数据结构(C语言版)-第6章 图
6.1 图的定义和基本术语
图:Graph=(V,E)
V:顶点(数据元素)的有穷非空集合;
E:边的有穷集合。
无向图:每条边都是无方向的
有向图:每条边都是有方向的
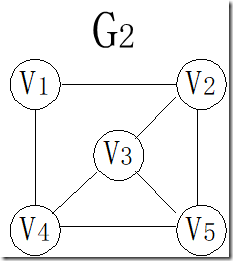
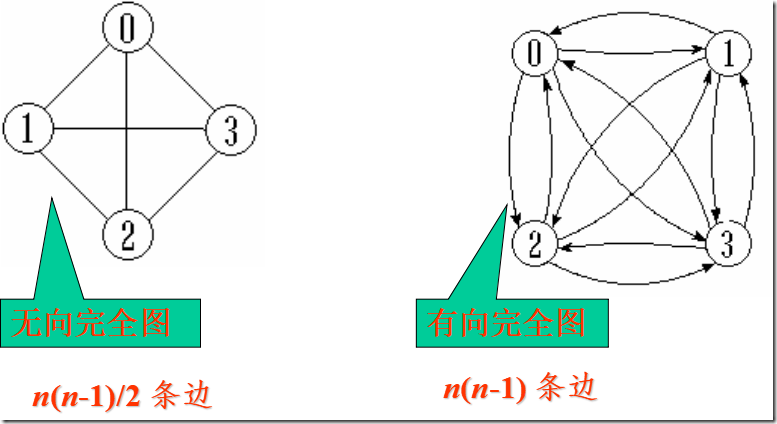
完全图:任意两个点都有一条边相连
稀疏图:有很少边或弧的图。
稠密图:有较多边或弧的图。
网:边/弧带权的图。
邻接:有边/弧相连的两个顶点之间的关系。
存在(vi, vj),则称vi和vj互为邻接点;
存在<vi, vj>,则称vi邻接到vj, vj邻接于vi
关联(依附):边/弧与顶点之间的关系。
存在(vi, vj)/ <vi, vj>, 则称该边/弧关联于vi和vj
顶点的度:与该顶点相关联的边的数目,记为TD(v)
在有向图中, 顶点的度等于该顶点的入度与出度之和。
顶点 v 的入度是以 v 为终点的有向边的条数, 记作 ID(v)
顶点 v 的出度是以 v 为始点的有向边的条数, 记作OD(v)

路径:接续的边构成的顶点序列。
路径长度:路径上边或弧的数目/权值之和。
回路(环):第一个顶点和最后一个顶点相同的路径。
简单路径:除路径起点和终点可以相同外,其余顶点均不相同的路径。
简单回路(简单环):除路径起点和终点相同外,其余顶点均不相同的路径。
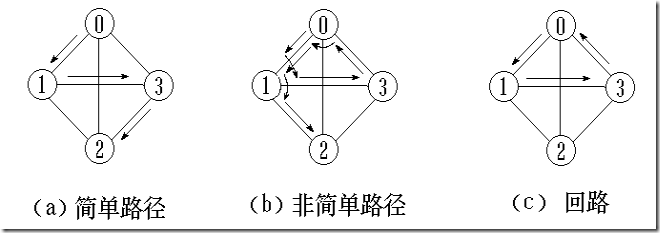
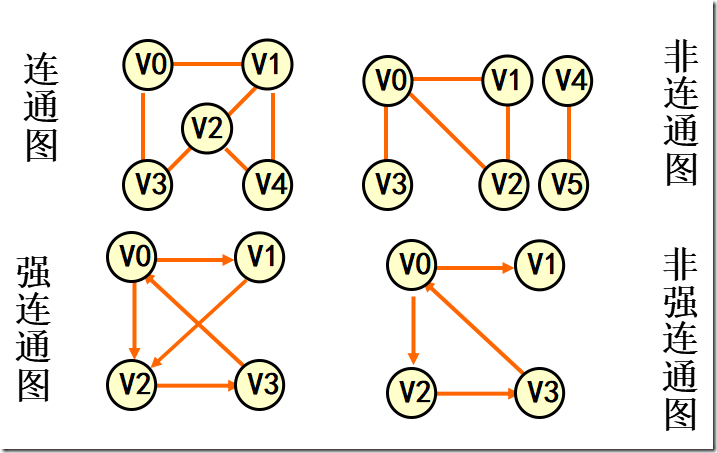
连通图(强连通图)
在无(有)向图G=( V, {E} )中,若对任何两个顶点 v、u 都存在从v 到 u 的路径,则称G是连通图(强连通图)。
权与网:图中边或弧所具有的相关数称为权。表明从一个顶点到另一个顶点的距离或耗费。带权的图称为网。
子图:设有两个图G=(V,{E})、G1=(V1,{E1}),若V1属于V,E1 属于 E,则称 G1是G的子图。 例:(b)、(c) 是 (a) 的子图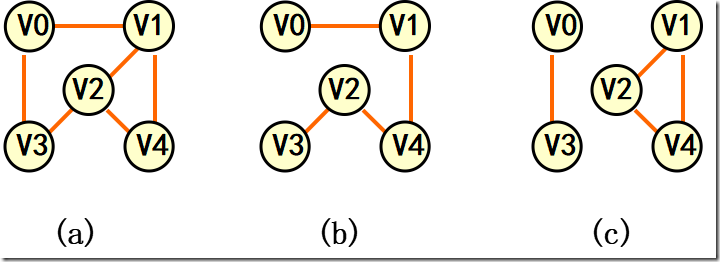
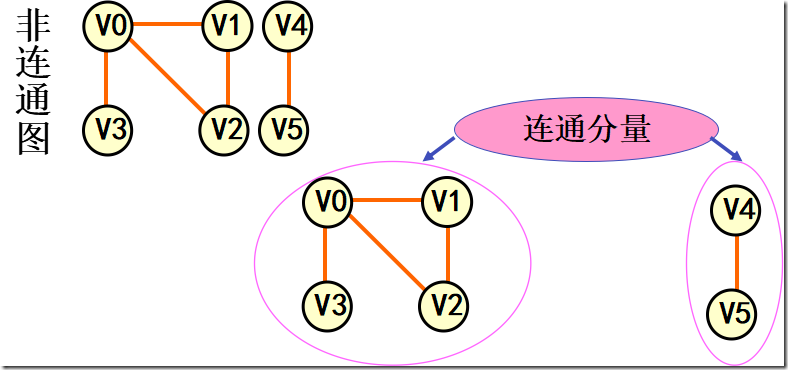
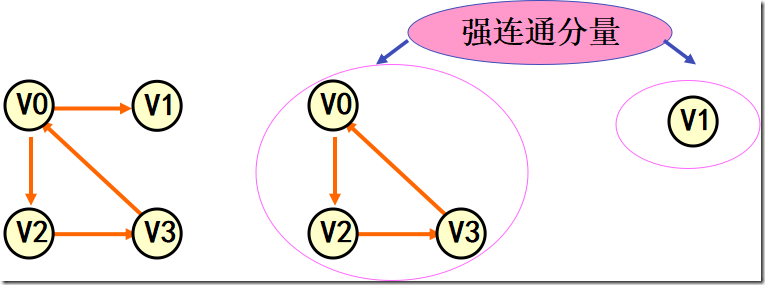
连通分量(强连通分量)
无向图G 的极大连通子图称为G的连通分量。 极大连通子图意思是:该子图是 G 连通子图,将G 的任何不在该子图中的顶点加入,子图不再连通。
有向图G 的极大强连通子图称为G的强连通分量。极大强连通子图意思是:该子图是G的强连通子图,将D的任何不在该子图中的顶点加入,子图不再是强连通的。
极小连通子图:该子图是G 的连通子图,在该子图中删除任何一条边,子图不再连通。 生成树:包含无向图G 所有顶点的极小连通子图。生成森林:对非连通图,由各个连通分量的生成树的集合。
