网易大数据之数据存储:HDFS
一、HDFS基础架构
1、HDFS特点:水平扩展、高容错性、廉价硬件、开源生态系统
2、Hadoop生态圈
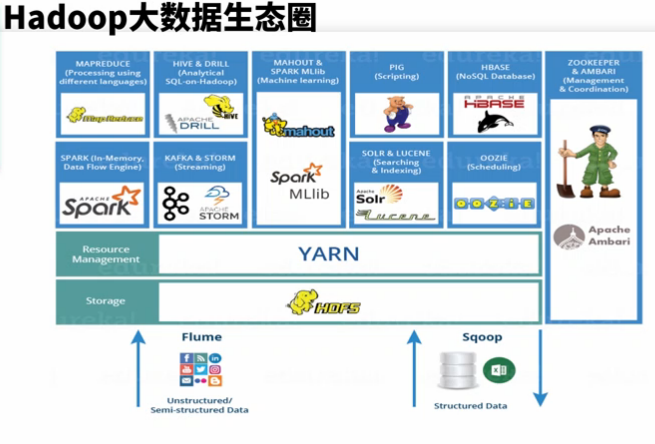
1)、分布式存储系统(HDFS),2)、资源管理框架(YARN),3)、批处理框架(MapReduce、Pig),4)、数据仓库(Hive),5)、NoSQL系统(HBase、Drill),6)、OLAP系统(Impala、Presto、Spark(SQL)),7)、实时流计算框架(Storm、Spark(Streaming)、Flink),8)、机器学习框架(Mahout、Spark(MLlib)),9)、消息队列(Kafka),10)、分布式协同服务(Zookeeper),11)、作业调度系统(Oozie),12)、全文检索系统Solr
3、HDFS架构
相关概念:Rack 机架:存储节点放在不同机架上,这与数据备份放置策略有关
Block 数据块:数据切分成特定大小的数据块,分发到不同存储节点
Replication 副本:数据块在不同存储节点之间,通过复制方式来拷贝
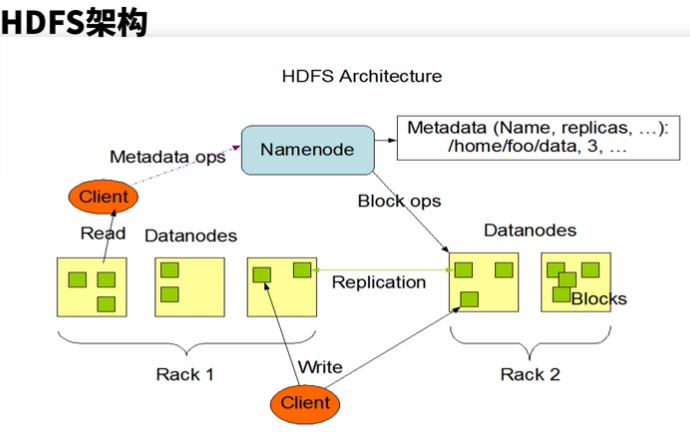
1)、NameNode(管理节点):负责名称空间管理,管理元数据;负责文件到数据块的映射,以及数据块和存储节点对应关系
2)、DataNode(数据存储节点):向管理节点汇报数据块信息;存储节点之间通过复制操作来实现数据均衡和备份;与客户端交互,执行数据读写请求
3)、Client(客户端):向NN/DN发起读写请求
4、HDFS读写
1)、HDFS Read
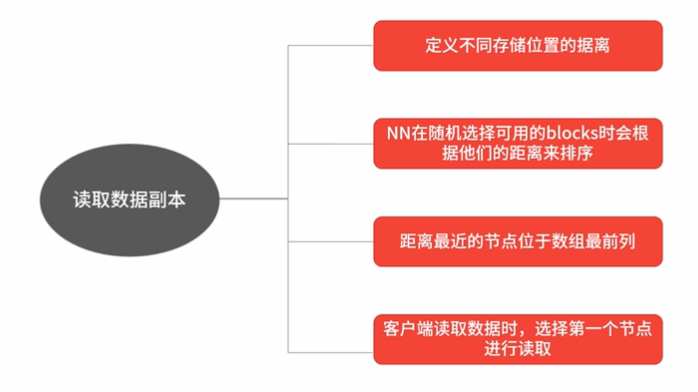
a、客户端向NN发起读请求
b、NN返回请求文件的数据块所在的存储节点列表,如果有多个块,会返回多个存储列表,因为一个数据块对应一个存储节点
c、客户端根据返回的节点列表,优先选择最近的节点访问
d、选完节点后,客户端直接与DN节点连接读取相应的Block数据,读完这个Block后关闭连接
e、如果文件有多个数据块,客户端再次选择下一个Block所在节点,进行连接,重复上述过程
f、已经读完最后一个数据块后,关闭与NN连接
2)、HDFS Write
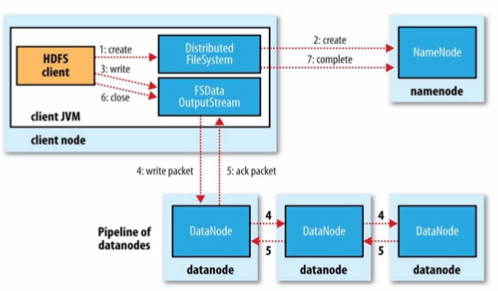
a、客户端向NN发起写请求
b、NN返回需要写入文件的数据块所在的存储节点列表
c、客户端根据返回的节点列表,优先选择最近的节点创建链接;如果该客户端在DN节点上,则优先写本地节点
d、客户端与第一个DN节点建立TCP链接,然后该DN节点会根据客户端传递过来的节点信息,依次创建下一个DN节点的链接。以及第二个DN节点到第三个DN节点的链接。这个过程称为创建DataNode管道
e、客户端先写第一个数据包,待第一个节点收到该数据包后,由其向下一个节点发送这个数据包,直至到第三个节点
