Mysql:小主键,大问题
今日格言:让一切回归原点,回归最初的为什么。
本篇讲解 Mysql 的主键问题,从为什么的角度来了解 Mysql 主键相关的知识,并拓展到主键的生成方案问题。再也不怕被问到 Mysql 时只知道 CRUD 了。
一、为什么需要主键
- 数据记录需具有唯一性(第一范式)
- 数据需要关联 join
- 数据库底层索引用于检索数据所需
以下废话连篇,可以直接跳过到下一节。
“信息是用来消除随机不定性的东西”(香农)。人通过获得、识别自然界和社会的不同信息来区别不同事物,得以认识和改造世界。数据是反映客观事物属性的记录,是信息的具体表现形式。数据经过加工处理之后,就成为信息;而信息需要经过数字化转变成数据才能存储和传输。数据库就是用于存储数据记录的。既已如此,记录便是具有确定性(相对)的信息,其确定性即唯一性。我们得出第一条原因:
1.数据记录需具有唯一性
世界是由客观存在及其关系组成的。数据是数字化和模型化的存在关系。数据除了本身的描述价值外,其价值还在于其相互关联性。为实现关联的准确性,数据需要有对外相互关联的标识。所以体现在数据存储上,主键的第二作用,也是存在的第二因素即:
2.数据需要关联
数据用于描述客观实在的,本身没有意义。只有在根据主观需求组织之后,通过一定方式满足人认识事物的过程才具有了意义。所以数据需要被检索,被组织。则主键第三个作用:
3.数据库底层索引用于检索数据所需
二、为什么主键不宜过长
这个问题的点在长上。那短比长有什么优势?(嘿嘿嘿,内涵)—— 短不占空间。但这么点磁盘空间相对整个数据量来说微不足道,而且我们一般不怎么用到主键列。那么原因应该在快上,而且和原始数据关系不大。以此自然得出和索引相关,而且和索引读取相关。那么为什么长主键在索引中会影响性能?
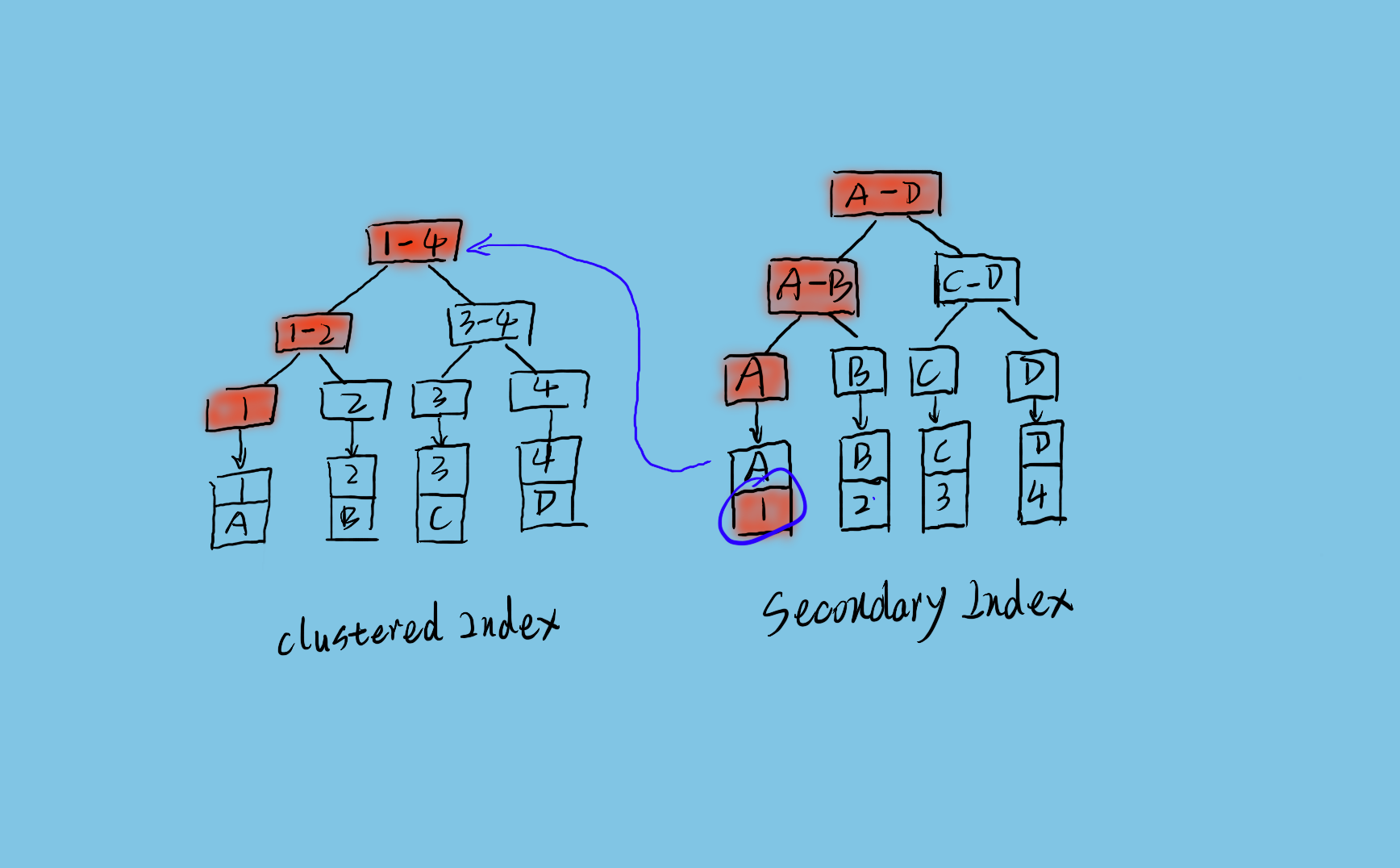
上面是 Innodb 的索引数据结构。左边是聚簇索引,通过主键定位数据记录。右边是二级索引,对列数据做索引,通过列数据查找数据主键。如果通过二级索引查询数据,流程如图上所示,先从二级索引树上搜索到主键,然后在聚簇索引上通过主键搜索到数据行。其中二级索引的叶子节点是直接存储的主键值,而不是主键指针。所以如果主键太长,一个二级索引树所能存储的索引记录就会变少,这样在有限的索引缓冲中,需要读取磁盘的次数就会变多,所以性能就会下降。
