(0)diango、ORM的语法
Django
django迁移命令:
生成迁移命令:python manage.py makemigrations
执行迁移命令:python manage.py migrate
PS:Django默认的是sqlite3数据库
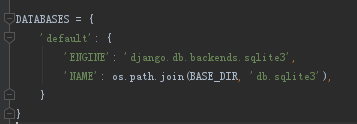
PS:settings里面的这里可以修改数据库
1、^ 这个符号就是以什么开头 #url(r'index/',views.index)就是以i开头做正则匹配
2、render #向浏览器返回页面
3、HttpResponse #向浏览器返回字符内容
4、redirect #重定向
5、urls.py #就是路由层
6、views.py #就是视图层
7、templates.py #就是模板层
8、modles.py #就是模型层,就是ORM语法写东西的地方
9、url(r'index/',views.index) #路由,执行函数的对应关系,这个是固定写法,第一个r后面跟的是一个路径,后面跟导入的函数
10、?P<这里写名字> #有名分组 url(r'^index/(?P<num>\d+)/(?P<num1>\d+)',views.index)
11、url(r'^index/(\d+)',views.index) #无名分组,index/可以传任意的数字,括号的用意就是将后面传入的数字进行分组,如果不加括号则不会分组
12、url(r'^index/(\d+)/(\d+)',views.index) # 无名分组-多分组
13、路由控制下:url(r'正则表达式',函数内存地址,name='别名',{'name':'name'}) #别名就是用来做反向解析的,{'name':'name'}就是python的函数,用来提供功能和取值的
14、名称空间的概念:在反向解析的时候可能会导致项目中有相同的别名,这时候如果从别名去反向解析则会出bug,项目中使用app名/别名来反向解析
15、视图层下request对象 #发过来的所有数据都在这个request对象里
16、文件上传request.FIELS
17、过滤器 { 数字或字符 | add:数字或字符} # 在模板中做加减法,如果是字符就是拼接
18、{{ 变量名 }} #在页面中打印变量的值
19、{% %} #这种方式是用来做if判断和for循环的
20、 如果循环的对象是空的,则会打印empty,如果有值则会打印列表的值
21、使用forloop.counter获取循环的次数 #可以模拟出浏览的几楼
22、parentloop #就是外层的对象,后面counter就是上层循环的第几次循环,这里循环和python的for循环嵌套原理同理
23、forloop.revcounter0 #通过for循环倒过来索引且最后一位索引序号为0
24、forloop.revcounter #通过for循环倒过来索引
25、forloop.counter0 #通过for循环从0开始索引的第二种写法
26、forloop.counter | add:-1 #通过for循环从0开始索引第一种写法
27、forloop.counter #forloop只在for循环内部使用,是一个对象,counter就是用来取索引值的
28、{{ dic.hobby.1 }} # dic = {'hobby':['p','sl']} 取出变量dic的对应key名中的索引位置为1的值
29、locals() #会把该函数中所有的变量,构造成字典传到模板中
30、slice #内置过滤器,用来做字符串切片操作 name='aaabbbccc' ,在模板中{{ name |slice:'1:4' }},就是从传入的字符串中从索引1到4的位置的参数
31、add(在模板中实现加减法) #这是过滤器,用在模板中的
32、default(就是当传入的变量是False的时候显示后面设定的字符,如果是True的时候就是显示True) #这是过滤器,用在模板中的
33、length(计算变量的长度) #这是过滤器,用在模板中的
34、filesizeformat*(将变量的值根据长度自动进行一个单位换算,不同长度显示不同的单位,kb\mb\tb) #这是过滤器,用在模板中的
35、date(将python中的时间对象变成自己设定的类型在页面中显示,date后面格式一定是一个字符串形式)、safe(就是将视图中的变量值原封不动的在页面中显示) #这是过滤器,用在模板中的
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
ORM就是django中modles文件内写的东西
ORM:ORM不能创建数据库,只能创建表、删除表、新增字段、删除字段
1、id = models.AutoField(primary_key=True) # 这个固定写法,创建表中的id字段int类型,且自增,primary_key=True就是主键
2、name = models.CharField(max_length=32,null=True,default='qqq') # 创建表中的name字段,类型CharField就是等于varchar,max_length就是最大的字段长度,null就是字段可以为空,default就是添加一个默认字段
3、age = models.IntegerField() #IntegerField数字类型,无法显示小数点
4、price = models.DecimalField(max_digits=5,decimal_places=2) # 价格类型的尽量用DexcimalFiled类型,这个是可以表示小数点后的数字,decimal_places表示小数点后几位数
