MapReduce(三)
MapReduce(三)
MapReduce(三):
1.关于倒叙排序前10名
1)TreeMap根据key排序
2)TreeSet排序,传入一个对象,排序按照类中的compareTo方法排序
2.写一个MapReduce的模板
3.MapReduce的分区
1)手动分区
2)自动分区
4.自定义分区
----------------------------------------------------------------------------------------------------------------------------------
一.关于倒叙排序前10名
将一个文章中字母单词出现的次数进行倒叙排序,只取前十
1)TreeMap
- package com.huhu.day03;
- import java.io.IOException;
- import java.util.Collections;
- import java.util.Map;
- import java.util.StringTokenizer;
- import java.util.TreeMap;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- import org.apache.hadoop.util.Tool;
- import org.apache.hadoop.util.ToolRunner;
- /**
- * a 80 b 78 r 70 .. 基于value来排序
- *
- * @author huhu_k
- *
- */
- public class Top10_1 extends ToolRunner implements Tool {
- private Configuration conf;
- public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
- @Override
- protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- StringTokenizer st = new StringTokenizer(value.toString());
- while (st.hasMoreTokens()) {
- context.write(new Text(st.nextToken()), new IntWritable(1));
- }
- }
- }
- public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
- // TreeMap倒叙排列
- private TreeMap<Long, String> map = new TreeMap<>(Collections.reverseOrder());
- @Override
- protected void reduce(Text key, Iterable<IntWritable> values, Context context)
- throws IOException, InterruptedException {
- int sum = 0;
- for (IntWritable v : values) {
- sum++;
- }
- map.put(Long.valueOf(sum), key.toString());
- if (map.size() > 10) {
- // 按key排序 前十 降序
- map.remove(map.lastKey());
- }
- }
- @Override
- protected void cleanup(Context context) throws IOException, InterruptedException {
- for (Map.Entry<Long, String> m : map.entrySet()) {
- context.write(new Text(m.getValue()), new IntWritable(Integer.parseInt(m.getKey() + "")));
- }
- }
- }
- @Override
- public Configuration getConf() {
- if (conf != null) {
- return conf;
- }
- return new Configuration();
- }
- @Override
- public void setConf(Configuration arg0) {
- }
- @Override
- public int run(String[] other) throws Exception {
- Configuration conf = new Configuration();
- Job job = Job.getInstance(conf);
- job.setJarByClass(Top10_1.class);
- job.setMapperClass(MyMapper.class);
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(IntWritable.class);
- job.setReducerClass(MyReduce.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- FileInputFormat.addInputPath(job, new Path(other[0]));
- FileOutputFormat.setOutputPath(job, new Path(other[1]));
- return job.waitForCompletion(true) ? 0 : 1;
- }
- public static void main(String[] args) throws Exception {
- Top10_1 t = new Top10_1();
- String[] other = new GenericOptionsParser(t.getConf(), args).getRemainingArgs();
- if (other.length != 2) {
- System.out.println("your input args number is fail,you need input <in> and <out>");
- System.exit(0);
- }
- ToolRunner.run(t.conf, t, other);
- }
- }
- package com.huhu.day03;
- import java.io.IOException;
- import java.util.Iterator;
- import java.util.TreeSet;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.NullWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- import org.apache.hadoop.util.Tool;
- import org.apache.hadoop.util.ToolRunner;
- /**
- * a 80 b 78 r 70 .. 基于value来排序 TreeSet
- *
- * @author huhu_k
- *
- */
- public class Top10_2 extends ToolRunner implements Tool {
- private Configuration conf;
