Python3 Srcapy 爬虫
最近一直在理论学习,没有时间写博客。今天来一波Python爬虫,为机器学习做数据准备。
爬虫配置环境 Anaconda3 + Spyder + Scrapy
Anaconda 安装就不绍了,网上很多。下面简单介绍一Scrapy的安装,重点介绍Scrapy编写爬虫
#Scrapy 安装
conda install scrapy
Scrapy安装好后,开始第一个项目:
#打开cmd终端或者Anaconda 自带的Anaconda Prompt,本人极力推荐后者
scrapy startproject project_name
#project_name 是项目名称,不能带有路径比如H:/Python/project_name这种格式是不行
scrapy startproject zhufang #这是我写的项目名称
小说明:使用scrapy 创建好项目后,Spyder中无法识别到这个项目的(Pycharm可以识别到)。在这里可以先在Spyder中建立一个空项目,然后把scrapy建立好的项目整个文件夹拷贝到Spyder建立好的空文件夹下。实例如下:
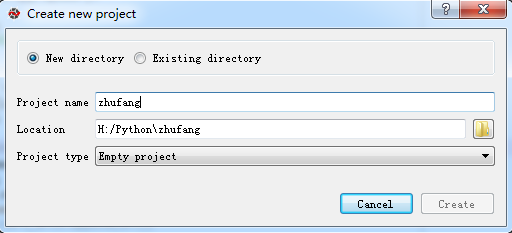
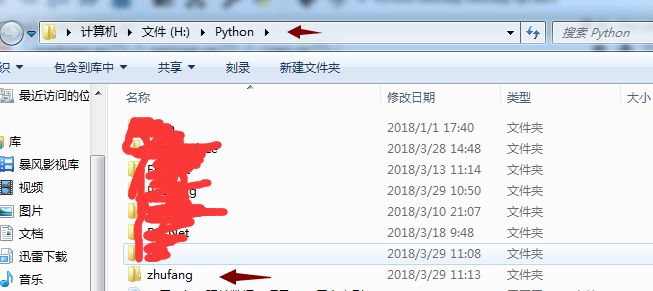
#打开Anaconda Prompt 执行以下命令
H:
cd Python\zhufang
scrapy startproject zhufang
建立好项目后,在打开Spyder,找到项目,可以看到如下图所示的文件目录结构。其中的ganji.py 和zhufang.db是我自己后来建的。ganji.py 是主要核心部分,zhufang.db是数据库文件,使用python自带的sqlite3建立的。文件的其他说明我就不班门弄釜了,我在网上找到一个写的很全的文章,分享给大家 http://python.jobbole.com/86405/
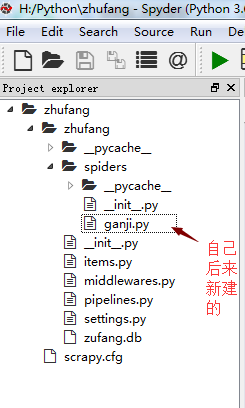
我在写爬虫遇到一个最困惑的问题就是不知道爬虫的入口哪里,以及如何自动跳转到下一页面爬取。最后这个问题归结到了start_requests函数,将其重写,按照要爬取的目标网站的网址URL所遵循的规律写。下面附上本次爬虫经历的所有代码
# -*- coding: utf-8 -*-
#ganji.py import scrapy
from zhufang.items import ZhufangItem class GanJiSpyder(scrapy.Spider): name = "ganji";
URL = "http://dl.ganji.com/fang1/";
#下一页地址
#http://dl.ganji.com/fang1/o{pagenum}/
#url_change = "o1";
start_urls = [];
start_page = 1;
end_page = 10;
#重写start_requests 爬虫的入口
def start_requests(self):
pages = [];
while self.start_page <= self.end_page:
url = self.URL + 'o' + str(self.start_page);
#self.start_urls.append(url);
#请求url
page = scrapy.Request(url);
self.start_page = self.start_page + 1;
pages.append(page);
return pages; def parse(self,response):
#print(response);
price_list = response.xpath("//div[@class='f-list-item ershoufang-list']/dl[@class='f-list-item-wrap f-clear']/dd[@class='dd-item info']/div[@class='price']/span[1]/text()").extract();
title_list = response.xpath("//div[@class='f-list-item ershoufang-list']/dl[@class='f-list-item-wrap f-clear']/dd[@class='dd-item title']/a/text()").extract();
zf = ZhufangItem(); for t,p in zip(title_list,price_list):
#将数据存入item中,与Items 文件中定义的字段对应
zf['title'] = t;
zf['price'] = p;
yield zf; #回调失败
# yield scrapy.Request(URL + url_change, callback = parse) #print("%s : %s" % (t,p));
# -*- coding: utf-8 -*- #piplines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
#管道文件 将爬到的数据在这里清理 存入数据库 import sqlite3 class ZhufangPipeline(object):
#重写爬虫开始函数
def open_spider(self,spider):
#连接数据库
self.con = sqlite3.connect("zufang.db");
self.cu = self.con.cursor(); def process_item(self, item, spider):
#print(spider.name);
sql_insert = "insert into info (title,price) values('{}','{}')".format(item["title"],item["price"]);
#print(sql_insert);
self.cu.execute(sql_insert);
self.con.commit();
return item #重写爬虫结束函数
def spider_close(self,spider):
self.con.close();
#setting.py
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
#标记ZhufangPipeline 这个类 ,后面的值范围【1,1000】,根据值的大小依次顺序执行
'zhufang.pipelines.ZhufangPipeline': 300,
}
# -*- coding: utf-8 -*-
#items.py
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy #数据通过items文件中的ZhufangItem类才能传回到管道文件pipelines中
class ZhufangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#pass
#定义字段
title = scrapy.Field();
price = scrapy.Field();
最后,由于项目中有文件夹的嵌套,在模块引用的时候可能会出现问题,在这里也附上一个很好的文章 https://www.cnblogs.com/ArsenalfanInECNU/p/5346751.html
Python3 Srcapy 爬虫的更多相关文章
- Python3.x爬虫教程:爬网页、爬图片、自己主动登录
林炳文Evankaka原创作品. 转载请注明出处http://blog.csdn.net/evankaka 摘要:本文将使用Python3.4爬网页.爬图片.自己主动登录.并对HTTP协议做了一个简单 ...