f、在最后一个节点完成数据包的接收后,向第二个节点发送确认信息;第二个节点收到确认信息后,将自己的确认信息发送给第一个节点,然后第一个节点将确认信息发送给客户端。客户端收到这个数据包的确认信息后,才会发送下一个数据包,如此反复
g、当第一个数据块写完后,客户端关闭这个DataNode管道。如果还有数据块,则创建一个新的数据管道开始写入数据
h、数据写完后,客户端关闭
5、副本放置策略 下图,n1234\node为节点即服务器,r123\rack为机架,d12\data center为数据中心;黄块为数据块;蓝块为客户端;
d=0246为客户端到存储块节点距离,local为d=0,同rack为d=2,同数据中不同rack为d=4,不同数据中心为d=6
定义节点访问距离,可以降低网络访问流量开销,提高访问性能
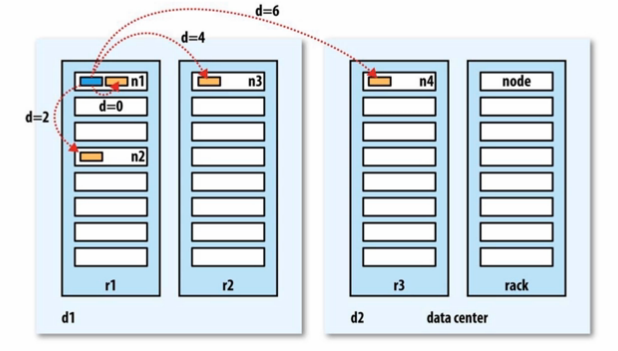
NN来选择数据块的放置节点,它按照机架配置来选择节点。如果是3副本放置策略,优先放入到离写入客户端最近的DN节点;然后是该节点同机架上的一个节点;最后是与该节点不在同一机架上的节点。
选择节点辅助策略:随机选择一个节点,随机选择两次,返回磁盘使用率较低的一个节点
二、部署配置
1、部署安装
一般参数列表
fs.defaultFS HDFS的名称空间地址
dfs.blocksize 块大小,默认是64M或128M,文件存储的时候,如果大于指定块大小,则切分,如果小于,则按照文件大小存储,并不会占用指定块大小
dfs.replication 备份数,默认为3
dfs.reservedsize 磁盘保留空间,默认未开启
dfs.namenode.edit.dir NN的edit日志存放路径,edit日志文件编号前后连接,如果中间有断链,那么说明文件缺失
dfs.namenode.name.dir NN的image文件(元数据)存放路径
dfs.datanode.data.dir DN的数据存储目录,可以选择存储在多个目录下,多个目录用逗号隔开
dfs.namenode.rpc-address NN的RPC服务端口号
dfs.namenode.http-address NN的HTTP服务端口号
dfs.datanode.address DN的RPC服务端口号,数据传输用
dfs.datanode.http.address DN的HTTP服务端口号
dfs.datanode.ipc.address DN的IPC端口号,与NN通信
fs.trash.interval 开起回收站,如果通过hdfs的shell命令删除的数据会放到回收站,回收站默认清除时间为1小时,也可以自定义
2、部署实操
1)、配置javahome环境变量、可以使用scp命令(需要安装SSH)上传Hadoop软件包
2)、使用tar -zxvf命令解压hadoop软件包;使用ln命令创建软连接,如ln -s hadoop-2.7.7 hadoop-current
3)、配置Hadoop Home环境变量
a、cd ~
b、vi .bashrc 配置文件写入如下图

