IK分词器 整合solr4.7 含同义词、切分词、停止词
转载请注明出处!
IK分词器如果配置成
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
本人测试切分词可以,但是同义词,扩展词库用不了,
网上查各种资料说IK分词器有个BUG,要自己把jar文件改一下,于是找到IK的源码,里面只有IKAnalyzer的源码,代码如下
package org.wltea.analyzer.lucene; import java.io.Reader; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.Tokenizer; /**
* IK分词器,Lucene Analyzer接口实现
* 兼容Lucene 4.0版本
*/
public final class IKAnalyzer extends Analyzer{ private boolean useSmart; public boolean useSmart() {
return useSmart;
} public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
} /**
* IK分词器Lucene Analyzer接口实现类
*
* 默认细粒度切分算法
*/
public IKAnalyzer(){
this(false);
} /**
* IK分词器Lucene Analyzer接口实现类
*
* @param useSmart 当为true时,分词器进行智能切分
*/
public IKAnalyzer(boolean useSmart){
super();
this.useSmart = useSmart;
} /**
* 重载Analyzer接口,构造分词组件
*/
@Override
protected TokenStreamComponents createComponents(String fieldName, final Reader in) {
Tokenizer _IKTokenizer = new IKTokenizer(in , this.useSmart());
return new TokenStreamComponents(_IKTokenizer);
} }
自己加了一个IKAnalyzerSolrFactory,代码如下
package org.wltea.analyzer.lucene; import java.io.Reader;
import java.util.Map; import org.apache.lucene.analysis.Tokenizer;
import org.apache.lucene.analysis.util.TokenizerFactory;
import org.apache.lucene.util.AttributeSource.AttributeFactory; public class IKAnalyzerSolrFactory extends TokenizerFactory{ private boolean useSmart; public boolean useSmart() {
return useSmart;
} public void setUseSmart(boolean useSmart) {
this.useSmart = useSmart;
} public IKAnalyzerSolrFactory(Map<String,String> args) {
super(args);
assureMatchVersion();
this.setUseSmart(args.get("useSmart").toString().equals("true"));
} @Override
public Tokenizer create(AttributeFactory factory, Reader input) {
Tokenizer _IKTokenizer = new IKTokenizer(input , this.useSmart);
return _IKTokenizer;
} }
这样一来就能在配置文件中配置成IKAnalyzerSolrFactory 的列子
下面是具体的配置描述:
1。修改IK的jar文件,加入IKAnalyzerSolrFactory (如果不会改的自行下载 http://pan.baidu.com/s/1gfLOIL9)
2.修改solrconfig.xml文件,加入
<lib dir="/contrib/analysis-extras/lib" regex=".*\.jar" />
3.修改schema.xml文件,加入
<!--IK分词器-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" useSmart="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKAnalyzerSolrFactory" useSmart="true"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
</analyzer>
</fieldType>
4.在solr的webINFO 下的classes(没有新建)加入如下图,IK压缩文件中的部分文件,如图所示:
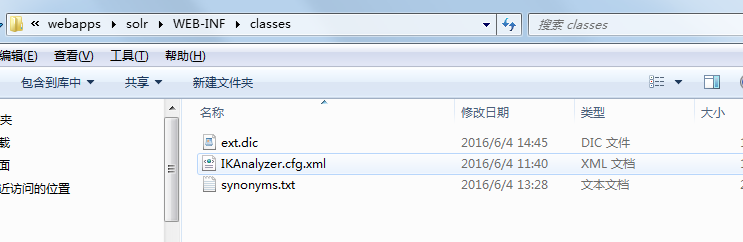
5.在ext.dic配置自定义词库,不需要切分词的词语配置在此,同义词写在synonyms.txt中即可。格式为: 通知,通告
注意每次改变词库或者同义词需要重启服务。
IK分词器 整合solr4.7 含同义词、切分词、停止词的更多相关文章
- Ik分词器没有使用---------elasticsearch-analysis-ik 5.6.3分词问题
此文章在作者认真阅读源码后发现,这并不是问题所在. 此篇文章是对IK配置的错误理解.新版本的IK配置的扩展字典本来就该使用者自己去手动配置! 1.问题 现在项目中用的是ES5.6.3的版本,在解决Fi ...
- nlp任务中的传统分词器和Bert系列伴生的新分词器tokenizers介绍
layout: blog title: Bert系列伴生的新分词器 date: 2020-04-29 09:31:52 tags: 5 categories: nlp mathjax: true ty ...