- Python3 网络爬虫(请求库的安装)
Python3 网络爬虫(请求库的安装) 爬虫可以简单分为几步:抓取页面,分析页面和存储数据 在页面爬取的过程中我们需要模拟浏览器向服务器发送请求,所以需要用到一些python库来实现HTTP的请求操 ...
- 崔庆才Python3网络爬虫开发实战电子版书籍分享
资料下载地址: 链接:https://pan.baidu.com/s/1WV-_XHZvYIedsC1GJ1hOtw 提取码:4o94 <崔庆才Python3网络爬虫开发实战>高清中文版P ...
- python3网络爬虫系统学习:第一讲 基本库urllib
在python3中爬虫常用基本库为urllib以及requests 本文主要描述urllib的相关内容 urllib包含四个模块:requests——模拟发送请求 error——异常处理模块 pars ...
- Python3 常用爬虫库的安装
Python3 常用爬虫库的安装 1 简介 Windows下安装Python3常用的爬虫库:requests.selenium.beautifulsoup4.pyquery.pymysql.pymon ...
- 《Python3 网络爬虫开发实战》开发环境配置过程中踩过的坑
<Python3 网络爬虫开发实战>学习资料:https://www.cnblogs.com/waiwai14/p/11698175.html 如何从墙内下载Android Studio: ...
- 《Python3 网络爬虫开发实战》学习资料
<Python3 网络爬虫开发实战> 学习资料 百度网盘:https://pan.baidu.com/s/1PisddjC9e60TXlCFMgVjrQ
- python3版 爬虫了解
摘要:本文将使用Python3.4爬网页.爬图片.自动登录.并对HTTP协议做了一个简单的介绍.在进行爬虫之前,先简单来进行一个HTTP协议的讲解,这样下面再来进行爬虫就是理解更加清楚. 一.HTTP ...
- # Python3微博爬虫[requests+pyquery+selenium+mongodb]
目录 Python3微博爬虫[requests+pyquery+selenium+mongodb] 主要技术 站点分析 程序流程图 编程实现 数据库选择 代理IP测试 模拟登录 获取用户详细信息 获取 ...
随机推荐
- G - Preparing for Exams
题目链接: https://vjudge.net/contest/251958#problem/G 具体思路: 圆内四边形内角互补,所以,如图所示. 证明,三角形oda和三角形obc相似. 第一步,角 ...
- Python 爬虫学习
#coding:utf-8 #author:Blood_Zero ''' 1.获取网页信息 2.解决编码问题,通过charset库(默认不安装这个库文件) ''' import urllib impo ...
- mysql授权报错 ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
授权用户时报错,ERROR 1819 (HY000): Your password does not satisfy the current policy requirements 原因为其实与val ...
- java并发编程系列七:volatile和sinchronized底层实现原理
一.线程安全 1. 怎样让多线程下的类安全起来 无状态.加锁.让类不可变.栈封闭.安全的发布对象 2. 死锁 2.1 死锁概念及解决死锁的原则 一定发生在多个线程争夺多个资源里的情况下,发生的原因是 ...
- 为你的VPS进行一些安全设置吧
安全是一个VPS最基本的必备条件,若您的VPS三天两头被人攻破,那么对于网站来说也没什么意义了,所以,在创建了Web服务器之后,您首先要做的事情就是将您的VPS加固,至少让普通黑客没有办法能够攻破您的 ...
- JS正则表达式大全(附例子)
0 前言 正则表达式用来字符串匹配,格式校验,非常cool且有趣. 1 正则表达式中的特殊字符 \ 做为转义,即通常在"\"后面的字符不按原来意义解释,如/b/匹配字符" ...
- Android 自定义View二(深入了解自定义属性attrs.xml)
1.为什么要自定义属性 要使用属性,首先这个属性应该存在,所以如果我们要使用自己的属性,必须要先把他定义出来才能使用.但我们平时在写布局文件的时候好像没有自己定义属性,但我们照样可以用很多属性,这是为 ...
- python之鸭子类型
python不支持多态,也不用支持多态,python是一种多态语言,崇尚鸭子类型. 在程序设计中,鸭子类型是动态类型的一种风格,不是由继承特定的类或实现特定的接口,而是当前的方法和属性的集合决定,鸭子 ...
- C++ code:char pointers and char arrays(字符指针与字符数组)
C-串的正确赋值.复制.修改.比较.连接等方式. #include<iostream> #pragma warning(disable: 4996)//这一句是为了解决“strrev”出现 ...
- ZOJ 3229 Shoot the Bullet(有源汇上下界最大流)
题目链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=3442 题目大意: 一个屌丝给m个女神拍照,计划拍照n天,每一天屌丝给 ...