Netty Tutorial Part 1.5: On Channel Handlers and Channel Options [z]
Intro:
After some feedback on Part 1, and being prompted by some stackoverflow questions, I want to expand on and clarify some topics, so this is Part 1.5.
- Channel Handler Sharability & State
- Channel Options
Channel Handlers
As discussed previously, most types of ChannelHandlers have the job of either encoding objects into byte arrays (or specifically, ChannelBuffers) or decoding ChannelBuffers into objects. In most cases, handlers will be instantiated and placed into a ChannelPipeline by a definedChannelPipelineFactory in code that looks something like this (borrowed from the ClientBootstrapjavadoc):
The seeming complexity of the pipeline factory may not be obvious, but it's actually an elegant structure that flexibly handles some variability in the capabilities of different ChannelHandler implementations. First of all, many ChannelHandlers require some configuration, a detail not represented in the above example. Consider the DelimiterBasedFrameDecoder which decodes chunks of bytes in accordance with the constructor specified delimiter. Instances of this decoder require configuration, so the interface only ChannelPipelineFactory allows us to provide the template that defines how it should be createdevery time a new pipeline is created. An as a recap, every time a new channel is created, a pipeline is created for it, although in some cases, I suppose, you might end up with an empty pipeline with no channel handlers, which means you are using a snazzy framework for passing around ChannelBuffers. That, combined with the ordering and logical names of handlers in the pipeline, is why one needs some care and attention when creating a pipeline. Here's a better example of the use of someparameterized channel handlers in use (again, pilfered liberally from the StringEncoder javadoc):
Shared and Exclusive Channel Handlers
However, a crucial factor in the use of channel handlers is this: Some channel handlers are such good multitaskers, that you only ever need one instance and that single instance can be reused in every single pipeline created. That is to say, these types of channel handlers maintain no state so they are exhibit channel safety, a variation on the notion of thread safety. With no state to maintain, there's no reason to create more than one. On the other hand, other channel handlers keep state in instance variables and therefore assume that they are exclusive to one channel and one pipeline. Both the above examples create pipelines with exclusive channel handler instances, inasmuch as they create a new handler instance each time a new pipeline is created. The second example, creating a pipeline factory called MyStringServerFactory (which uses actual real-life channel handlers) contains an example of two channel handlers which could actually be shared, although they have been created inexclusive mode. They are the StringEncoder and StringDecoder (and I will explain the reasoning behind it shortly).
Creating and registering a channel handler in shared mode is simply a matter of instantiating one instance and re-using it in all created pipelines. The following code reimplementsMyStringServerFactory using a shared StringDecoderand StringEncoder:
Indicates that the same instance of the annotated
ChannelHandlercan be added to one or moreChannelPipelines multiple times without a race condition.
If this annotation is not specified, you have to create a new handler instance every time you add it to a pipeline because it has unshared state such as member variables.
This annotation is provided for documentation purpose, just like the JCIP annotations.
It's safe to say that the author summed it up with more brevity than I did, but also informs the reader that the annotation is informational only, so there is no built-in use of the annotation within the API implementation itself, although the @Retention of the annotation is RUNTIMEso it can be detected by your code, so using a bit of Reflection[s], I whipped up this table that categorizes all the channel handlers included in the Netty API into Sharable, Exclusive, Upstream, Downstream, and Both. Excluded from this table are abstract and inner classes as well asSimpleChannelHandler, SimpleChannelUpstreamHandlerand SimpleChannelDownstreamHandler. Those last three are concrete channel handlers and are not annotated as @Sharable but they are, what I refer to as, logically abstract, or empty implementations. By themselves, they do nothing and are intended for extending when implementing your own handler classes.
| Direction | Sharable | Exclusive |
|---|---|---|
| Upstream |
|
|
| Downstream |
|
|
| Both |
|
|
Decoders
You might notice a few instances of asymetry when it comes to sharability. For example, theObjectEncoder is sharable, but the ObjectDecoder is not. This is revealing about the nature of handlers. An ObjectEncoder's job is to convert an object into a byte array (ok, a ChannelBuffer), and it is passed the complete payload (the object to be encoded) so there is no need to retain any state. In contrast, the ObjectDecoder has to work with a bunch of bytes which may, or may not be complete for the purposes of reconstituting back into an object. Think about a serialized object being sent from a remote client. It has been serialized into a byte stream of possibly several thousand bytes. When the decoder is first called, the bytestream may be incomplete, with some portion of the byte stream still being transported.