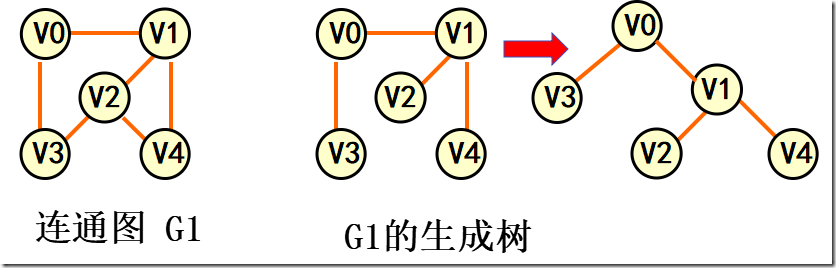
6.3 图的类型定义
CreateGraph(&G,V,VR)
初始条件:V是图的顶点集,VR是图中弧的集合。
操作结果:按V和VR的定义构造图G。
DFSTraverse(G)
初始条件:图G存在。
操作结果:对图进行深度优先遍历。
BFSTraverse(G)
初始条件:图G存在。
操作结果:对图进行广度优先遍历。
6.4 图的存储结构
数组(邻接矩阵)表示法
建立一个顶点表(记录各个顶点信息)和一个邻接矩阵(表示各个顶点之间关系)。
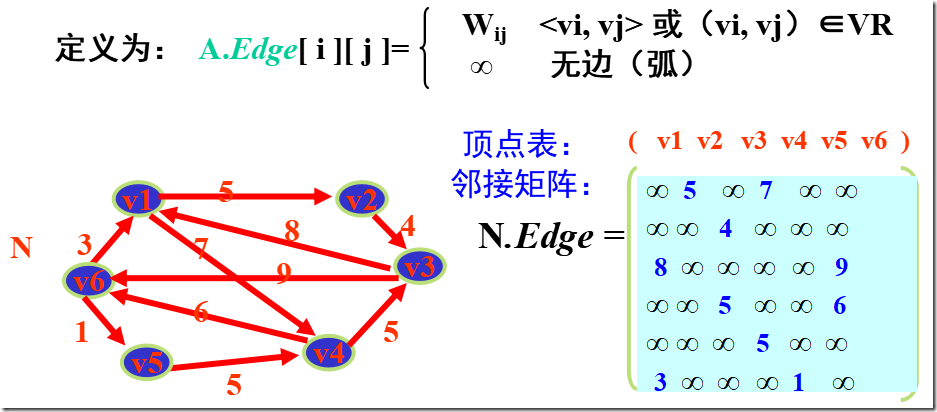
设图 A = (V, E) 有 n 个顶点,则图的邻接矩阵是一个二维数组 A.Edge[n][n],定义为:
无向图的邻接矩阵表示法

分析1:无向图的邻接矩阵是对称的;
分析2:顶点i 的度=第 i 行 (列) 中1 的个数;
特别:完全图的邻接矩阵中,对角元素为0,其余1。
有向图的邻接矩阵表示法

注:在有向图的邻接矩阵中,
第i行含义:以结点vi为尾的弧(即出度边);
第i列含义:以结点vi为头的弧(即入度边)。
分析1:有向图的邻接矩阵可能是不对称的。
分析2:顶点的出度=第i行元素之和
顶点的入度=第i列元素之和
顶点的度=第i行元素之和+第i列元素之和
网(即有权图)的邻接矩阵表示法
优点:容易实现图的操作,如:求某顶点的度、判断顶点之间是否有边、找顶点的邻接点等等。
缺点:n个顶点需要n*n个单元存储边;空间效率为O(n2)。 对稀疏图而言尤其浪费空间。
邻接矩阵的存储表示
//用两个数组分别存储顶点表和邻接矩阵
#define MaxInt 32767 //表示极大值,即∞
#define MVNum 100 //最大顶点数
typedef char VerTexType; //假设顶点的数据类型为字符型
typedef int ArcType; //假设边的权值类型为整型
typedef struct{
VerTexType vexs[MVNum]; //顶点表
ArcType arcs[MVNum][MVNum]; //邻接矩阵
int vexnum,arcnum; //图的当前点数和边数
}AMGraph;
采用邻接矩阵表示法创建无向网
(1)输入总顶点数和总边数。
(2)依次输入点的信息存入顶点表中。
(3)初始化邻接矩阵,使每个权值初始化为极大值。
(4)构造邻接矩阵。
Status CreateUDN(AMGraph &G){
//采用邻接矩阵表示法,创建无向网G
cin>>G.vexnum>>G.arcnum; //输入总顶点数,总边数
for(i = 0; i<G.vexnum; ++i)