c、source .bashrc
d、hadoop命令查看配置是否正确,如下图

4)、如果没有配置全局Javahome环境变量,可以在Hadoop配置文件/root/dev/hadoop-2.7.7/etc/hadoop/hadoop-env.sh中配置,此文件也可以配置HadoopJVM相关参数
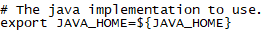 此处默认取环境变量JAVA_HOME
此处默认取环境变量JAVA_HOME
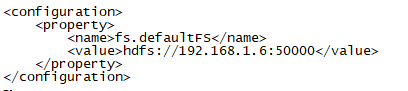
5)、配置HDFS的核心配置文件core-site.xml(/root/dev/hadoop-current/etc/hadoop/core-site.xml),NN、DN和YARN都会加载这个文件, vi core-site.xml 配置fs.defaultFS指向NN地址,其他用默认值(注意下面地址不能用localhost,否则只有本机才能访问)
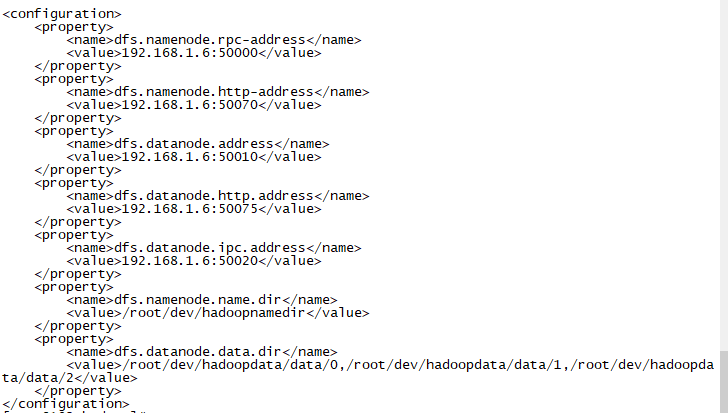
6)、配置hdfs-site.xml vi hdfs-site.xml
7)、格式化HDFS命令 hdfs namenode -format
原本dev文件夹下没有hadoopnamedir,执行完命令后就有了