5、publish_date = models.DateField() #这个是时间日期类型,DatetimeField表示年月日 时分秒,DateField就是年月日
6、email = models.EmailField() #EmailField 类型对应的就是varchar类型,并没有限制
---python3 manage.py makemigrations 数据表变化的记录 #在models里写好语句要新增表,就要执行3和4这两条命令
---python3 manage.py migrate 同步数据记录
PS:3和4的步骤可以在pycharm中的菜单Tools下的Run manage.py运行后输入makemigrations 和 migrate直接运行
PS:要删除相关的字段直接注释掉,然后同步即可
PS:要删除表只要把整个类注释,然后同步即可
ORM对mysql表操作
单表操作
增
1、id = models.AutoField(primary_key=True) #这个固定写法,创建表中的id字典int类型,且自增,primary_key=True就是主键
2、name = models.CharField(max_length=32) #创建表中的name字段,类型CharField就是等于varchar,括号里的参数就是定义最长的长度
3、pwd = models.CharField(max_length=32,null=True) # 创建表中的pwd字典,类型CharField就等于varchar,括号里的参数就是最大的长度,null=true就表示可以为空
4、addr = models.CharField(max_length=64) # 增加字段直接在这里写要增加的字段
5、yy = models.CharField(max_length=64,null=True) # 在增加字段,后面值可以为空,则不会要求输入默认的字段,直接成功创建
6、z = models.CharField(max_length=64,null=True,default='qqq') # 括号里的参数default就是设定默认值,创建后自动传入设定的默认值
7、user = models.User.objects.create(name=name,pwd=pwd) # 中间的User就是表的名字,这种是常用的写法,只需要一条命令即可
查
ret = models.User.objects.filter(name=name).values() # 这个就是查询语句,filter是过滤,用get会报错后面.可以有很多功能first、values等
删---有两种方式
第一种
ret = models.User.objects.filter(id=1).delete() #这里就是查询id=1的数据,delete方法就是直接删除查询到的所有数据
ret = models.User.objects.filter(name='lqz').delete() #这样写就是把查询出来的所有名字为lqz的数据全部删除了
第二种方式,通过对象删除
user = models.User.objects.filter(id=2).first #first就是把查询到的第一个拿出来 # user就是一个对象
print(user.name) #获取用户名
print(user.pwd) #获取密码
user.delete() #删除这个对象
改--有两种方式
第一种方式
ret=models.User.objects.filter(id=3).update(name='xxx') # 修改id=3的人的名字为xxx
PS:update把查到的所有数据都更新
PS:有一个返回值,就是影响的行数,所以这里的ret就是一个数字
第二种方式,通过对象去修改
ret=models.User.objects.filter(id=3).first()
ret.name='xxx'
ret.save()
queryset对象的方法
all #结果拿到的是所有的数据
ret=models.User.objects.all() #这里的返回结果就是queryset对象
filter(**kwargs) #可以传多个值
ret=models.User.objects.filter(id=3,pwd='333') #filter这种形式id=3,pwd='333'是and条件
ret = models.User.objects.filter(**{'id':3,'pwd':'333'}) #以字典形式传的时候需要在前面加**
get(**kwargs) #和filter一样传多值
ret=models.User.objects.get(id=3) #返回值是user对象,如果是book对象,返回值就是book对象
exclude(**kwargs) #和filter一样传多值 、过滤查询的对象,除输入的条件外其他所有不匹配的数据全部查询出来
ret=models.User.objects.exclude(id=3)
order_by(*field) #将查询出来的结果根据要求进行排序,查询的值支持多个值
ret=models.User.objects.all().order_by('name') #这个是正向排序
ret=models.User.objects.all().order_by('-name') #条件前加一个 - 这个是反向排序
PS:并不是只能用在all后面,可以用在其他的查询方法后
count(): #返回数据库中匹配查询(QuerySet)的对象数量
ret=models.User.objects.filter(name='lqz').first().count()
first() # 返回第一条记录
last() # 返回最后一条记录
exists() #如果QuerySet包含数据,就返回True,否则返回