- public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
- @Override
- protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- String[] line = value.toString().split(" ");
- for (String s : line) {
- context.write(new Text(s), new IntWritable(1));
- }
- }
- }
- public static class MyReduce extends Reducer<Text, IntWritable, WCWritable, NullWritable> {
- // TreeSet倒叙排列
- private TreeSet<WCWritable> set;
- private final int KEY = 11;
- @Override
- protected void setup(Context context) throws IOException, InterruptedException {
- set = new TreeSet<WCWritable>();
- }
- @Override
- protected void reduce(Text key, Iterable<IntWritable> values, Context context)
- throws IOException, InterruptedException {
- WCWritable w = new WCWritable();
- int sum = 0;
- for (IntWritable i : values) {
- sum += i.get();
- }
- w.setWord(key.toString());
- w.setCount(sum);
- set.add(w);
- if (KEY < set.size()) {
- set.remove(set.last());
- }
- }
- @Override
- protected void cleanup(Context context) throws IOException, InterruptedException {
- Iterator<WCWritable> iterator = set.iterator();
- if (iterator.hasNext()) {
- context.write(iterator.next(), NullWritable.get());
- }
- }
- }
- @Override
- public Configuration getConf() {
- if (conf != null) {
- return conf;
- }
- return new Configuration();
- }
- @Override
- public void setConf(Configuration arg0) {
- }
- @Override
- public int run(String[] other) throws Exception {
- Configuration conf = new Configuration();
- Job job = Job.getInstance(conf);
- job.setJarByClass(Top10_2.class);
- job.setMapperClass(MyMapper.class);
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(IntWritable.class);
- job.setReducerClass(MyReduce.class);
- job.setOutputKeyClass(WCWritable.class);
- job.setOutputValueClass(NullWritable.class);
- FileInputFormat.addInputPath(job, new Path(other[0]));
- FileOutputFormat.setOutputPath(job, new Path(other[1]));
- return job.waitForCompletion(true) ? 0 : 1;
- }
- public static void main(String[] args) throws Exception {
- Top10_2 t = new Top10_2();
- String[] other = new GenericOptionsParser(t.getConf(), args).getRemainingArgs();
- if (other.length != 2) {
- System.out.println("your input args number is fail,you need input <in> and <out>");
- System.exit(0);
- }
- ToolRunner.run(t.getConf(), t, other);
- }
- }
运行还是在集群中运行,报错可以查看日志
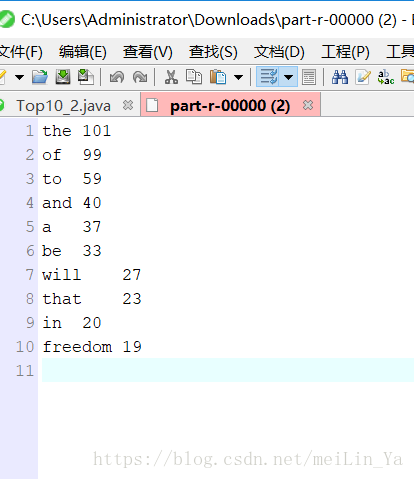
2)TreeSet
- package com.huhu.day03;
- import java.io.DataInput;
- import java.io.DataOutput;
- import java.io.IOException;
- import org.apache.hadoop.io.WritableComparable;
- public class WCWritable implements WritableComparable<WCWritable> {
- private String word;
- private int count;
- public WCWritable() {
- super();
- }
- public WCWritable(String word, int count) {
- super();
- this.word = word;
- this.count = count;
- }
- public String getWord() {
- return word;
- }
- public void setWord(String word) {
- this.word = word;
- }
- public int getCount() {
- return count;
- }
- public void setCount(int count) {
- this.count = count;
- }
- @Override
- public String toString() {
- return "WCWritable [word=" + word + ", count=" + count + "]";
- }
- @Override
- public int hashCode() {
- final int prime = 31;
- int result = 1;
- result = prime * result + count;
- result = prime * result + ((word == null) ? 0 : word.hashCode());
- return result;
- }
- @Override
- public boolean equals(Object obj) {
- if (this == obj)
- return true;
- if (obj == null)
