微软BI 之SSAS 系列 - 维度的优化,灌木丛属性关系,以及自然层次结构与非自然层次结构的概念
维度的优化
- 确认属性关系
- 有效的使用用户自定义的层次结构
定义属性关系
属性关系定义了属性之间的依赖关系,比如如果 A 有一个关联的属性 B, 那么就是 A -> B。比如,一个给定的属性关系 City -> State, 如果当前的城市是 Seattle, 那么我们一定知道 State 一定是 Washington. 通常情况下,属性之间的关系可能在原始维度表中有可能比较明显,也有可能不是很明显,但是还是可以利用起来做性能优化。比如默认情况下,所有的属性都是关联到 Key 的,这个时候的属性关系表现的就是被称之为 "Bush Attribute Relationship" - 可以理解为浓密的,比较粗野灌木丛状的这种关联关系。在这种 Bush Attribute Relationship 关系中,所有的树干都是从 Key 关键属性展开,但都同时都已自身属性结束,这就是 "灌木丛属性关系"。
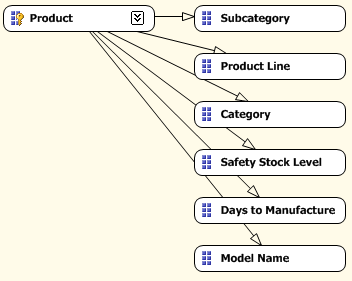
那么我们可以基于数据之间本身自有的逻辑关联来重新定义属性之间的关系以优化性能。在这种情况下,如下图所示 Model Name 定义了 Product Line 和 Subcategory (即知道了是哪一种 Model 那么就一定知道它是属于哪一个 Product Line 和 Subcategory), 而 Subcategory 定义确定了 Category (即知道它是哪一种 Subcategory 那么就一定能确定它是属于哪一种 Category; 或者理解为,这个 Subcategory 只会在一个 Category 中出现,不会同时出现在两个 Category 中)。像这种属性关系的定义一般都是多对一,或者 一对一的关联关系 -
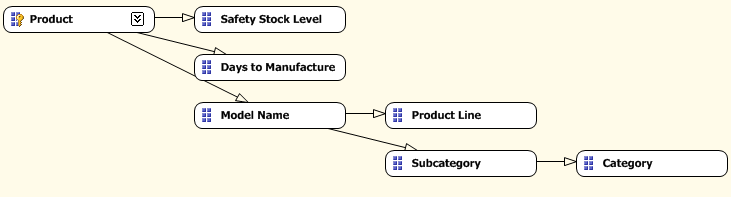
属性之间的关系设计可以从两个方面提升性能:
- 索引的构建和跨属性查询不需要都依赖于关键属性 Key Attribute。
- 在属性上的聚合能够在查询中和相关的属性中重用。
可以对比上面的两幅图,比如需要获取 Subcategory 和 Category 这两个属性,包括最后做一些聚合等操作。在第一个属性关系中,在 Subcategory 和 Category 之间并没有一个显示的关系定义,查询引擎必须首先要查询到哪一个产品是属于哪一个 Subcategory,然后再确定这个产品 Product 是属于哪一个 Category,最后才能确定 Subcategory 和 Category 之间的关联关系。BIWORK 在这里开个玩笑,比如张三这条记录,记录中有一个爸爸叫李四,还有一个爷爷叫王五 (当然张三,李四和王五背后的 KEY 肯定是可以唯一的),要搞清楚李四和王五之间的关系,或者如何通过李四找到李四的爸爸,就必须首先通过李四找到他的儿子张三,然后通过张三找到他的爷爷王五,这样就知道王五是李四的爸爸了。

如果是通过这样的一种方式来确定属性之间的关系,比如说通常在 Office Excel 中通过一个层次结构去聚合和查看数据,如果这个维度比较大的话,那么这种查找关联与确定下上层次之间的关联关系的过程会非常消耗时间。相反,如果能够重新定义属性之间的这种关联关系,那么在 PROCESS 处理阶段内部索引被构建,并且索引信息中维护了他们之间的关系,因此分析服务很容易就知道哪些 Category 被哪些 Subcategory 所关联,这样效率会得到极大的提升。
同时在考虑定义属性关系的时候,也要考虑属性之间的关系是 Flexible (可变的) 还是 Rigid (固定的), 默认是 Flexible 的。
Flexible 是指在维度更新的时候,属性之间的关系是可变的。比如 BIWORK 我之前在上海工作,现在到了北京,因此 Customer -> City 这种关系就是可变的。并且,在维度增量更新的时候,之前的聚合会被删除掉然后重新计算。但是如果仅仅是新成员的增加,就不会删除已有的聚合。
