EasyUI中tree有三种选中状态,分别是checked(选中).unchecked(未选中).indeterminate(部分选中). 其中indeterminate状态比较特殊,主要表示只有部分 ...