数据中台技术汇(二)| DataSimba系列之数据采集平台
继上期数据中台技术汇栏目发布DataSimba——企业级一站式大数据智能服务平台,本期介绍DataSimba的数据采集平台。
DataSimba采集平台属于DataSimba的数据计算及服务平台的一部分, 负责数据的导入, 从而支持上层的数据处理。 DataSimba的定位是面向企业私有化部署,决定了采集平台面临要解决的问题和传统的互联网公司不太一样:
1、企业使用的数据库类型多且杂, 包括很多非主流的数据库;
2、企业的数据管理水平参差不齐, 依赖数据规范(如:维护列modify_time判断记录是否修改)的导入方式推行困难;
3、需要支持的场景比较复杂, 包括:流处理、增量处理、批处理;
4、企业的数据平台规模一般较小,资源有限, 需要更好的平衡计算成本与效率。
采集平台总体架构
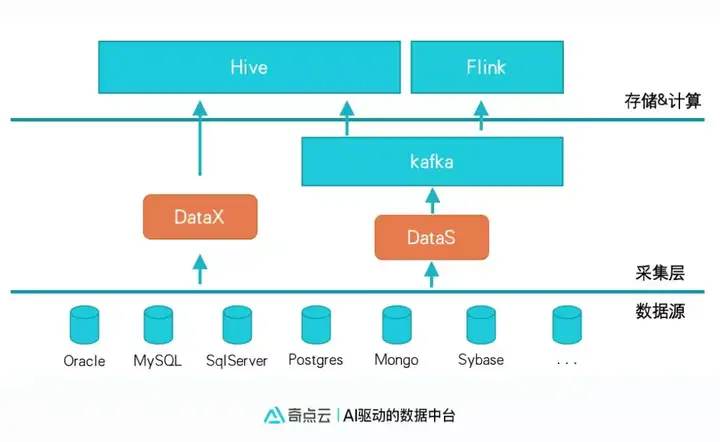
整个采集平台核心为DataX与DataS两个采集组件:
DataX:
·阿里开源的数据集成组件,通过jdbc,以查询的方式支持通用的关系行数据库导入;
·DataSimba 同时支持向导模式和脚本模式。
·可扩展支持NoSQL、FTP等。
DataS:
奇点云针对复杂的企业数据环境开发的, 基于数据库日志(类似binlog)同步数据的工具, 主要特征如下:
·配置简单: 整库导入配置只需要一分钟, 支持实时抽取、增量落盘、全量合并;
·基于数据库Log采集, 以减少对企业现有系统的侵入。 目前支持Mysql, Sqlserver, Oracle, Postgres, MongoDB;
·支持多种业务场景, 包括:实时计算, 增量计算(10m~1h), 全量批处理(>1h);
·高效的数据合并性能, 节省计算资源;
·schema自动同步;
DataX vs DataS:
·DataX通过查询(即Select)方式, 而DataS通过解析数据库日志;
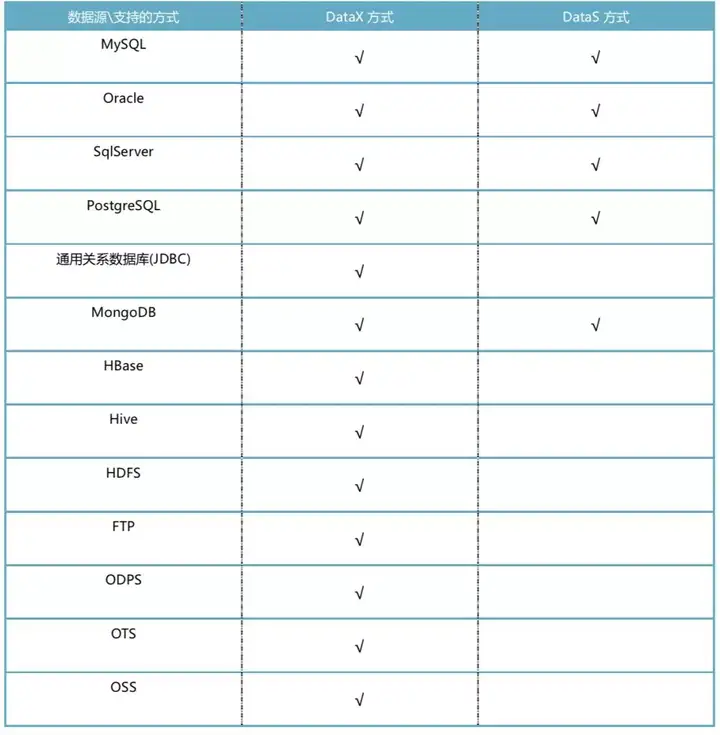
·DataX 支持数据源更广, DataS支持数据源较少(见下表);