Don't even think about having the handler wait for the rest of the byte stream to arrive before proceeding. That sort of thing is just not done around these parts, because Netty is an asynchronous API and we're not going to allocate a pool of worker threads (remmeber, they do all real work) to sit around waiting for I/O to complete. Accordingly, when there are bytes available for processing, a worker thread will be allocated to process it through execution of the ObjectDecoder's decode method. This is the signature of that method:
Object decode(ChannelHandlerContext ctx, Channel channel, ChannelBuffer buffer)
When this method is called, if the buffer contains the complete set of bytes required to decode into an object, then the decoded object will be returned and passed on to the next upstream handler. If not, the handler returns a null, in effect signaling a No Op. Either way, the worker thread doing the work is off onto doing something else once the invocation is complete.
That's a standard pattern for decoders. Examining ObjectDecoder specifically, we can see that it extendsLengthFieldBasedFrameDecoder, and a brief glance at the sourceof that class shows the following non-final instance fields:
privateboolean discardingTooLongFrame;
privatelong tooLongFrameLength;
privatelong bytesToDiscard;
These fields are the state being protected by making this handler exclusive. The actual byte stream being decoded is not stored in state, but rather accumulates in the same instance of the ChannelBuffer passed to the decode each time an invocation is made to decode the specific byte stream. This is an important conceptual point to understand: A decoder may be invoked more than once in order to decode a byte stream. Completion results in a returned object; in-completion results a returned null (and an assumption of more invocations to follow).
Non-Blocking = Scalability ?
An important takeaway from this is the notion that worker threads only kick in when there is work to do, rather than blocking waiting for I/O to deliver bytes to process. Consider a simple and contrived scenario where a server listens for clients submitting serialized java objects. Implementing a blocking I/O reader, the thread spawned to process a given client's object submission might create a java.io.ObjectInputStream to read from theSocketInputStream. Bytes are read in and objects are spit out the other side. If the byte stream is constantly full, then we would have efficient use of worker threads, although the model still requires one thread to be dedicated to each connected client. Fair enough, since there is a constant supply of data to process, all things being equal.
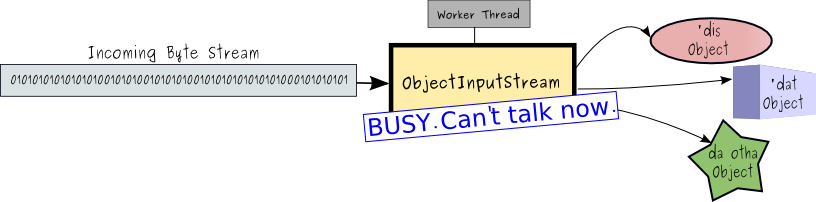
However, what happens if the supply of bytes to process is intermitent ? Perhaps the clients only supply data intermitently, or perhaps the network has limited bandwidth and/or is congested, delaying the object transmissions. Now the server has allocated threads to read (and block) from the input stream, but there are long periods of time where there is nothing to do but wait for work to arrive.
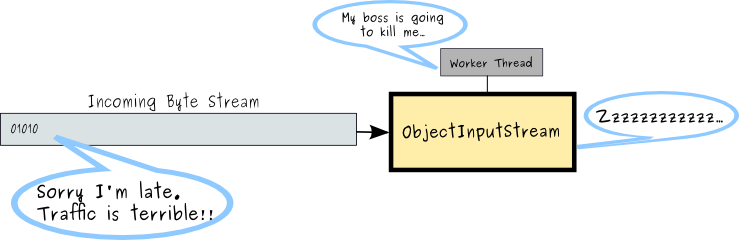
This is one of the reasons that non-blocking I/O tends to scale better than traditional blocking I/O. Note, it does not necessarilly make it faster, it allows the server to accept and process an escalating number of clients for a more controlled and reduced level of resource allocation. For smaller numbers of clients, it is quite likely that blocking I/O will be faster, since dedicated threads require less supervision. Of course, since Netty supports both blocking (OIO) and non-blocking (NIO) channels, a Netty developer can create all sorts of services that can be configured to use either. Which one is appropriate for any given application is so dependent on many application specific factors that it is rarely possible to state any hard rules about this. The Netty javadoc for the org.jboss.netty.channel.socket.oio package attempts to set a rule of thumb regarding the use of OIO:
Old blocking I/O based socket channel API implementation - recommended for a small number of connections (< 1000).