- return false;
- if (getClass() != obj.getClass())
- return false;
- WCWritable other = (WCWritable) obj;
- if (count != other.count)
- return false;
- if (word == null) {
- if (other.word != null)
- return false;
- } else if (!word.equals(other.word))
- return false;
- return true;
- }
- @Override
- public void readFields(DataInput in) throws IOException {
- this.word = in.readUTF();
- this.count = in.readInt();
- }
- @Override
- public void write(DataOutput out) throws IOException {
- out.writeUTF(word);
- out.writeInt(count);
- }
- @Override
- public int compareTo(WCWritable o) {
- if (this.count == o.count) {
- // 字典顺序
- return this.word.compareTo(o.word);
- // return this.word.length() - o.word.length();
- }
- return o.count - this.count;
- }
- }
- package com.huhu.day03;
- import java.io.IOException;
- import java.util.Iterator;
- import java.util.TreeSet;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.NullWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
- import org.apache.hadoop.util.GenericOptionsParser;
- import org.apache.hadoop.util.Tool;
- import org.apache.hadoop.util.ToolRunner;
- /**
- * a 80 b 78 r 70 .. 基于value来排序 TreeSet
- *
- * @author huhu_k
- *
- */
- public class Top10_2 extends ToolRunner implements Tool {
- private Configuration conf;
- static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
- @Override
- protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- String[] line = value.toString().split(" ");
- for (String s : line) {
- context.write(new Text(s), new IntWritable(1));
- }
- }
- }
- static class MyReducer extends Reducer<Text, IntWritable, WCWritable, NullWritable> {
- private TreeSet<WCWritable> set;
- private final int KEY = 10;
- @Override
- protected void setup(Context context) throws IOException, InterruptedException {
- set = new TreeSet<WCWritable>();
- }
- @Override
- protected void reduce(Text key, Iterable<IntWritable> values, Context context)
- throws IOException, InterruptedException {
- WCWritable w = new WCWritable();
- int sum = 0;
- for (IntWritable v : values) {
- sum += v.get();
- }
- w.setWord(key.toString());
- w.setCount(sum);
- set.add(w);
- if (KEY < set.size()) {
- set.remove(set.last());
- }
- }
- @Override
- protected void cleanup(Context context) throws IOException, InterruptedException {
- Iterator<WCWritable> iterator = set.iterator();
- while (iterator.hasNext()) {
- context.write(iterator.next(), NullWritable.get());
- }
- }
- }
- public static void main(String[] args) throws Exception {
- Top10_2 t = new Top10_2();
- Configuration con = t.getConf();
- String[] other = new GenericOptionsParser(con, args).getRemainingArgs();
- if (other.length != 2) {
- System.err.println("number is fail");
- }
- int run = ToolRunner.run(con, t, args);
- System.exit(run);
- }
- @Override
- public Configuration getConf() {
- if (conf != null) {
- return conf;
- }
- return new Configuration();
- }
- @Override
- public void setConf(Configuration arg0) {
- }
- @Override
- public int run(String[] other) throws Exception {
- Configuration con = getConf();
- Job job = Job.getInstance(con);
- job.setJarByClass(Top10_2.class);
- job.setMapperClass(MyMapper.class);
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(IntWritable.class);
- // 默认分区
- job.setPartitionerClass(HashPartitioner.class);
- job.setReducerClass(MyReducer.class);
- job.setOutputKeyClass(WCWritable.class);
- job.setOutputValueClass(NullWritable.class);
