推荐系统中的SVD
本文主要参考:Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model
在用户对自己需求相对明确的时候,用搜索引擎很方便的通过关键字搜索很快的找到自己需要的信息。但搜索引擎并不能完全满足用户对信息发现的需求,那是因为在很多情况下,用户其实并不明确自己的需要,或者他们的需求很难用简单的关键字来表述。又或者他们需要更加符合他们个人口味和喜好的结果,因此出现了推荐系统,与搜索引擎对应,大家也习惯称它为推荐引擎。
推荐系统通常依赖于协同过滤(Collaborative Filtering),从海量数据中发掘出一小部分与你口味相近的产品推荐给你。本文主要介绍协同过滤的两种方式: 隐语义模型(Latent factor models)和邻域模型(neighborhood model).
Neighborhood model
首先考虑基于邻域的协同过滤模型, 加入baseline 估计

这是考虑在实际情况下,一个评分系统有些固有属性和用户物品无关,而用户也有些属性和物品无关,物品也有些属性和用户无关。因此,μ为训练集中所有记录的评分的全局平均数,表示网站本身对用户评分的影响。 bu 为用户偏置项,表示在用户评分习惯中和物品无关的因素,如有些用户偏苛刻,普遍评分较低而有些用户比较宽容,评分偏高。 bi 为物品偏置项,表示物品接受评分中和用户无关的因素,例如物品本身质量很高,因此获得评分普遍比较高。

cij 与 wij 类似,对于两个物品i和j,一个用户u对物品j的正隐性反馈信息会在模型中修正预测值 rui ,给出一个更高的预测值。将这些权值视为baseline的偏移,而非基于用户或者基于项目的系数,便强化了缺失评分值的影响,即用户的预测评分不仅与其评分历史数据相关,同时与他未评分的物品相关,特别是那些相对热门,而用户并未评分的物品。例如,假设一个电影评分数据集显示那些对"指环王3"评分较高的用户通常对"指环王1-2"的评分也相对较高,这就使得"指环王3"与"指环王1-2"之间有很高的权值。假设一个用户没有对"指环王1-2"进行评分,那么他对"指环王3"的预测评分会变低,因为相应的权值 cij 在模型中为0。
利用这个模型预测出来的值有时候会不怎么精确,即得出来的结果非0即1.为此我们需要对结果进行平滑处理,如下式:

其中R(u)代表显示因子,N(u)是隐式因子,例如R(u)为某用户打过评分的电影,N(u)是某用户看过但没有评分的电影。
但如果用户看过很多电影的情况下,对上述模型进行训练,复杂度会增加。而其实我们可以只保留相似度最高的k部电影来训练,相似度的评估可以用余弦定理求得。得到最终的预测公式:

现在使用随机梯度下降(Stochastic gradient descent)来最小化下式


其中e_ui是真实值r_ui与预测值的差值。
Latent factor model
Latent factor model中比较著名的算法即SVD,对于一个给定的用户行为数据集(数据集包含的是所有的user, 所有的item,以及每个user有过行为的item列表),使用LFM对其建模后,我们可以得到如下图所示的模型:
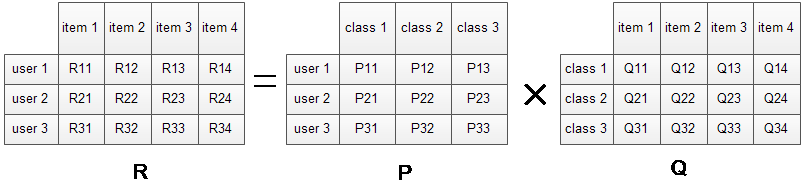
R矩阵是user-item矩阵,矩阵值Rij表示的是user i 对item j的兴趣度,这正是我们要求的值。对于一个user来说,当计算出他对所有item的兴趣度后,就可以进行排序并作出推荐。LFM算法从数据集中抽取出若干主题,作为user和item之间连接的桥梁,将R矩阵表示为P矩阵和Q矩阵相乘。其中P矩阵是user-class矩阵,矩阵值Pij表示的是user i对class j的兴趣度;Q矩阵式class-item矩阵,矩阵值Qij表示的是item j在class i中的权重,权重越高越能作为该类的代表。所以LFM根据如下公式来计算用户U对物品I的兴趣度。

