Streaming SQL for Apache Kafka
KSQL是基于Kafka的Streams API进行构建的流式SQL引擎,KSQL降低了进入流处理的门槛,提供了一个简单的、完全交互式的SQL接口,用于处理Kafka的数据。 KSQL是一套基于Apache 2.0许可开源的、分布式的、可扩展的、可靠的和实时的组件。支持多种流式操作,包括聚合(aggregate)、连接(join)、时间窗口(window)、会话(session)等等。KSQL的两个核心概念是流(Stream)和表(Table)【参见:http://www.cnblogs.com/tgzhu/p/7660838.html】,集成流和表,允许将代表当前状态的表与代表当前发生事件的流连接在一起。
KSQL项目介绍
事实上,KSQL与关系型数据库中的SQL还是有很大不同的。传统的SQL都是即时的一次性操作,不管是查询还是更新都是在当前的数据集上进行。KSQL的查询和更新是持续进行的,而且数据集可以源源不断地增加。简言之,KSQL所做的其实是转换操作,也就是流式处理。 项目目前还处于开发者预览阶段,在可预料的条件下,KSQL在实时监控、安全检测、在线数据集成、应用开发等场景拥有极大的潜力,具体介绍如下:
1、实时监控实时分析
CREATE TABLE error_counts AS
SELECT error_code, count(*)FROM monitoring_stream
WINDOW TUMBLING (SIZE 1 MINUTE)
WHERE type = 'ERROR'
其中的一个用途是定义定制的业务级度量,这些度量是实时计算的,您可以监视和警报,就像您的CPU负载一样。另一个用途是在KSQL中定义应用程序的正确性的概念,并检查它在生产过程中是否会遇到这个问题。通常,当我们想到监控时,我们会想到计数器和仪表跟踪低水平的性能统计。这些类型的测量器通常可以告诉你CPU负载很高,但是它们不能真正告诉你你的应用程序是否在做它应该做的事情。KSQL允许从应用程序生成的原始事件流中定义定制指标,无论它们是日志事件、数据库更新还是其他类型的事件。
例如,一个web应用程序可能需要检查,每次新客户注册一个受欢迎的电子邮件,创建一个新的用户记录,并且他们的信用卡被计费。这些功能可能分布在不同的服务或应用程序中,您可能希望监视每个新客户在SLA中发生的每一件事,比如30秒。
2、安全性和异常检测
CREATE STREAM possible_fraud AS
SELECT card_number, count(*)
FROM authorization_attempts
WINDOW TUMBLING (SIZE 5 SECONDS)
GROUP BY card_number
HAVING count(*) > 3;
KSQL把事件流转换成包含数值的时间序列数据,通过可视化工具把这些数据展示在UI上,可以检测到很多威胁安全的行为,比如欺诈、入侵等等
3、在线数据集成
CREATE STREAM vip_users AS
SELECT userid, page, action
FROM clickstream c
LEFT JOIN users u ON c.userid = u.user_id
WHERE u.level = 'Platinum';
大部分的数据处理都会经历 ETL(Extract—Transform—Load)这样的过程,而这样的系统通常都是通过定时的批次作业来完成数据处理的,但批次作业所带来的延时在很多时候是无法被接受的。而通过使用 KSQL 和 Kafka 连接器,可以将批次数据集成转变成在线数据集成。比如,通过流与表的连接,可以用存储在数据表里的元数据来填充事件流里的数据,或者在将数据传输到其他系统之前过滤掉数据里的敏感信息。
4、应用开发
对于复杂的应用来说,使用 Kafka 的原生 Streams API 或许会更合适。不过,对于简单的应用来说,或者对于不喜欢 Java 编程的人来说,KSQL 会是更好的选择。
KSQL架构
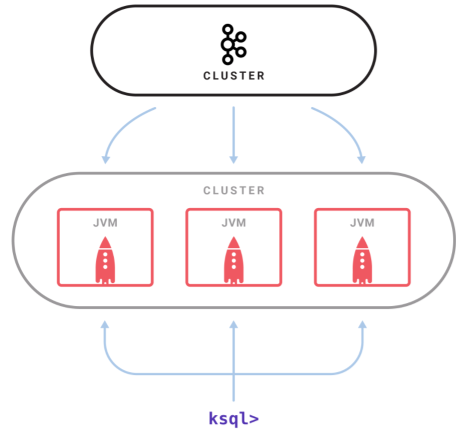
- KSQL 是一个独立运行的服务器,多个 KSQL 服务器可以组成集群,可以动态地添加服务器实例。
- 集群具有容错机制,如果一个服务器失效,其他服务器就会接管它的工作。
- KSQL 命令行客户端通过 REST API 向集群发起查询操作,可以查看流和表的信息、查询数据以及查看查询状态。
- 因为是基于 Streams API 构建的,所以 KSQL 也沿袭了 Streams API 的弹性、状态管理和容错能力,同时也具备了仅一次(exactly once)语义。KSQL 服务器内嵌了这些特性,并增加了一个分布式 SQL 引擎、用于提升查询性能的自动字节码生成机制,以及用于执行查询和管理的 REST API。
KSQL中的核心抽象
KSQL在内部使用Kafka的Streams API,并且它们共享与Kafka流处理相同的核心抽象。 KSQL有两个核心抽象,它们映射到Kafka Streams中的两个核心抽象,并允许您操纵Kafka主题:
1、流:流是无限制的结构化数据序列(“事实”)。 示例 :一个金融交易流,“Alice向Bob发送了100美元,然后查理向鲍勃发送了50美元”。 流中的事实是不可变的,这意味着可以将新事实插入到流中,但是现有事实永远不会被更新或删除。 流可以从Kafka主题创建,或者从现有的流和表中派生。
CREATE STREAM pageviews (viewtime BIGINT, userid VARCHAR, pageid VARCHAR)
WITH (kafka_topic='pageviews', value_format=’JSON’);
2、表:一个表是一个流或另一个表的视图,它代表了一个不断变化的事实的集合。示例 :一个包含最新财务信息的表, “Bob的经常帐户余额为$150”。它相当于传统的数据库表,但通过流化等流语义来丰富。表中的事实是可变的,这意味着可以将新的事实插入到表中,现有的事实可以被更新或删除。可以从Kafka主题中创建表,也可以从现有的流和表中派生表。
CREATE TABLE users (registertime BIGINT, gender VARCHAR, regionid VARCHAR, userid VARCHAR)
WITH (kafka_topic='users', value_format='DELIMITED');
KSQL简化了流应用程序,因为它完全集成了表和流的概念,允许使用表示现在发生的事件的流来连接表示当前状态的表。 Apache Kafka中的一个主题可以表示为KSQL中的STREAM或TABLE,具体取决于主题处理的预期语义。 例如,如果要将主题中的数据作为一系列独立值读取,则可以使用CREATE STREAM。此类流的一个例子是捕获页面视图事件,其中每个页面视图事件都不相关且独立于另一个页面视图事件。另一方面,如果您希望将某个主题中的数据读取为可更新的值的集合,那么您将使用CREATE TABLE。在KSQL中应该读取一个主题的示例,它捕获用户元数据,其中每个事件代表特定用户id的最新元数据,如用户的姓名、地址或首选项。