8)、启动namenode服务 hdfs namenode
(一般端口会被防火墙限制,关闭或者放开端口,参考···········)
启动服务后就可以通过WebUI访问namenode了,地址:http://192.168.1.6:50070
9)、启动datanode服务 hdfs datanode
原本dev文件夹下没有hadoopdata/data/0,hadoopdata/data/1,hadoopdata/data/2,启动服务后就有了(教程中使用 mkdir -p hadoopdata/data/{0..2}命令创建,Hadoop有权限创建情况下会自动创建,否则要自己创建)
在namenode的WebUI下就可以看到启动的datanode了
10)、启动另一个节点的datanode,方式类似以上
a、解压Hadoop,创建软连接
b、从上一个节点拷贝core-site.xml到本机 先切换到Hadoop配置文件目录,后(注意命令最后的点,拷贝到当前文件夹,$PWD表示本机的Hadoop配置文件目录和上一个节点Hadoop配置文件目录一样)scp root@192.168.1.6:$PWD/core-site.xml . 同样的方式再拷贝hdfs-site.xml(教程中拷贝了hadoop-env.xml,由于我本地配置了javahome,所以就不用拷贝了)
c、由于我们使用上一个节点的namenode,所以我们只修改本机Hadoop配置文件hdfs-site.xml中datanode相关配置
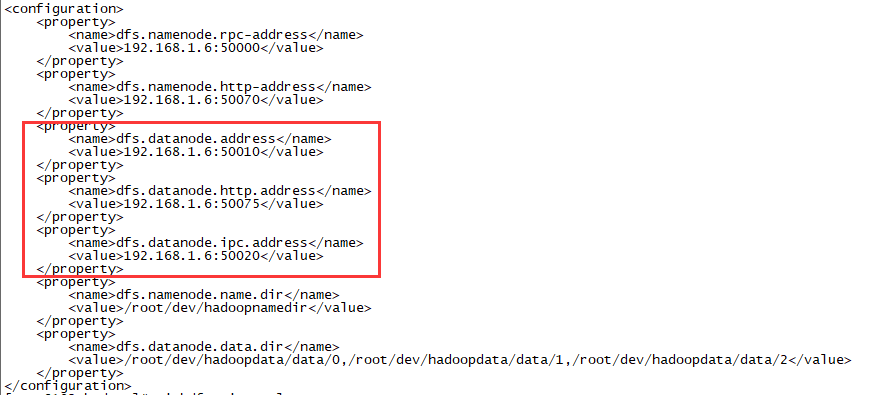 改为
改为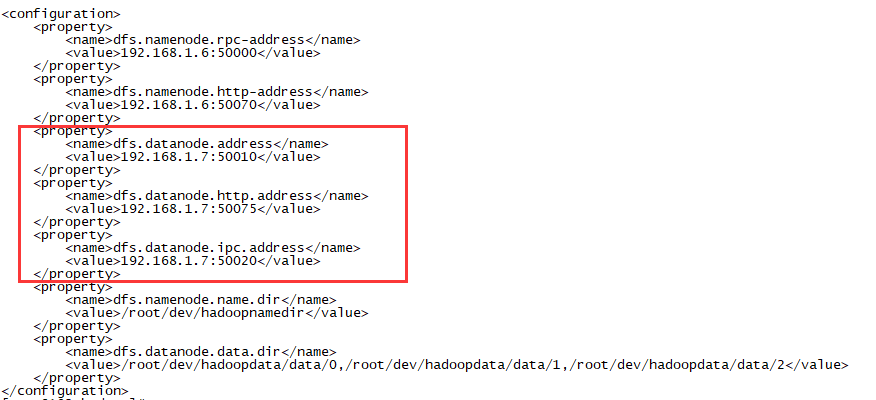
d、由于本机没有配置HadoopHome环境变量,所以使用带路径方式或到bin下使用hdfs datanode命令启动datanode服务
哎呀,不好,报错了,此错是由于解析hostname出错,因为配置中使用的是IP
