K中心点算法之PAM
对比kmeans:k-means是每次选簇的均值作为新的中心,迭代直到簇中对象分布不再变化。其缺点是对于离群点是敏感的,因为一个具有很大极端值的对象会扭曲数据分布。那么我们可以考虑新的簇中心不选择均值而是选择簇内的某个对象,只要使总的代价降低就可以。kmedoids算法比kmenas对于噪声和孤立点更鲁棒,因为它最小化相异点对的和(minimizes a sum of pairwise dissimilarities )而不是欧式距离的平方和(sum of squared Euclidean distances.)。一个中心点(medoid)可以这么定义:簇中某点的平均差异性在这一簇中所有点中最小。
1. 初始化:随机挑选n个点中的k个点作为中心点。
2. 将其余的点根据距离划分至这k个类别中。
3. 当损失值减少时:
1)对于每个中心点m,对于每个非中心点o:
i)交换m和o,重新计算损失(损失值的大小为:所有点到中心点的距离和)
ii)如果总的损失增加则不进行交换
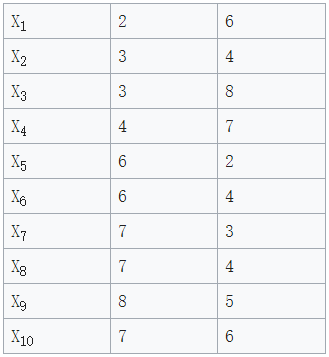
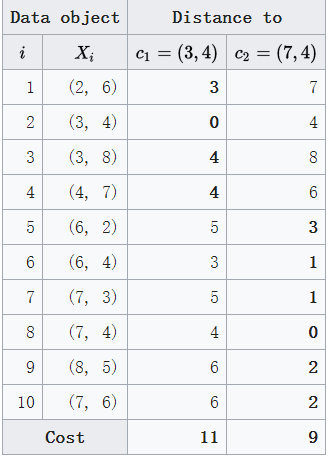
1. 随机挑选k=2个中心点:c1=(3,4) , c2=(7,4).那么将所有点到这两点的距离计算出来(图2),可以看到黑体为到两个中心点距离较小的距离值。那么根据图2,我们可以对所有数据点进行归类:
Cluster1 = {(3,4)(2,6)(3,8)(4,7)}
Cluster2 = {(7,4)(6,2)(6,4)(7,3)(8,5)(7,6)}
很容易算出此时的损失值cost为:20
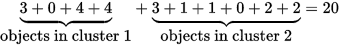
2. 挑选一个非中心点O’,让我们假定挑选的为X7 ,即O‘=(7,3)。那么此时这两个中心点暂时变成了c1(3,4) and O′(7,3),那么我们要计算一下这一替换措施所带来的损失cost:

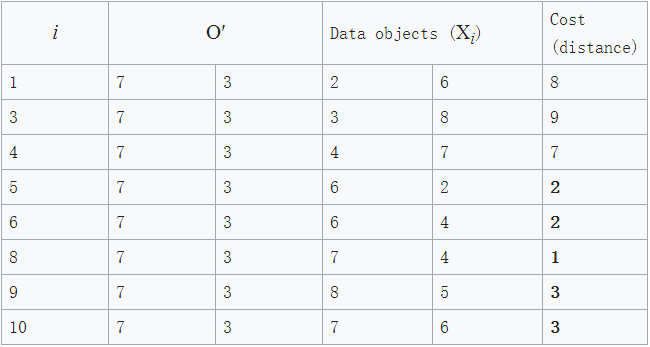
图3 图4
正如图3和图4所见,此时的cost(很好计算,黑体数值的和)变成了: total cost = 3+4+4+2+2+1+3+3 = 22
此时的cost为22,比之前的cost=20要大,所以这次替换的损失变大啦,我们最终不进行这次替换。
这仅仅是X7 替代了c2点,我们应该计算除了c1和c2点外的所有点外分别替代c1和c2,将这些替换后的损失都计算出来,看看有没有比20小的损失,如果有那么我们就将这个最小损失对应的中心点对作为新的中心点对。至此才完成了一次迭代。重复迭代直至收敛。
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sun Oct 22 20:31:32 2017 @author: LPS
""" import numpy as np
import pandas as pd
import copy df = np.loadtxt('waveform.txt',delimiter=',') # 载入waveform数据集,22列,最后一列为标签0,1,2
s= np.array(df)
print(s.shape)
print(s[0:10]) data0 = s[s[:,s.shape[1]-1]==0][:100] # 取标签为0的前100个样本
data1 = s[s[:,s.shape[1]-1]==1][:100] # 取标签为1的前100个样本
data2 = s[s[:,s.shape[1]-1]==2][:100] # 取标签为2的前100个样本 data = np.array([data0,data1,data2])
data = data.reshape(-1,22) def dis(data_a, data_b):
return np.sqrt(np.sum(np.square(data_a - data_b), axis=1)) # 返回欧氏距离 def kmeans_wave(n=10, k=3, data=data):
data_new = copy.deepcopy(data) # 前21列存放数据,不可变。最后1列即第22列存放标签,标签列随着每次迭代而更新。
data_now = copy.deepcopy(data) # data_now用于存放中间过程的数据 center_point = np.random.choice(300,3,replace=False)
center = data_new[center_point,:20] # 随机形成的3个中心,维度为(3,21) distance = [[] for i in range(k)]
distance_now = [[] for i in range(k)] # distance_now用于存放中间过程的距离