三、为什么建议使用自增 ID
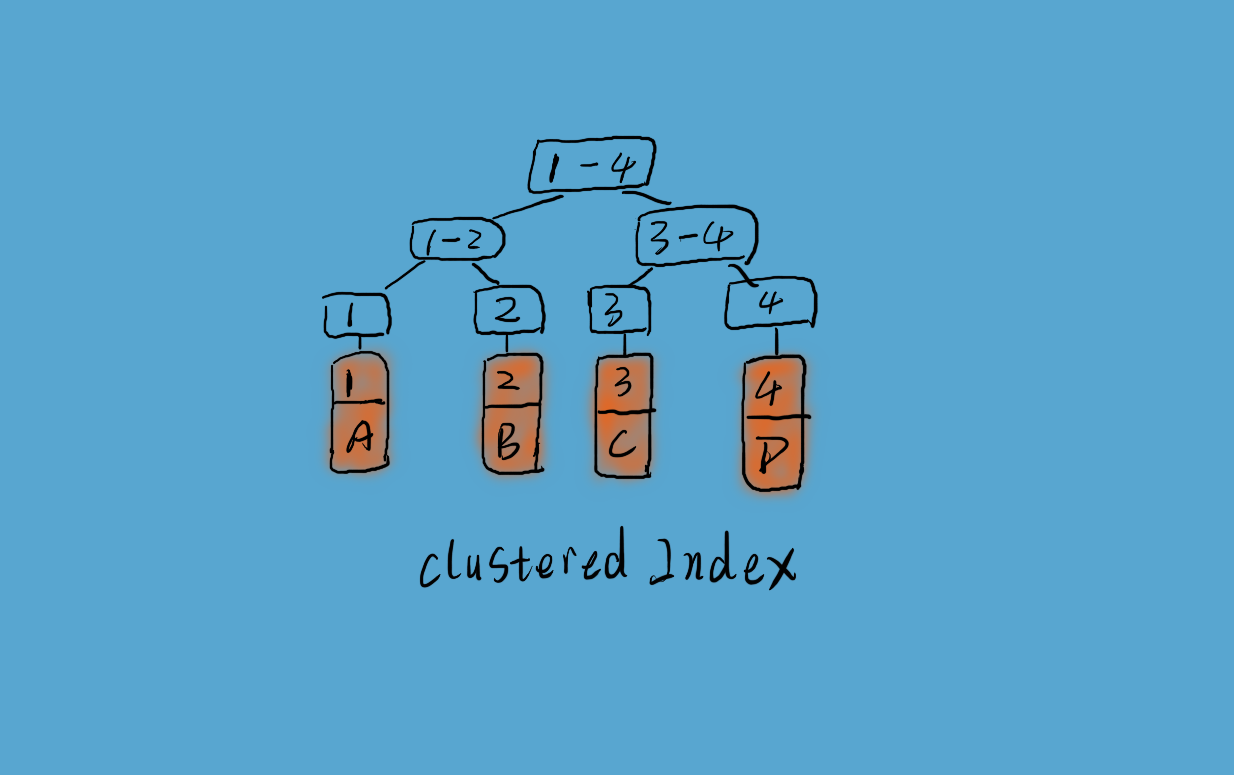
InnoDB 使用聚簇索引,如上图所示,数据记录本身被存于主索引(一颗 B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL 会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB 默认为 15/16),则开辟一个新的页(节点)。
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上,如下图左侧所示。否则由于每次插入主键的值近似于随机,因此每次新记录都要被插到现有索引页的中间某个位置,MySQL 不得不为了将新记录插到合适位置而移动数据,如下图右侧所示,这样就造成了一定的开销。由于此,Mysql 为维护索引可能需要频繁的刷新缓冲,增加了方法磁盘 IO 的次数,而且时常需要对索引结构进行重组织。

四、业务 Key VS 逻辑 Key
业务 Key,即使用具有业务意义的 id 作为 Key,比如使用订单流水号作为订单表的主键 Key。逻辑 Key,即无关业务的 Key,按某种规则生成 Key,如自增 Key。
业务 Key 的优点
- Key 具有业务意义,在查询时可以直接作为搜索关键字使用
- 不需要额外的列和索引空间
- 可以减少一些 join 操作。
业务 Key 的缺点
- 当业务发生变化时,有时需要变更主键
- 涉及多列 Key 时比较难操作
- 业务 Key 往往比较长,所占空间更大,导致更大的磁盘 IO
- 在 Key 确定前不能持久化数据,有时我们没有在确定数据 Key 时,就想先添加一条记录,之后再更新业务 Key
- 设计一个兼具易用和性能的 Key 生成方案比较难
逻辑 Key 的优点
- 不会因为业务的变动而需要修改 Key 逻辑
- 操作简单,且易于管理
- 逻辑 Key 往往更小,性能更优
- 逻辑 Key 更容易保证唯一性
- 更易于优化
逻辑 Key 缺点
- 查询主键列和主键索引需要额外的磁盘空间