That seems high to me, but hardware, network, traffic types and other factors will certainly influence the magic number.
Framing (buffers, not pictures)
ObjectDecoder extends LengthFieldBasedFrameDecoder because the latter performs a critical function necessary in many decoders. Without a frame decoder, the object decoder would be faced with an entire unsegmented byte stream, not knowing where one serialized object ended and the next one started.

Of course, the CompatibleObjectDecoder can do this because it expects a standard java serialization stream, but there are several downsides to this, not the least of which is that they payloads will be significantly larger. In order to help the ObjectDecoder figure out which bytes belong to which serialized object, the frame decoder part of the class knows how to segment the byte stream into discrete chunks that the ObjectDecoder can assume are the contents of one object.

There are two points to note from this:
- Most non-trivial decoders are either implementing a known protocol specification (like HTTP for example) or are expecting the payload to have been "massaged" by the encoding counterpart (like the ObjectEncoder).
- The opportunity for optimization with the Netty encoder/decoder pairs is a good (though not the only) reason to use Netty even if you're using the traditional blocking IO ( OIO ) model.
Please note that this decoder must be used with a proper
FrameDecodersuch asDelimiterBasedFrameDecoderif you are using a stream-based transport such as TCP/IP.
- Fixed Length: No specific encoder, just use fixed length strings / FixedLengthFrameDecoder
- Length Field Prepend: LengthFieldPrepender / LengthFieldBasedFrameDecoder
- String delimiter: No specific encoder, but strings should be delimited by the specified delimiters /DelimiterBasedFrameDecoder.
To frame-up this discussion on frames, channel handlers are often put to work in conjunction with each other. This can be within one pipleline, such as a frame decoder before a string decoder. In addition, a decoder's decoding algorithm may rely on a counterpart encoder's encoding.
ChannelHandler State
Although the most common (and recommended) way of handling state in a ChannelHandler is to use instance fields and then make sure the handler is used exclusively ( a new instance per pipeline inserted into ), there are a couple of ways of keeping state safely in a shared ChannelHandler.
The ChannelHandlerContext class provides the notion of an attachment which is a store that is specific to a channel and handler instance. It is accessed using the getter and setter methods:
void channelHandlerContext.setAttachment(Object obj)
Object channelHandlerContext.getAttachment()
Typically, if you only need to keep state within a handler across calls to the handler, the attachment model is suitable. However, if you need to access state specific to a channel outside [and/or inside] the handler, Netty provides an analog to ThreadLocal called a ChannelLocal. Obviously, since this state is channel specific, but may be accessed by multiple different threads, a ThreadLocal does not serve this purpose. While a ThreadLocal is essentially a bit of data keyed in part by the owning thread, a ChannelLocal is similar in that it is a bit of data keyed by the owning channel. Accordingly, you can define a static field and using the channel as the key, access the value from pretty much anywhere in your code. The primary methods are:
void channelLocal.set(Channel channel, T value)
T channelLocal.get(Channel channel)
This concludes the discussion specific to handlers. It seems to me that a missing piece here is a walk-through of building a read world encoder/decoder pair that really does something useful, and I will endeavor to do this in a future entry.
Channel Options
Channel options are configuration name/value pairs that are used as a loosely typed way of configuring various bits-and-pieces in Netty. They fall into four categories:
- General Netty Configuration
- Client Socket Configuration
- Server Socket Configuration
- Server Child Socket Configuration
General Netty Channel Options
- bufferFactory: An instance of a ChannelBufferFactory that will be called to create new ChannelBuffers. This might be useful in order to customize the byte order of created channels, or to create direct (off heap) buffers.