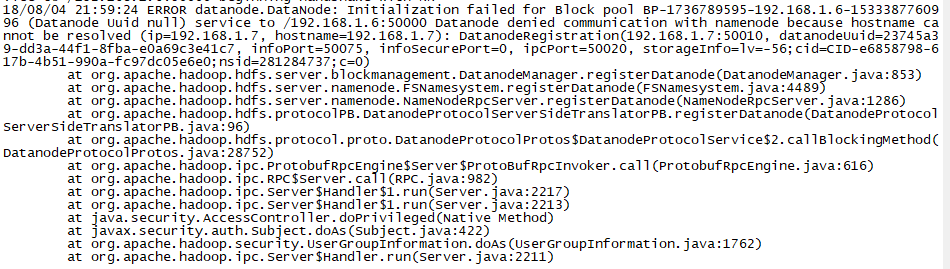
两种解决办法;第一种、使用hostname,在hosts文件中做好映射(没测)
第二种、在hdfs-site.xml中添加配置如下 (namenode和datanode都配置)
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
添加了配置后,重新启动datanode服务,刷新namenode节点对应的WebUI,看到datanode节点数为2
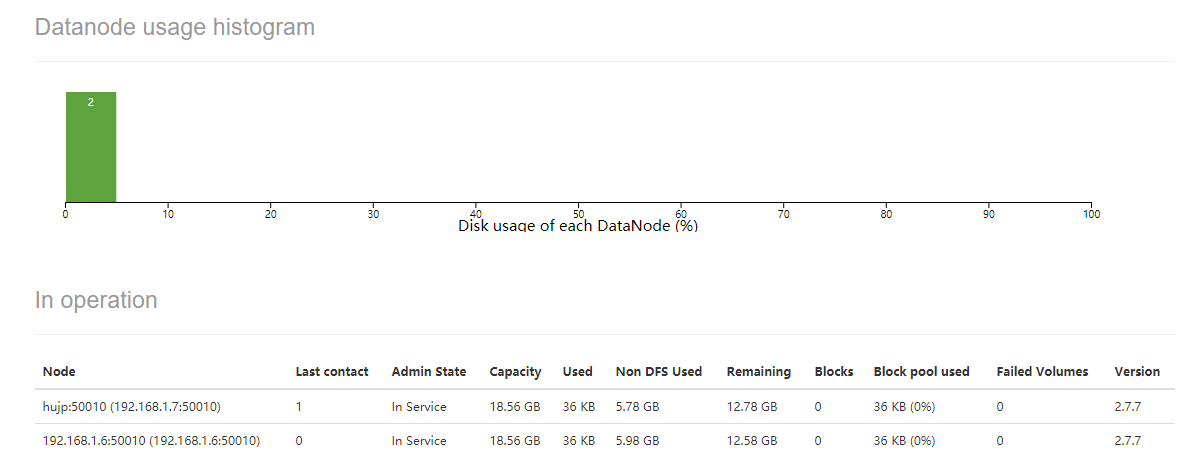
如果其中一个DataNode宕机,namenode要等很久才知道,如果查询或获取数据,正好访问宕机节点,要达到最大尝试次数

注意,如果出现类似异常java.io.IOException: Incompatible clusterIDs、java.io.IOException: All specified directories are failed to load需要将datanode存放数据的目录删掉,使用命令如 rm -rf hadoopdata
11)、测试hadoop fs命令
查看根目录命令:hadoop fs -ls /
创建文件夹命令:hadoop fs -mkdir /tmp hadoop fs -mkdir -p /user/hjp hadoop fs -mkdir /user/hjp/input
上传txt格式文件:hadoop fs -put *.txt /user/hjp/input
删除指定文件:hadoop fs -rm /user/hjp/input/1.txt
查看文件内容命令:hadoop fs -text /user/hjp/input/1.txt
下载文件到本地并重命名:hadoop fs -get /user/hjp/input/1.txt 123.txt (比较两个文件内容是否一样,可以使用md5sum命令获取md5值对比,如下图)