- 在插入数据和更新数据时需要额外的 IO
- 更多的 join 可能
- 如果没有唯一性策略限制,容易出现重复的 Key
- 测试环境和正式环境 Key 不一致,不利于排查问题
- Key 的值没有和数据关联,不符合三范式
- 不能用于搜索关键字
- 依赖不同数据库系统的具体实现,不利于底层数据库的替换
五、主键生成
一般情况下,我们都使用 Mysql 的自增 ID,来作为表的主键,这样简单,而且从上面讲到的来看,性能也是最好的。但是在分库分表的情况情况下,自增 ID 则不能满足需求。我们可以来看看不同数据库生成 ID 的方式,也看一些分布式 ID 生成方案。利于我们思考甚至实现自己的分布式 ID 生成服务。
数据库的实现
Mysql 自增
Mysql 在内存中维护一个自增计数器,每次访问 auto-increment 计数器的时候, InnoDB 都会加上一个名为AUTO-INC 锁直到该语句结束(注意锁只持有到语句结束,不是事务结束)。AUTO-INC 锁是一个特殊的表级别的锁,用来提升包含 auto_increment 列的并发插入性。
在分布式的情况下,其实可以独立一个服务和数据库来做 id 生成,依旧依赖 Mysql 的表 id 自增能力来为第三方服务统一生成 id。为性能考虑可以不同业务使用不同的表。
Mongodb ObjectId
Mongodb 为防止主键冲突,设计了一个 ObjectId 作为主键 id。它由一个 12 字节的十六进制数字组成,其中包含以下几部分:
Time:时间戳。4 字节。秒级。
Machine:机器标识。3 字节。一般是机器主机名的散列值,这样就确保了不同主机生成不同的机器 hash 值,确保在分布式中不造成冲突,同一台机器的值相同。
PID:进程 ID。2 字节。上面的 Machine 是为了确保在不同机器产生的 objectId 不冲突,而 pid 就是为了在同一台机器不同的 mongodb 进程产生的 objectId 不冲突。
INC:自增计数器。3 字节。前面的九个字节保证了一秒内不同机器不同进程生成的 objectId 不冲突,自增计数器,用来确保在同一秒内产生的 objectId 也不会发现冲突,允许 256 的 3 次方等于 16777216 条记录的唯一性。