- connectTimeoutMillis: The number of milliseconds before a connection request times out. Ignored if the channel factory creates connectionless channels.
- pipelineFactory: An instance of a ChannelPipelineFactory
- receiveBufferSizePredictor: UDP packets are received into pre-created byte arrays, which is an unresolvable dilema in that you don't know how much space to allocate until you have received the datagram, but to receive the datagram, you have to allocate a buffer to receive it. BufferSizePredictors provide a way to customize the size of those arrays based on some intelligence you might have about the expected size.
- receiveBufferSizePredictorFactory: A factory for creating buffer size predictors.
Socket Channel Options
- Client Socket: A socket on the client side of a TCP connection to a server.
- Datagram Socket: A socket on the client and/or server side of a unicast UDP conversation.
- Multicast Socket: A socket on the client and/or server side of a multicast UDP conversation.
- Server Socket: A specialized socket on the server side of a TCP server that brokers connection requests from client sockets and spins up a new Socket dedicated to that connection in an action referred to as an accept. Aside from the initial connection, a client socket does not communicate with the server socket.
- Child Socket: The socket created on the server, by the server socket, to communicate with a client socket.
All of these socket types support options outlined in java.net.SocketOptions and many of them can have a significant impact on performance. The options are listed below with the SocketOption constant name and the Netty channel option equivalent.
- IP_MULTICAST_IF / networkInterface: The name of the interface on which outgoing multicast packets should be sent. When a host has multiple network interfaces, this tends to be quite important.
- IP_MULTICAST_IF2 / networkInterface: The same as IP_MULTICAST_IF but defined again for good measure.
- IP_MULTICAST_LOOP / loopbackModeDisabled: Defines if multicast packets should be received by the sender of the same.
- IP_TOS / trafficClass: Sets the type of service or traffic class in the headers of packets.
- SO_BINDADDR / : A read only option representing the bind interface of a local socket.
- SO_BROADCAST / broadcast: Enables or disables a DataGramSocket's ability to send broadcast messages,
- SO_KEEPALIVE / keepAlive: A flag indicating that probes should be periodically sent across the network to the oposing socket to keep the connection alive.
- SO_LINGER / soLinger: Allows the close of a socket to be delayed for a period of time to allow completion of I/O.
- SO_OOBINLINE / : Allows Out of Band TCP Urgent data transmissions to be received through the normal data channel rather than discarded.
- SO_RCVBUF / receiveBufferSize: The size in bytes of the socket's data receive buffer.
- SO_REUSEADDR / reuseAddress: When set to true, allows multiple DatagramSockets to be bound to the same socket address if the option is enabled prior to binding the socket.
- SO_SNDBUF / sendBufferSize: The size in bytes of the socket's data send buffer.
- SO_TIMEOUT / connectTimeoutMillis: Sets a timeout in ms. on blocking socket operations.
- TCP_NODELAY / tcpNoDelay: Disables Nagle's algorithm on the socket which delays the transmission of data until a certain volume of pending data has accumulated.
SO_Timeout vs. ChannelFuture Await
The connectTimeoutMillis (or Socket SO_TIMEOUT) is sometimes confused with the timeout that can be set on a ChannelFuture using await or one of its equivalents. The SO_TIMEOUT is strictly the time limit (in ms.) that an I/O operation on the socket must complete in. If a connect I/O operation is not complete within that time, the socket instance will throw a java.net.ConnectException: connection timed out exception. On the other hand, the ChannelFuture's await timeout is simply the amount of time the calling thread will wait for the operation to complete. The timeout itself does not impact the operation and the operation is considered complete when it concludes, whether it was successful or not.
Having said that, if you wanted any asynchronous operation executed on a channel to be cancelled if it did not complete within a specific period of time, a ChannelFuture await timeout is useful because when the timeout elapses and the operation is found incomplete, it can be cancelled. This might be applicable, for example, in a mobile device scenario where you might want to save battery consumption by ensuring that network operations did not run an overly long time. Just because your application threads are not running, does not mean the device would not be consuming power attempting to complete a long running network operation that the application has long since forgotten about.
