HBase完全分布式集群搭建
HBase完全分布式集群搭建
hbase和hadoop一样也分为单机版,伪分布式版和完全分布式集群版,此文介绍如何搭建完全分布式集群环境搭建。hbase依赖于hadoop环境,搭建habase之前首先需要搭建好hadoop的完全集群环境。本文中采用独立的zookeeper,不使用hbase自带的zookeeper。
一.环境准备
*HBase软件包hbase-1.2.0-cdh5.12.0.tar.gz
*完成hadoop集群环境搭建
二.安装HBase
1.首先在hdp-node-01安装配置好之后,再复制分发到其他从节点
#解压
| $ tar -xzvf hbase-1.2.0-cdh5.12.0.tar.gz -C /opt/modules/cdh5.12.0 |
2.配置环境变量vim /etc/profile
|
#HBASE_HOME export HBASE_HOME=/opt/modules/cdh5.12.0/hbase-1.2.0-cdh5.12.0 export PATH=$HBASE_HOME/bin:$PATH |
三.配置文件
hbase 相关的配置主要包括hbase-env.sh、hbase-site.xml、regionservers三个文件,都在$HBASE_HOME/conf目录下面,同时拷贝hadoop的配置文件core-site.xml,hdfs-site.xml到该目录下,因为hadoop使用了HA集群模式,hbase访问hdfs时需要知道访问地址。
1.配置hbase-env.sh
|
export JAVA_HOME=/opt/modules/jdk1.7.0_71 #关联hadoop #Hbase日志目录,需创建 #使用单独的zookeeper,禁用hbase自带的zookeeper |
2.配置 hbase-site.xml
|
<configuration> |
3.修改regionservers
|
vim /opt/modules/cdh5.12.0/hbase-1.2.0-cdh5.12.0/conf/regionservers hdp-node-02 hdp-node-03 hdp-node-04 hdp-node-05 |
4.复制分发hbase到其他4个从节点中
| $ scp -r hbase-1.2.0-cdh5.12.0/ root@hdp-node-02:/opt/modules/cdh5.12.0/ |
四.启动HBase
由于是集群在master节点hdp-node-01上启动hbase即可
| $ bin/start-hbase.sh |
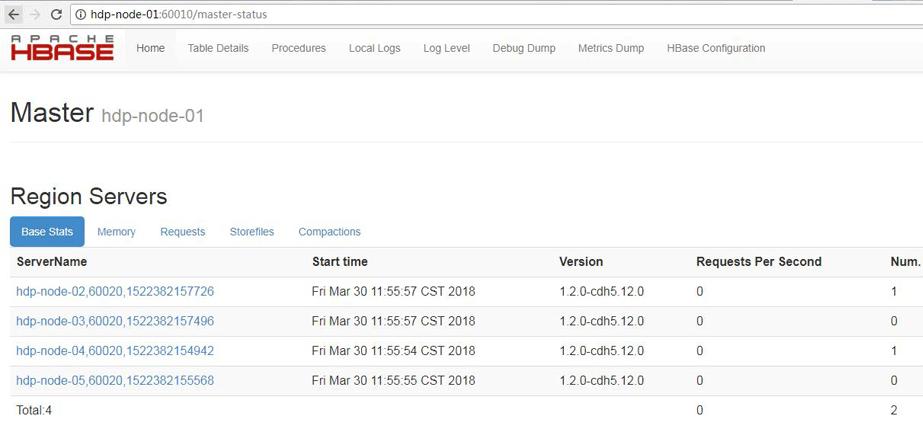
五.访问HBase Web页面
| http://hdp-node-01:60010 |
HBase完全分布式集群搭建的更多相关文章
- hbase完整分布式集群搭建
简介: hadoop的单机,伪分布式,分布式安装 hadoop2.8 集群 1 (伪分布式搭建 hadoop2.8 ha 集群搭建 hbase完整分布式集群搭建 hadoop完整集群遇到问题汇总 Hb ...