cin>>G.vexs[i]; //依次输入点的信息
for(i = 0; i<G.vexnum;++i) //初始化邻接矩阵,边的权值均置为极大值
for(j = 0; j<G.vexnum;++j)
G.arcs[i][j] = MaxInt;
for(k = 0; k<G.arcnum;++k){ //构造邻接矩阵
cin>>v1>>v2>>w; //输入一条边依附的顶点及权值
i = LocateVex(G, v1); j = LocateVex(G, v2); //确定v1和v2在G中的位置
G.arcs[i][j] = w; //边<v1, v2>的权值置为w
G.arcs[j][i] = G.arcs[i][j]; //置<v1, v2>的对称边<v2, v1>的权值为w
}//for
return OK;
}//CreateUDN
int LocateVex(MGraph G,VertexType u)
{//存在则返回u在顶点表中的下标;否则返回-1
int i;
for(i=0;i<G.vexnum;++i)
if(u==G.vexs[i])
return i;
return -1;
}
邻接表(链式)表示法
对每个顶点vi 建立一个单链表,把与vi有关联的边的信息链接起来,每个结点设为3个域;
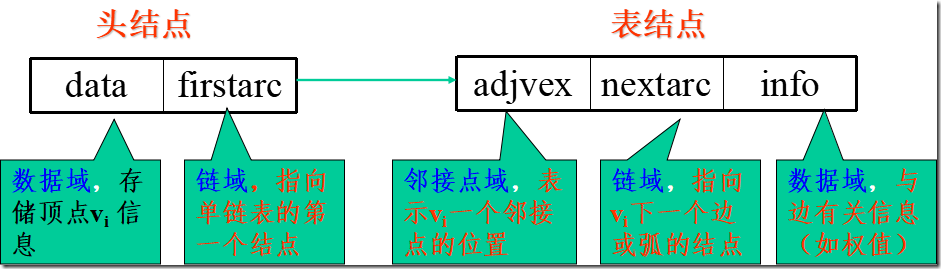
每个单链表有一个头结点(设为2个域),存vi信息;每个单链表的头结点另外用顺序存储结构存储。
无向图的邻接表表示
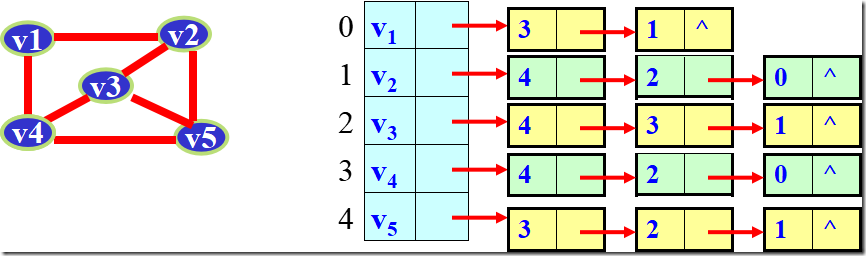
注:邻接表不唯一,因各个边结点的链入顺序是任意的
空间效率为O(n+2e)。
若是稀疏图(e<<n2),比邻接矩阵表示法O(n2)省空间。
TD(Vi)=单链表中链接的结点个数
有向图的邻接表表示
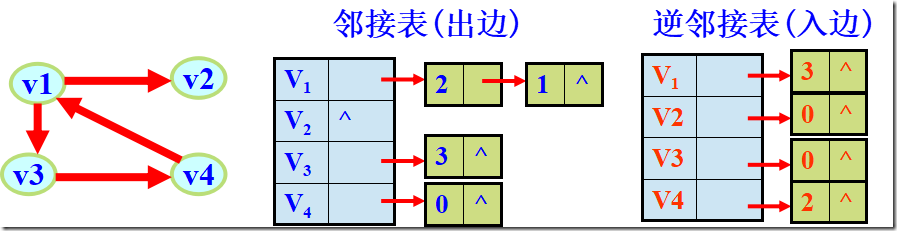
空间效率为O(n+e)

#define MVNum 100 //最大顶点数
typedef struct ArcNode{ //边结点
int adjvex; //该边所指向的顶点的位置
struct ArcNode * nextarc; //指向下一条边的指针
OtherInfo info; //和边相关的信息
}ArcNode;
typedef struct VNode{
VerTexType data; //顶点信息
ArcNode * firstarc; //指向第一条依附该顶点的边的指针
}VNode, AdjList[MVNum]; //AdjList表示邻接表类型
typedef struct{
AdjList vertices; //邻接表
int vexnum, arcnum; //图的当前顶点数和边数
}ALGraph;
采用邻接表表示法创建无向网