- FileInputFormat.addInputPath(job, new Path(other[0]));
- FileOutputFormat.setOutputPath(job, new Path(other[1]));
- return job.waitForCompletion(true) ? 0 : 1;
- }
- }
二.写一个MapReduce的模板
- package util;
- import java.io.IOException;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
- import org.apache.hadoop.util.GenericOptionsParser;
- import org.apache.hadoop.util.Tool;
- import org.apache.hadoop.util.ToolRunner;
- public class Frame extends ToolRunner implements Tool {
- private Configuration conf;
- public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
- @Override
- protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- String[] line = value.toString().split(" ");
- }
- }
- public static class MyReduce extends Reducer<Text, Text, Text, Text> {
- @Override
- protected void setup(Context context) throws IOException, InterruptedException {
- }
- @Override
- protected void reduce(Text key, Iterable<Text> values, Context context)
- throws IOException, InterruptedException {
- }
- @Override
- protected void cleanup(Context context) throws IOException, InterruptedException {
- }
- }
- public static void main(String[] args) throws Exception {
- Frame t = new Frame();
- Configuration conf = t.getConf();
- String[] other = new GenericOptionsParser(conf, args).getRemainingArgs();
- if (other.length != 2) {
- System.err.println("number is fail");
- }
- int run = ToolRunner.run(conf, t, args);
- System.exit(run);
- }
- @Override
- public Configuration getConf() {
- if (conf != null) {
- return conf;
- }
- return new Configuration();
- }
- @Override
- public void setConf(Configuration arg0) {
- }
- @Override
- public int run(String[] other) throws Exception {
- Configuration con = getConf();
- Job job = Job.getInstance(con);
- job.setJarByClass(Frame.class);
- job.setMapperClass(MyMapper.class);
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(Text.class);
- //默认分区
- job.setPartitionerClass(HashPartitioner.class);
- job.setReducerClass(MyReduce.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- FileInputFormat.addInputPath(job, new Path(other[0]));
- FileOutputFormat.setOutputPath(job, new Path(other[1]));
- return job.waitForCompletion(true) ? 0 : 1;
- }
- }
三.MapReduce的分区
- package com.huhu.day03;
- import java.io.IOException;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
- import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
- import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
- import org.apache.hadoop.util.GenericOptionsParser;
- import org.apache.hadoop.util.Tool;
- import org.apache.hadoop.util.ToolRunner;
- /**
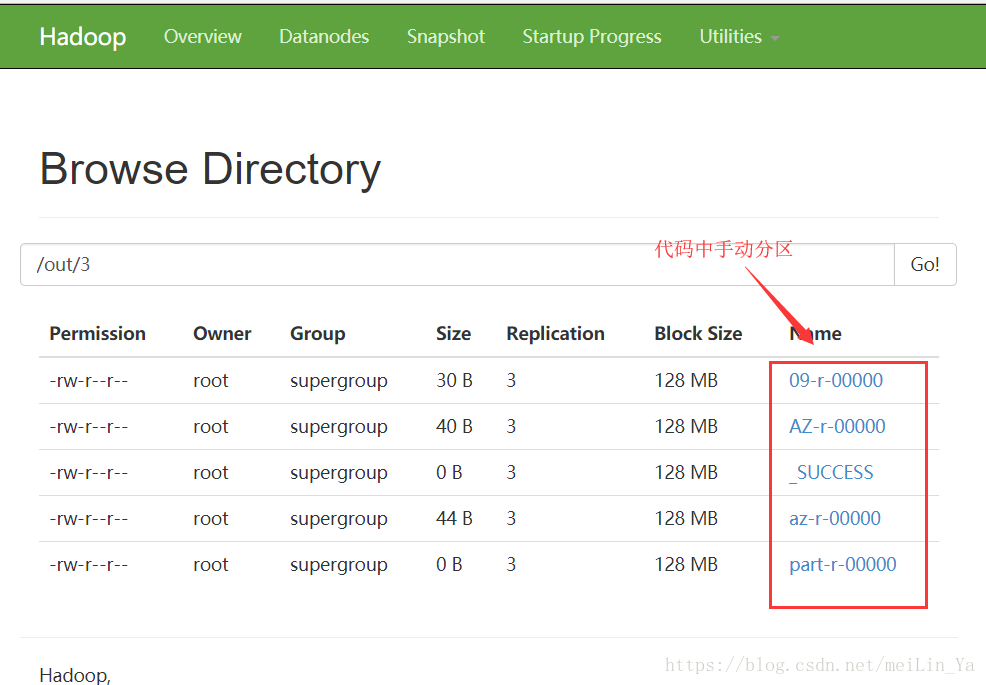
- * 手动分区
- *
- * @author huhu_k
- *
- */
- public class ManualPartition extends ToolRunner implements Tool {
- private Configuration conf;
- public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
- @Override
- protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- String[] line = value.toString().split(" ");
- for (String s : line) {
- context.write(new Text(s), new IntWritable(1));
- }
- }
- }
- public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
- private MultipleOutputs<Text, IntWritable> mos;
- @Override
- protected void setup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
- throws IOException, InterruptedException {
- mos = new MultipleOutputs<>(context);
- }
- @Override
- protected void reduce(Text key, Iterable<IntWritable> values, Context context)
