Consistent hashing
What is libconhash
libconhash is a consistent hashing library which can be compiled both on Windows and Linux platforms, with the following features:
- High performance and easy to use, libconhash uses a red-black tree to manage all nodes to achieve high performance.
- By default, it uses the MD5 algorithm, but it also supports user-defined hash functions.
- Easy to scale according to the node's processing capacity.
Consistent hashing
Why you need consistent hashing
Now we will consider the common way to do load balance. The machine number chosen to cache object o will be:
hash(o) mod n
Here, n is the total number of cache machines. While this works well until you add or remove cache machines:
- When you add a cache machine, then object o will be cached into the machine:
hash(o) mod (n+1)
- When you remove a cache machine, then object o will be cached into the machine:
Hide Copy Code
hash(o) mod (n-1)
So you can see that almost all objects will hashed into a new location. This will be a disaster since the originating content servers are swamped with requests from the cache machines. And this is why you need consistent hashing.
Consistent hashing can guarantee that when a cache machine is removed, only the objects cached in it will be rehashed; when a new cache machine is added, only a fairly few objects will be rehashed.
Now we will go into consistent hashing step by step.
Hash space
Commonly, a hash function will map a value into a 32-bit key, 0~2^32-1. Now imagine mapping the range into a circle, then the key will be wrapped, and 0 will be followed by 2^32-1, as illustrated in figure 1.

Map object into hash space
Now consider four objects: object1~object4. We use a hash function to get their key values and map them into the circle, as illustrated in figure 2.

hash(object1) = key1;
.....
hash(object4) = key4;
Map the cache into hash space
The basic idea of consistent hashing is to map the cache and objects into the same hash space using the same hash function.
Now consider we have three caches, A, B and C, and then the mapping result will look like in figure 3.
hash(cache A) = key A;
....
hash(cache C) = key C;

Map objects into cache
Now all the caches and objects are hashed into the same space, so we can determine how to map objects into caches. Take object obj for example, just start from where obj is and head clockwise on the ring until you find a server. If that server is down, you go to the next one, and so forth. See figure 3 above.
According to the method, object1 will be cached into cache A; object2 and object3 will be cached into cache C, and object4 will be cached into cache B.
Add or remove cache
Now consider the two scenarios, a cache is down and removed; and a new cache is added.
If cache B is removed, then only the objects that cached in B will be rehashed and moved to C; in the example, see object4 illustrated in figure 4.

If a new cache D is added, and D is hashed between object2 and object3 in the ring, then only the objects that are between D and B will be rehashed; in the example, see object2, illustrated in figure 5.

Virtual nodes
It is possible to have a very non-uniform distribution of objects between caches if you don't deploy enough caches. The solution is to introduce the idea of "virtual nodes".
Virtual nodes are replicas of cache points in the circle, each real cache corresponds to several virtual nodes in the circle; whenever we add a cache, actually, we create a number of virtual nodes in the circle for it; and when a cache is removed, we remove all its virtual nodes from the circle.
Consider the above example. There are two caches A and C in the system, and now we introduce virtual nodes, and the replica is 2, then three will be 4 virtual nodes. Cache A1 and cache A2 represent cache A; cache C1 and cache C2 represent cache C, illustrated as in figure 6.