(1)输入总顶点数和总边数。
(2)依次输入点的信息存入顶点表中,使每个表头结点的指针域初始化为NULL。
(3)创建邻接表。
Status CreateUDG(ALGraph &G){
//采用邻接表表示法,创建无向图G
cin>>G.vexnum>>G.arcnum; //输入总顶点数,总边数
for(i = 0; i<G.vexnum; ++i){ //输入各点,构造表头结点表
cin>> G.vertices[i].data; //输入顶点值
G.vertices[i].firstarc=NULL; //初始化表头结点的指针域为NULL
}//for
for(k = 0; k<G.arcnum;++k){ //输入各边,构造邻接表
cin>>v1>>v2; //输入一条边依附的两个顶点
i = LocateVex(G, v1); j = LocateVex(G, v2);
p1=new ArcNode; //生成一个新的边结点*p1
p1->adjvex=j; //邻接点序号为j
p1->nextarc= G.vertices[i].firstarc; G.vertices[i].firstarc=p1;
//将新结点*p1插入顶点vi的边表头部
p2=new ArcNode; //生成另一个对称的新的边结点*p2
p2->adjvex=i; //邻接点序号为i
p2->nextarc= G.vertices[j].firstarc; G.vertices[j].firstarc=p2;
//将新结点*p2插入顶点vj的边表头部
}//for
return OK;
}//CreateUDG
优点:空间效率高,容易寻找顶点的邻接点;
缺点:判断两顶点间是否有边或弧,需搜索两结点对应的单链表,没有邻接矩阵方便。
邻接矩阵与邻接表表示法的关系
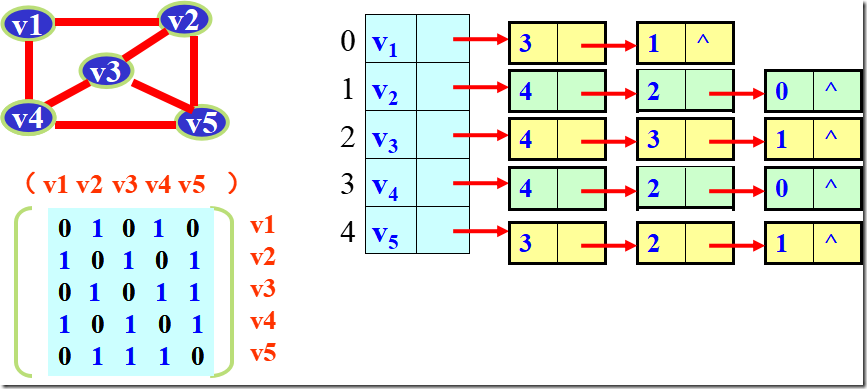
1. 联系:邻接表中每个链表对应于邻接矩阵中的一行,链表中结点个数等于一行中非零元素的个数。
2. 区别:
① 对于任一确定的无向图,邻接矩阵是唯一的(行列号与顶点编号一致),但邻接表不唯一(链接次序与顶点编号无关)。
② 邻接矩阵的空间复杂度为O(n2),而邻接表的空间复杂度为O(n+e)。
3. 用途:邻接矩阵多用于稠密图;而邻接表多用于稀疏图
十字链表---用于有向图

十字链表---用于无向图
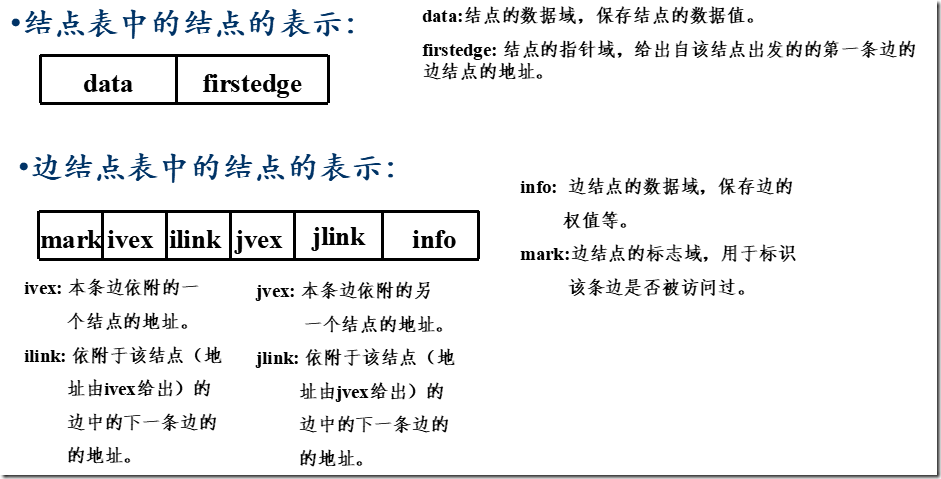
6.5 图的遍历
遍历定义:从已给的连通图中某一顶点出发,沿着一些边访遍图中所有的顶点,且使每个顶点仅被访问一次,就叫做图的遍历,它是图的基本运算。
遍历实质:找每个顶点的邻接点的过程。
图的特点:图中可能存在回路,且图的任一顶点都可能与其它顶点相通,在访问完某个顶点之后可能会沿着某些边又回到了曾经访问过的顶点。
怎样避免重复访问?