Rigid 是指维度更新的时候,属性之间的关系也不改变,或者说也承诺不改变。如果发生改变了,那么在增量 Processing 处理的过程中就会发生错误。比如 Month -> Year 这种关系就是 Rigid 固定的。
但是要注意,属性关系无论是定义成 Flexible 还是 Rigid 对查询性能都没有什么影响,只是一种手段。这种设计只是确保比如 Rigid 确实要做到两个属性关系是不可变的,应该跟我们预先设计保持一致。如果出现错误,说明某些数据的改变打破了我们预先的设计,应该引起我们的注意。
有效的使用层次结构
属性如果仅仅只是保留在默认的属性层次结构中的话,那么在聚合设计阶段它们并不会主动使用到它们,不会发生真正的聚合。在查询阶段,如果包含了这些属性的引用,这个时候也还是通过主键 Key Attribute 来汇总数据。这样一来,没有利用到聚合的好处,在查询中对这些属性层次结构的使用上性能将非常慢。
为了提升查询性能,一般会通过 Aggregation Usage 属性来配置聚合属性的候选人 (这个以后再介绍)。在修改 Aggregation Usage 属性之前,还要考虑到使用用户自定义的属性层次结构。
分析服务有两种用户自定义的属性层次结构 - 自然层次结构和非自然层次结构 (Natural Hierarchy and Unnatural Hierarchy),它们各自的设计和性能特征都不相同:
自然层次结构 Natural Hierarchy - 在自然层次结构中的所有级别上的所有属性,它们与其它从层次结构顶层到底层上的其它所有属性都有着直接的或者间接的关联关系。
非自然层次结构 Unnatural Hierarchy - 在层次结构中的至少两个连续的层级上的属性,它们彼此之间是没有属性关联关系的。通常这种类型的层次结构也是用来为常用的属性创建 Drill-down 钻取导航路径,但是它本身又没有"自然层次"的特征。比如说,用户可能需要通过由性别和教育构成的层级结构来浏览数据,但是性别和教育彼此之间没有这种自然的关联关系。
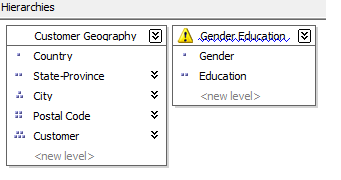
从性能的角度来考虑,自然层次结构的表现方式和非自然层次结构区别还是非常大的。在自然层级结构中,层次结构树在层次结构存储时将会被具体化或者磁盘化 Materialized。并且,参与到自然层次结构中的所有属性都会被自动的成为聚合候选属性。( 关于 Materialized 等概念可以参考索引视图,索引视图中也有这个概念。可以理解像表一样存储数据,把聚合结果和层次结构保存到磁盘上) 。
非自然层次结构不会磁盘化,并且结构中的属性并不会自动的被选为聚合候选属性。尽管没有这种自然的关联关系,但是从用户的角度来说,有这种钻取的层次路径还是非常方便的,并且在 MDX 中通过导航函数也可以非常方便的导航和计算,所以还是可以起到一定的积极作用的。
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。
微软BI 之SSAS 系列 - 维度的优化,灌木丛属性关系,以及自然层次结构与非自然层次结构的概念的更多相关文章
- 微软BI 之SSAS 系列 - 自定义的日期维度设计
SSAS Date 维度基本上在所有的 Cube 设计过程中都存在,很难见到没有时间维度的 OLAP 数据库.但是根据不同的项目需求, Date 维度的设计可能不大相同,所以在设计时间维度的时候需要搞 ...
- 微软BI 之SSAS 系列 - 多维数据集维度用法之三 多对多维度 Many to Many
开篇介绍 对于维度成员和事实数据直接的关系看到更多的可能还是一对一,一对多的关系.比方在事实维度(或退化维度)中一个订单和明细号组合而成的ID,对应的就是事实表中的一条数据,这就是一对一的关系.比方说 ...
- 微软BI 之SSAS 系列 - 多维数据集维度用法之一 引用维度 Referenced Dimension
在 CUBE 设计过程中有一个非常重要的点就是定义维度与度量值组关系,维度的创建一般在前,而度量值组一般来源于一个事实表.当维度和度量值组在 CUBE 中定义完成之后,下一个最重要的动作就是定义两者之 ...