12)、守护进程启动datanode服务:dev/hadoop-current/sbin/hadoop-daemon.sh start datanode,其他DataNode和NameNode也类似此守护进程方式启动

使用tail -f命令查看日志信息:tail -f /root/dev/hadoop-2.7.7/logs/hadoop-root-datanode-192.168.1.8.log
13)、YARN部署(master上启动resourcemanager服务,slaves上启动nodemanager服务)
a、YARN共用Hadoop的core-site.xml和hdfs-site.xml,只需配置YARN的yarn-site.xml和mapred-site即可
yarn-site.xml配置如下
<configuration>
<!-- Site specific YARN configuration properties -->
<!--RM WebUI地址-->
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.6:8088</value>
</property>
<!--RM域名-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.1.6</value>
</property>
<!--NM logs存放作业的日志输出-->
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/root/dev/yarn/0/logs,/root/dev/yarn/1/logs,/root/dev/yarn/2/logs</value>
</property>
<!--NM工作目录-->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/root/dev/yarn/0/local,/root/dev/yarn/1/local,/root/dev/yarn/2/local</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml配置如下(Hadoop配置目录下没有mapred-site.xml,而又mapred-site.xml.template。配置目录下使用cp mapred-site.xml.template mapred-site.xml命令复制一下):
<configuration>
<!--MR的资源调度框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--作业历史RPC地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.6:10020</value>
</property>
<!--MR作业历史WebUI-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.6:19888</value>
</property>
</configuration>
b、如果没有权限创建yarn日志输出和工作目录文件夹权限,就使用mkdir -p /root/dev/yarn/{0..2}/local和mkdir -p /root/dev/yarn/{0..2}/logs命令创建对应文件夹;如果当前用户有权限,Hadoop会自动创建;下面其他节点启动nodemanager服务也是如此
c、启动yarn resourcemanager,直接使用命令yarn resourcemanager,启动成功后,看到WebUI端口为8088

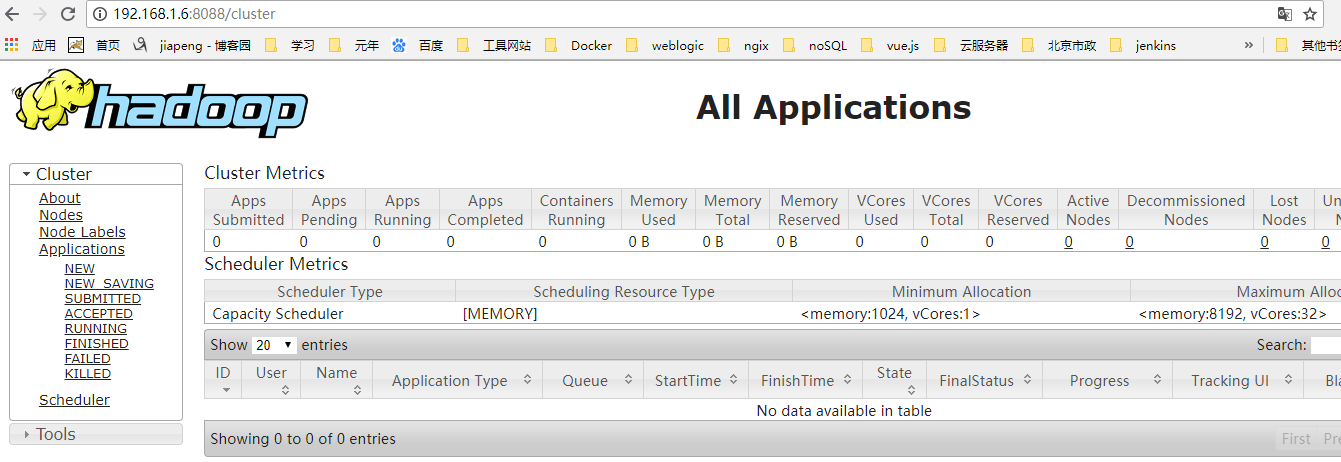
d、在其他节点Hadoop配置文件目录下,使用scp root@192.168.1.6:$PWD/yarn-site.xml . 和scp root@192.168.1.6:$PWD/yarn-site.xml . 命令拷贝yarn-site.xml和mapred-site.xml文件到其他节点。无需改动配置
e、其他节点因为没有配置Hadoop环境变量,到bin目录下启动nodemanager服务: bin/yarn nodemanager
f、到ResourceManager WebUI上查看nodes,1.6为ResourceManager,1.7和1.8为NodeManager,如下图(我本机配置没有这样高,下面的配置数据估计是来自配置文件)
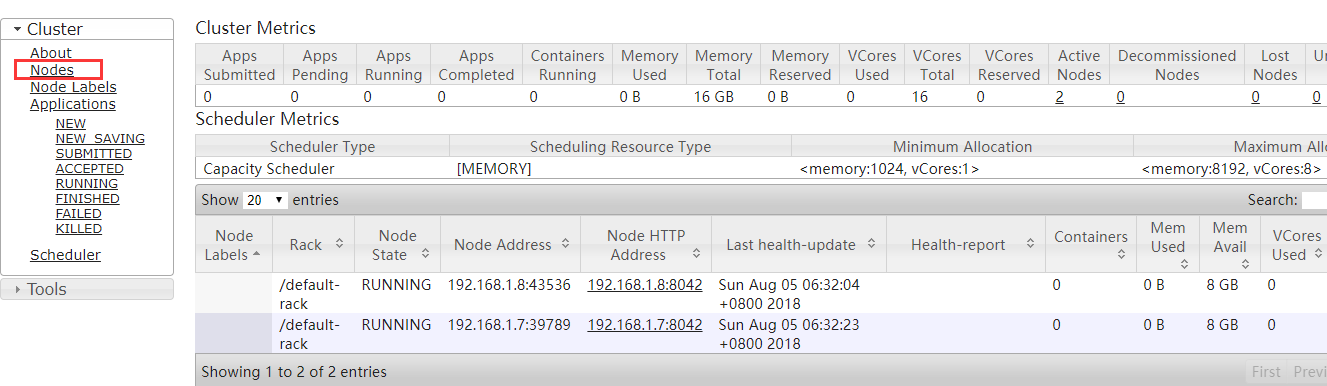
注意:如果本地没有配置hosts,那么yarn的node节点需要在yarn-site.xml配置文件中配置yarn.nodemanager.address,对应本节点的IP,IP后面的0表示端口号随机分配。resourcemanager节点不需要配置。nodemanager中yarn-site.xml添加配置如下,可参考······