解决思路:设置辅助数组 visited [n ],用来标记每个被访问过的顶点。
初始状态为0
i 被访问,改 visited [i]为1,防止被多次访问
图常用的遍历:
深度优先搜索
广度优先搜索
深度优先搜索( DFS - Depth_First Search)
图G为邻接矩阵类型
void DFS(AMGraph G, int v){ //图G为邻接矩阵类型
cout<<v; visited[v] = true; //访问第v个顶点
for(w = 0; w< G.vexnum; w++) //依次检查邻接矩阵v所在的行
if((G.arcs[v][w]!=0)&& (!visited[w]))
DFS(G, w);
//w是v的邻接点,如果w未访问,则递归调用DFS
}
邻接表的DFS算法
void DFS(ALGraph G, int v){ //图G为邻接表类型
cout<<v; visited[v] = true; //访问第v个顶点
p= G.vertices[v].firstarc; //p指向v的边链表的第一个边结点
while(p!=NULL){ //边结点非空
w=p->adjvex; //表示w是v的邻接点
if(!visited[w]) DFS(G, w); //如果w未访问,则递归调用DFS
p=p->nextarc; //p指向下一个边结点
}
}
DFS算法效率分析
用邻接矩阵来表示图,遍历图中每一个顶点都要从头扫描该顶点所在行,时间复杂度为O(n2)。
用邻接表来表示图,虽然有 2e 个表结点,但只需扫描 e 个结点即可完成遍历,加上访问 n个头结点的时间,时间复杂度为O(n+e)。
结论:
稠密图适于在邻接矩阵上进行深度遍历;
稀疏图适于在邻接表上进行深度遍历。
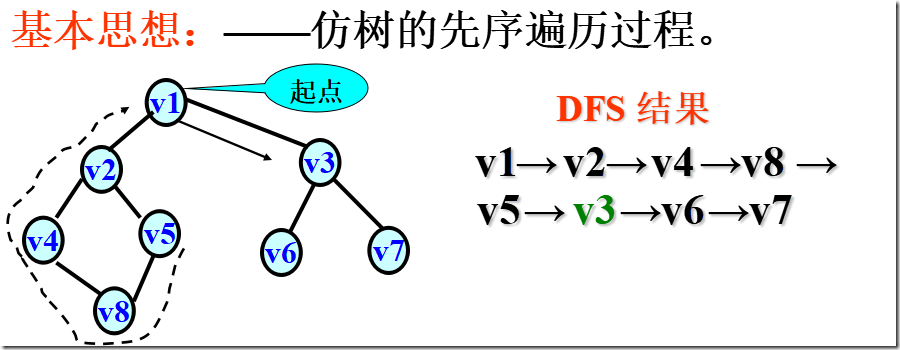
广度优先搜索( BFS - Breadth_First Search)
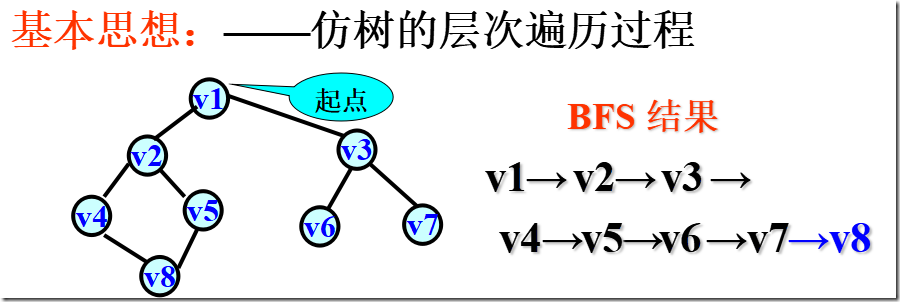
简单归纳:
在访问了起始点v之后,依次访问 v的邻接点;
然后再依次访问这些顶点中未被访问过的邻接点;
直到所有顶点都被访问过为止。
广度优先搜索是一种分层的搜索过程,每向前走一步可能访问一批顶点,不像深度优先搜索那样有回退的情况。
因此,广度优先搜索不是一个递归的过程,其算法也不是递归的。
【算法思想】
(1)从图中某个顶点v出发,访问v,并置visited[v]的值为true,然后将v进队。
(2)只要队列不空,则重复下述处理。
① 队头顶点u出队。
② 依次检查u的所有邻接点w,如果visited[w]的值为false,则访问w,并置visited[w]的值为true,然后将w进队。
