林轩田机器学习基石课程学习笔记5 — Training versus Testing
上节课,我们主要介绍了机器学习的可行性。首先,由NFL定理可知,机器学习貌似是不可行的。但是,随后引入了统计学知识,如果样本数据足够大,且hypothesis个数有限,那么机器学习一般就是可行的。本节课将讨论机器学习的核心问题,严格证明为什么机器可以学习。从上节课最后的问题出发,即当hypothesis的个数是无限多的时候,机器学习的可行性是否仍然成立?
一、Recap and Preview
我们先来看一下基于统计学的机器学习流程图:
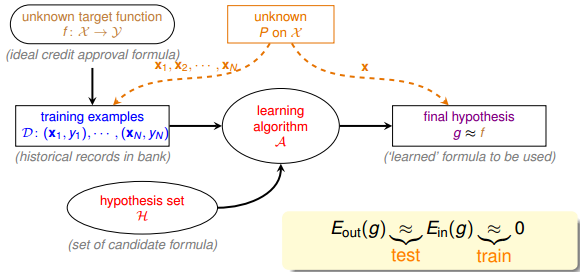
该流程图中,训练样本D和最终测试h的样本都是来自同一个数据分布,这是机器能够学习的前提。另外,训练样本D应该足够大,且hypothesis set的个数是有限的,这样根据霍夫丁不等式,才不会出现Bad Data,保证Ein≈Eout,即有很好的泛化能力。同时,通过训练,得到使Ein最小的h,作为模型最终的矩g,g接近于目标函数。
这里,我们总结一下前四节课的主要内容:第一节课,我们介绍了机器学习的定义,目标是找出最好的矩g,使g≈f,保证Eout(g)≈0;第二节课,我们介绍了如何让Ein≈0,可以使用PLA、pocket等演算法来实现;第三节课,我们介绍了机器学习的分类,我们的训练样本是批量数据(batch),处理监督式(supervised)二元分类(binary classification)问题;第四节课,我们介绍了机器学习的可行性,通过统计学知识,把Ein(g)与Eout(g)联系起来,证明了在一些条件假设下,Ein(g)≈Eout(g)成立。

这四节课总结下来,我们把机器学习的主要目标分成两个核心的问题:
- Ein(g)≈Eout(g)
Ein(g)足够小
上节课介绍的机器学习可行的一个条件是hypothesis set的个数M是有限的,那M跟上面这两个核心问题有什么联系呢?
我们先来看一下,当M很小的时候,由上节课介绍的霍夫丁不等式,得到Ein(g)≈Eout(g),即能保证第一个核心问题成立。但M很小时,演算法A可以选择的hypothesis有限,不一定能找到Ein(g)足够小的hypothesis,即不能保证第二个核心问题成立。当M很大的时候,同样由霍夫丁不等式,Ein(g)与Eout(g)的差距可能比较大,第一个核心问题可能不成立。而M很大,使的演算法A的可以选择的hypothesis就很多,很有可能找到一个hypothesis,使Ein(g)足够小,第二个核心问题可能成立。

从上面的分析来看,M的选择直接影响机器学习两个核心问题是否满足,M不能太大也不能太小。那么如果M无限大的时候,是否机器就不可以学习了呢?例如PLA算法中直线是无数条的,但是PLA能够很好地进行机器学习,这又是为什么呢?如果我们能将无限大的M限定在一个有限的mH内,问题似乎就解决了。
二、Effective Number of Line