- 微软BI 之SSAS 系列 - 多维数据集维度用法之二 事实维度(退化维度 Degenerate Dimension)
这篇文章是基于上一篇 SSAS 系列 - 多维数据集维度用法之一 引用维度 Referenced Dimension 继续讲解多维数据集维度用法中的事实维度. 事实维度,顾名思义就是把事实表 Fact ...
- 微软BI 之SSAS 系列 - 基于雪花模型的维度设计
基于雪花模型的维度以下面的 Product 产品与产品子类别,产品类别为例. DimProduct 表和 DimProductSubcategory 表有外键关系,而 DimProductSubcat ...
- 微软BI 之SSAS 系列 - 实现Cube 以及角色扮演维度,度量值格式化和计算成员的创建
在熟悉完下面这三种维度的创建方式之后,就可以开始创建我们的第一个 Cube 了. SSAS 系列 - 自定义的日期维度设计 SSAS 系列 - 基于雪花模型的维度设计 SSAS系列 - 关于父子维度的 ...
- 微软BI 之SSAS 系列 - 多维数据集中度量值设计时的聚合函数 (累加性_半累加性和非累加性)
在 SSAS 系列 - 实现第一个 Cube 以及角色扮演维度,度量值格式化和计算成员的创建 中主要是通过已存在的维度和事实数据创建了一个多维数据集,并同时解释了 Role-Playing Dimen ...
- 微软BI 之SSAS 系列 - 在SQL Server 2012 中开发 Analysis Services Multidimensional Project
SQL Server 2012 中提供了开发 SSAS 项目的两种模型,一种是新增加的 Tabular Model 表格模型,另一种就是原始的 Multidimensional Model 多维模型. ...
- 微软BI 之SSAS 系列 - 关于父子维度的设计
除了之前的几篇文章中出现的时间维度,雪花型维度的设计之外还有一种比较特殊的维度 - 父子维度.父子维度特殊就特殊在它包含了一种基于递归关系(Recursive Relationship)的引用结构, ...
随机推荐
- 老方块Oracle--数值类型性能考虑
我们在设计数据库表,或者在使用SQL,写程序时都会经常用到数值类型.比如常见的number.int.float. float是浮点类型,也属于数值类型,我们最常用的是number类型. 他的格式是nu ...
- Android 之 tools:context和tools:ignore两个属性的作用
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools= ...
- android和java以太坊开发区块链应用使用web3j类库
如何使用web3j为Java应用或Android App增加以太坊区块链支持,教程内容即涉及以太坊中的核心概念,例如账户管理包括账户的创建.钱包创建.交易转账,交易与状态.智能合约开发与交互.过滤器和 ...
- php字符串截取
保留字符串前面的 substr($str,start[,$length]); start 为负数 则从后面开始截取 leng为负数则返回的字符串将从 $str 结尾处向前数第 start 个字符开始 ...
- Android应用开发-数据存储和界面展现(二)
SQLite数据库 // 自定义类MyOpenHelper继承自SQLiteOpenHelper MyOpenHelper oh = new MyOpenHelper(getContext(), &q ...
- 2852 ACM 杭电 KiKi's K-Number 0 1 2
题目:http://acm.hdu.edu.cn/showproblem.php?pid=2852 题意:三种操作: 0 插入 1 删除 2 查找比a大的第k个数. 思路:看了大神都是用树状数组写的, ...
- python生成指定文件夹目录树
# -*- coding: utf-8 -*- import sys from pathlib import Path class DirectionTree(object): "" ...
- (转)理解classloader
ClassLoader翻译过来就是类加载器,普通的Java开发者其实用到的不多,但对于某些框架开发者来说却非常常见.理解ClassLoader的加载机制,也有利于我们编写出更高效的代码.ClassLo ...
- sessions
php session 用于存储有关用户回话的相关信息,或更改用户会话的相关设置,session变量保存的信息是单一用户的,并且可供应用程序中所有页面使用 session 的工作机制:为每个访问者创建 ...
- GPSCamera隐私声明
GPSCamera获取了以下敏感隐私权限用于照片水印展示: 1:修改或删除您的SD卡中的内容 2:访问确切位置信息(使用 GPS 和网络进行定位) 3:访问大致位置信息(使用网络进行定位) 4:拍摄照 ...