- throws IOException, InterruptedException {
- int sum = 0;
- for (IntWritable v : values) {
- sum += v.get();
- }
- if (key.toString().substring(0, 1).matches("[a-z]")) {
- mos.write("az", key.toString(), new IntWritable(sum));
- } else if (key.toString().substring(0, 1).matches("[A-Z]")) {
- mos.write("AZ", key.toString(), new IntWritable(sum));
- } else if (key.toString().substring(0, 1).matches("[0-9]")) {
- mos.write("09", key.toString(), new IntWritable(sum));
- } else {
- mos.write("default", key.toString(), new IntWritable(sum));
- }
- }
- @Override
- protected void cleanup(Context context) throws IOException, InterruptedException {
- // 很重要 -->因为mos类时一个类似的缓冲区 hdfs可以写 更改 追加写
- mos.close();
- }
- }
- public static void main(String[] args) throws Exception {
- ManualPartition t = new ManualPartition();
- Configuration conf = t.getConf();
- String[] other = new GenericOptionsParser(conf, args).getRemainingArgs();
- if (other.length != 2) {
- System.err.println("number is fail");
- }
- int run = ToolRunner.run(conf, t, args);
- System.exit(run);
- }
- @Override
- public Configuration getConf() {
- if (conf != null) {
- return conf;
- }
- return new Configuration();
- }
- @Override
- public void setConf(Configuration arg0) {
- }
- @Override
- public int run(String[] other) throws Exception {
- Configuration con = getConf();
- Job job = Job.getInstance(con);
- job.setJarByClass(ManualPartition.class);
- job.setMapperClass(MyMapper.class);
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(IntWritable.class);
- // 默认分区
- job.setPartitionerClass(HashPartitioner.class);
- job.setReducerClass(MyReduce.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- FileInputFormat.addInputPath(job, new Path(other[0]));
- FileOutputFormat.setOutputPath(job, new Path(other[1]));
- // 手动分区
- MultipleOutputs.addNamedOutput(job, "az", TextOutputFormat.class, Text.class, IntWritable.class);
- MultipleOutputs.addNamedOutput(job, "AZ", TextOutputFormat.class, Text.class, IntWritable.class);
- MultipleOutputs.addNamedOutput(job, "09", TextOutputFormat.class, Text.class, IntWritable.class);
- MultipleOutputs.addNamedOutput(job, "default", TextOutputFormat.class, Text.class, IntWritable.class);
- return job.waitForCompletion(true) ? 0 : 1;
- }
- }
- package com.huhu.day03.partitioner;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Partitioner;
- public class WordCountAUTOPartitioner extends Partitioner<Text, IntWritable> {
- @Override
- public int getPartition(Text key, IntWritable value, int numPartitioner) {
- String firstChar = key.toString().substring(0, 1);
- if (firstChar.matches("[a-g]")) {
- //返回
- return 0 % numPartitioner;
- } else if (firstChar.matches("[h-z]")) {
- return 1 % numPartitioner;
- } else if (firstChar.matches("[0-5]")) {
- return 2 % numPartitioner;
- } else if (firstChar.matches("[6-9]")) {
- return 3 % numPartitioner;
- } else if (firstChar.matches("[A-G]")) {
- return 0 % numPartitioner;
- } else if (firstChar.matches("[H-Z]")) {
- return 5 % numPartitioner;
- } else {
- return 6 % numPartitioner;
- }
- }
- }
- package com.huhu.day03;
- import java.io.IOException;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- import org.apache.hadoop.util.Tool;
- import org.apache.hadoop.util.ToolRunner;
- import com.huhu.day03.partitioner.WordCountAUTOPartitioner;
- public class AutomaticPartition extends ToolRunner implements Tool {