·DataX 对数据源压力较大, 而DataS对数据源压力较小;
·DataX 需要数据源有较大的空闲时间窗口, 用于抽取数据。 而DataS不需要;
·DataX 需要维护类似modify_time字段做增量抽取, 而DataS不需要;
·DataX 无法跟踪记录变更过程, DataS可以跟踪;
·DataX 不支持实时数据采集, DataS支持秒级的数据采集;
DataSimba在采集数据时优先使用DataS的方式。
为什么要做DataS
早期的Simba使用DataX导入数据, 在企业部署过程中遇到很多问题, 如:
·某快消企业, 数据库本身的压力就比较大, 且没有大段的空闲窗口用于数据采集, 采用DataX抽取难度较大。
·某企业, 数据库每日增量较少(~10GB), 但全量数据较大(>20T), 导致增量与全量合并的效率较低, 消耗资源比较多。
·某金融企业, 需要在数仓中跟踪账户余额的每一次变动, 又要不侵入现有的业务, 采用DataX的方式无法做到。
·某企业大屏, 需按小时刷新, 统计数据量较大, 采用流式计算成本较高, 实现比较复杂。 采用DataX又无法做到小时以内的采集频率。
以上只是在simba部署过程中碰到的一部分内容。 为了解决碰到的种种问题, 我们最终决定开发一套新的采集工具: DataS。
DataS 技术方案
DataS 的目标是: 配置维护简单, 支持多种数据源, 支持多种应用场景, 尽可能高效。
与cannal/maxwell等binlog采集工具相比, DataS支持更多的数据库类型:
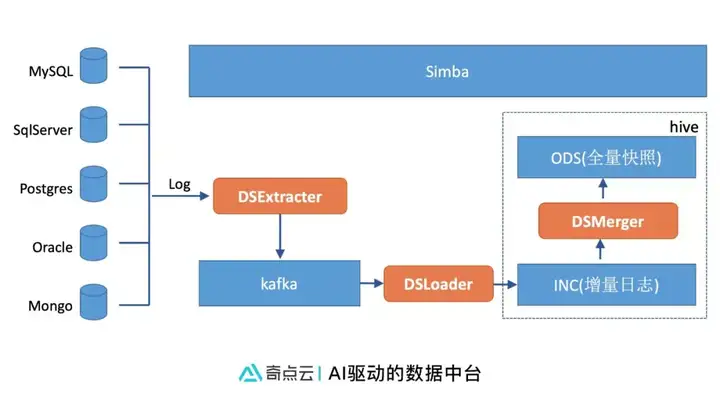
实时采集数据流程
实时采集的主要流程如下:
1、 数据源端创建访问账号, 设置权限和日志配置项
2、 simba平台上配置数据源
3、 simba平台上创建导入任务, 选择导入的库和表, 确定是否合并
4、 发布导入任务
5、 DSExtracter从数据库源拉取全量快照, 作为初始化导入数据
6、 DSExtracter实时解析数据库日志, 以增量的方式解析新增数据到kafka
7、 DSLoader 按照设定的周期(通常是10分钟)将新增数据落盘到增量数据层(INC)