也就是说union bound被估计过高了(over-estimating)。所以,我们的目的是找出不同BAD events之间的重叠部分,也就是将无数个hypothesis分成有限个类别。
如何将无数个hypothesis分成有限类呢?我们先来看这样一个例子,假如平面上用直线将点分开,也就跟PLA一样。如果平面上只有一个点x1,那么直线的种类有两种:一种将x1划为+1,一种将x1划为-1:
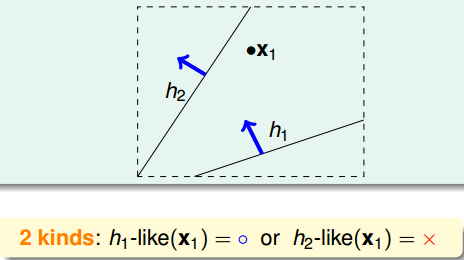
如果平面上有两个点x1、x2,那么直线的种类共4种:x1、x2都为+1,x1、x2都为-1,x1为+1且x2为-1,x1为-1且x2为+1:

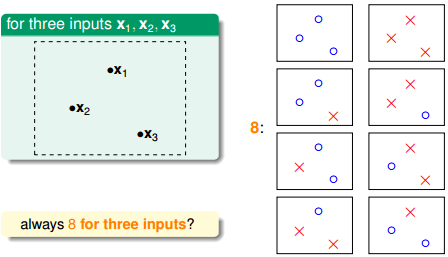
如果平面上有三个点x1、x2、x3,那么直线的种类共8种:
但是,在三个点的情况下,也会出现不能用一条直线划分的情况:
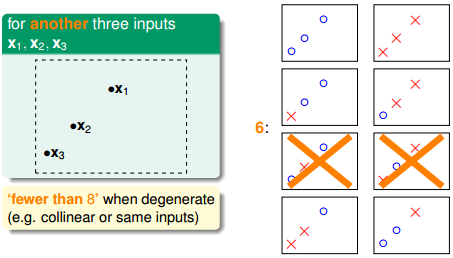
也就是说,对于平面上三个点,不能保证所有的8个类别都能被一条直线划分。那如果是四个点x1、x2、x3、x4,我们发现,平面上找不到一条直线能将四个点组成的16个类别完全分开,最多只能分开其中的14类,即直线最多只有14种:
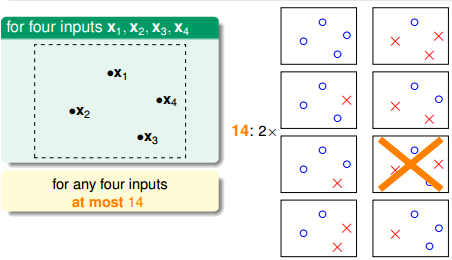

三、Effective Number of Hypotheses
接下来先介绍一个新名词:二分类(dichotomy)。dichotomy就是将空间中的点(例如二维平面)用一条直线分成正类(蓝色o)和负类(红色x)。令H是将平面上的点用直线分开的所有hypothesis h的集合,dichotomy H与hypotheses H的关系是:hypotheses H是平面上所有直线的集合,个数可能是无限个,而dichotomy H是平面上能将点完全用直线分开的直线种类,它的上界是2^N。接下来,我们要做的就是尝试用dichotomy代替M。

再介绍一个新的名词:成长函数(growth function),记为m_H(H)mH(H)。成长函数的定义是:对于由N个点组成的不同集合中,某集合对应的dichotomy最大,那么这个dichotomy值就是mH(H),它的上界是2^N:
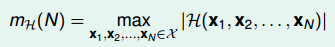
成长函数其实就是我们之前讲的effective lines的数量最大值。根据成长函数的定义,二维平面上,mH(H)随N的变化关系是:

接下来,我们讨论如何计算成长函数。先看一个简单情况,一维的Positive Rays:

若有N个点,则整个区域可分为N+1段,很容易得到其成长函数m_H(N)=N+1mH(N)=N+1。注意当N很大时,2^N(N+1)<<2N,这是我们希望看到的。
另一种情况是一维的Positive Intervals:

它的成长函数可以由下面推导得出:

这种情况下,在N很大的时候,仍然是满足的。
再来看这个例子,假设在二维空间里,如果hypothesis是凸多边形或类圆构成的封闭曲线,如下图所示,左边是convex的,右边不是convex的。那么,它的成长函数是多少呢?