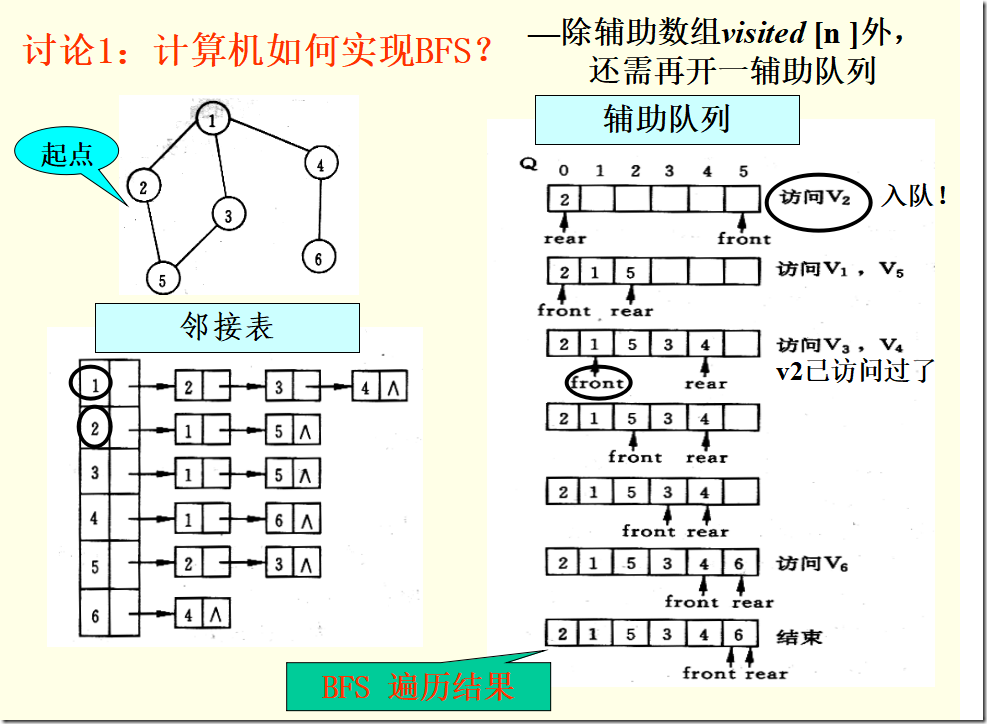
void BFS (Graph G, int v){
//按广度优先非递归遍历连通图G
cout<<v; visited[v] = true; //访问第v个顶点
InitQueue(Q); //辅助队列Q初始化,置空
EnQueue(Q, v); //v进队
while(!QueueEmpty(Q)){ //队列非空
DeQueue(Q, u); //队头元素出队并置为u
for(w = FirstAdjVex(G, u); w>=0; w = NextAdjVex(G, u, w))
if(!visited[w]){ //w为u的尚未访问的邻接顶点
cout<<w; visited[w] = true; EnQueue(Q, w); //w进队
}//if
}//while
}//BFS
BFS算法效率分析
如果使用邻接矩阵,则BFS对于每一个被访问到的顶点,都要循环检测矩阵中的整整一行( n 个元素),总的时间代价为O(n2)。
用邻接表来表示图,虽然有 2e 个表结点,但只需扫描 e 个结点即可完成遍历,加上访问 n个头结点的时间,时间复杂度为O(n+e)。
6.6 图的应用
最小生成树
最短路径
拓扑排序
关键路径
如何求最小生成树
Prim(普里姆)算法
Kruskal(克鲁斯卡尔)算法
Prim算法: 归并顶点,与边数无关,适于稠密网
Kruskal算法:归并边,适于稀疏网
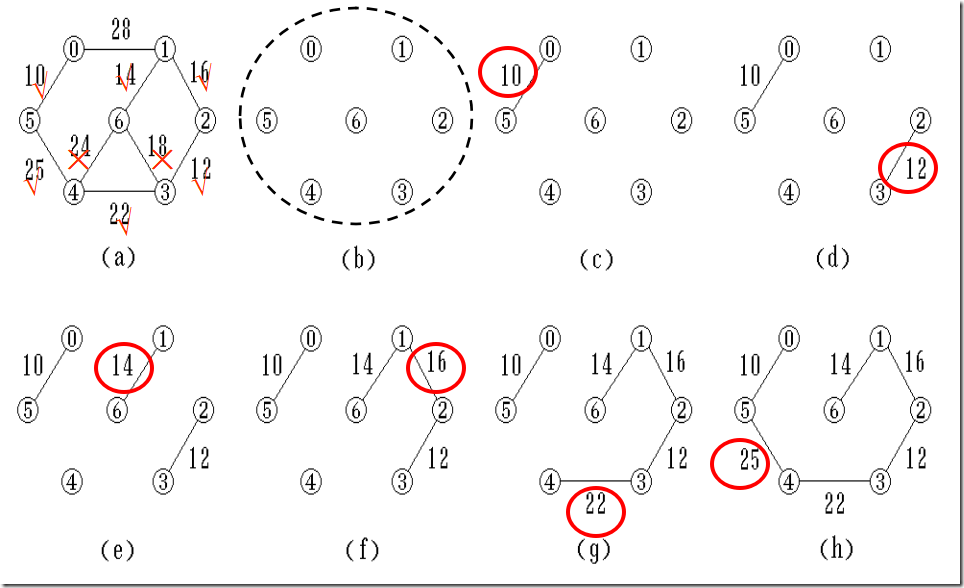
普里姆算法的基本思想--归并顶点
设连通网络 N = { V, E }
1. 从某顶点 u0 出发,选择与它关联的具有最小权值的边(u0, v),将其顶点加入到生成树的顶点集合U中
2. 每一步从一个顶点在U中,而另一个顶点不在U中的各条边中选择权值最小的边(u, v),把它的顶点加入到U中
3. 直到所有顶点都加入到生成树顶点集合U中为止
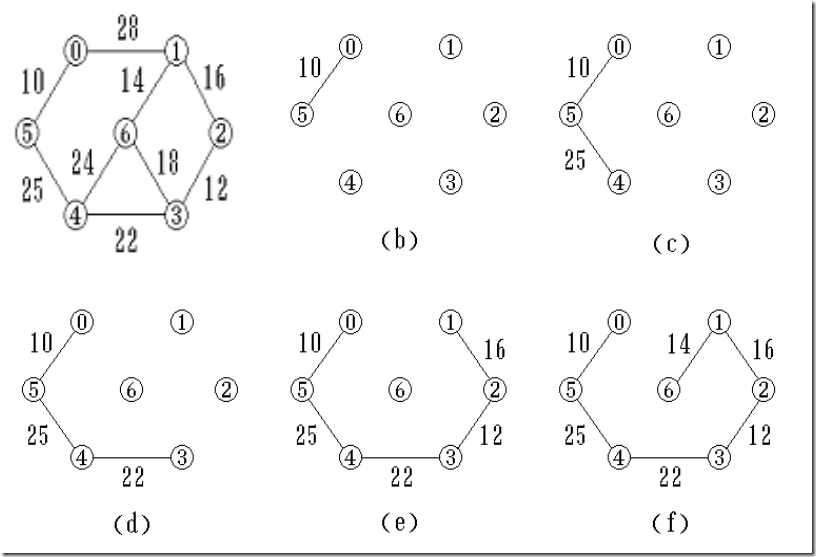
克鲁斯卡尔算法的基本思想-归并边
设连通网络 N = { V, E }
1. 构造一个只有 n 个顶点,没有边的非连通图 T = { V,空集 }, 每个顶点自成一个连通分量
2. 在 E 中选最小权值的边,若该边的两个顶点落在不同的连通分量上,则加入 T 中;否则舍去,重新选择
3. 重复下去,直到所有顶点在同一连通分量上为止
最短路径
典型用途:交通问题。如:城市A到城市B有多条线路,但每条线路的交通费(或所需时间)不同,那么,如何选择一条线路,使总费用(或总时间)最少?