lost = np.ones([300,k])*float('inf') # 初始lost为维度为(300,3)的无穷大 for j in range(k): # 首先完成第一次划分,即第一次根据距离划分所有点到三个类别中
distance[j] = np.sqrt(np.sum(np.square(data_new[:,:20] - np.array(center[j])), axis=1))
data_new[:, 21] = np.argmin(np.array(distance), axis=0) # data_new 的最后一列,即标签列随之改变,变为距离某中心点最近的标签,例如与第0个中心点最近,则为0 for i in range(n): # 假设迭代n次 for m in range(k): # 每一次都要分别替换k=3个中心点,所以循环k次。这层循环结束即算出利用所有点分别替代3个中心点后产生的900个lost值 for l in range(300): # 替换某个中心点时都要利用全部点进行替换,所以循环300次。这层循环结束即算出利用所有点分别替换1个中心点后产生的300个lost值 center_now = copy.deepcopy(center) # center_now用于存放中间过程的中心点
center_now[m] = data_now[l,:20] # 用第l个点替换第m个中心点
for j in range(k): # 计算暂时替换1个中心点后的距离值
distance_now[j] = np.sqrt(np.sum(np.square(data_now[:,:20] - np.array(center_now[j])), axis=1))
data_now[:, 21] = np.argmin(np.array(distance), axis=0) # data_now的标签列更新,注意data_now时中间过程,所以这里不能选择更新data_new的标签列 lost[l, m] = (dis(data_now[:, :20], center_now[data_now[:, 21].astype(int)]) \
- dis(data_now[:, :20], center[data_new[:, 21].astype(int)])).sum() # 这里很好理解lost的维度为什么为300*3了。lost[l,m]的值代表用第l个点替换第m个中心点的损失值 if np.min(lost) < 0: # lost意味替换代价,选择代价最小的来完成替换
index = np.where(np.min(lost) == lost) # 即找到min(lost)对应的替换组合
index_l = index[0][0] # index_l指将要替代某个中心点的候选点
index_m = index[1][0] # index_m指将要被替代的某个中心点,即用index_l来替代index_m center[index_m] = data_now[index_l,:20] #更新聚类中心 for j in range(k):
distance[j] = np.sqrt(np.sum(np.square(data_now[:, :20] - np.array(center[j])), axis=1))
data_new[:, 21] = np.argmin(np.array(distance), axis=0) # 更新参考矩阵,至此data_new的标签列得以更新,即完成了一次迭代 return data_new # 最后返回data_new,其最后一列即为最终聚好的标签 if __name__ == '__main__':
data_new = kmeans_wave(10,3,data)
print(data_new.shape)
print(np.mean(data[:,21] == data_new[:,21])) # 验证划分准确度
附:利用上面实现的代码对图片聚类。结果发现和kmeans相比实在是太慢了。就拿500*500的三通道jpg来说,有500*500=250000个像素值,即这个图像的数据集维度为(250000,3)。而上文我们实现的数据集维度仅仅为(300, 3)。这意味每次迭代都要循环250000*3次。所以我只好截选了一张小图来测试。。代码与结果如下:


图1.从1200*800图中截取的70*70的图片 图2. 迭代20次k=3的结果
其实这个结果意义不大,只是作为测试。因为像素分布太集中,可以选择其他分布较散的图像,此外改进pam算法来实现更高效的聚类。
K中心点算法之PAM的更多相关文章
- ML: 聚类算法R包-K中心点聚类
K-medodis与K-means比较相似,但是K-medoids和K-means是有区别的,不一样的地方在于中心点的选取,在K-means中,我们将中心点取为当前cluster中所有数据点的平均值, ...