ret=models.User.objects.filter(id=10).exists()
values(*field): #返回一个ValueQuerySet,一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列
ret=models.User.objects.all().values('name') # 返回的是特殊的QuerySet对象,QuerySet[{'name':'xxxxxx',}]
ret = models.User.objects.all().values('name','pwd').first() #这个返回结果就是特殊对象的索引第一个位置的值,就是结果中的第一个值
ret = models.User.objects.all().values('name', 'pwd') #返回的是一个可迭代的字典序列 <QuerySet [{'name':'xxxx','pwd','9999},{'name':'lqz','pwd':'4456'}]>
values_list(*field) # 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
ret = models.User.objects.all().values_list('name','pwd') #这个返回结果就是一个元组 <QuerySet [('xxxxx','999),('lqz','3333')]>
distinct() #从返回结果中剔除重复纪录
ret=models.User.objects.filter(name='lqz').distinct()
ret = models.User.objects.filter(name='lqz').values('name').distinct() #后面values的值是去重的条件
模糊查询 __ 双下划线
ret=models.User.objects.filter(id__in=[4,5]) #查询id是4和5的数据
ret = models.User.objects.filter(id__range=[1,9]) #查询id是1-9 的数据
'''gt是大于、lt是 小于、大于等于gte、小于等于lte'''
ret = models.User.objects.filter(id__ge=2) #gt是大于,gte是大于等于
ret = models.User.objects.filter(name__startswith='l') #name以l为开头,就是指定的键查询以什么开头的
ret = models.User.objects.filter(name__contains='q') #name只要包含q的都查询出来
ret = models.User.objects.filter(name__icontains='q') #name只要包含q并且忽略大小写的都查询出来
建表对应关系
author_detail = models.OneToOneField(to='AuthorDetail',to_field='id') #这里表示Author表和AuthorDetail表示一对一的关系,并且关联的字段是id字段,语句里面to表示对应的表,to_field对应的是哪个字段
publish = models.ForeignKey(to='Publish') #一对多的关系外键创立,如果不指定关联的键to_field,默认关联主键
authors = models.ManyToManyField(to='Author') #多对多的关系,写这一句ORM会自动创建第三张表
多表的新增
多表的新增就是一对一的新增 有两种方式
# 第一种方式
'''增加数据一定要注意表的先后顺序,如果字段设置看null=True,即可以为空,就不用注意先后的顺序'''
author_detail = models.AuthorDetail.objects.create(addr = '南京',phone='1234567890')
# author_detail_id 就是表的一个字段 author_detail.id 就是author_detail表的主键字段
author_ = models.AuthorDetail.objects.create(name='lqz2',age=19,author_detail_id=author_detail.id) #最后的author_detail.id也可以协程author_detail.pk,一样的 #第二种方式
# author_detail = 对象
author_detail = models.AuthorDetail.objects.create(addr='东京',phone='1234567890')
# 最后面关联的字段是一个对象,底层就是去对象中把主键取得,然后对应给author_detail
author = models.Author.objects.create(name='lqz2',age=19,author_detail=author_detail) # 多表的修改,就是在操作第三张表 # 对应关系的修改
'''将Author的关联字段中主键是1的修改成author_deatil表中的主键为3的值'''
author = models.Author.objects.filter(pk=1).update(author_detail_id=3) # 用对象修改,对象已经获取了对象的主键,然后将对象直接给author_detai表进行修改
author_detail = models.AuthorDetail.objects.get(pk=3)
author = models.Author.objects.filter(pk=1).update(author_detai=author_detail) '''一对多关系的新增两种方式'''