当数据集D按照如下的凸分布时,我们很容易计算得到它的成长函数m_H=2^N。这种情况下,N个点所有可能的分类情况都能够被hypotheses set覆盖,我们把这种情形称为shattered。也就是说,如果能够找到一个数据分布集,hypotheses set对N个输入所有的分类情况都做得到,那么它的成长函数就是2^N。
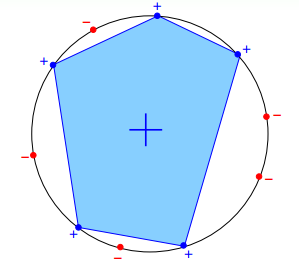
四、Break Point
上一小节,我们介绍了四种不同的成长函数,分别是:

其中,positive rays和positive intervals的成长函数都是polynomial的,如果用mH代替M的话,这两种情况是比较好的。而convex sets的成长函数是exponential的,即等于M,并不能保证机器学习的可行性。那么,对于2D perceptrons,它的成长函数究竟是polynomial的还是exponential的呢?
对于2D perceptrons,我们之前分析了3个点,可以做出8种所有的dichotomy,而4个点,就无法做出所有16个点的dichotomy了。所以,我们就把4称为2D perceptrons的break point(5、6、7等都是break point)。令有k个点,如果k大于等于break point时,它的成长函数一定小于2的k次方。
根据break point的定义,我们知道满足的k的最小值就是break point。对于我们之前介绍的四种成长函数,他们的break point分别是:
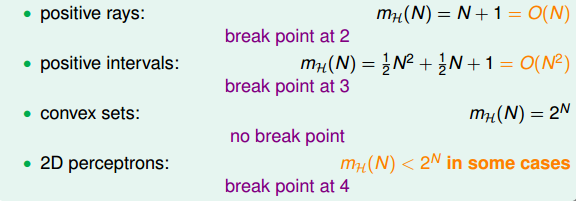
通过观察,我们猜测成长函数可能与break point存在某种关系:对于convex sets,没有break point,它的成长函数是2的N次方;对于positive rays,break point k=2,它的成长函数是O(N);对于positive intervals,break point k=3,它的成长函数是O(N^2)O(N2)。则根据这种推论,我们猜测2D perceptrons,它的成长函数mH(N)=O(Nk−1) 。如果成立,那么就可以用m_HmH代替M,就满足了机器能够学习的条件。关于上述猜测的证明,我们下节课再详细介绍。
五、总结
本节课,我们更深入地探讨了机器学习的可行性。我们把机器学习拆分为两个核心问题:Ein(g)≈Eout(g)和Ein(g)≈0。对于第一个问题,我们探讨了M个hypothesis到底可以划分为多少种,也就是成长函数m_H。并引入了break point的概念,给出了break point的计算方法。下节课,我们将详细论证对于2D perceptrons,它的成长函数与break point是否存在多项式的关系,如果是这样,那么机器学习就是可行的。
林轩田机器学习基石课程学习笔记5 — Training versus Testing的更多相关文章
- (转载)林轩田机器学习基石课程学习笔记1 — The Learning Problem
(转载)林轩田机器学习基石课程学习笔记1 - The Learning Problem When Can Machine Learn? Why Can Machine Learn? How Can M ...
- 林轩田机器学习基石笔记3—Types of Learning
上节课我们主要介绍了解决线性分类问题的一个简单的方法:PLA.PLA能够在平面中选择一条直线将样本数据完全正确分类.而对于线性不可分的情况,可以使用Pocket Algorithm来处理.本节课将主要 ...
- 林轩田机器学习基石笔记1—The Learning Problem
机器学习分为四步: When Can Machine Learn? Why Can Machine Learn? How Can Machine Learn? How Can Machine Lear ...
- 林轩田机器学习基石笔记4—Feasibility of Learning
上节课介绍了机器学习可以分为不同的类型.其中,监督式学习中的二元分类和回归分析是最常见的也是最重要的机器学习问题.本节课,我们将介绍机器学习的可行性,讨论问题是否可以使用机器学习来解决. 一.Lear ...
- 林轩田机器学习基石笔记2—Learning to Answer Yes/No