我们在上述式子中加入上文提到的N(u),得到:

这个就是SVD++了,里面的y叫做implicit feedback factor,为这个值的意思google了好久,囧。
下面是对于这两种方法的优缺点,英文不好,无法用中文准确的表达出来……。
Neighborhood models are most effective at detecting very localized relationships. They rely on a few significant neighborhood relations, often ignoring the vast majority of ratings by a user. Consequently ,these methods are unable to capture the totality of weak signals encompassed in all of a user's ratings. Latent factor models are generally effective at estimating overall structure that relates simultaneously to most or all items. However, these models are poor at detecting strong associations among a small set of closely related items, precisely where neighborhood models do best.
根据两者的优缺点,我们把它们联合起来训练得到:

相应的梯度下降:

最后介绍下当前的推荐系统实际应用。
以Amazon为例,作为推荐引擎的鼻祖,它已经将推荐的思想渗透在应用的各个角落。Amazon 推荐的核心是通过数据挖掘算法和比较用户的消费偏好于其他用户进行对比,借以预测用户可能感兴趣的商品。对应于上面介绍的各种推荐机制,Amazon 采用的是分区的混合的机制,并将不同的推荐结果分不同的区显示给用户,下凸展示了用户在 Amazon 上能得到的推荐。


Amazon 利用可以记录的所有用户在站点上的行为,根据不同数据的特点对它们进行处理,并分成不同区为用户推送推荐:
今日推荐 (Today's Recommendation For You): 通常是根据用户的近期的历史购买或者查看记录,并结合时下流行的物品给出一个折中的推荐。
新产品的推荐 (New For You): 采用了基于内容的推荐机制 (Content-based Recommendation),将一些新到物品推荐给用户。在方法选择上由于新物品没有大量的用户喜好信息,所以基于内容的推荐能很好的解决这个"冷启动"的问题。
捆绑销售 (Frequently Bought Together): 采用数据挖掘技术对用户的购买行为进行分析,找到经常被一起或同一个人购买的物品集,进行捆绑销售,这是一种典型的基于项目的协同过滤推荐机制。
别人购买 / 浏览的商品 (Customers Who Bought/See This Item Also Bought/See): 这也是一个典型的基于项目的协同过滤推荐的应用,通过社会化机制用户能更快更方便的找到自己感兴趣的物品。
值得一提的是,Amazon 在做推荐时,设计和用户体验也做得特别独到:
Amazon 利用有它大量历史数据的优势,量化推荐原因。
基于社会化的推荐,Amazon 会给你事实的数据,让用户信服,例如:购买此物品的用户百分之多少也购买了那个物品;
基于物品本身的推荐,Amazon 也会列出推荐的理由,例如:因为你的购物框中有 ***,或者因为你购买过 ***,所以给你推荐类似的 ***。
另外,Amazon 很多推荐是基于用户的 profile 计算出来的,用户的 profile 中记录了用户在 Amazon 上的行为,包括看了那些物品,买了那些物品,收藏夹和 wish list 里的物品等等,当然 Amazon 里还集成了评分等其他的用户反馈的方式,它们都是 profile 的一部分,同时,Amazon 提供了让用户自主管理自己 profile 的功能,通过这种方式用户可以更明确的告诉推荐引擎他的品味和意图是什么。
推荐系统中的SVD的更多相关文章
- NMF和SVD在推荐系统中的应用(实战)
本文以NMF和经典SVD为例,讲一讲矩阵分解在推荐系统中的应用. 数据 item\user Ben Tom John Fred item 1 5 5 0 5 item 2 5 0 3 4 item 3 ...
- [机器学习笔记]奇异值分解SVD简介及其在推荐系统中的简单应用
本文先从几何意义上对奇异值分解SVD进行简单介绍,然后分析了特征值分解与奇异值分解的区别与联系,最后用python实现将SVD应用于推荐系统. 1.SVD详解 SVD(singular value d ...