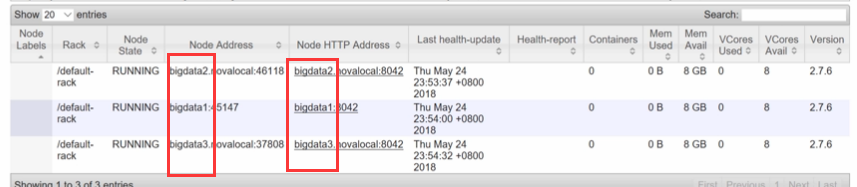
教程中会看到老师的ResourceManager WebUI下对应NodeManager RPC或Http地址如下,使用的是主机名
g、在Hadoop home文件下可以通过命令hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar,获取example Jar包命令参数解释,如下

h、使用example Jar包的pi命令测试yarn 和 mapreduce:在resourcemanager节点上的Hadoop home文件夹下输入命令 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 5 10 哎呀报错了,如下,需要设置resourcemanager和nodemanager节点时间一致,方法参考··············

修改好再次执行就OK了
i、再写一个获取文件字数的命令: hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /user/hjp/input /user/hjp/output
在ResourceManager上查看历史任务,如下

点击上面ID列中一个,进入下面界面,点击History,无法访问网页,说明MapReduce JobHistory服务还没有启动;ResourceManager节点上命令mapred historyserver启动
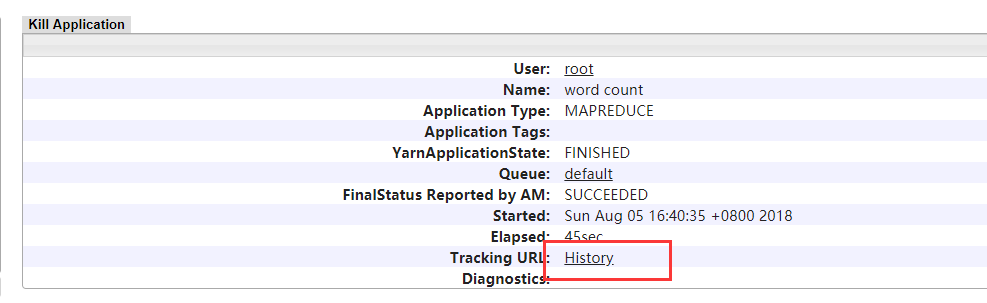 启动historyserver后----》
启动historyserver后----》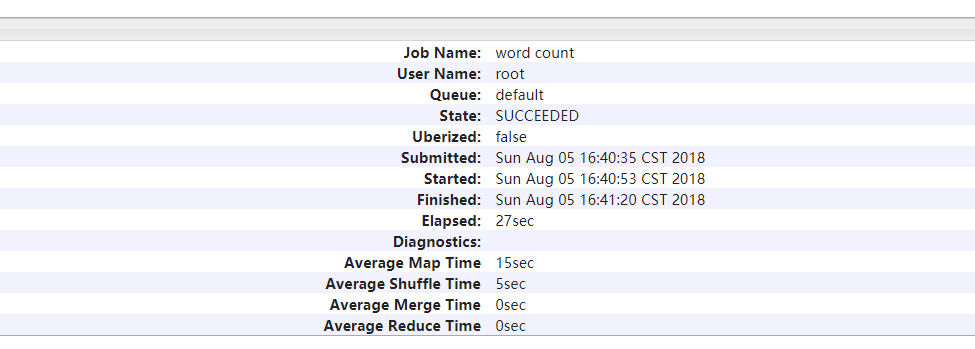
j、守护进程启动resourcemanager服务和nodemanager服务:dev/hadoop-current/sbin/yarn-daemon.sh start resourcemanager和dev/hadoop-current/sbin/yarn-daemon.sh start nodemanager;守护进程启动historyserver:dev/hadoop-current/sbin/mr-jobhistory-daemon.sh start historyserver
三、HDFS管理与使用
注意要配置hdfs-site.xml打开ACL权限控制,默认不打开
<property>
<name>dfs.namenode.acls.enabled</name>
<value>true</value>
</property>
1、HDFS默认使用POSIX风格的权限管理方式,权限分为用户、用户组、其他等角色。使用方式类似Linux系统修改权限。
如hadoop fs -chmod <PERM> <PATH> 修改文件权限;hadoop fs -chown <USER:GROUP> <PATH>修改文件所属用户、用户组
例,改变用户目录所属用户组:haddop fs -chown :groupa /user/hjp/foo 或 hadoop fs -chgrp groupa /user/hjp/foo
2、ACL权限变更,修改ACL权限后立即生效,无需刷新用户用户组
1)、普通文件的权限,会延续到此文件下子文件,所以使用ACL来细粒度控制权限,HDFS提供了类似POSIX ACL特性
2)、一条ACL规则由若干ACL条目组成,每个条目指定一个用户或用户组的权限位。ACL条目由类型名,可选名称和权限字符串组成,以英文冒号为分隔符
3)、目录或文件的ACL规则示例如下(逗号分隔,第一个表示类型名,第二个表示可选名,第三个是权限位),当设置了ACL规则后,hdfs目录或文件权限位后面会多一个加号(+):

user::rw- 所属用户,读写权限;类型名表示设置的是用户权限,可选名省略表示目录或文件所属的用户
user:bruce:rwx bruce用户,读写可执行权限;类型名表示设置的是用户权限,可选名是bruce用户,但是写了可选名,就要经过下面mask的过滤,最终该用户对目录或文件是读权限
group::r-x 所属用户组可读可执行权限;类型名表示设置的是用户组权限,可选名省略表示目录或文件所属的用户组,但是类型名为用户组的要经过下面的mask过滤,最终目录或文件所属用户组是读权限
group:sales:rwx sales用户组,读写可执行权限;类型名表示设置的是用户组权限,可选名是sales用户组,但是类型名为用户组的要经过下面的mask过滤,最终目录或文件对sales用户是读权限
mask::r-- 对group条目和指定用户的user条目起作用,进行过滤
other::r-- 其他用户,即非目录或文件所属用户及用户组,读权限;
default:上面权限设置形式;default只应用于目录上,权限会被子目录及文件所继承,所以慎用
具体示例如下:

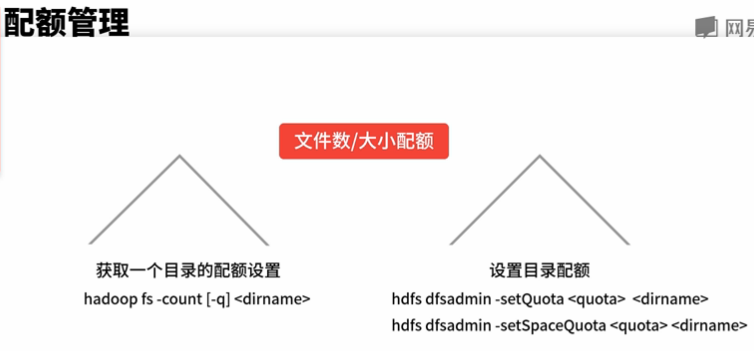
3、 配额管理
4、数据均衡

5、滚动升级(可以不用停服)
1)、NN升级,注意下面的NN1表示当前使用的NN节点,NN2表示备用的NN节点;当前使用的NN节点简称ANN(ActiveNameNode),备用的NN节点简称SNN(StandbyNameNode)