publish = models.Publish.objects.create(name='南京出版社',email='ddddd',phone='1234567890',addr='南京')
# 这里后面publish=publish,获取对象的主键放入变量,然后增加到对应表的关联列
book = models.Book.objects.create(name='红楼梦',price=12.34,publish_date='2018-07-08',publish=publish)
# 这种写法就是直接定义Book表的 publish_id关联 publish表的主键
book = models.Book.objects.create(name='红楼梦', price=12.34, publish_date='2018-07-08', publish_id=publish.pk) '''多对多的关系的修改'''
# 增加
'''要添加肯定要先查询,所里这里先查询'''
book = models.Book.objects.filter(name='红楼梦').first() #这里需求是给红楼梦的书增加两个作者
# 这样写相当于拿到第三张表,然后将book对象中的红楼梦的id对应上关联表author表中的键值,键值就是add括号里指定的放入第三张表
book.authors.add(1,4) #add内可以传对象,可以传id # 通过对象增加
lqz = models.Author.objects.get(pk=1)
egon = models.Author.objects.get(pk=4)
book.authors.add(lqz,egon) # 删除红楼梦这本书的两个作者
book.authors.clear() #clear 把所有作者删除
book.authors.remove() #传几个参数移除几个,remove里面可以传id也可以穿对象 # 修改 # 修改红楼梦的作者
# 第一种方式:全部删除clear,然后再add进去
# 第二种方式:用set修改,底层原理就是把7拿出来后删除全部的,然后再把关联的id=7的放进去
book.authors.set([7,]) #这里可以传id也可以传对象
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
django2.0 path转化器
Django默认支持以下5个转化器:
- str,匹配除了路径分隔符(
/)之外的非空字符串,这是默认的形式 - int,匹配正整数,包含0。
- slug,匹配字母、数字以及横杠、下划线组成的字符串。
- uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
- path,匹配任何非空字符串,包含了路径分隔符
注册自定义转化器
对于一些复杂或者复用的需要,可以定义自己的转化器。转化器是一个类或接口,它的要求有三点:
regex类属性,字符串类型to_python(self, value)方法,value是由类属性regex所匹配到的字符串,返回具体的Python变量值,以供Django传递到对应的视图函数中。to_url(self, value)方法,和to_python相反,value是一个具体的Python变量值,返回其字符串,通常用于url反向引用。
django 的组件
forms组件 # 做数据校验
cookie和session组件 # cookie就是 存在浏览器上的键值对,session就是存在服务器端的键值对
中间块组件 #请求的拦截,识别等一些功能
Auth模块 #快速做认证
ContentType组件 #表关联
forloop 对象
views中传入一个列表li = [1,2,3],在index文件中用for打印forloop对象
{'parentloop': {}, 'counter0': 0, 'counter': 1, 'revcounter': 3, 'revcounter0': 2, 'first': True, 'last': False}
{'parentloop': {}, 'counter0': 1, 'counter': 2, 'revcounter': 2, 'revcounter0': 1, 'first': False, 'last': False}
{'parentloop': {}, 'counter0': 2, 'counter': 3, 'revcounter': 1, 'revcounter0': 0, 'first': False, 'last': True}
PS:可以看到counter0就是从0开始索引,所以后面的参数就是0开始顺序,counter就是从1开始,所以后面的值就是1,revcounter就是根据列表有多少位,就是从最后开始向前,revcounter0倒过来排序到0,所以后面的值最后一个额就是0,first就是是否是第一个循环,如果是第一个就是Ture,last就是是否是最后一个循环
PS:parentloop就是外层循环的forloop对象
(0)diango、ORM的语法的更多相关文章
- C#7.0新特性和语法糖详解
转自IT之家网--DotNet码农:https://www.ithome.com/html/win10/305148.htm 伴随Visual Studio 2017的发布,C#7.0开始正式走上工作 ...
- Qt 5.0+ 中 connect 新语法与重载函数不兼容问题的解决方法,以及个人看法
Qt 5.0+ 版本提供了 connect 的新语法,相比之前的语法新语法可以提供编译期检查,使用也更方便.可是使用过程中发现一个小问题——当某个 signal 和成员函数是重载关系的时候,qmake ...