- private Configuration conf;
- public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
- @Override
- protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- String[] line = value.toString().split(" ");
- for (String s : line) {
- context.write(new Text(s), new IntWritable(1));
- }
- }
- }
- public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
- @Override
- protected void setup(Context context) throws IOException, InterruptedException {
- }
- @Override
- protected void reduce(Text key, Iterable<IntWritable> values, Context context)
- throws IOException, InterruptedException {
- int sum = 0;
- for (IntWritable v : values) {
- sum += v.get();
- }
- context.write(key, new IntWritable(sum));
- }
- @Override
- protected void cleanup(Context context) throws IOException, InterruptedException {
- }
- }
- public static void main(String[] args) throws Exception {
- AutomaticPartition t = new AutomaticPartition();
- Configuration conf = t.getConf();
- String[] other = new GenericOptionsParser(conf, args).getRemainingArgs();
- if (other.length != 2) {
- System.err.println("number is fail");
- }
- int run = ToolRunner.run(conf, t, args);
- System.exit(run);
- }
- @Override
- public Configuration getConf() {
- if (conf != null) {
- return conf;
- }
- return new Configuration();
- }
- @Override
- public void setConf(Configuration arg0) {
- }
- @Override
- public int run(String[] other) throws Exception {
- Configuration con = getConf();
- Job job = Job.getInstance(con);
- job.setJarByClass(AutomaticPartition.class);
- job.setMapperClass(MyMapper.class);
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(IntWritable.class);
- // 默认分区
- // job.setPartitionerClass(HashPartitioner.class);
- // 自定义分区
- job.setPartitionerClass(WordCountAUTOPartitioner.class);
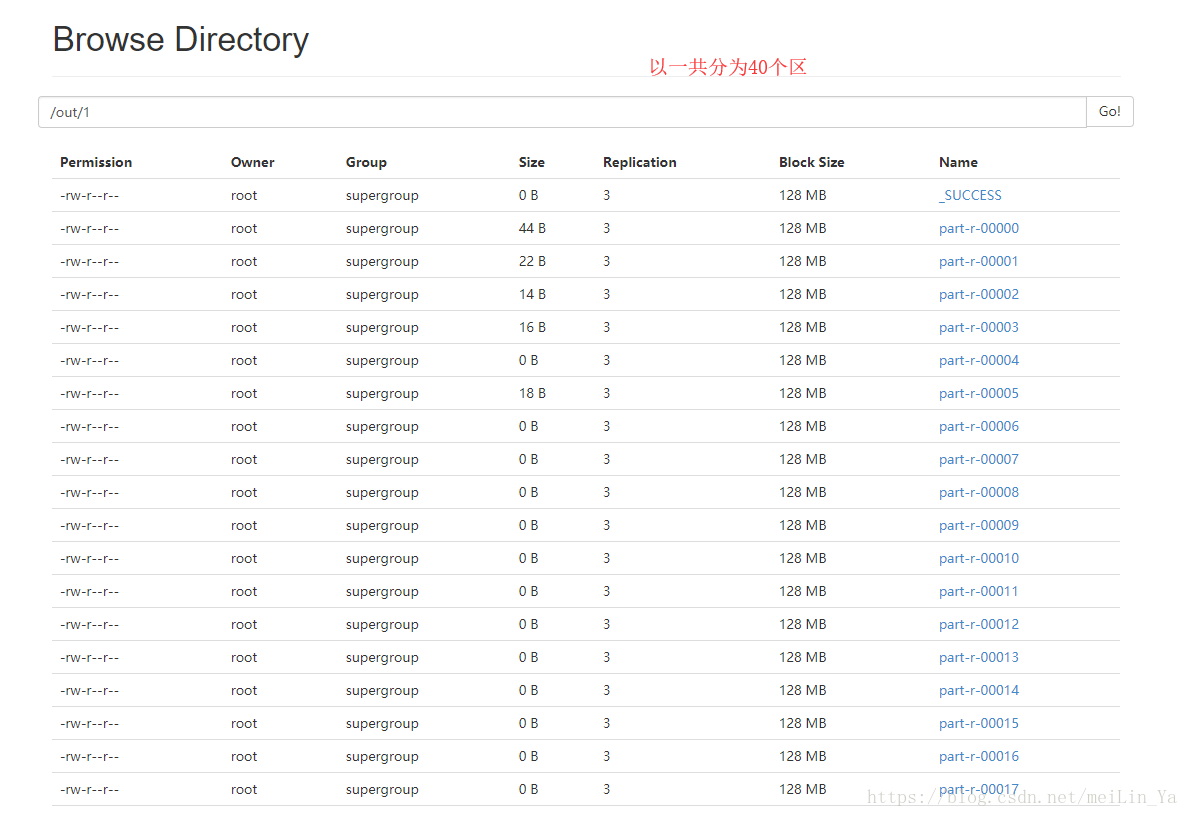
- // 分40个区
- job.setNumReduceTasks(40);
- job.setReducerClass(MyReduce.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- FileInputFormat.addInputPath(job, new Path(other[0]));
- FileOutputFormat.setOutputPath(job, new Path(other[1]));
- return job.waitForCompletion(true) ? 0 : 1;
- }
- }
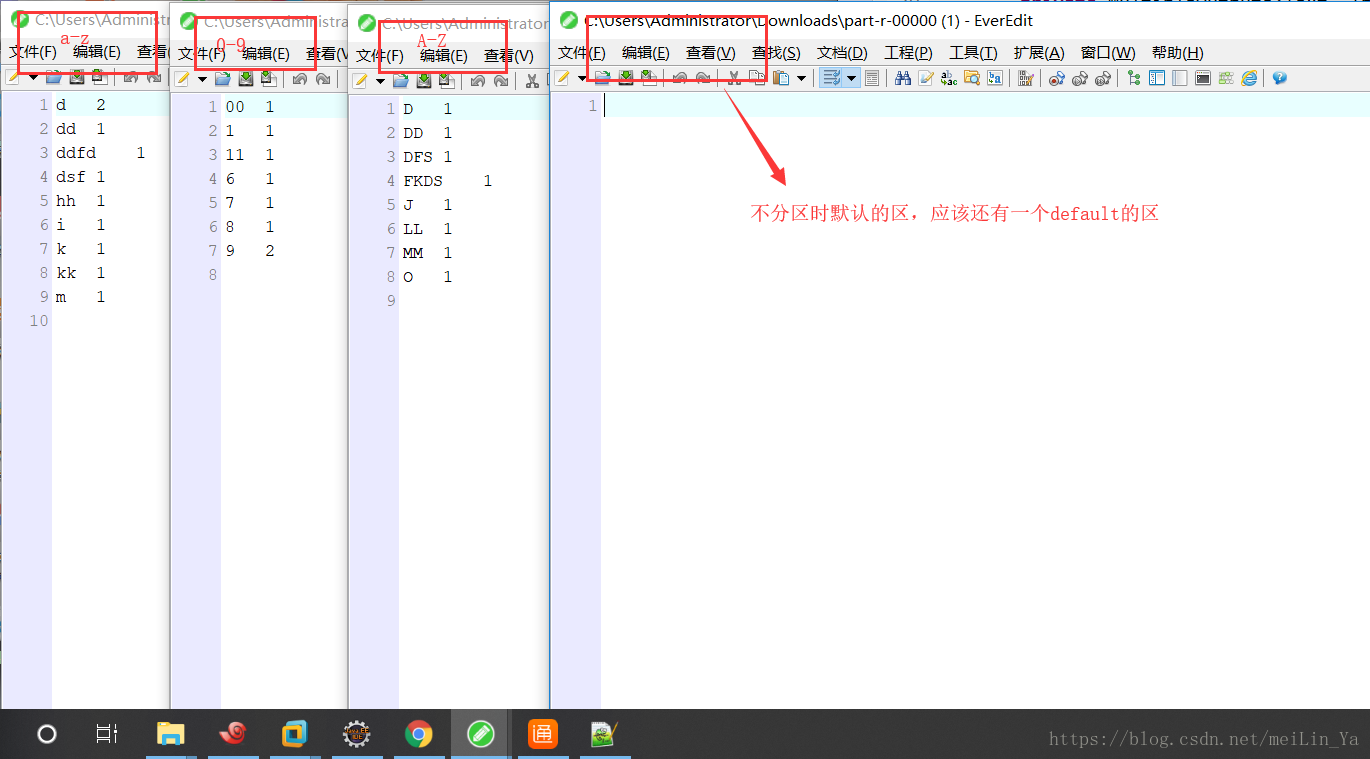
只有在我的分区类中设置的分区中有内容,别的没有,因为我没有设置
- package com.huhu.day03;
- import java.io.IOException;
- import java.util.Iterator;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
- import org.apache.hadoop.util.GenericOptionsParser;
- import org.apache.hadoop.util.Tool;
- import org.apache.hadoop.util.ToolRunner;
- import com.huhu.day03.group.ClassGroupSort;
- import com.huhu.day03.pojo.Student;
- public class StudentAutoGroup extends ToolRunner implements Tool {
- private Configuration conf;
- public static class MyMapper extends Mapper<LongWritable, Text, Student, Student> {
- @Override
- protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
- String[] line = value.toString().split(" ");
- Student s = new Student(line[0], line[1], Integer.parseInt(line[2]));
- context.write(s, s);
- }
- }
- public static class MyReduce extends Reducer<Student, Student, Text, IntWritable> {
- @Override
- protected void reduce(Student key, Iterable<Student> values, Context context)
- throws IOException, InterruptedException {
- int sum = 0;
- for (Student s : values) {
- sum += s.getSccore();
- }
- context.write(new Text(key.getGroup()), new IntWritable(sum));
- }
- }
- public static void main(String[] args) throws Exception {