The following example will attempt to illustrate the difference and how they can be usefully implemented. This code sample is based on simple testing framework class called SimpleNIOClient. The code for the example is TimeoutTest. The test performed is very simple and just attempts to connect to an internet address using different values for the ChannelFuture await timeout and the client socket's SO_TIMEOUT.
The salient part of this test is the connect code and the timers that are placed around it.
public static void timeoutTest(long ioTimeout, long futureTimeout) {
// Create a map with the channel options
Map<String, Object> options = new HashMap<String, Object>();
options.put("connectTimeoutMillis", ioTimeout);
// Create the client
// Not providing any handlers since we're not using any for this test
SimpleNIOClient client = new SimpleNIOClient(options);
// Issue a connect operation
ChannelFuture cf = client.connect("heliosapm.com", 80);
// Add a completion listener
cf.addListener(new ChannelFutureListener() {
public void operationComplete(ChannelFuture future) throws Exception {
if(future.isSuccess()) {
clog("F: Connected:" + future.isDone());
} else {
if(future.isCancelled()) {
clog("Request Cancelled");
} else {
clog("Connect Exception:Success: " + future.isSuccess() + " Done: " + future.isDone() + " Cause: "+ future.getCause());
}
}
}
});
// Wait at least futureTimeout for the operation to complete
cf.awaitUninterruptibly(futureTimeout);
// If the operation is not complete, cancel it.
if(!cf.isDone()) {
clog("Channel Future Still Waiting. Cancelled:" + cf.cancel());
}
}
I run the test using arbitrarily low timeouts since I am trying to trigger connect timeouts. The invocation code looks like this:
// Timeout on I/O
timeoutTest(10, 500);
// Wait a bit so output is clear
try { Thread.sleep(2000); } catch (Exception e) {}
System.out.println("===============================");
// Timeout on future
timeoutTest(500, 10);
try { Thread.currentThread().join(5000); } catch (Exception e) {}
In the first case, on line 2, I want the SO_TIMEOUT timeout to occur, so I invoke with a low I/O timeout and a higher ChannelFuture timeout. On line 7, I reverse the values for a higher timeout on the socket, but a low timeout on the ChannelFuture. The output is as follows:
[Client][Thread[ClientBossPoolThread#1,5,ClientBossPoolThreadGroup]]:Socket Timeout Exception:Success: false Done: true Cause: java.net.ConnectException: connection timed out
===============================
[Client][Thread[main,5,main]]:Request Cancelled
[Client][Thread[main,5,main]]:Channel Future Still Waiting. Cancelled:true
In the first case, the socket timeout is so low that the operation completes quite quickly (although it does not succeed) so the future listener reports that the operation:
- Was not successful
- Is Complete
- Resulted in a ConnectException on account of a timed out connection.
Socket Buffer Sizes
The next example code I want to demonstrate uses another test harness called SimpleNIOServer. The test class is called AdjustableSocketBufferSizeServer. It requires a little explanation around some of the customizations, so please bear with....
ChannelHandlerProviderFactory
This is a channel handler factory that understands whether a channel handler class is sharable or exclusive, so when an instance of a ChannelHandlerProvider is given to the ChannelPipelineFactoryImpland it creates a new pipeline, it will either create a brand new handler instance (if exclusive) or provide the "singleton" instance already created. This is not critical to the example, but to avoid confusion, I am mentioning their use.
CustomServerBootstrap
This is a customized server bootstrap that allows me to change the channel options on the fly. In the native version, once a bootstrap has been created, the channel options are committed and I want to to be able to change the socket buffer sizes of created child channels on the fly. (Once a change is made, it affects only new connections from that point on.... it does not change existing socket buffer sizes). I also created a management interface called BootstrapJMXManager that allows me to make these changes through JMX.
Alright, the test class, AdjustableSocketBufferSizeServer, creates a new server usingSimpleNIOServer. It also creates a JMXConnectorServer and RMI Registry so the MBeanServer can easily be connected to so the child socket receive buffer sizes can be adjusted programatically, so that in turn the test case can be run automatically end to end.