- php ci 2.0框架 ORM
很早知道ci出了2.0版本了.这几天正好有项目要用ci开发 虽然项目不大.不过也从开发项目的过程中熟悉了CI框架 因为是个电商项目 本来想用个YII2 的. 封装的虽然厉害不过功能强大 因为另个兄弟坚 ...
- vue 2.0 无法编译ES6语法
# vue2.0 webpack 无法编译 ES6 语法 之前在使用 vue 1.x 时用 vue-loader@8.0.0 版本可以正常打包vue的代码,包括ES6语法也能正常转为ES5语法,但是当 ...
- 大神博客链接系列---C#SubSonic3.0搭建ORM
一.C#框架 C#ORM框架: SubSonic3.0制作ORM--- http://www.cnblogs.com/EmptyFS/p/3659679.html
- Vue2.0中v-for迭代语法变化(key、index)【转】
转自:http://blog.csdn.net/sinat_35512245/article/details/53966788 Vue2.0的代码中发现 $key这个值并不能渲染成功,问题如下:但是v ...
- WAP 2.0开发XHTML MP语法及常用功能
XHTML Mobile Profile 的基本结构 <?xml version="1.0" encoding="utf-8"?> <!DOC ...
- Vue2.0中v-for迭代语法变化(key、index)
语法发生了变化:http://blog.csdn.net/sinat_35512245/article/details/53966788 新数组语法 value in arr (value, inde ...
- 发布并开源自己的一款 基于.Net 4.0 及 netstandard2.0 的 ORM 框架
这款ORM框架的原版在经历过大概十几个项目的磨合,最近整理了一下,原名字为:ZhCun.Framework ,该框架辗转跟了我去过几家公司,大概从2012年出现第一个版本,当时就为简化数据库操作,从优 ...
随机推荐
- nyoj-0613-免费馅饼(dp)
nyoj-0613-免费馅饼 G. 免费馅饼 都说天上不会掉馅饼,但有一天gameboy正走在回家的小径上,忽然天上掉下大把大把的馅饼.说来gameboy的人品实在是太好了,这馅饼别处都不掉,就掉落在 ...
- H5 PWA技术以及小demo
H5 PWA技术 1.原生app优缺点 a.体验好.下载到手机上入口方便 b.开发成本高(ios和安卓) c.软件上线需要审核 d.版本更新需要将新版本上传到不同的应用商店 e.使用前需下载 2.we ...
- R语言常用操作
1 取整运算 在编程实现的时候有时会碰到对数值取整的需求,而取整的方式却多种多样,依赖于具体问题,不过在R中已经配备了种类齐全的相关函数,主要包括以下五种: floor():向下取整: ceiling ...
- js数组及常用数学方法
数组方法 清空数组 1: arr.length=0; 2: arr=[]; arr.push() //往数组最后一个添加元素,会待会一个返回值,就是新的数组长度arr.uns ...
- BootStrap字体图标不显示、下拉菜单不显示
在W3CSchool学习BootStrap教程时遇到的问题…… 1.字体图标不能显示 上面是正常显示的样子,不能正常显示,因为缺少下面的字体图标样式文件 (1)在下载的Bootstrap包中将font ...
- :单件模式:Singleton
#ifndef __SINGLETON_H__ #define __SINGLETON_H__ class Singleton { private: static Singleton* instanc ...
- delete和delete[] 区别
// DeleteAndDelete[].cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <Windows.h> ...
- Java进程和线程
进程是资源分配和任务调度的基本单位, 进程就是包含上下文切换的程序执行时间总和=CPU加载上下文环境+CPU执行+CPU保存上下文环境,可以理解为时间片段: 进程的颗粒度太大了,将进程分块,按照a,c ...
- vue-router + ElementUI实现NavMenu 导航菜单 选中状态的切换
elemen-ui官方网站:http://element.eleme.io/#/zh-CN/component/menu 新手小白利用vue+element-ui尝试搭建后台管理系统, 效果是这样的, ...
- 16位GUID
当我们想要获得一个唯一的key的时候,通常会想到GUID.这个key非常的长,虽然我们在很多情况下这并不是个问题. 但是当我们需要将这个36个字符的字符串放在URL中时,会使的URL非常的丑陋. 想要 ...