- StudentAutoGroup t = new StudentAutoGroup();
- Configuration conf = t.getConf();
- String[] other = new GenericOptionsParser(conf, args).getRemainingArgs();
- if (other.length != 2) {
- System.err.println("number is fail");
- }
- int run = ToolRunner.run(conf, t, args);
- System.exit(run);
- }
- @Override
- public Configuration getConf() {
- if (conf != null) {
- return conf;
- }
- return new Configuration();
- }
- @Override
- public void setConf(Configuration arg0) {
- }
- @Override
- public int run(String[] other) throws Exception {
- Configuration con = getConf();
- Job job = Job.getInstance(con);
- job.setJarByClass(StudentAutoGroup.class);
- job.setMapperClass(MyMapper.class);
- job.setMapOutputKeyClass(Student.class);
- job.setMapOutputValueClass(Student.class);
- // 分组
- job.setCombinerKeyGroupingComparatorClass(ClassGroupSort.class);
- // job.setGroupingComparatorClass(ClassGroupSort.class);
- // 默认分区
- job.setPartitionerClass(HashPartitioner.class);
- job.setNumReduceTasks(1);
- job.setReducerClass(MyReduce.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- FileInputFormat.addInputPath(job, new Path(other[0]));
- FileOutputFormat.setOutputPath(job, new Path(other[1]));
- return job.waitForCompletion(true) ? 0 : 1;
- }
- }
- package com.huhu.day03.pojo;
- import java.io.DataInput;
- import java.io.DataOutput;
- import java.io.IOException;
- import org.apache.hadoop.io.WritableComparable;
- public class Student implements WritableComparable<Student> {
- private String name;
- private String group;
- private int sccore;
- public Student() {
- super();
- // TODO Auto-generated constructor stub
- }
- public Student(String name, String group, int sccore) {
- super();
- this.name = name;
- this.group = group;
- this.sccore = sccore;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getGroup() {
- return group;
- }
- public void setGroup(String group) {
- this.group = group;
- }
- public int getSccore() {
- return sccore;
- }
- public void setSccore(int sccore) {
- this.sccore = sccore;
- }
- @Override
- public String toString() {
- return "Student [name=" + name + ", group=" + group + ", sccore=" + sccore + "]";
- }
- @Override
- public void readFields(DataInput in) throws IOException {
- this.name = in.readUTF();
- this.group = in.readUTF();
- this.sccore = in.readInt();
- }
- @Override
- public void write(DataOutput out) throws IOException {
- out.writeUTF(name);
- out.writeUTF(group);
- out.writeInt(sccore);
- }
- @Override
- public int compareTo(Student o) {
- return this.group.compareTo(o.group);
- }
- }
- package com.huhu.day03.group;
- import org.apache.hadoop.io.RawComparator;
- import org.apache.hadoop.io.WritableComparator;
- import com.huhu.day03.pojo.Student;
- public class ClassGroupSort implements RawComparator<Student> {
- @Override
- public int compare(Student o1, Student o2) {
- return (int) (o1.getGroup().equals(o2.getGroup()) ? 0 : 1);
- }
- @Override
- public int compare(byte[] arg0, int arg1, int arg2, byte[] arg3, int arg4, int arg5) {
- return WritableComparator.compareBytes(arg0, arg1, 8, arg3, arg4, 8);
- }
- }

MapReduce的分区是对key的类型分:可以根据【a-z】【A-Z】【0-9】.....等等。是对reduce中的key来分的
MapReduce的分组则是忽略key:根据value来分的,比如你传入一个对象,根据对象的属性来比较,虽然传入的是不同的对象,但是只要属性相同,则可以对数据进行操作。
他们之所以又是分组又是分区,一则为了清洗数据,二则为了给数据排序。
MapReduce(三)的更多相关文章
- MapReduce三种join实例分析
本文引自吴超博客 实现原理 1.在Reudce端进行连接. 在Reudce端进行连接是MapReduce框架进行表之间join操作最为常见的模式,其具体的实现原理如下: Map端的主要工作:为来自不同 ...