参考资料:
- https://github.com/confluentinc/ksql
- https://www.confluent.io/product/ksql/
- http://geek.csdn.net/news/detail/235801
Streaming SQL for Apache Kafka的更多相关文章
- KSQL: Streaming SQL for Apache Kafka
Few weeks back, while I was enjoying my holidays in the south of Italy, I started receiving notifica ...
- Introducing KSQL: Streaming SQL for Apache Kafka
Update: KSQL is now available as a component of the Confluent Platform. I’m really excited to announ ...
- 重磅开源 KSQL:用于 Apache Kafka 的流数据 SQL 引擎 2017.8.29
Kafka 的作者 Neha Narkhede 在 Confluent 上发表了一篇博文,介绍了Kafka 新引入的KSQL 引擎——一个基于流的SQL.推出KSQL 是为了降低流式处理的门槛,为处理 ...
- How Cigna Tuned Its Spark Streaming App for Real-time Processing with Apache Kafka
Explore the configuration changes that Cigna’s Big Data Analytics team has made to optimize the perf ...
- Offset Management For Apache Kafka With Apache Spark Streaming
An ingest pattern that we commonly see being adopted at Cloudera customers is Apache Spark Streaming ...
- 1.1 Introduction中 Apache Kafka™ is a distributed streaming platform. What exactly does that mean?(官网剖析)(博主推荐)
不多说,直接上干货! 一切来源于官网 http://kafka.apache.org/documentation/ Apache Kafka™ is a distributed streaming p ...
- Apache Kafka® is a distributed streaming platform
Kafka Connect简介 我们知道过去对于Kafka的定义是分布式,分区化的,带备份机制的日志提交服务.也就是一个分布式的消息队列,这也是他最常见的用法.但是Kafka不止于此,打开最新的官网. ...
- Apache Kafka + Spark Streaming Integration
1.目标 为了构建实时应用程序,Apache Kafka - Spark Streaming Integration是最佳组合.因此,在本文中,我们将详细了解Kafka中Spark Streamin ...
- Stream Processing for Everyone with SQL and Apache Flink
Where did we come from? With the 0.9.0-milestone1 release, Apache Flink added an API to process rela ...
随机推荐
- vue框架搭建
1到网上下载node.js,安装,(新版node,包括了npm ).2下载Git安装.3.你需要的地方建一个文件夹.打开cmd,跳转到这个文件夹输入npm install -g vue-cli 完成 ...
- extjs技术
转载:http://www.cnblogs.com/willick/p/3168809.html 转载 :http://www.cnblogs.com/youring2/archive/2013/08 ...
- ES6 函数的扩展-rest参数
ES6 引入 rest 参数(形式为...变量名),用于获取函数的多余参数,这样就不需要使用arguments对象了.rest 参数搭配的变量是一个数组,该变量将多余的参数放入数组中. functio ...
- linux 编译链接问题
-rpath和-rpath-link 假设有3个文件,在同一目录下,有这样的依赖关系 test->liba.so->libd.so 如果编译test的时候这样写 gcc test.c –l ...
- Windows 下使用nginx命令启动
http://wanganwu.blog.163.com/blog/static/7788722012322111417966/ Windows下Nginx的启动.停止等命令 在Windows下使用N ...
- JDK8 特性详解
Base64 对Base64编码的支持已经被加入到Java 8官方库中,这样不需要使用第三方库就可以进行Base64编码,例子代码如下: package com.cn.yunliu.jdk8; imp ...
- HDU 2058:The sum problem(数学)
The sum problem Time Limit: 5000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- eclipse + cdt
Window > Preferences > General > Appearance中设置主题颜色. Help > eclipse marketplace > find ...
- c#接口与虚函数的实验报告
1)定义Student类,用string型变量name存储学生姓名,用int型变量age存储学生年龄.Student类实现IComparable接口.要求从键盘输入学生的姓名和年龄,并注意可能出现的异 ...
- CF643D Bearish Fanpages
题意 英文版题面 Problems Submit Status Standings Custom test .input-output-copier { font-size: 1.2rem; floa ...