Cassandra TimeUUID
Cassandra 使用下面规则生成一个唯一的 id:time + MAC + sequence
方案
- Zookeeper 自增:通过 zk 的自增机制实现。
- Redis 自增:通过 Redis 的自增机制实现。
- UUID:使用 UUID 字符串作为 Key。
- snowflake 算法:和 Mongodb 的实现类似,
1位符号位 + 41位时间戳(毫秒级)+ 10位数据机器位 + 12位毫秒内的序列。
开源实现
- 百度 UidGenerator:基于snowflake算法。
- 美团 Leaf:同时实现了基于 Mysql 自增(优化)和 snowflake 算法的机制。
推荐系列
列式存储
时间序列数据库(TSDB)初识与选择
十分钟了解 Apache Druid
Apache Druid 底层存储设计
Apache Druid 的集群设计与工作流程
Mysql 大表问题和解决
想了解更多数据存储相关知识,请关注我的公众号。

Mysql:小主键,大问题的更多相关文章
- mysql 外键约束备注
梳理mysql外键约束的知识点. 1.mysql外键约束只对InnoDb引擎有效: 2.创建外键约束如下: DROP TABLE IF EXISTS t_demo_product; CREATE TA ...
- MySQL外键之级联
简介 MySQL外键起到约束作用,在数据库层面保证数据的完整性.例如使用外键的CASCADE类型,当子表(例如user_info)关联父表(例如user)时,父表更新或删除时,子表会更新或删除记录,这 ...
- PowerDesigner 15设置mysql主键自动增长及基数
PowerDesigner 15设置mysql主键自动增长及基数 1.双击标示图,打开table properties->columns, 如图点击图标Customize Columns an ...
- MySQL外键与外键关系说明(简单易懂)
MySQL主键和外键使用及说明 一.外键约束 MySQL通过外键约束来保证表与表之间的数据的完整性和准确性. 外键的使用条件: 1.两个表必须是InnoDB表,MyISAM表暂时不支持外键(据说以后 ...