- MapReduce三种路径输入
目前为止知道MapReduce有三种路径输入方式.1.第一种是通过一下方式输入: FileInputFormat.addInputPath(job, new Path(args[0]));FileIn ...
- MapReduce(三) 典型场景(一)
一.mapreduce多job串联 1.需求 一个稍复杂点的处理逻辑往往需要多个 mapreduce 程序串联处理,多 job 的串联可以借助 mapreduce 框架的 JobControl 实现 ...
- mapreduce (三) MapReduce实现倒排索引(二)
hadoop api http://hadoop.apache.org/docs/r1.0.4/api/org/apache/hadoop/mapreduce/Reducer.html 改变一下需求: ...
- 百度和 Google 的搜索技术是一个量级吗?
著作权归作者所有. 商业转载请联系作者获得授权,非商业转载请注明出处. 作者:Kenny Chao 链接:http://www.zhihu.com/question/22447908/answer/2 ...
- MongoDB中聚合工具Aggregate等的介绍与使用
Aggregate是MongoDB提供的众多工具中的比较重要的一个,类似于SQL语句中的GROUP BY.聚合工具可以让开发人员直接使用MongoDB原生的命令操作数据库中的数据,并且按照要求进行聚合 ...
- Hive的HQL语句及数据倾斜解决方案
[版权申明:本文系作者原创,转载请注明出处] 文章出处:http://blog.csdn.net/sdksdk0/article/details/51675005 作者: 朱培 ID ...
- Spark原理概述
原文来自我的个人网站:http://www.itrensheng.com/archives/Spark_basic_knowledge 一. Spark出现的背景 在Spark出现之前,大数据计算引擎 ...
- Apache Flink 如何正确处理实时计算场景中的乱序数据
一.流式计算的未来 在谷歌发表了 GFS.BigTable.Google MapReduce 三篇论文后,大数据技术真正有了第一次飞跃,Hadoop 生态系统逐渐发展起来. Hadoop 在处理大批量 ...
随机推荐
- Gym 100247C Victor's Research(有多少区间之和为S)
https://vjudge.net/problem/Gym-100247C 题意: 给出一串数,求有多少个区间的和正好等于S. 思路:计算处前缀和,并且用map维护一下每个前缀和出现的次数.这样接下 ...
- ASP.NET —— Web Pages
为简单起见,新建一个空的web工程,再新建一个MVC的视图(.cshtml),因为WP是单页面模型,所以以后就在这个页面中进行试验. Razor语法简介: 变量可用var或者其确切类型声明. 遍历fo ...
- _killerstreak
`count`连杀或终结连杀的数量(最大支持10个) `announceFlag` 0-不广播1-只广播连杀消息2-只广播终结连杀消息3-广播连杀与终结连杀消息 `rewId` 连杀奖励模板Id,对应 ...
- mysql / sqlserver / oracle 常见数据库分页
空闲时间里用着mysql学习开发测试平台和测试用具, 在公司里将可用的测试平台部署,将数据库换成sqlserver 巴望着能去用oracle的公司 mysql中的分页 limit是mysql的语法se ...
- Eclipse+maven 构建第一个简单的springmvc项目
先给出项目的目录: 在eclipse下使用maven构建第一个springmvc项目步骤如下: 1.创建maven project(此处默认你已了解maven),此处需要注意以下两点 2.创建完毕后会 ...
- 常见字符集&乱码问题
字符集 常用字符集分类 ASCII及其扩展字符集 作用:表语英语及西欧语言. 位数:ASCII是用7位表示的,能表示128个字符:其扩展使用8位表示,表示256个字符. 范围:ASCII从00到7F, ...
- 学习笔记41—ttest误区
1.grapPad软件里面双T结果和matlab,EXCEl里面双T结果一致时,设置如下:
- vscode 的tab与空格设置
为了python 的pep8 标准,把tab键输入从\t的制表符 转为4个空格. 1在vscode下边栏点击 “空格” 在上面选项里设置 使用空格缩进, 以及可以 将缩进转换为空格 2在“文件-> ...
- QTableWidget自定义表头QHeaderView加全选复选框
1 QTableWidget自定义表头QHeaderView加全选复选框 在使用QTableWidget时需要在表头添加全选复选框,但是默认的表头无法添加复选框,只能用图片画上去一个复 ...
- HDU 4804 Campus Design
HDU 4804 思路: 轮廓线dp #include<bits/stdc++.h> using namespace std; #define fi first #define se se ...