The server's pipeline factory creates pipelines with the following handlers:
- Upstream:
- InstrumentedDelimiterBasedFrameDecoder with a "|" delimiter (exclusive)
- StringDecoder (shared)
- StringReporter (shared)
- Downstream:
- CompatibleObjectEncoder (shared)
The test is fairly straightforward:
- The client makes a JMX call to the server to specify the size of the server allocated child channel's socket receive buffer size.
- The client makes a new connection and sends a [longish] string to the server.
- The FrameDecoder splits the string content and sends the fragments upstream to the StringDecoder.
- The StringDecoder decodes the byte stream into a String and sends the strings upstream to the StringReporter.
- The StringReporter measures the length of the String, creates an int array with the length of the passed string and writes the array downstream back to the client.
- On its way downstream, the int[] is encoded using standard Java serialization in the CompatibleObjectEncoder.
- The client records the elapsed time to get a response from the server.
- The client increases the requested server allocated child channel's socket receive buffer size.
- Rinse, Repeat, (Go to #1.) for each subsequent defined buffer size
The script looping has an outer loop and an inner loop:
- Outer Loop: Iterates each socket receive buffer size defined in an array, sets this size on the server's bootstrap and executes the inner loops. Size: 5
- Inner Loop: Submits the configured string payload and captures the elapsed time to response. Size: 100
I am going to run the client side of the test from a Groovy script using the raw TCP Socket API, so the server pipeline uses a CompatibleObjectEncoder since the client cannot decode the optimized ObjectDecoder's payload. (It could, but I am sticking to a generic client).
InstrumentedDelimiterBasedFrameDecoder
Remember that for each logical request, server side decoders may need to be invoked several times in order to complete the task of reading the full bytestream and decoding it. When it is invoked, if the bytestream is not complete, it returns a null. Eventually, the bytestream will be complete and the decoder can complete the task and return the (non-null) decoded payload. This being the case, my theory was that the smaller the receiving socket's receive buffer size, the more times the decoder would need to be called. Or in contrast, the larger the receiving buffer size, the more likely that the full bytestream would be transmitted in one shot, reducing the number of required frame decoder calls to one.
To test this theory, I made a simple extension of the DelimiterBasedFrameDecoder that counts the number of times it is invoked by incrementing a counter in an instance variable. When the decode completes, the highwater counter value is written to a ChannelLocal and the counter is reset back to zero. Upstream, the StringReporter, which determines the length of the passed string and returns it to the client, also returns the count of frame decoder invocations by reading it from the ChannelLocal and adding it to the int[] payload returned to the client. In addition, it occurred to me that the socket buffer size might not actually be set to what the client requested. (Will it really set the buffer size to 2 bytes ??!!??) So I added a read of that value and appended it to the result sent back to the client. It is useful to note that when reading or writing channel options from a live (socket based) channel, they are read from and applied to the actual socket instance. With that, the client can report:
- The length of the submitted string reported by the server. (Not useful except as a validating assertion)
- The number of times the frame decoder was called for the most recently submitted string.
- The elapsed time of the request execution.
- The actual server socket receive buffer size.
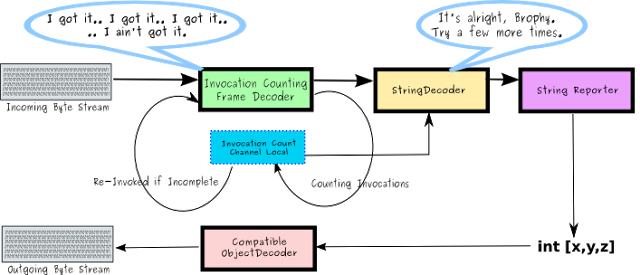
The server pipeline uses a CompatibleObjectEncoder since we're sending back an int[] and since the client is a simple socket client, not a Netty based client. It is a bit of overkill though. Whenever one is sending primitives, or arrays of primitives, it is possible to bypass modular encoding and simply write directly to a ChannelBuffer. Here's how we could remove the CompatibleObjectEncoder from the pipeline and rewrite the StringReporter's write of the int[].