- SVD及其在推荐系统中的作用
本文先从几何意义上对奇异值分解SVD进行简单介绍,然后分析了特征值分解与奇异值分解的区别与联系,最后用python实现将SVD应用于推荐系统. 1.SVD详解 SVD(singular value d ...
- 多维数组分解----SVD在推荐系统中的应用-
http://www.janscon.com/multiarray/rs_used_svd.html [声明]本文主要参考自论文<A SINGULAR VALUE DECOMPOSITION A ...
- SVD在餐馆菜肴推荐系统中的应用
SVD在餐馆菜肴推荐系统中的应用 摘要:餐馆可以分为很多类别,比如中式.美式.日式等等.但是这些类别不一定够用,有的人喜欢混合类别.对用户对菜肴的点评数据进行分析,可以提取出区分菜品的真正因素,利用这 ...
- SVD在推荐系统中的应用详解以及算法推导
SVD在推荐系统中的应用详解以及算法推导 出处http://blog.csdn.net/zhongkejingwang/article/details/43083603 前面文章SVD原理及推 ...
- SVD在推荐系统中的应用
一.奇异值分解SVD 1.SVD原理 SVD将矩阵分为三个矩阵的乘积,公式: 中间矩阵∑为对角阵,对角元素值为Data矩阵特征值λi,且已经从大到小排序,即使去掉特征值小的那些特征,依然可以很好地重构 ...
- RS:推荐系统中的数据稀疏和冷启动问题
如何在没有大量用户数据的情况下设计个性化推荐系统并且让用户对推荐结果满意从而愿意使用推荐系统,就是冷启动问题. 冷启动问题主要分为三类: (1) 用户冷启动:如何给新用户做个性化推荐的问题,新用户刚使 ...
- 14、RALM: 实时 look-alike 算法在推荐系统中的应用
转载:https://zhuanlan.zhihu.com/p/71951411 RALM: 实时 look-alike 算法在推荐系统中的应用 0. 导语 本论文题为<Real-time At ...
随机推荐
- oracle中有关表的操作
在Oracle中查看所有的表: select * from tab/dba_tables/dba_objects/cat; 看用户建立的表 : select table_name from user_ ...
- Python3 hashlib模块和hmac 模块(加密)
hashlib 是一个提供了一些流行的hash算法的 Python 标准库.其中所包括的算法有 md5, sha1, sha224, sha256, sha384, sha512等常用算法 MD5加密 ...
- 手動設定 電池溫度 mtk platform
adb root adb shell echo "3 1 27" > ./proc/mtk_battery_cmd/battery_cmd 27 即是所要設定的溫度, 此設定 ...
- python基础===两个list之间移动元素
首先我们先了解一下list的几个常用函数: a = [123,456,"tony","jack"] #list中增加元素a.append("www&q ...
- 再议perl写多线程端口扫描器
再议perl写多线程端口扫描器 http://blog.csdn.net/sx1989827/article/details/4642179 perl写端口多线程扫描器 http://blog.csd ...
- swift中闭包的循环引用
首先我们先创造一个循环引用 var nameB:(()->())? override func viewDidLoad() { super.viewDidLoad() let bu = UIBu ...
- vue页面高度填充,不出现滚动条
现在的需求是这样:vue单页工程化开发,上面有一个header,左边有一个侧边栏,右边内容展示.要求左边侧边栏的高度,要填充满整个页面(除了header外,header:height:60px)--如 ...
- CCF试题:高速公路(Targin)
问题描述 某国有n个城市,为了使得城市间的交通更便利,该国国王打算在城市之间修一些高速公路,由于经费限制,国王打算第一阶段先在部分城市之间修一些单向的高速公路. 现在,大臣们帮国王拟了一个修高速公路的 ...
- Edit Distance——经典的动态规划问题
题目描述Edit DistanceGiven two words word1 and word2, find the minimum number of steps required to conve ...
- 将Sphinx的日志放置到/dev/shm里需要注意的事情
可以采用定时器控制,清空日志的办法: 几种快速清空文件内容的方法: $ : > filename #其中的 : 是一个占位符, 不产生任何输出. $ > filename $ echo “ ...