8、 DSMerger 定期(通常是30分钟)将新增数据与全量数据合并到ODS
9、 后续的计算以增量或者全量的方式从ODS层消费数据
技术亮点
一、高效的合并方案
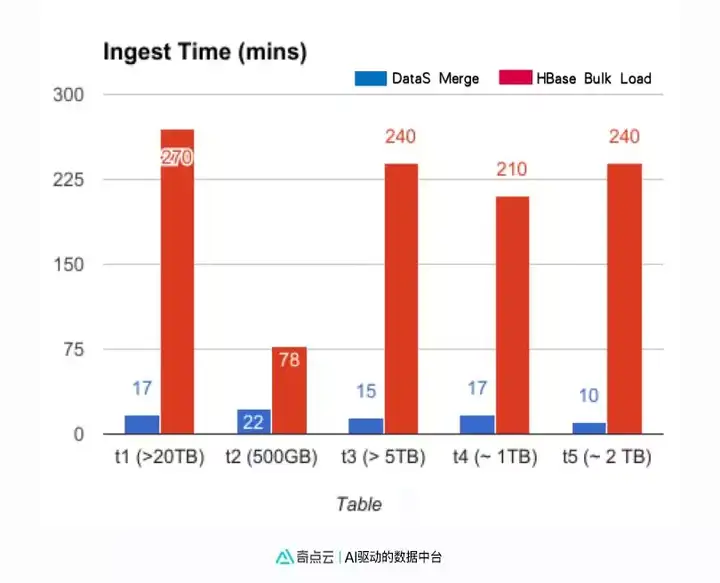
DataS同时保留了增量的日志数据和全量的快照数据, 以支持复杂的企业业务场景。 同时DataS提供了高效的快照合并方案。 以下是DataS合并与基于HBase方案合并的性能比较测试。对于1T以上的数据表增量和全量merge时, DataS有12 ~24 倍的性能提升。
与传统的利用HiveSQL 或者HBase 做merge的方式不同, DataS采用了二级映射的方式, 使最终的合并转化为一个RDD或者一个Map中就可完成的小文件合并, 并避免了不需要合并的文件读取, 如图所示:
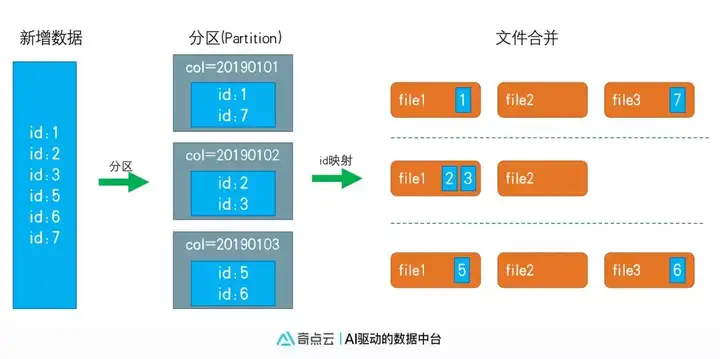
DataS合并逻辑如下:
1、 DataS会将新增数据划分到不同的hive分区中, 分区可以根据业务自定义;
2、 在一个分区内, DataS利用布隆过滤(Bloom Filter)将数据映射到不同的文件;
3、 新增数据和单一存储文件做局部合并;
将整个合并最终划分为小文件的合并, 从而大幅提高了合并的效率。
二. 近实时的数据时延
DataS提供两种合并方式: 写时拷贝(CopyOnWrite)和 读时合并(MergeOnRead)
写时拷贝是指每次增量数据与文件合并时, 都是拷贝两边的数据生成新的全量数据文件。 此种方式合并时性能稍差, 但读数据(统计查询)时性能好一些, 过程如下:
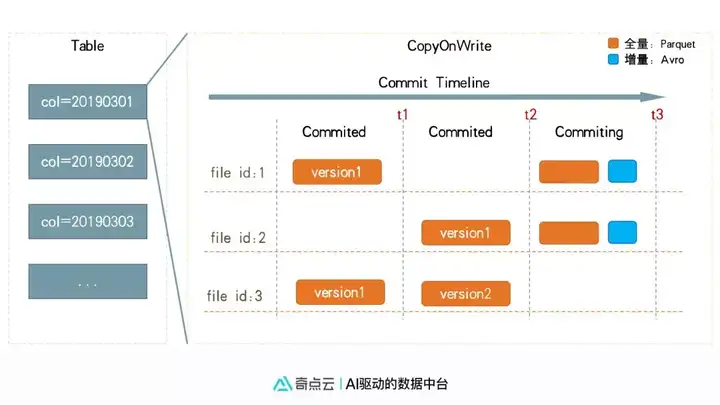
读时合并是指合并时只将增量数据写入日志文件, 读时(查询统计)再合并重复数据。 同时会定期全量合并。 此种方式的合并效率很高, 数据时延可以达到秒级~分钟级, 但查询时性能稍差, 如图所示:
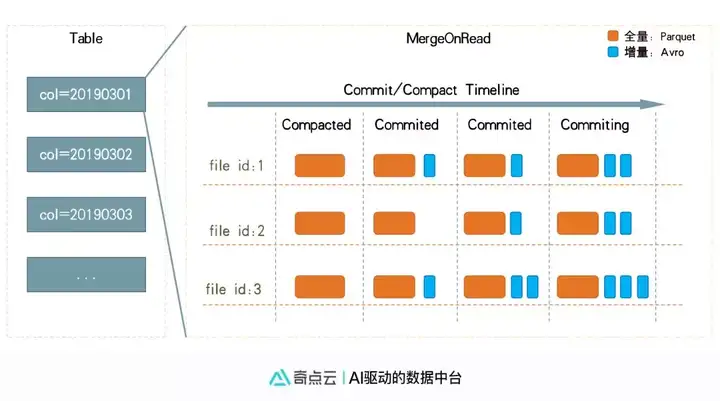
两种方式使用与不同的业务场景: 注重读性能或者注重合并性能。
Datas支持丰富的场景应用