问题抽象:在带权有向图中A点(源点)到达B点(终点)的多条路径中,寻找一条各边权值之和最小的路径,即最短路径。
(注:最短路径与最小生成树不同,路径上不一定包含n个顶点)
两种常见的最短路径问题:
一、 单源最短路径—用Dijkstra(迪杰斯特拉)算法
二、所有顶点间的最短路径—用Floyd(弗洛伊德)算法
Dijistra算法的改进—A*算法(静态环境)

Dijistra算法的改进—D*算法(动态环境)
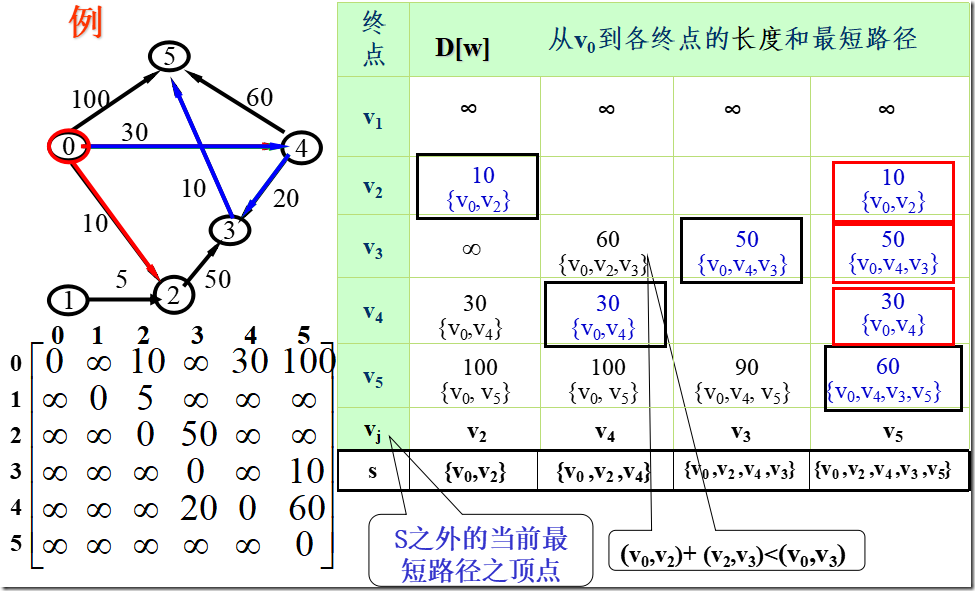
1.初始化:先找出从源点v0到各终点vk的直达路径(v0,vk),即通过一条弧到达的路径。
2.选择:从这些路径中找出一条长度最短的路径(v0,u)。
3.更新:然后对其余各条路径进行适当调整:
若在图中存在弧(u,vk),且(v0,u)+(u,vk)<(v0,vk),
则以路径(v0,u,vk)代替(v0,vk)。
在调整后的各条路径中,再找长度最短的路径,依此类推。
主:邻接矩阵G[n][n] (或者邻接表)
辅:
数组S[n]:记录相应顶点是否已被确定最短距离
数组D[n]:记录源点到相应顶点路径长度
数组Path[n]:记录相应顶点的前驱顶点
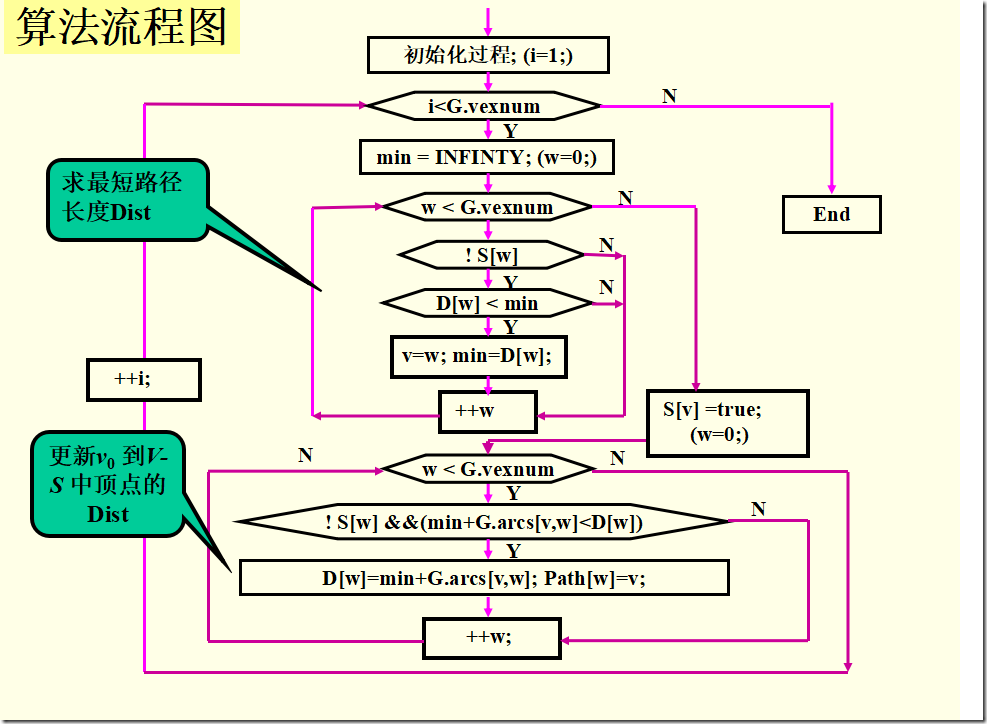
void ShortestPath_DIJ(AMGraph G, int v0){
//用Dijkstra算法求有向网G的v0顶点到其余顶点的最短路径
n=G.vexnum; //n为G中顶点的个数
for(v = 0; v<n; ++v){ //n个顶点依次初始化
S[v] = false; //S初始为空集
D[v] = G.arcs[v0][v]; //将v0到各个终点的最短路径长度初始化
if(D[v]< MaxInt) Path [v]=v0; //v0和v之间有弧,将v的前驱置为v0
else Path [v]=-1; //如果v0和v之间无弧,则将v的前驱置为-1
}//for
S[v0]=true; //将v0加入S
D[v0]=0; //源点到源点的距离为0
/*―开始主循环,每次求得v0到某个顶点v的最短路径,将v加到S集―*/
for(i=1;i<n; ++i){ //对其余n−1个顶点,依次进行计算
min= MaxInt;
for(w=0;w<n; ++w)
if(!S[w]&&D[w]<min)
{v=w; min=D[w];} //选择一条当前的最短路径,终点为v
S[v]=true; //将v加入S
for(w=0;w<n; ++w) //更新从v0出发到集合V−S上所有顶点的最短路径长度
if(!S[w]&&(D[v]+G.arcs[v][w]<D[w])){
D[w]=D[v]+G.arcs[v][w]; //更新D[w]
Path [w]=v; //更改w的前驱为v
}//if
}//for
}//ShortestPath_DIJ
数据结构(C语言版)-第6章 图的更多相关文章
- c++学习书籍推荐《清华大学计算机系列教材:数据结构(C++语言版)(第3版)》下载
百度云及其他网盘下载地址:点我 编辑推荐 <清华大学计算机系列教材:数据结构(C++语言版)(第3版)>习题解析涵盖验证型.拓展型.反思型.实践型和研究型习题,总计290余道大题.525道 ...
