RDD(七)——依赖
概述
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
示例代码如下:
def main(args: Array[String]): Unit = {
val sc: SparkContext = new SparkContext(new SparkConf()
.setMaster("local[*]").setAppName("spark"))
val f: RDD[(String, Int)] = sc.parallelize(Array("hello,spark", "hello,scala", "hello,world"))
.flatMap(_.split(" "))
.map((_, 1))
print(f.toDebugString)//查看依赖信息
println(f.dependencies)//查看依赖类型
}
它的依赖信息如下:
(8) MapPartitionsRDD[2] at map at Lineage.scala:11 []
| MapPartitionsRDD[1] at flatMap at Lineage.scala:10 []
| ParallelCollectionRDD[0] at parallelize at Lineage.scala:9 []
从上往下,依次是RDD的转换过程。通过这些信息,当链条中的任意一个RDD的部分分区数据丢失时,它可以根据这些信息重新进行运算,恢复丢失的分区数据。
窄依赖、宽依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用。窄依赖我们形象的比喻为独生子女。
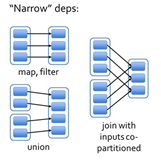
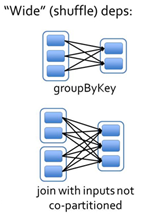
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle.宽依赖我们形象的比喻为超生
任务划分
RDD任务切分分为:Application、Job、Stage和Task
1)Application:初始化一个SparkContext即生成一个ApplicationMaster
2)Job:一个Action算子就会生成一个Job
3)Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖(shuffle)则划分一个Stage。
4)task:一个RDD有多个分区,一个分区在一个executor尚的执行就可以算作一个task
对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
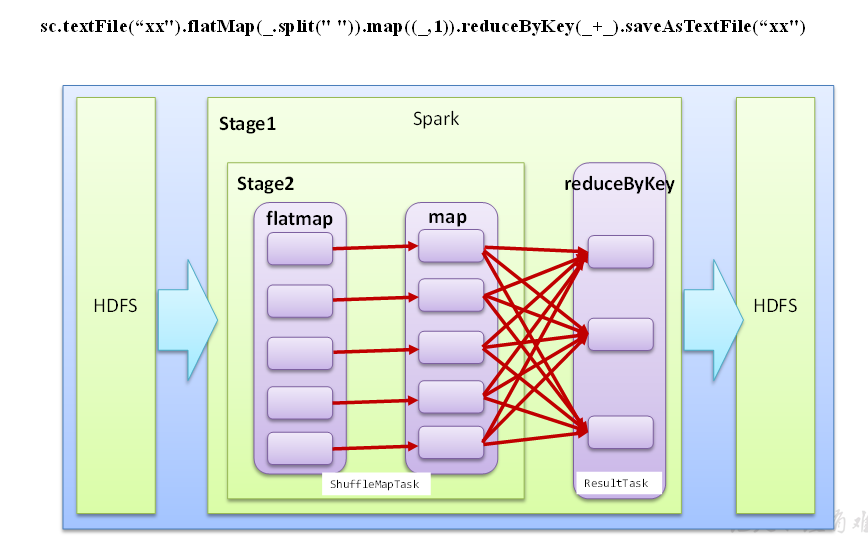
阶段划分过程如下:
首先无论如何要有一个阶段,这是一个总体的阶段。然后再看中间有多少个shuffle过程,遇到一个shuffle,则切分出一个阶段。
textFile方法从HDFS文件系统读取数据;flatMap,map方法均没有shuffle过程,不能形成阶段;reduceByKey有shuffle过程,可以形成阶段。总共有两个阶段。
RDD(七)——依赖的更多相关文章
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- RDD的依赖关系
RDD的依赖关系 Rdd之间的依赖关系通过rdd中的getDependencies来进行表示, 在提交job后,会通过在DAGShuduler.submitStage-->getMissingP ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- 021 RDD的依赖关系,以及造成的stage的划分
一:RDD的依赖关系 1.在代码中观察 val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data) val resultRD ...
- Spark RDD 窄依赖研究
1.. 简介 spark从RDD依赖上来说分为窄依赖和宽依赖. 其中可以这样区分是哪种依赖:当父RDD的一个partition被子RDD的多个partitions引用到的时候则说明是宽依赖,否则为窄依 ...
- sparkRDD:第4节 RDD的依赖关系;第5节 RDD的缓存机制;第6节 DAG的生成
4. RDD的依赖关系 6.1 RDD的依赖 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency ...
- Spark RDD 宽窄依赖
RDD 宽窄依赖 RDD之间有一系列的依赖关系, 可分为窄依赖和宽依赖 窄依赖 从 RDD 的 parition 角度来看 父 RRD 的 parition 和 子 RDD 的 parition 之间 ...
- 【Spark】RDD的依赖关系和缓存相关知识点
文章目录 RDD的依赖关系 宽依赖 窄依赖 血统 RDD缓存 概述 缓存方式 RDD的依赖关系 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency) 和宽依赖 ...
随机推荐
- Vue 项目de一些准备工作
1.安装node,同时也会自动安装npm,npm是node的一种包安装工具. 2.准备一个git,可以用来管理代码. 3.打开vue官网,可以使用vue-cli脚手架工作. 这里介绍一个element ...
- JAVA基础——使用配置文件
一. 前言 日常我们做项目中,我们经常会遇到这样的情况:由于开发环境和生产环境的不同,项目部署在生产环境之前,有些参数我们并不知道如何取值.例如:数据库链接设定,我们在部署生产环境之前 ...
- HTML-基础标记
HTML, 一种超文本标记语言,顾名思义,要比文本的样式多,而且是由标记组成,还是一门语言. 标记写法 <标记名> <a></a>双标记 超链接 <br /& ...
- SeetaFaceQt:写一个简单的界面
关于这个界面,我用到了几个控件,这些控件通过Qt是非常容易构建的,窗口的话用的是QWidget,之前说了,QWidget是Qt里面几乎大部分控件的父类,QWidget的布局我使用了简单的水平布局(QH ...
- 使用maven打包问题
项目打包:选择项目 右键->run as-> maven install . 项目中使用的是maven项目,将项目打包成war的时候有时候会出现 出现这种情况的时候解决步骤如下: 选择要打 ...
- unable to execute /bin/mv: Argument list too long
四种解决”Argument list too long”参数列表过长的办法 转自 http://hi.baidu.com/cpuramdisk/item/5aa49ce00c0757aecf2d4f2 ...
- 基本 Python 词汇
本文档介绍了要理解“使用 Python 进行地理处理”的帮助文档需要掌握的一些词汇. ! 术语 说明 Python Python 是由 Guido van Rossum 在上世纪八十年代末构想并 ...
- python3 str.encode bytes.decode
str.encode 把字符串编码成字节序列 bytes.decode 把字节序列解码成字符串 https://docs.python.org/3.5/library/stdtypes.html st ...
- 通过编写c语言程序,运行时实现打印另一个程序的源代码和行号
2017年6月1日程序编写说明: 1.实现行号的打印,实现代码的读取和输出,理解主函数中的参数含义. 2.对fgets函数理解不够 3.对return(1); return 0的含义理解不够 4.未实 ...
- UML-类图-箭头
概览 1.泛化 一般理解为 继承.实线+空心箭头 2.依赖 成员变量.局部变量.参数.虚线+箭头 public class Sale { public void updatePriceFor(Prod ...