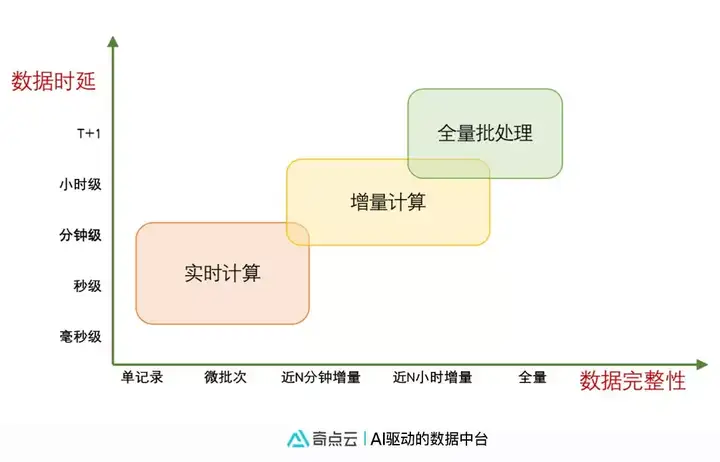
按照数据要求的时延和数据要求的完整性, 计算场景大致可分为三类:
其中:
·实时计算: 很多数据时延要求在 毫秒级 ~ 10分钟的场景, 通常采用flink或者spark等计算引擎。 如:监控告警、实时特征等等。
·增量计算:时延要求在10分钟~小时级别, 数据要求增量处理的场景。 如企业大屏、活动效果分析、当日uv等统计数据展示。
·全量批处理: 主要针对各种T+1的报表统计, Simba目前采用Hive引擎。
目前市场上对于实时计算和全量批处理都有成熟的方案, 但对于夹缝中的增量计算支持的都不太好。增量计算无论是采用流式实时处理, 还是采用全量批处理, 都比较浪费资源, 且效果不理想。 DataS可以支持增量的采集、合并、计算, 以较低的计算成本支持了此类场景。 此外, DataS能很好的支持秒级以上的实时计算和批处理任务。
附-DataSimba数据采集支持的多种数据源
DataSimba的采集平台支持丰富的数据源, 包括:
数据中台技术汇(二)| DataSimba系列之数据采集平台的更多相关文章
- 奇点云数据中台技术汇(一) | DataSimba——企业级一站式大数据智能服务平台
在这个“数据即资产”的时代,大数据技术和体量都有了前所未有的进步,若企业能有效使用数据,让数据赚钱,这必将成为企业数字化转型升级的有力武器. 奇点云自研的一站式大数据智能服务平台——DataSimba ...
- 奇点云数据中台技术汇(三)| DataSimba系列之计算引擎篇
随着移动互联网.云计算.物联网和大数据技术的广泛应用,现代社会已经迈入全新的大数据时代.数据的爆炸式增长以及价值的扩大化,将对企业未来的发展产生深远的影响,数据将成为企业的核心资产.如何处理大数据,挖 ...
- 奇点云数据中台技术汇(四)| DataSimba系列之流式计算
你是否有过这样的念头:如果能立刻马上看到我想要的数据,我就能更好地决策? 市场变化越来越快,企业对于数据及时性的需求,也越来越大,另一方面,当下数据容量呈几何倍暴增,数据的价值在其产生之后,也将随 ...