机器学习的整个过程:根据模型H,使用演算法A,在训练样本D上进行训练,得到最好的h,其对应的g就是我们最后需要的机器学习的模型函数,一般g接近于目标函数f.本节课将继续深入探讨机器学习问题,介绍感知机 ...
- 【The VC Dimension】林轩田机器学习基石
首先回顾上节课末尾引出来的VC Bound概念,对于机器学习来说,VC dimension理论到底有啥用. 三点: 1. 如果有Break Point证明是一个好的假设集合 2. 如果N足够大,那么E ...
- 【 Logistic Regression 】林轩田机器学习基石
这里提出Logistic Regression的角度是Soft Binary Classification.输出限定在0~1之间,用于表示可能发生positive的概率. 具体的做法是在Linear ...
- 【Linear Regression】林轩田机器学习基石
这一节开始讲基础的Linear Regression算法. (1)Linear Regression的假设空间变成了实数域 (2)Linear Regression的目标是找到使得残差更小的分割线(超 ...
- 【Theory of Generalization】林轩田机器学习基石
紧接上一讲的Break Point of H.有一个非常intuition的结论,如果break point在k取到了,那么k+1, k+2,... 都是break point. 那么除此之外,我们还 ...
随机推荐
- Digit sum (第 44 届 ACM/ICPC 亚洲区域赛(上海)网络赛)进制预处理水题
131072K A digit sum S_b(n)Sb(n) is a sum of the base-bb digits of nn. Such as S_{10}(233) = 2 + 3 ...
- 201771010123汪慧和《面向对象程序设计Java》第二周学习总结
一.理论知识部分 1.标识符由字母.下划线.美元符号和数字组成, 且第一个符号不能为数字.标识符可用作: 类名.变量名.方法名.数组名.文件名等.第二部分:理论知识学习部分 2.关键字就是Java语言 ...
- css伪元素::before与::after使用基础示例
1.指定文本前后添加内容 <div class="box">test</div> .box::before{ content: 'before'; marg ...
- 18 11 12 网络通信 tcp
tec 客户端的接受代码 import socket def main(): # 1. 创建tcp的套接字 tcp_socket = socket.socket(socket.AF_INET, soc ...
- OpenCV和Qt的图像格式互转
做图像处理的时候经常使需要用到opencv的,这应该是免费的图像处理库中用得最广泛而且最好用的库了吧.然后有时候想用界面来展示点东西的时候,我们就需要编写个界面,编写界面的方法千千万,弱水三千我只取一 ...
- Java目录下文件夹的含义和运行机制
Java安装目录下的各个文件夹的意义 >bin 放置Java所有的可执行文件 >include 一些C语言的头文件 >jre Java的运行环境 >lib Java的类库文件 ...
- delphi数据类型列表
Delphi 数据类型列表 分类 范围 字节 备注 简单类型 序数 整数 Integer -2147483648 .. 2147483647 4 有符号32位 Cardinal 0 .. 429496 ...
- selenium滚动条应用,爬永远讲不完的故事
from selenium import webdriver class Lj(object): def __init__(self): self.driver = webdriver.Chrome( ...
- 题解 P1829 【[国家集训队]Crash的数字表格 / JZPTAB】
题目 我的第一篇莫比乌斯反演题解 兴奋兴奋兴奋 贡献一个本人自己想的思路,你从未看到过的船新思路 [分析] 显然,题目要求求的是 \(\displaystyle Ans=\sum_{i=1}^n\su ...
- UML-领域模型-如何找到概念类
有3个方法 方法1:对已有的重用和修改(这是最好的方法) 重用和修改现有模型.这些模型来源于之前的项目.网上的 方法2:使用分类列表 从网上搜索该领域的常见分类,或参考书籍Martin Fowler的 ...