2)、DN升级,注意rollingUpgrade finalize命令会删除NN和DN备份的数据,所以在确保升级成功后再执行该命令

6、版本回滚(要停服)

7、其他

四、高级内容
1、HDFS高可用
网易大数据之数据存储:HDFS的更多相关文章
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- 网易大数据平台的Spark技术实践
网易大数据平台的Spark技术实践 作者 王健宗 网易的实时计算需求 对于大多数的大数据而言,实时性是其所应具备的重要属性,信息的到达和获取应满足实时性的要求,而信息的价值需在其到达那刻展现才能利益最 ...
- 大数据-hadoop生态之-HDFS
一.HDFS初识 hdfs的概念: HDFS,它是一个文件系统,用于存储文件,通过目录树定位文件,其次,他是分布式的,由很多服务器联合起来 实现功能,集群中的服务器各有各自的角色 HDFS设计适合一次 ...
- 大数据 - hadoop基础概念 - HDFS
Hadoop之HDFS的概念及用法 1.概念介绍 Hadoop是Apache旗下的一个项目.他由HDFS.MapReduce.Hive.HBase和ZooKeeper等成员组成. HDFS是一个高度容 ...
- 大数据技术 - 分布式文件系统 HDFS 的设计
本章内容介绍下 Hadoop 自带的分布式文件系统,HDFS 即 Hadoop Distributed Filesystem.HDFS 能够存储超大文件,可以部署在廉价的服务器上,适合一次写入多次读取 ...
- 为数据计算提供强力引擎,阿里云文件存储HDFS v1.0公测发布
在2019年3月的北京云栖峰会上,阿里云正式推出全球首个云原生HDFS存储服务—文件存储HDFS,为数据分析业务在云上提供可线性扩展的吞吐能力和免运维的快速弹性伸缩能力,降低用户TCO.阿里云文件存储 ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- 我眼中的大数据(二)——HDFS
Hadoop的第一个产品是HDFS,可以说分布式文件存储是分布式计算的基础,也可见分布式文件存储的重要性.如果我们将大数据计算比作烹饪,那么数据就是食材,而Hadoop分布式文件系统HDFS就是烧菜的 ...
- 大数据笔记04:大数据之Hadoop的HDFS(基本概念)
1.HDFS是什么? Hadoop分布式文件系统(HDFS),被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点. 2.HDFS ...
随机推荐
- spring源码分析系列
spring源码分析系列 (1) spring拓展接口BeanFactoryPostProcessor.BeanDefinitionRegistryPostProcessor spring源码分析系列 ...
- 使用Quartz搭建定时任务脚手架
定时任务的实现有很多种,在Spring项目中使用一个注解 @Scheduled就可以很快搞定. 但是很难去管理项目中的定时任务,比如说:系统中有多少定时任务,每个定时任务执行规则,修改执行规则,暂停任 ...
- JDBC(2)—Statement
介绍: 获取到数据库连接之后,就可以对数据库进行一些增.删.改操作,但是却不能进行查询操作. 增删改操作是程序到数据库的一个操作过程,但是查询是程序到数据库--数据库返回到程序的一个过程. 步骤: 步 ...
- Adding Digital control to Dual tracking LM317 / LM337 Bench supply
Adding Digital control to Dual tracking LM317 / LM337 Bench supply I've been working on my own idea ...
- opencv rtsp 人脸识别
import cv2 import dlibimport jsonface_detector = dlib.get_frontal_face_detector() cap = cv2.VideoCap ...
- qt不能调试
在F5执行qt的调试时,提示:unknown debugger type "No engine" 需要下载debug调试工具,win7的下载位于:https://www.micro ...
- Swift学习笔记(十四)——字符,常量字符串与变量字符串
在学习Java过程中,字符串碰到过String和StringBuffer,当中前者是不可变的,不能对字符串进行改动:后者是可变的,能够不断改动. 来到Swift中,对字符串的定义变的更加简单. (1) ...
- Spring ActiveMQ 整合(三): 确认机制ACK(收到消息后,应该有一个回应也就是确认答复)
https://blog.csdn.net/dly1580854879/article/details/68490197
- hive在命令行消除进度等错误信息
大家在使用shell脚本调用hive命令的时候,发现hive的中间过程竟然打印到错误输出流里面,这样在查看错误日志的时候,需要过滤这些没用的信息,那么可以使用如下的配置参数. set hive.ses ...
- Ext4 ReiserFS Btrfs 等7种文件系统性能比拼
2009年02月04日 为了满足广大群众的热切需求,今天做了 Ext2.Ext3.Ext4.XFS.JFS.ReiserFS 和 Btrfs 的全面性能测试,对比结果如下: 本次测试所 ...