- 数据结构C语言版 有向图的十字链表存储表示和实现
/*1wangxiaobo@163.com 数据结构C语言版 有向图的十字链表存储表示和实现 P165 编译环境:Dev-C++ 4.9.9.2 */ #include <stdio.h> ...
- 数据结构C语言版 弗洛伊德算法实现
/* 数据结构C语言版 弗洛伊德算法 P191 编译环境:Dev-C++ 4.9.9.2 */ #include <stdio.h>#include <limits.h> # ...
- 《数据结构-C语言版》(严蔚敏,吴伟民版)课本源码+习题集解析使用说明
<数据结构-C语言版>(严蔚敏,吴伟民版)课本源码+习题集解析使用说明 先附上文档归类目录: 课本源码合辑 链接☛☛☛ <数据结构>课本源码合辑 习题集全解析 链接☛☛☛ ...
- 数据结构C语言版 表插入排序 静态表
数据结构C语言版 表插入排序.txt两个人吵架,先说对不起的人,并不是认输了,并不是原谅了.他只是比对方更珍惜这份感情./* 数据结构C语言版 表插入排序 算法10.3 P267-P270 编译 ...
- 数据结构(c语言版)文摘
第一章 绪论 数据结构:是一门研究非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作等的学科. 数据:是对客观事物的符号表示,在计算机科学中是指所有能输入到计算机中并被计算机程序处理 ...
- 【数据结构(C语言版)系列二】 栈
栈和队列是两种重要的线性结构.从数据结构角度看,栈和队列也是线性表,但它们是操作受限的线性表,因此,可称为限定性的数据结构.但从数据类型角度看,它们是和线性表大不相同的两类重要的抽象数据类型. 栈的定 ...
- 【数据结构(C语言版)系列三】 队列
队列的定义 队列是一种先进先出的线性表,它只允许在表的一端进行插入,而在另一端删除元素.这和我们日常生活中的排队是一致的,最早进入队列的元素最早离开.在队列中,允许插入的一端叫做队尾(rear),允许 ...
- 数据结构( Pyhon 语言描述 ) — — 第5章:接口、实现和多态
接口 接口是软件资源用户可用的一组操作 接口中的内容是函数头和方法头,以及它们的文档 设计良好的软件系统会将接口与其实现分隔开来 多态 多态是在两个或多个类的实现中使用相同的运算符号.函数名或方法.多 ...
- 深入浅出数据结构C语言版(5)——链表的操作
上一次我们从什么是表一直讲到了链表该怎么实现的想法上:http://www.cnblogs.com/mm93/p/6574912.html 而这一次我们就要实现所说的承诺,即实现链表应有的操作(至于游 ...
随机推荐
- Unity3D之主菜单
1.新建一个名为MainMenu的C#脚本,修改编码后拖动到主摄像机,并给主摄像机添加一个AudioSource声音源作为背景音乐.将音乐文件赋值给Audio Clip属性. 2.创建一个Common ...
- 复选框批量删除操作-jquery方式
1.首先在页面添加一个批量删除的按钮:<li class="btns"><input id="deleteSubmit" class=&quo ...
- [c/c++] programming之路(8)、汇编、求模、自增自减
一.插入汇编 #include<stdio.h> void main(){ ; num=num+; //插入汇编语言 _asm{ mov eax,num;//eax是一个存储器,将num的 ...
- Codeforces 765F Souvenirs - 莫队算法 - 链表 - 线段树
题目传送门 神速的列车 光速的列车 声速的列车 题目大意 给定一个长度为$n$的序列,$m$次询问区间$[l, r]$内相差最小的两个数的差的绝对值. Solution 1 Mo's Algorith ...
- Qt Quick Dialogs
一.如下图.. 二. 1.FileDialog //定义FileDialog{ id:fileDialog; title: "open a picture"; nameFilter ...
- topcoder srm 697 div1 -3
1.给定长度为$n$ 的数组$b$,构造长度为$n$ 的且没有重复元素的数组$a$,令$p_{i}$表示$a$中除$a_{i}$外其他元素的乘积.构造出的$a$满足$a_{i}^{b_{i}}$能够被 ...
- reshape2
require(reshape2)x = data.frame(subject = c("John", "Mary"), tim ...
- HDU 6096 String(AC自动机+树状数组)
题意 给定 \(n\) 个单词,\(q\) 个询问,每个询问包含两个串 \(s_1,s_2\),询问有多少个单词以 \(s_1\) 为前缀, \(s_2\) 为后缀,前后缀不能重叠. \(1 \leq ...
- Hadoop【单机安装-测试程序WordCount】
Hadoop程序说明,就是创建一个文本文件,然后统计这个文本文件中单词出现过多少次! (MapReduce 运行在本地 启动JVM ) 第一步 创建需要的文件目录,然后进入该文件中进行编辑 ...
- Shell中的IFS
一.IFS 介绍 Shell 脚本中有个变量叫 IFS(Internal Field Seprator) ,内部域分隔符.完整定义是The shell uses the value stored in ...