- 奇点云数据中台技术汇(五)| CDP,线下零售顾客运营中台
顾客数据平台(Customer Data Platform,简称CDP),是近年兴起的一种以顾客为核心.聚焦客群细分与人群洞察的企业数据应用平台. 听上去很互联网啊?跟实体行业和零售营销有什么关系呢? ...
- 好未来数据中台 Node.js BFF实践(一):基础篇
好未来数据中台 Node.js BFF实践系列文章列表: 基础篇 实战篇(TODO) 进阶篇(TODO) 好未来数据中台的Node.js中间层从7月份开始讨论可行性,截止到9月已经支持了4个平台,其中 ...
- CTO与CIO选型数据中台的几大建议
企业数字化转型离不开企业数字化技术的配备.但企业在选择数字化技术时也面临着一个问题,就是如何在大胆采用先进的数字化技术和对技术进行投资之间找到平衡,将投资风险降到最低,毕竟错误的技术选型会给企业带来不 ...
- 20.1翻译系列:EF 6中自动数据迁移技术【EF 6 Code-First系列】
原文链接:https://www.entityframeworktutorial.net/code-first/automated-migration-in-code-first.aspx EF 6 ...
- Influx Sql系列教程九:query数据查询基本篇二
前面一篇介绍了influxdb中基本的查询操作,在结尾处提到了如果我们希望对查询的结果进行分组,排序,分页时,应该怎么操作,接下来我们看一下上面几个场景的支持 在开始本文之前,建议先阅读上篇博文: 1 ...
- Dataphin帮助企业构建数据中台系列之--萃取数据中心
Dataphin作为阿里巴巴数据中台OneData (OneModel.OneID.OneService)方法论的产品载体,帮助企业构建三大数据中心:基于数据集成形成的垂直数据中心.基于数据开发沉淀的 ...
随机推荐
- 如何用Python统计《论语》中每个字的出现次数?10行代码搞定--用计算机学国学
编者按: 上学时听过山师王志民先生一场讲座,说每个人不论干什么,都应该学习国学(原谅我学了计算机专业)!王先生讲得很是吸引我这个工科男,可能比我的后来的那些同学听课还要认真些,当然一方面是兴趣.一方面 ...
- Swift 中调试状态下打印日志
首先我们应该知道Swift中真个程序的入口就是在AppDelegate.swift中.所以在打印日志在 AppDelegate.swift中是这样的 import UIKit @UIApplicati ...
- Unity3d游戏代码保护
现在的游戏项目如果达到一定规模.项目比较创新方竞争对手.项目严重依赖客户端代码那么代码保护还是尽量做,如果不是也没必须瞎折腾. Unity常见代码保护机制: 1.重新编译mono,修改mono_ima ...
- pycharm使用常见设置
字体修改: file——setting——Editor——font(快捷键:ctrl+alt+s) 修改项目编译器:a,b方法二选一 a.ctrl+alt+s,调出设置窗口——选中想要换的版本即可,如 ...
- JavaScript—面向对象 贪吃蛇_2 食物对象
食物对象 //自调用 (function (){ function Food(element) { this.width = 20 this.height = 20 this.backgroundCo ...
- 2. laravel 5.5 学习 过程中 遇到问题 的 链接
关于 laravel 5.5 的文档 网络上已经太多 就不些太多重复的话了 在以后的 工作 中遇到问题的 查询到的解决方案 或者 相关文档将会具体写在这里 laravel 5.5 中文文档 https ...
- 《Docekr入门学习篇》——Docker常用命令
Docker常用命令 Docker镜像管理 搜索镜像:docker search 获取镜像:docker pull 查看镜像:docker images 删除镜像:docker rmi 构建镜像:do ...
- js中要声明变量吗?
你好,js语言是弱类型语言,无需申明即可直接使用,默认是作为全局变量使用的.建议:在function里时应使用var 申明变量,这样改变量仅仅只在function的生存周期内存在,不会污染到,全局控件 ...
- 操作实践,git本地分支执行rebase,让主干分支记录更简洁
声明:迁移自本人CSDN博客https://blog.csdn.net/u013365635 我们平时在写代码的时候,难免会修修改改,如果团队中每个人的代码提交记录都包含着一堆中间过程,是很不利于团队 ...
- Juniper srx新增接口IP,使PC直连srx(转)
转自:https://www.jianshu.com/p/bc27134bde3d Juniper srx新增接口IP,使PC直连srx 2018.11.19 14:24:15字数 424 概述 需求 ...