<Spark><Spark Streaming>
Overview
- Spark Streaming为用户提供了一套与batch jobs十分相似的API,以编写streaming应用
- 与Spark的基本概念RDDs类似,Spark Streaming提供了被称为DStreams/discretized streams的抽象。
- DStream is a sequence of data arriving over time. 其本质是,每个DStream被表示成来自每个时间阶段的RDDs的序列,因此被称为离散的。
- DStreams可以从各种输入数据源创建,比如Flume, Kafka, or HDFS
- transformations: which yield a new DStreams
- ouput operations: which write data to an external system
- 与批处理不同的是,Spark Streaming还需要额外的setup来operate 24/7。稍后我们会讨论checkpointing: the main mechanism Spark Streaming provides for this purpose, which lets it store data in a reliable file system such as HDFS.稍后我们会讨论如何在失败时重启,或者如何自动重启。
一旦创建,DStream提供两种类型的操作:[DStreams提供很多与RDD上类型的操作,同时还有新的关于时间的操作,比如sliding-windows]
A Simple Example
- 首先要创建一个StreamingContext。这也在下层创建了一个SparkContext用来处理数据。这其中我们会指定一个batch interval作为输入来确定处理新数据的频率。
- 然后使用socketTextStreams()来创建一个基于文本数据的DStream
// Create a Streming filter for printing lines containing "error" in Scala
val ssc = new StreamingContext(conf, Seconds(1))
// Create a DStream using data received after connecting to port 777 on the local machine
val lines = scc.socketTextStream("localhost", 7777)
// Filter our DStreams for lines with "error"
val errorLines = lines.filter(_.contains("error"))
//Print out the lines with errors
errorLines.print()
- 以上程序只有在系统接收到数据的时候才会开始计算。为此,我们必须显式地调用ssc.start()。然后SparkStreaming会基于底层的SparkContext开始调度这个Spark jobs。这些是在一个单独的线程发生的。为了防止程序退出,我们还需要调用awaitTermination来等待Streaming计算完成。
// Start our streaming context and wait for it to "finish"
ssc.start()
// Wait for the job to finish
ssc.awaitTermination()
- 注意一个streaming context只能被start一次,并且必须在所有DStreams设置好了之后启动
Architecture and Abstraction
- Spark Streaming使用“micro-batch”架构,streaming计算被当做一些列连续的batch computations on small batches of data.
- Spark Streaming从多种数据源接收数据并把他们分成small batches。新的batches在固定时间间隔内被创建。
- 每个输入batch组成一个RDD,并通过Spark jobs来处理,被处理好的结果可以被pushed out到外部系统。
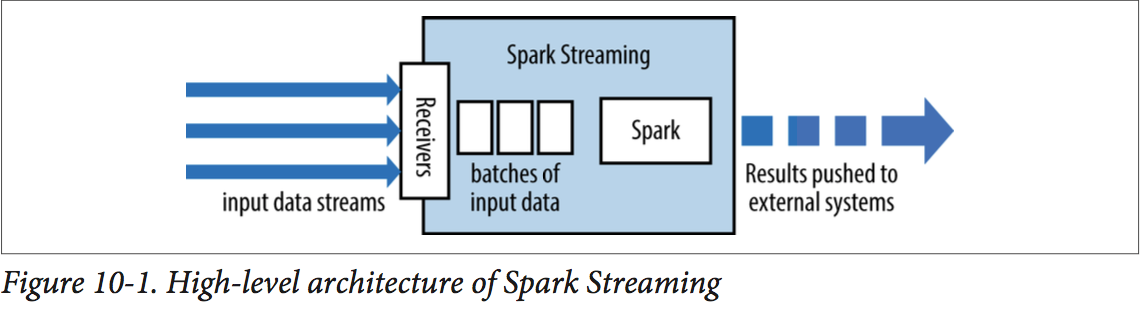
- 容错:和RDDs类似,只要输入数据的一个copy有效,那么它可以通过RDDs的lineage重计算。缺省情况下,received data在两个nodes上都有副本,所以SparkStreaming可以容忍single worker failures。但是如果仅仅使用lineage,那么recomputation可能会耗费很多时间。因此,SparkStreaming提供了checkpointing机制来周期地存储状态到reliable文件系统(HDFS or S3)。典型地,你可以每5-10个batches的数据创建一个checkpointing。
Transformations
- DStreams上的Transformations可以分为stateless和stateful两类:
- 对stateless transformations,对每个batch的处理不依赖于之间的batches数据。这些包括了普通的RDD transformations:map(), filter(), reduceByKey()
- Stateful transformations, 相比之下会使用之前batches的数据或中间结果来得到当前batch的结果。这包括了一些基于sliding window和时间状态追踪的transformations。
Stateless Transformations
- 无状态的Transformations只是简单地被应用到每个batch--也就是DStream中的每个RDD。
- eg:在如下的log processing程序中,我们使用map()和reduceByKey()来对每个时间阶段统计log events
// Assumes ApacheAccessLog is utility class for parsing entries from Apache logs
val accessLogDStream = logData.map(line => ApacheAccessLog.parseFromLogLine(line))
val ipDStream = accessLogsDStream.map(entry => (entry.getIpAddress(), 1))
val ipCountsDStream = ipDStream.reduceByKey((x, y) => x +y)
Stateful Transformations
- 有状态的transformations主要有两种:
- windowed operations:which act over a sliding window of time periods
- updateStateByKey(): which is used to track state across events for each key(eg: to build up an object representing each user session.)
- 有状态的transformation需要开启checkpointing来容错。
Windowed transformation
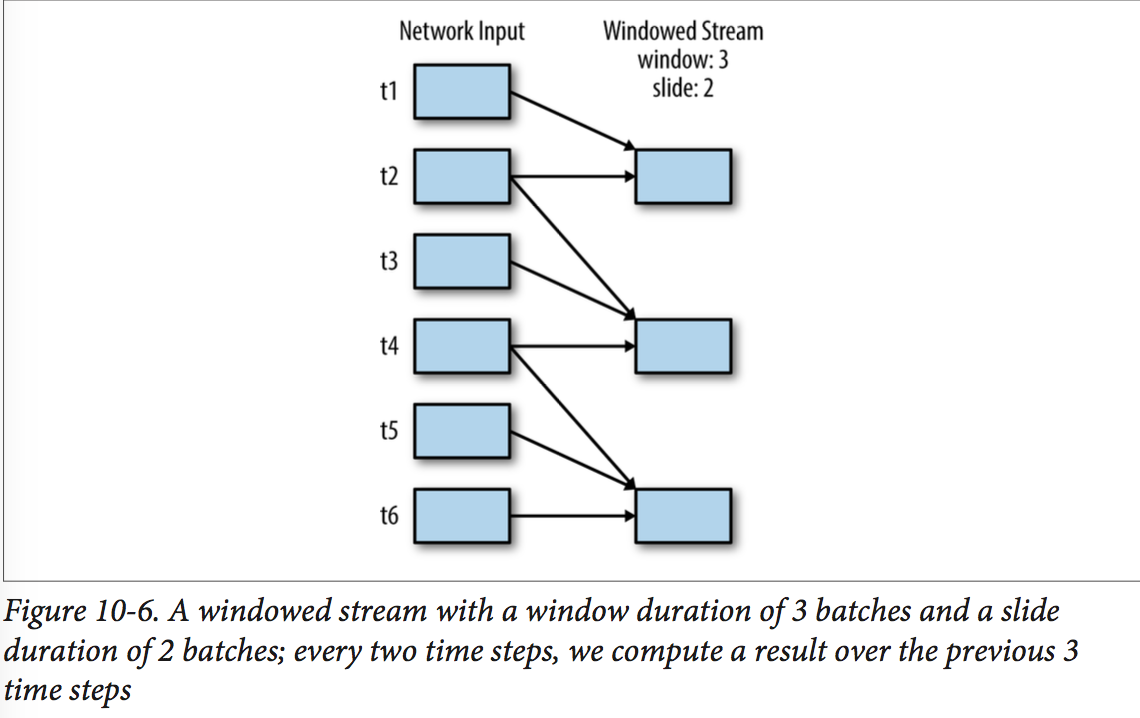
- 基于窗口的操作所处理的时间段长于StreamingContext的batch interval --> 通过合并多个batches的结果。
- 所有基于窗口的操作需要两个参数:【这两个值都要是batch interval的倍数
- window duration:控制考虑多少个previous batches of data
- sliding duration: 控制一个新的DStream计算结果的频率
UpdateStateByKey transformation
- 有时候需要在一个DStream的batches之间维护一个状态。
- updateStateByKey()提供一个访问DStreams状态变量的键值对。
- eg:对于日志文件,我们可以追踪每个userID(key)的最后访问的10个页面。也就是说这最后10个页面组成的list使我们的"state"对象,我们在每次事件到达的时候update。
- 使用方式:调用update(events, oldState),返回newState。【
- events: a list of events that arrived in the current batch(may be empty)
- oldState: an optional state object, stored within an Option; it might be missing if there was no previous state for the key.
- newState: 函数返回值,也是一个Option。我们可以返回一个空Option,来表示我们要删除该状态。
- eg:key是HTTP response code, state是integer表示count,events是page views。这里我们保留的是从程序开始的所有count。
def updateRunningSum(values: Seq[Long], state: Option[Long]) = {
Some(State.getOrElse(0L) + values.size)
}
val responseCodeDSrteam = accessLogsDStream.map(log => (log.getResponseCode(), 1L))
val responseCodeCountDStream = responseCodeDStream.updateStateByKey(updateRunningSum _)
Output Operations
ipAddressRequeseCount.foreach { rdd =>
rdd.foreachPartition { partition =>
// Open connection to storage system(e.g. a database connection)
partition.foreach{ item =>
// Use connection to push item to system
}
// Close connection
}
}
Input Sources
Core Sources
- 可以从core sources创建DStream的方法are all available on the StreamingContext.
Stream of files
- 因为Spark支持从任意Hadoop-compatible文件系统中读取,所以Spark Streaming天然地允许从这些FS中创建stream。这种情况很常见,因为它支持variety of backends,尤其是我们会赋值到HDFS的log data。
- TBD...
Akka actor stream
- TBD...
Additional Sources
- 包括Twitter,Apache Kafka,Amazon Kinesis, Apache Flume以及ZeroMQ
Apache Kakfa
- TBD...
Apache Flume
- Spark对Flume有两种不同的receiver:
- Push-based receiver:the receiver acts as Avro sink that Flume pushes data to.
- Pull-based receiver: the receiver can pull data from an intermediate custom sink, to which other processes are pushing data with Flume.

Push-based receiver
- 这种push-based方法可以快速安装,但是没有使用事务来接收数据。
- 缺点很明显:就是没有使用事务,那么很有可能在worker node失效的时候丢失数据。并且如果配置了receiver的worker彻底fail掉的话,系统需要试图在另一个位置launch a receiver,这种配置是十分困难的。
Pull-based receiver
- 这种方法is preferred for resiliency(弹性),并且数据保存在sink直到SparkStreaming读取并复制掉。整个过程会用事务来维护。
- TBD...
Multiple Sources and Cluster Sizing
- 我们可以使用union()方法来combine多个DStreams的数据
- TBD...
24/7 Operation
- Spark Streaming的一个主要优点就是它提供了很强的容错保证。
- 只要输入数据stored reliably,Spark Streaming总可以计算得到正确的结果 --> 即使有worker or dirver fail掉,也会像没有nodes fail一样得到结果。
- 为了使Spark Streaming 24/7, 你需要进行一些特殊的setup。
- 第一步就是setting up checkpointing to a reliable storage system, such as HDFS or Amazon S3.
- 除此之外,你还要考虑driver program的容错问题,以及输入源的unreliable。
Checkpointing
- checkpointing是Spark Streaming最主要的容错机制。
- 它允许Spark Streaming周期地将数据存储到可信赖的存储系统。
- 具体地,checkpointing有两个目的:
- 减少在失败时的recompute。像之前介绍的,Streaming会使用transformation的lineage图来recompute,但是checkpointing可以控制它必须要go back多远
- 为driver提供容错。如果driver program crashes,你可以再启动它,并且告诉它去从一个checkpoint恢复。这样Spark Streaming就会读取该program已经处理了多少了,并且从这里继续。
ssc.chepoint("hdfs://...")
- 注: 在local模式你可以使用本地文件系统,但是对于生产环境,你需要使用a replicated system, 比如HDFS,S3,NFS filer。
Driver Fault Tolerance
- Driver节点的容错需要用特殊的方式创建StreamingContext,其中包含checkpoint目录;
- 用StreamingContext.getOrCreate()方法代替new StreamingContext方式。如下:
def createStreamingContext() = {
...
val sc = new SparkContext(conf)
// Create a StreamingContext with a 1 second batch size
val scc = new StreamingContext(sc, Seconds(1))
scc.checkpoint(checkpointDir)
}
...
val scc = StreamingContext.getOrCreate(checkpointDir, createStreamingContext _)
- 以上,除了使用getOrCreate()方法,我们还需要在crashes后实际地去restart driver程序。很多cluster manager都不会自动地relaunch the driver,所以你需要监控并重启它。
Worker Fault Tolerance
- 对于worker node失效,Spark Streaming使用和Spark一样的技术。
- 也就是说,所有从外部数据源获取的数据会在Spark workers之间复制。因而这些数据通过transformation所创建的RDDs都可以通过RDD lineage recompute。
Receiver Fault Tolerance
- receiver的容错性取决于source的特性(source是否可以resend数据),以及receiver的实现(receiver是否向source更新是否收到数据)。
- 通常来说,receivers提供以下保证:
- 所有从reliable文件系统读入的数据是可靠的,因为底层的FS是被复制的。Spark会通过checkpoints记住那些数据已经处理过,并且在crashes之后从断点处读取;
- 对于unreliable的数据源,比如Kafka,push-based Flume或是Twitter,Spark会将数据复制到其他节点,但是这还是可能在receiver task down掉时丢失数据。
- Summary:因此,为了保证所有数据都被处理的最好方式就是使用reliable输入数据源。
Processing Guarantees
- 由于Spark Streaming的容错保证,它可以通过exactly-once semantics for all transformations, 即使worker fails and一些数据被reprocessed,最终的结果都是只被处理一次的。
- 然而,当使用output操作将transformed result被push到外部系统时,pushing结果的task可能会因为failures而被执行多次,一些数据会被push多次。因为这包括了外部系统,所以这种情况需要system-specific的代码来处理。
- 可以使用transaction来push,也就是说一次只会自动push一个RDD分区;
- 或设计idempotent(幂等的)操作,也就是说多次的运行更新仍然产生相同的result。
Streaming UI
The Streaming UI exposes statistics for our batch processing and our receivers. http://<driver>:4040
Performance Consideration
- Spark Streaming有很多专用的tuning options。
Batch and Window Sizes
- 一个最常见的问题是,SparkStreaming可用的最小batch size是多少。
- 通常,500ms被证明对很多应用是一个好的最小size。
- 最好的方法是,首先用一个大的batch size然后慢慢地降。再去Streaming UI看processing time,如果处理时间保持一致,那么就可以继续将,如果处理时间上升,就说明已经达到应用所能处理的极限了。
Level of Parallelism
- 最common的降低处理时间的方式就是提高并行度。提高并行度有以下三种方式:
- Increasing the number of receivers: receivers会在有很多记录时成为瓶颈,你可以通过增加更多的receiver,然后通过union()来merger到单一的stream中;
- Explicitly repartitioning received data:如果receivers不能再增多了,你可以通过显式地充分区来进一步redistribute输入数据流;
- Increasing parallelism in aggregation:对于像reduceByKey()这样的操作,你可以指定并行度为第二个参数。
Garbage Collection and Memory Usage
- 可以enabling Java‘s Concurrent Mark-Sweep garbage collector:这种方式会消耗更多的资源,但引入了fewer pauses
- 以序列化的形式Caching RDD也会减少GC的压力,这也是Spark Streaming所生成的RDDs都以序列化形式存储的原因。
- 缺省情况下,Spark使用LRU cache来驱逐cache。同样也可以通过spark.cleaner.ttl来驱逐某个时间周期前的数据。
<Spark><Spark Streaming>的更多相关文章
- 简单物联网:外网访问内网路由器下树莓派Flask服务器
最近做一个小东西,大概过程就是想在教室,宿舍控制实验室的一些设备. 已经在树莓上搭了一个轻量的flask服务器,在实验室的路由器下,任何设备都是可以访问的:但是有一些限制条件,比如我想在宿舍控制我种花 ...
- 利用ssh反向代理以及autossh实现从外网连接内网服务器
前言 最近遇到这样一个问题,我在实验室架设了一台服务器,给师弟或者小伙伴练习Linux用,然后平时在实验室这边直接连接是没有问题的,都是内网嘛.但是回到宿舍问题出来了,使用校园网的童鞋还是能连接上,使 ...
- 外网访问内网Docker容器
外网访问内网Docker容器 本地安装了Docker容器,只能在局域网内访问,怎样从外网也能访问本地Docker容器? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Docker容器 ...
- 外网访问内网SpringBoot
外网访问内网SpringBoot 本地安装了SpringBoot,只能在局域网内访问,怎样从外网也能访问本地SpringBoot? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装Java 1 ...
- 外网访问内网Elasticsearch WEB
外网访问内网Elasticsearch WEB 本地安装了Elasticsearch,只能在局域网内访问其WEB,怎样从外网也能访问本地Elasticsearch? 本文将介绍具体的实现步骤. 1. ...
- 怎样从外网访问内网Rails
外网访问内网Rails 本地安装了Rails,只能在局域网内访问,怎样从外网也能访问本地Rails? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Rails 默认安装的Rails端口 ...
- 怎样从外网访问内网Memcached数据库
外网访问内网Memcached数据库 本地安装了Memcached数据库,只能在局域网内访问,怎样从外网也能访问本地Memcached数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装 ...
- 怎样从外网访问内网CouchDB数据库
外网访问内网CouchDB数据库 本地安装了CouchDB数据库,只能在局域网内访问,怎样从外网也能访问本地CouchDB数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动Cou ...
- 怎样从外网访问内网DB2数据库
外网访问内网DB2数据库 本地安装了DB2数据库,只能在局域网内访问,怎样从外网也能访问本地DB2数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动DB2数据库 默认安装的DB2 ...
- 怎样从外网访问内网OpenLDAP数据库
外网访问内网OpenLDAP数据库 本地安装了OpenLDAP数据库,只能在局域网内访问,怎样从外网也能访问本地OpenLDAP数据库? 本文将介绍具体的实现步骤. 1. 准备工作 1.1 安装并启动 ...
随机推荐
- Linux简单了解
Linux内核最初只是由芬兰人李纳斯·托瓦兹(Linus Torvalds)在赫尔辛基大学上学时出于个人爱好而编写的. Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和U ...
- SQL 2016安装
微软数据库SQL Server 2016正式版在2016年6月就发布,由于近期工作忙,一直拖到现在才有时间把安装过程写到博客上,分享给大家.本人一直习惯使用英文版,所以版本和截图都是英文版的.废话少说 ...
- Java中遍历实体类(处理MongoDB)
在实际过程中,经常要将实体类进行封装,尤其是处理数据库的过程中:因此,对于遍历实体类能够与数据库中的一行数据对应起来. 我是使用的环境是Spring boot,访问的数据库时MongoDB 实体类遍历 ...
- 『TensorFlow』高级高维切片gather_nd
gather用于高级切片,有关官方文档的介绍,关于维度的说明很是费解,示例也不太直观,这里给出我的解读,示例见下面, indices = [[0, 0], [1, 1]] params ...
- leetcode_输入一个数组,目标树,检查目标是数组下标的哪两个之和,不准重复
今天是leetcode第一天,但是不太顺利.做这些,想不到 原题目: 我给的答案: class Solution { public: vector<int> twoSum(vector&l ...
- java把13位时间戳转换成"yyyy-MM-dd HH:mm:ss"格式,工具类
public static void main(String[] args) { String time = System.currentTimeMillis();//获取当前时间精确到毫秒级的时间戳 ...
- [CodeForces - 447E] E - DZY Loves Fibonacci Numbers
E DZY Loves Fibonacci Numbers In mathematical terms, the sequence Fn of Fibonacci numbers is define ...
- POJ2393奶酪工厂
Yogurt factory Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 14771 Accepted: 7437 D ...
- spring自定义xml标签&自定义注解
public class YafBeanDefinitionParser implements BeanDefinitionParser { private BeanDefinitionRegistr ...
- 谈一谈JUnit神奇的报错 java.lang.Exception:No tests found matching
最近在学习Spring+SpringMVC+MyBatis,一个人的挖掘过程确实有点艰难,尤其是有一些神奇的报错让你会很蛋疼.特别是接触一些框架还是最新版本的时候,会因为版本问题出现很多错误,欢迎大家 ...