Then, the map from object to the virtual node will be:
objec1->cache A2; objec2->cache A1; objec3->cache C1; objec4->cache C2
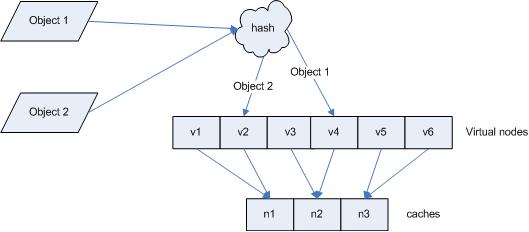
When you get the virtual node, you get the cache, as in the above figure.
So object1 and object2 are cached into cache A, and object3 and object4 are cached into cache. The result is more balanced now.
So now you know what consistent hashing is.
Using the code
Interfaces of libconhash
/* initialize conhash library
* @pfhash : hash function, NULL to use default MD5 method
* return a conhash_s instance
*/
CONHASH_API struct conhash_s* conhash_init(conhash_cb_hashfunc pfhash); /* finalize lib */
CONHASH_API void conhash_fini(struct conhash_s *conhash); /* set node */
CONHASH_API void conhash_set_node(struct node_s *node,
const char *iden, u_int replica); /*
* add a new node
* @node: the node to add
*/
CONHASH_API int conhash_add_node(struct conhash_s *conhash,
struct node_s *node); /* remove a node */
CONHASH_API int conhash_del_node(struct conhash_s *conhash,
struct node_s *node);
... /*
* lookup a server which object belongs to
* @object: the input string which indicates an object
* return the server_s structure, do not modify the value,
* or it will cause a disaster
*/
CONHASH_API const struct node_s*
conhash_lookup(const struct conhash_s *conhash,
const char *object);
Libconhash is very easy to use. There is a sample in the project that shows how to use the library.
First, create a conhash instance. And then you can add or remove nodes of the instance, and look up objects.
The update node's replica function is not implemented yet.
/* init conhash instance */
struct conhash_s *conhash = conhash_init(NULL);
if(conhash)
{
/* set nodes */
conhash_set_node(&g_nodes[0], "titanic", 32);
/* ... */ /* add nodes */
conhash_add_node(conhash, &g_nodes[0]);
/* ... */
printf("virtual nodes number %d\n", conhash_get_vnodes_num(conhash));
printf("the hashing results--------------------------------------:\n"); /* lookup object */
node = conhash_lookup(conhash, "James.km");
if(node) printf("[%16s] is in node: [%16s]\n", str, node->iden);
}
Reference
License
This article, along with any associated source code and files, is licensed under The BSD License
Consistent hashing的更多相关文章
- Consistent hashing —— 一致性哈希
原文地址:http://www.codeproject.com/Articles/56138/Consistent-hashing 基于BSD License What is libconhash l ...
- 一致性 hash 算法( consistent hashing )a
一致性 hash 算法( consistent hashing ) 张亮 consistent hashing 算法早在 1997 年就在论文 Consistent hashing and rando ...
- 一致性哈希算法 - consistent hashing
1 基本场景比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 ...
- 一致性 hash 算法( consistent hashing )
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在cache 系统中应用越来越广泛: 1 基 ...
- 【转】一致性hash算法(consistent hashing)
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛: 1 ...
- Consistent Hashing算法-搜索/负载均衡
在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin).哈希算法(HASH).最少连接算法(Least Connection).响应速度算法(Respons ...
- 一致性hash算法 - consistent hashing
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛: 1 ...
- Consistent Hashing原理与实现
原理介绍: consistent hashing原理介绍来自博客:http://blog.csdn.net/sparkliang/article/details/5279393, 多谢博主的分享 co ...
- 一致性哈希算法(consistent hashing)样例+測试。
一个简单的consistent hashing的样例,非常easy理解. 首先有一个设备类,定义了机器名和ip: public class Cache { public String name; pu ...
- _00013 一致性哈希算法 Consistent Hashing 新的讨论,并出现相应的解决
笔者博文:妳那伊抹微笑 博客地址:http://blog.csdn.net/u012185296 个性签名:世界上最遥远的距离不是天涯,也不是海角,而是我站在妳的面前.妳却感觉不到我的存在 技术方向: ...
随机推荐
- iOS多线程与网络开发之NSURLCache
郝萌主倾心贡献,尊重作者的劳动成果.请勿转载. // 2 // ViewController.m 3 // NSURLCacheDemo 4 // 5 // Created by haomengzhu ...
- 折腾gcc/g++链接时.o文件及库的顺序问题(转)
转自: http://www.cnblogs.com/OCaml/archive/2012/06/18/2554086.html#sec-1-1 折腾gcc/g++链接时.o文件及库的顺序问题 Tab ...
- Python 集合常用方法总结
数据类型:int/str/bool/list/dict/tuple/float/set (set类型天生去重) 一.集合的定义 s = set() #定义空集合 s = {'a','b','c' ...
- [Delphi] 常用字符集简介
转载 http://www.cnblogs.com/yangyxd/articles/4778483.html 字符集 ANSI (ASCII)美国信息互换标准编码 GB 2312信息交换用汉字编码字 ...
- 0050 MyBatis关联映射--一对多关系
一对多关系更加常见,比如用户和订单,一个用户可以有多个订单 DROP TABLE IF EXISTS customer; /*用户表*/ CREATE TABLE customer( `pk` INT ...
- C++忽略字符大小写比较
在项目中用到对两个字符串进行忽略大小写的比较,有两个方法实现 1.使用C++提供的忽略大小写比较函数实现 代码实现: /* 功能 :忽略大小写进行字符串比较 */ #ifdef __LINUX__ # ...
- 【问题记录】shiro logout UnknownSessionException
问题描述:web项目中使用shiro做登录权限控制,当shiro执行logout后,直接返回一个jsp路径会抛出org.apache.shiro.session.UnknownSessionExcep ...
- hdu3879 Base Station 最大权闭合子图 边权有正有负
/** 题目:hdu3879 Base Station 最大权闭合子图 边权有正有负 链接:http://acm.hdu.edu.cn/showproblem.php?pid=3879 题意:给出n个 ...
- xaf 学习 RuleUniqueValueAttribute 唯一验证。
xaf 学习 RuleUniqueValueAttribute 唯一验证. RuleUniqueValue("", DefaultContexts.Save, CriteriaE ...
- 临界区(Critical Section)的封装和使用示例
向我老大致敬! 这个做法其实是抄我老大的.服务器中,多线程经常需要使用临界区,为了简化代码的使用,把临界区封装为 CThreadLockHandle 类,通过封装,使用临界区资源每次只需要一行代码, ...