- 【杂记】docker搭建ELK 集群6.4.0版本 + elasticsearch-head IK分词器与拼音分词器整合
大佬博客地址:https://blog.csdn.net/supermao1013/article/category/8269552 docker elasticsearch 集群启动命令 docke ...
- solr4.x配置IK2012FF智能分词+同义词配置
本文配置环境:solr4.6+ IK2012ff +tomcat7 在Solr4.0发布以后,官方取消了BaseTokenizerFactory接口,而直接使用Lucene Analyzer标准接口T ...
- solr添加中文IK分词器,以及配置自定义词库
Solr是一个基于Lucene的Java搜索引擎服务器.Solr 提供了层面搜索.命中醒目显示并且支持多种输出格式(包括 XML/XSLT 和 JSON 格式).它易于安装和配置,而且附带了一个基于H ...
- 三、Solr多核心及分词器(IK)配置
多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索,不使用多核也没问题,这样带来的问题是 ...
- Solr多核心及分词器(IK)配置
Solr多核心及分词器(IK)配置 多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索 ...
- elasticsearch 之IK分词器安装
IK分词器地址:https://github.com/medcl/elasticsearch-analysis-ik 安装好ES之后就可以安装分词器插件了 记住选择ES对应的版本 对应的有版本选择下载 ...
- solr4.5配置中文分词器mmseg4j
solr4.x虽然提供了分词器,但不太适合对中文的分词,给大家推荐一个中文分词器mmseg4j mmseg4j的下载地址:https://code.google.com/p/mmseg4j/ 通过以下 ...
随机推荐
- echo命令详解
echo: echo [-neE] [arg ...] echo会将输入的字符串送往标准输出.输出的字符串间以空白字符隔开, 并在最后加上换行号. Options: -n 不在最后自动换行 -e 使用 ...
- 使用github之前的技能准备
Git的导入 介绍 Git属于分散型版本管理系统,是为版本管理而设计的软件.版本管理就是管理更新的历史记录.它为我们提供了一些在软件开发过程中必不可少的功能,例如记录一款软件添加或更改源代码的过程,回 ...
- 【2016-11-3】【坚持学习】【Day18】【ADO.NET 】
使用Connection创建数据库连接 使用Command创建命令 使用ExecuteScalar,ExecuteNonQuery,ExecuteReader方法来执行命令 使用DataReader来 ...
- 《The Elder Scrolls V: Skyrim》百般冷门却强力职业
<The Elder Scrolls V: Skyrim>百般冷门却强力职业 1.有如成龙平常的杂耍型战斗窃贼 每次看帖都察觉大伙一贯在强调窃贼不需要防御,窃贼不需要血,窃贼就是一击致命, ...
- 基于ionic+cordova+angularJs从零开始搭建自己的移动端H5 APP
这里详细介绍下如何用ionic+cordova+angularjs搭建自己的移动端app,包括环境搭建,框架使用等,具体项目已放置在github上,可下载下来自行启动. 下载地址:https://gi ...
- BZOJ 2243: [SDOI2011]染色 [树链剖分]
2243: [SDOI2011]染色 Time Limit: 20 Sec Memory Limit: 512 MBSubmit: 6651 Solved: 2432[Submit][Status ...
- NOIP2001 一元三次方程求解[导数+牛顿迭代法]
题目描述 有形如:ax3+bx2+cx+d=0 这样的一个一元三次方程.给出该方程中各项的系数(a,b,c,d 均为实数),并约定该方程存在三个不同实根(根的范围在-100至100之间),且根与根之差 ...
- 玩KVM
按照网上的一篇博客玩KVM,结果wifi上不了网,上不了网! 把br0下线就好了! 呀------ 11月16日,今天发现kvm卡成屎可能是和kvm内存使用率为0相关,虚拟机中的内存显示内存确实是我配 ...
- jQuery旋转木马仿3D效果的图片切换特效代码
用jQuery实现的一款仿3D效果的图片切换特效代码,类似旋转木马一样,幻灯图片以三维视觉上下滑动切换,效果很酷炫,兼容IE8.360.FireFox.Chrome.Safari.Opera.傲游.搜 ...
- 如何重新划分linux分区大小
1.下载脚本文件,将脚本文件内容复制 chmod +x resize.sh sudo ./resize.sh 输入上面命令后会看到下面的结果 root@odroid:~# sudo ./resize. ...