- 聚类分析K均值算法讲解
聚类分析及K均值算法讲解 吴裕雄 当今信息大爆炸时代,公司企业.教育科学.医疗卫生.社会民生等领域每天都在产生大量的结构多样的数据.产生数据的方式更是多种多样,如各类的:摄像头.传感器.报表.海量网络 ...
- 【机器学习】K均值算法(I)
K均值算法是一类非监督学习类,其可以通过观察样本的离散性来对样本进行分类. 例如,在对如下图所示的样本中进行聚类,则执行如下步骤 1:随机选取3个点作为聚类中心. 2:簇分配:遍历所有样本然后依据每个 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- Bisecting KMeans (二分K均值)算法讲解及实现
算法原理 由于传统的KMeans算法的聚类结果易受到初始聚类中心点选择的影响,因此在传统的KMeans算法的基础上进行算法改进,对初始中心点选取比较严格,各中心点的距离较远,这就避免了初始聚类中心会选 ...
- KMeans (K均值)算法讲解及实现
算法原理 KMeans算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标 ...
- K均值算法
为了便于可视化,样本数据为随机生成的二维样本点. from matplotlib import pyplot as plt import numpy as np import random def k ...
- K均值算法-python实现
测试数据展示: #coding:utf-8__author__ = 'similarface''''实现K均值算法 算法摘要:-----------------------------输入:所有数据点 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
随机推荐
- [luogu4513]小白逛公园
题目描述 在小新家附近有一条"公园路",路的一边从南到北依次排着n个公园,小白早就看花了眼,自己也不清楚该去哪些公园玩了. 一开始,小白就根据公园的风景给每个公园打了分-.-.小新 ...
- 洛谷 P1691 有重复元素的排列问题 解题报告
P1691 有重复元素的排列问题 题目描述 设\(R={r_1,r_2,--,r_n}\)是要进行排列的\(n\)个元素.其中元素\(r_1,r_2,--,r_n\)可能相同.使设计一个算法,列出\( ...
- luogu1541 乌龟棋 (dp)
dp..dp的时候不能设f[N][x1][x2][x3][x4],会T,要把N省略,然后通过1/2/3/4牌的数量来算已经走到哪一个了 #include<bits/stdc++.h> #d ...
- JavaScript -- throw、try 和 catch
try 语句测试代码块的错误. catch 语句处理错误. throw 语句创建自定义错误. 很想java哦. <!DOCTYPE html> <html> <head& ...
- Jenkins中配置邮件通知实例演示
前言:本文通过安装配置Jenkins实现邮件通知,告知一个C# Git Repo的build成功与否 一.预配条件 在windows上安装Jenkins和它推荐安装的Plugins 创建一个@163. ...
- Luogu 1080 【NOIP2012】国王游戏 (贪心,高精度)
Luogu 1080 [NOIP2012]国王游戏 (贪心,高精度) Description 恰逢H国国庆,国王邀请n位大臣来玩一个有奖游戏.首先,他让每个大臣在左.右手上面分别写下一个整数,国王自己 ...
- LOJ#2095 选数
给定n,k,l,r 问从[l, r]中选出n个数gcd为k的方案数. 解:稍微一想就能想到反演,F(x)就是[l, r]中x的倍数个数的n次方. 后面那个莫比乌斯函数随便怎么搞都行,当然因为这是杜教筛 ...
- .net Forms身份验证不能用在应用的分布式部署中吗?
参照网上的一些方法,使用Forms身份验证对应用进行分布式部署,发现没有成功. 应用部署的两台内网服务器:192.168.1.19,192.168.1.87,使用Nginx做负载分配,配置完全相同:每 ...
- (转)Servlet的生命周期——初始化、运行、销毁全部过程
背景:面试中很基础的一个问题,所以有必要好好整理一番. Servlet体系结构是建立在 Java 多线程机制上的,它的生命周期由 Web 容器负责. 当客户端第一次请求某个 Servlet 时,Ser ...
- mac 终端输入带空格的路径 cd
mac 在终端如何进入名称带空格的目录? 后来找到原因,是因为要对空格转义或者输入“ ”或‘ ’,方案如下: 1. cd Appications/Android\Studio.app/sdk 这个好 ...