- HBase HA分布式集群搭建
HBase HA分布式集群搭建部署———集群架构 搭建之前建议先学习好HBase基本构架原理:https://www.cnblogs.com/lyywj170403/p/9203012.html 集群 ...
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 基于HBase0.98.13搭建HBase HA分布式集群
在hadoop2.6.0分布式集群上搭建hbase ha分布式集群.搭建hadoop2.6.0分布式集群,请参考“基于hadoop2.6.0搭建5个节点的分布式集群”.下面我们开始啦 1.规划 1.主 ...
- hbase分布式集群搭建
hbase和hadoop一样也分为单机版.伪分布式版和完全分布式集群版本,这篇文件介绍如何搭建完全分布式集群环境搭建. hbase依赖于hadoop环境,搭建habase之前首先需要搭建好hadoop ...
- HBase篇--搭建HBase完全分布式集群
一.前述. 完全分布式基于hadoop集群和Zookeeper集群.所以在搭建之前保证hadoop集群和Zookeeper集群可用.可参考本人博客地址 https://www.cnblogs.com/ ...
- 分布式实时日志系统(四) 环境搭建之centos 6.4下hbase 1.0.1 分布式集群搭建
一.hbase简介 HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java.它是Apache软件基金会的Hadoop项目的一部分,运行 ...
- 1、搭建HBase完全分布式集群
搭建完全分布式集群 HBase集群建立在hadoop集群基础之上,所以在搭建HBase集群之前需要把Hadoop集群搭建起来,并且要考虑二者的兼容性.现在就以5台机器为例,搭建一个简单的集群. 软件版 ...
随机推荐
- Python中列表的copy方法
1.在列表中存在一个名为copy的方法,就像字面意思一样copy方法是用于复制列表元素的,示例如下: names = [‘Zhangsan’,’Lisi’,’WangErgou’] names2 = ...
- Fractal Dimension|Relative Complexity|CG含量|重复序列|
生物信息学-序列拼接方法 物理学方法 Fractal Dimension of Exon and Intron Sequences --------------CGCGGCGTGTGTTATA --- ...
- quartz2.2.1bug
quartz2.1.5 调用 scheduler.start()方法时报这样一个异常: 严重: An error occurred while scanning for the next trigge ...
- windows下CreateDirectory创建路径失败的解决办法
第一: 权限不够: SECURITY_ATTRIBUTES sa;SECURITY_DESCRIPTOR sd; InitializeSecurityDescriptor(&sd,SECURI ...
- MySql数据库,查询数据导出时会出现重复的记录(数据越多越明显)
在查询数据时,数据量多的时候,我们会使用分页功能. 每页显示多少数据. 这种情况下,一半看不出什么问题. 而导出数据时,有时就是通过分页的方法,逐步讲数据追加到导出文件中. 当全部数据都导出之后,就有 ...
- 吴裕雄--天生自然 pythonTensorFlow图形数据处理:多线程队列操作
import tensorflow as tf #1. 定义队列及其操作. queue = tf.FIFOQueue(100,"float") enqueue_op = queue ...
- 吴裕雄--天生自然Linux操作系统:Linux常用命令大全
系统信息 arch 显示机器的处理器架构 uname -m 显示机器的处理器架构 uname -r 显示正在使用的内核版本 dmidecode -q 显示硬件系统部件 - (SMBIOS / DMI) ...
- 吴裕雄--天生自然 PYTHON3开发学习:OS 文件/目录方法
import os, sys # 假定 /tmp/foo.txt 文件存在,并有读写权限 ret = os.access("/tmp/foo.txt", os.F_OK) prin ...
- JavaScript 的数据结构与算法
1数组 1.1方法列表 数组的常用方法如下: concat: 链接两个或者更多数据,并返回结果. every: 对数组中的每一项运行给定的函数,如果该函数对每一项都返回true,则返回true. fi ...
- 900B. Position in Fraction#分数位置(模拟)
题目出处:http://codeforces.com/problemset/problem/900/B 题目大意:找到一个数字在小数部分中第一次出现的位置 #include<iostream&g ...