// =====================================================================
// Uncomment next section to ditch the CompatibleObjectEncoder from the pipeline
// =====================================================================
ChannelBuffer intBuffer = ChannelBuffers.buffer(12);
for(int i = 0; i < 3; i++) {
intBuffer.writeInt(ret[i]);
}
ctx.sendDownstream(new DownstreamMessageEvent(e.getChannel(), Channels.future(e.getChannel()), intBuffer, e.getChannel().getRemoteAddress()));
// ===================================================================== // =====================================================================
// Comment the next line to ditch the CompatibleObjectEncoder from the pipeline
// =====================================================================
// ctx.sendDownstream(new DownstreamMessageEvent(e.getChannel(), Channels.future(e.getChannel()), ret, e.getChannel().getRemoteAddress()));
Having done that, the groovy script client (coming up next) which normally uses an ObjectInputStreamto read objects from the SocketInputStream would be replaced with a DataInputStreamand the code would look like this:
/*
* The prior code
if(ois==null) {
ois = new ObjectInputStream(socket.getInputStream());
}
result = ois.readObject();
*/
if(ois==null) {
ois = new DataInputStream(socket.getInputStream());
}
result = new int[3];
for(index in 0..2) {
result[index] = ois.readInt();
}
Groovy Client Script and Network Kernel Tuning
This is the groovy test client I used to test the server. I admit that this script is a bit messy, but it does the job. I won't go over it in too much detail, excepting drawing your attention to the following:
- The client sends the same string each time, since the varying value being adjusted to measure the effect is the server's socket receive buffer size.
- The string content is fairly arbitrary and generated by appending all the JVM's system property key/value pairs a couple of times. Once generated, the same string is used in each call.
- The socket receive buffer sizes tested are defined in this int array: [1144, 2288, 4576, 9152, 18304, 36608, 73216, 146432, 292864, 585728]
Since the script assertively validates that the socket receive buffer size is actually what the client set it to, I found that when I requested a buffer size of 146,432, I got an assertion failure with the actual reported buffer size being only 131,071. As it happens, my Linux network kernel configuration had limited the maximum size of of socket receive buffers to 131,071. In order to raise this limit, running in a sudo'ed shell, I did this:
- sysctl -a | grep mem > ~/sysctl-mem.txt (Saved the current settings for rollback purposes)
- sysctl -w net.core.rmem_max=8388608 (Set the maximum buffer size to 8.3 MB)
- sysctl net.core.rmem_max (Verified the value was set. Output was "net.core.rmem_max = 8388608")
- sysctl -w net.ipv4.route.flush=1 (Flushed the settings so they took effect immediately)
This is a useful reference for tuning the network kernel in Linux. Here is a guide for TCP tuning on different operating systems. I should also note that the string I generated as the sample test payload was 8,088 bytes before being delimited with a single "|".
Here are the charted results of the test, with the socket receive buffer size on the x-axis and the average elapsed time of each request in ms. on the first y-axis. The second y-axis represents the average number of times the Frame Decoder was called for each request.

The results are pretty much what I expected and I think quite intuitive:
- The average elapsed time of the request executions is inversely proportional to the server child socket's receive buffer size until the buffer size is large enough to contain the whole request payload.
- The average number of frame decoder invocations per request execution is inversely proportional to the server child socket's receive buffer size until the buffer size is large enough to contain the whole request payload.
That's it for entry 1.5. I hope it has been helpful, if not outright entertaining. I am delighted to get any feedback, and genuinely pleased to answer any questions. As promised, in entry 2.0, I will be discussing implementing Ajax push in Netty (with no further decimal releases in the 1 range).
Part 1 of this series: Netty Tutorial Part 1: Introduction to Netty
Netty Tutorial Part 1.5: On Channel Handlers and Channel Options [z]的更多相关文章
- Netty Tutorial Part 1: Introduction to Netty [z]
Netty Tutorial, Part 1: Introduction to Netty Update: Part 1.5 Has Been Published: Netty Tutorial P ...
