python3下scrapy爬虫(第一卷:安装问题)
一般爬虫都是用urllib包,requests包 配合正则.beautifulsoup等包混合使用,达到爬虫效果,不过有框架谁还用原生啊,现在我们来谈谈SCRAPY框架爬虫,
现在python3的兼容性上来了,SCRAPY不光支持python2版本了,有新的不用旧的,现在说一下让很多人望而止步的安装问题,很多人开始都安装不明白,
当前使用的版本是PYTHON3.5,安装时用PIP3
安装步骤:
1 安装wheel
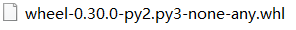
pip3 install wheel
2 安装twisted
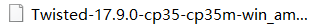
pip3 install Twisted-17.9.0-cp35-cp35m-win_amd64.whl
3 安装lxml
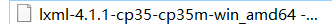
pip3 install lxml-4.1.1-cp35-cp35m-win_amd64.whl
4 安装scrapy
pip3 install scrapy
这样你就成功的安装上了scrapy,你可以创建文件,但是你任然不可爬虫,一旦执行爬虫文件就会报错
5 安装pywin32

一路下一步就行
接着我们创建scrapy文件夹
进入运行环境为python3.5的文件路径,如果你的电脑同时安装2,3版本一定要注意问题。两个版本会出现环境冲突问题,一旦python3版本下的scrapy运行在python2下就会出现版本不兼容问题,就会出现NO MOUDLE的报错
路径切换到python3运行的环境:
scrapy startproject filename
终端进入filename目录
scrapy genspider -t basic crawl1 webname.com
就会创建爬虫脚本文件
文件夹里几个文件我也就不介绍了,
我说下基本爬虫setting.py的应用
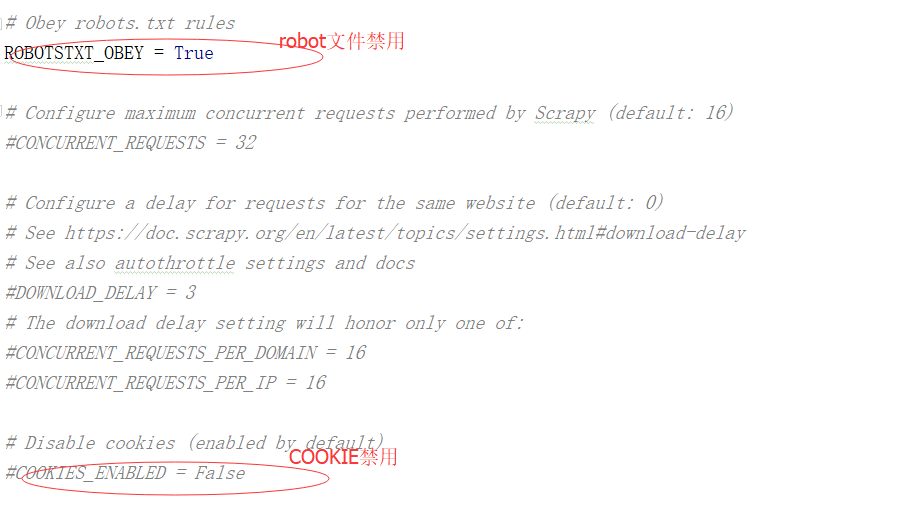
现在可以进行正常的爬取网页了
python3下scrapy爬虫(第一卷:安装问题)的更多相关文章
- python3下scrapy爬虫(第五卷:初步抓取网页内容之scrapy全面应用)
现在爬取http://category.dangdang.com/pg1-cid4008149.html网址上的商品价格,名称,评价数量 先准备下下数据:商品名,商品链接,评价数量 第一步:在item ...
- python3下scrapy爬虫(第二卷:初步抓取网页内容之直接抓取网页)
上一卷中介绍了安装过程,现在我们开始使用这个神奇的框架 跟很多博主一样我也先选择一个非常好爬取的网站作为最初案例,那么我先用屌丝必备网站http://www.shaimn.com/xinggan/作为 ...
- python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中 现在我们需要在SETTING.PY设置我们的爬虫文件 再添加PIPELINE 注释掉的原因是爬虫执行完后,和本地存 ...
- python3下scrapy爬虫(第十二卷:解决scrapy数据存储大量数据时阻塞问题)
之前我们使用scrapy爬取数据,用的存储方式是直接引入PYMYSQL,或者MYSQLDB,案例中数据量并不大,这种数据存储方式属于同步过程,也就是上一条语句执行完才能执行下一条语句,当数据量变大时, ...
- python3下scrapy爬虫(第十一卷:scrapy数据存储进mongodb)
说起python爬虫数据存储就不得不说到mongodb,现在我们来试一下scrapy操作mongodb 首先开启mongodb mongod --dbpath=D:\mongodb\db 开启服务后就 ...
- python3下scrapy爬虫(第七卷:编辑器内执行scrapy)
之前我们都是在终端切入到scrapy的路境内执行爬虫的,你要多敲多少行的字节,所以这次我们谈谈如何在编辑器里执行,这个你可以用在爬虫中,当你使用PYTHONWEB开发时尽量不要在编辑器内启动端口服务那 ...
- python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接 现在我再新建个爬虫文件,名称设置为crawler2 做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrap ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- python3下scrapy爬虫(第六卷:利用cookie模拟登陆抓取个人中心页面)
之前我们爬取的都是那些无需登录就要可以使用的网站但是当我们想爬取自己或他人的个人中心时就需要做登录,一般进入登录页面有两种 ,一个是独立页面登陆,另一个是弹窗,我们先不管验证码登陆的问题 ,现在试一下 ...
随机推荐
- Serverless 公司的远程团队沟通策略
本文系译文,Serverless 团队分散在全球各地,本文介绍我们如何管理沟通策略和远程协作. 原作者:FelixDesroches 译者:Aceyclee 首先向不了解我们的人说明一下,Server ...
- 字符串中子序列出现次数(dp)
躲藏 链接:https://ac.nowcoder.com/acm/problem/15669来源:牛客网 题目描述 XHRlyb和她的小伙伴Cwbc在玩捉迷藏游戏. Cwbc藏在多个不区分大小写的字 ...
- POJ 2796 Feel Good 【单调栈】
传送门:http://poj.org/problem?id=2796 题意:给你一串数字,需要你求出(某个子区间乘以这段区间中的最小值)所得到的最大值 例子: 6 3 1 6 4 5 2 当L=3,R ...
- orbslam算法框架
ORB-SLAM[1]完全继承了PTAM(http://www.cnblogs.com/zonghaochen/p/8442699.html)的衣钵,并做出了两点巨大改进:1)实时回环检测:2)很鲁棒 ...
- Ubuntu目錄
/ (这就是著名的根)├── bin (你在终端运行的大多数程序,比如cp.mv...)├── boot (内核放在这里,这个目录也经常被作为某个独立分 ...
- [原]调试实战——使用windbg调试崩溃在ComFriendlyWaitMtaThreadProc
原调试debugwindbgcrash崩溃COM 前言 这是几年前在项目中遇到的一个崩溃问题,崩溃在了ComFriendlyWaitMtaThreadProc()里,没有源码.耗费了我很大精力,最终通 ...
- AI大火之下智能手机行业能适应这一风口吗?
今年智能手机行业的变化,实在是让人摸不到头脑.一方面是智能手机厂商依然在拿出各种具有噱头的产品,仿佛整个市场还依然热火朝天.但在另一方面,智能手机出货量却出现大幅下滑.据中国信息通信研究院发布的数据显 ...
- Opencv笔记(五)——把鼠标当画笔
学习目标: 学习使用 OpenCV 处理鼠标事件 学会使用函数cv2.setMouseCallback() 简单演示: 首先我们来创建一个鼠标事件回调函数,但鼠标事件发生是他就会被执 ...
- Java复习(四)类的重用
4.1类的继承 Java只支持类的单继承,每一个子类只能有一个直接父类. #继承的语法 class childClass extends parentClass { //类体 } 子类不能直接访问从父 ...
- 数据结构与算法——认识O(NlogN)的排序(1)
归并排序 1) 整体就是一个简单递归,左边排好序.右边排好序.让其整体有序 2) 让其整体有序的过程里用了外排序方法 3) 利用master公式来求解时间复杂度 4) 归并排序的实质 时间复杂度0(N ...