- MySQL主键设计
[TOC] 在项目过程中遇到一个看似极为基础的问题,但是在深入思考后还是引出了不少问题,觉得有必要把这一学习过程进行记录. MySQL主键设计原则 MySQL主键应当是对用户没有意义的. MySQL主 ...
- mysql外键实战
一.基本概念 1.MySQL中“键”和“索引”的定义相同,所以外键和主键一样也是索引的一种.不同的是MySQL会自动为所有表的主键进行索引,但是外键字段必须由用户 进行明确的索引.用于外键关系的字段必 ...
- MYSQL主键自动增加的配置及auto_increment注意事项
文章一 原文地址: http://ej38.com/showinfo/mysql-202971.html 文章二: 点击转入第二篇文章 在数据库应用,我们经常要用到唯一编号.在MySQL中可通过字 ...
- 获得自动增长的MySQL主键
下面的脚本教您如何获得自动增长的MySQL主键,如果您对MySQL主键方面感兴趣的话,不妨一看,相信对您学习MySQL主键方面会有所启迪. import java.sql.Connection; im ...
- mysql外键详解
1.1.MySQL中“键”和“索引”的定义相同,所以外键和主键一样也是索引的一种.不同的是MySQL会自动为所有表的主键进行索引,但是外键字段必须由用户进行明确的索引.用于外键关系的字段必须在所有的参 ...
随机推荐
- P3916 图的遍历 题解
原题链接 简要题意: 求从每个点开始,可以到达的编号最大的点. 我们只要发现一条性质,这题就变得挺简单了. 你想,如果从每个点开始走,分别遍历,肯定是不科学的. 因为是有向图,所以当前点 \(x\) ...
- python-pathlib
2019-12-12 04:27:17 我们知道在不同的操作系统中文件路径的组成方式是不同的,因此在python中关于路径的问题以往我们通常采用os.path.join来进行路径的字符串级别的串联,通 ...
- k8s可视化工具kubernetes-dashboard部署——小白教程
参考资料: kubernetes官方文档 官方GitHub 创建访问用户 解决chrome无法访问dashboard 官方部署方法如下: kubectl apply -f https://raw.gi ...
- coding++:Spring Boot 全局事务解释及使用(二)
什么是全局事务: Spring Boot(Spring) 事务是通过 aop(aop相关术语:通知(Advice).连接点(Joinpoint).切入点(Pointcut).切面(Aspect).目标 ...
- 怎么获取WebAPI项目中图片在服务端的路径
1.这是我的项目结构. 2.路径格式为:[http://服务器域名/文件夹/文件.扩展名] 测试:假如我要获取到[logo_icon.jpg]这张图.在浏览器的地址栏中输入上面那个格式的路径. 3.可 ...
- CoderForces 327D Block Tower
Portal:http://codeforces.com/problemset/problem/327/D 一座红塔200人,一座蓝塔100人,只有与蓝塔相邻才可以建红塔. '.'处可建塔 '#'处不 ...
- Blazor入门笔记(6)-组件间通信
1.环境 VS2019 16.5.1.NET Core SDK 3.1.200Blazor WebAssembly Templates 3.2.0-preview2.20160.5 2.简介 在使用B ...
- pyspider_初始
一.简介 1.1.简介 pyspider 是一个使用python编写,并且拥有强大功能web界面的爬虫框架. 强大的web界面可进行脚本编辑,任务监控,项目管理,结果查看等功能. pyspider支持 ...
- 1031 Hello World for U (20分)
Given any string of N (≥) characters, you are asked to form the characters into the shape of U. For ...
- 基于 Hudi 和 Kylin 构建准实时高性能数据仓库
在近期的 Apache Kylin × Apache Hudi Meetup直播上,Apache Kylin PMC Chair 史少锋和 Kyligence 解决方案工程师刘永恒就 Hudi + K ...