- golang 的 buffered channel 及 unbuffered channel
The channel is divided into two categories: unbuffered and buffered. (1) Unbuffered channelFor unbuf ...
- netty源码解解析(4.0)-12 Channel NIO实现:channel初始化
创建一个channel实例,并把它register到eventLoopGroup中之后,这个channel然后处于inactive状态,仍然是不可用的.只有在bind或connect方法调用成功之后才 ...
- 实时事件统计项目:优化flume:用file channel代替mem channel
背景:利用kafka+flume+morphline+solr做实时统计. solr从12月23号开始一直没有数据.查看日志发现,因为有一个同事加了一条格式错误的埋点数据,导致大量error. 据推断 ...
- Fibre Channel和Fiber Channel
Fibre Channel也就是"网状通道"的意思,简称FC. 由于Fiber和Fibre只有一字之差,所以产生了很多流传的误解. FC只代表Fibre Channel,而不是 ...
- Netty实战 - 1. 基本概念
1. Netty简介 Netty是由JBOSS提供的一个java开源框架.它提供异步的.事件驱动的网络应用程序框架和工具,用以快速开发高性能.高可靠性的网络服务器和客户端程序.Netty是一个基于NI ...
- [源码解析] 消息队列 Kombu 之 基本架构
[源码解析] 消息队列 Kombu 之 基本架构 目录 [源码解析] 消息队列 Kombu 之 基本架构 0x00 摘要 0x01 AMQP 1.1 基本概念 1.2 工作过程 0x02 Poll系列 ...
- [源码分析] 消息队列 Kombu 之 启动过程
[源码分析] 消息队列 Kombu 之 启动过程 0x00 摘要 本系列我们介绍消息队列 Kombu.Kombu 的定位是一个兼容 AMQP 协议的消息队列抽象.通过本文,大家可以了解 Kombu 是 ...
- [源码分析] 消息队列 Kombu 之 Hub
[源码分析] 消息队列 Kombu 之 Hub 0x00 摘要 本系列我们介绍消息队列 Kombu.Kombu 的定位是一个兼容 AMQP 协议的消息队列抽象.通过本文,大家可以了解 Kombu 中的 ...
随机推荐
- s21day02 python笔记
s21day02 python笔记 一.昨日内容回顾及补充 内容回顾 补充 if条件语句嵌套 10086示例 pycharm更改解释器 python3.7解释器 python2.7解释器 二.循环语句 ...
- Mac下常用工具
MySql--Sequel Pro
- django JsonResponse和HttpResponse的在后端和前端区别
JsonResponse和HttpResponse的区别 1.from django.http import JsonResponse return JsonResponse('例子') 2.impo ...
- Win-Lin双系统重装Windows找回Linux启动
第一系统Windows,第二系统Linux:Ubuntu18.10: 1. 重新安装Windows系统后,使用Ubuntu的安装光盘,或启动U盘启动电脑:2. 选择:Try Ubuntu ;3. 进入 ...
- LeetCode - Subtree of Another Tree
Given two non-empty binary trees s and t, check whether tree t has exactly the same structure and no ...
- OpenGL编程-OpenGL框架-win32项目
在win32项目中开发的程序 小知识: 控制台应用程序运行就是dos的界面 项目一般采用了可视化开发 开发出来的东西就像QQ之类的 是有窗口界面的 程序运行结果是这样的 源代码:对第45行进行覆盖 # ...
- sofa graphql 2 rest api 试用
大部分代码还是来自sofa 的官方文档,同时添加了docker && docker-compose集成 备注: 代码使用typescript 同时运行的时候为了方便直接运行使用ts ...
- Python_TCP/IP简介
本篇将开始介绍Python的网络编程,更多内容请参考:Python学习指南 自从互联网诞生以来,现在基本上所有的程序都是网络程序,很少有单机版的程序了. 计算机网络就是把各个计算机连接在一起,让网络中 ...
- MySQL插入,更新,删除数据
插入 单行插入 1.insert into 表名 values(col1_value,col2_value,...); 每个列必须提供一个值,如果没有值,要提供NULL值 每个列必须与它在表中定义的次 ...
- asyn proposals
Objective: