HDFS的工作原理扫扫盲

Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的 机器上。它能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。要理解HDFS的内部工作原理,首先要理解什么是分布式文件系统。
<ignore_js_op>
分布式文件系统
多台计算机联网协同工作(有时也称为一个集群)就像单台系统一样解决某种问题,这样的系统我们称之为分布式系统。
分布式文件系统是分布式系统的一个子集,它们解决的问题就是数据存储。换句话说,它们是横跨在多台计算机上的存储系统。存储在分布式文件系统上的数据自动分布在不同的节点上。
分布式文件系统在大数据时代有着广泛的应用前景,它们为存储和处理来自网络和其它地方的超大规模数据提供所需的扩展能力。
分离元数据和数据:NameNode和DataNode
存储到文件系统中的每个文件都有相关联的元数据。元数据包括了文件名、i节点(inode)数、数据块位置等,而数据则是文件的实际内容。
在传统的文件系统里,因为文件系统不会跨越多台机器,元数据和数据存储在同一台机器上。
为了构建一个分布式文件系统,让客户端在这种系统中使用简单,并且不需要知道其他客户端的活动,那么元数据需要在客户端以外维护。HDFS的设计理念是拿出一台或多台机器来保存元数据,并让剩下的机器来保存文件的内容。
NameNode和DataNode是HDFS的两个主要组件。其中,元数据存储在NameNode上,而数据存储在DataNode的集群上。 NameNode不仅要管理存储在HDFS上内容的元数据,而且要记录一些事情,比如哪些节点是集群的一部分,某个文件有几份副本等。它还要决定当集群的节点宕机或者数据副本丢失的时候系统需要做什么。
存储在HDFS上的每份数据片有多份副本(replica)保存在不同的服务器上。在本质上,NameNode是HDFS的Master(主服务器),DataNode是Slave(从服务器)。
HDFS写过程
NameNode负责管理存储在HDFS上所有文件的元数据,它会确认客户端的请求,并记录下文件的名字和存储这个文件的DataNode集合。它把该信息存储在内存中的文件分配表里。
例如,客户端发送一个请求给NameNode,说它要将“zhou.log”文件写入到HDFS。那么,其执行流程如图1所示。具体为:
第一步:客户端发消息给NameNode,说要将“zhou.log”文件写入。(如图1中的①)第二步:NameNode发消息给客户端,叫客户端写到DataNode A、B和D,并直接联系DataNode B。(如图1中的②)
第三步:客户端发消息给DataNode B,叫它保存一份“zhou.log”文件,并且发送一份副本给DataNode A和DataNode D。(如图1中的③)
第四步:DataNode B发消息给DataNode A,叫它保存一份“zhou.log”文件,并且发送一份副本给DataNode D。(如图1中的④)
第五步:DataNode A发消息给DataNode D,叫它保存一份“zhou.log”文件。(如图1中的⑤)
第六步:DataNode D发确认消息给DataNode A。(如图1中的⑤)
第七步:DataNode A发确认消息给DataNode B。(如图1中的④)
第八步:DataNode B发确认消息给客户端,表示写入完成。(如图1中的⑥)
<ignore_js_op>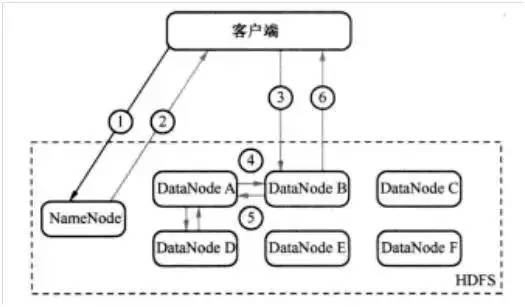
图1 HDFS写过程示意图
在分布式文件系统的设计中,挑战之一是如何确保数据的一致性。对于HDFS来说,直到所有要保存数据的DataNodes确认它们都有文件的副本 时,数据才被认为写入完成。因此,数据一致性是在写的阶段完成的。一个客户端无论选择从哪个DataNode读取,都将得到相同的数据。
HDFS读过程
为了理解读的过程,可以认为一个文件是由存储在DataNode上的数据块组成的。客户端查看之前写入的内容的执行流程如图2所示,具体步骤为:
第一步:客户端询问NameNode它应该从哪里读取文件。(如图2中的①)
第二步:NameNode发送数据块的信息给客户端。(数据块信息包含了保存着文件副本的DataNode的IP地址,以及DataNode在本地硬盘查找数据块所需要的数据块ID。) (如图2中的②)
第三步:客户端检查数据块信息,联系相关的DataNode,请求数据块。(如图2中的③)
第四步:DataNode返回文件内容给客户端,然后关闭连接,完成读操作。(如图2中的④)
<ignore_js_op>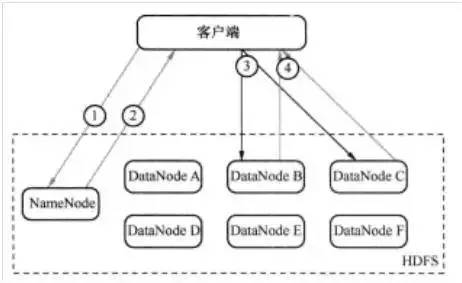
图2 HDFS读过程示意图
客户端并行从不同的DataNode中获取一个文件的数据块,然后联结这些数据块,拼成完整的文件。
通过副本快速恢复硬件故障
当一切运行正常时,DataNode会周期性发送心跳信息给NameNode(默认是每3秒钟一次)。如果NameNode在预定的时间内没有收到 心跳信息(默认是10分钟),它会认为DataNode出问题了,把它从集群中移除,并且启动一个进程去恢复数据。DataNode可能因为多种原因脱离 集群,如硬件故障、主板故障、电源老化和网络故障等。
对于HDFS来说,丢失一个DataNode意味着丢失了存储在它的硬盘上的数据块的副本。假如在任意时间总有超过一个副本存在(默认3个),故障 将不会导致数据丢失。当一个硬盘故障时,HDFS会检测到存储在该硬盘的数据块的副本数量低于要求,然后主动创建需要的副本,以达到满副本数状态。
跨多个DataNode切分文件
在HDFS里,文件被切分成数据块,通常每个数据块64MB~128MB,然后每个数据块被写入文件系统。同一个文件的不同数据块不一定保存在相同的DataNode上。这样做的好处是,当对这些文件执行运算时,能够通过并行方式读取和处理文件的不同部分。
当客户端准备写文件到HDFS并询问NameNode应该把文件写到哪里时,NameNode会告诉客户端,那些可以写入数据块的 DataNode。写完一批数据块后,客户端会回到NameNode获取新的DataNode列表,把下一批数据块写到新列表中的DataNode上。
转自:http://www.aboutyun.com/forum.php?mod=viewthread&tid=18075
HDFS的工作原理扫扫盲的更多相关文章
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- hadoop之hdfs及其工作原理
hadoop之hdfs及其工作原理 (一)hdfs产生的背景 随着数据量的不断增大和增长速度的不断加快,一台机器上已经容纳不下,因此就需要放到更多的机器中,但这样做不方便维护和管理,因此需要一种文件系 ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- HDFS的工作原理(读和写操作)
工作原理: NameNode和DateNode,NameNode相当于一个管理者,它管理集群内的DataNode,当客户发送请求过来后,NameNode会 根据情况指定存储到哪些DataNode上,而 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
- HADOOP1.X中HDFS工作原理
转载自:http://www.daniubiji.cn/archives/596 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据googl ...
- 一图看懂hadoop分布式文件存储系统HDFS工作原理
一图看懂hadoop分布式文件存储系统HDFS工作原理
- Hadoop中HDFS工作原理
转自:http://blog.csdn.net/sdlyjzh/article/details/28876385 Hadoop其实并不是一个产品,而是一些独立模块的组合.主要有分布式文件系统HDFS和 ...
- hadoop平台上HDFS和MAPREDUCE的功能、工作原理和工作过程
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapReduce ...
随机推荐
- 负载均衡集群ipvsadm命令及基本用法
ipvsadm是LVS在应用层的管理命令,我们可以通过这个命令去管理LVS的配置.需要使用yum单独安装. 基本用法: ipvsadm COMMAND [protocol] service-addre ...
- Web开发相关笔记
1.MySQL命令行下执行.sql脚本详解http://database.51cto.com/art/201107/277687.htm 在可视化工具里导出.sql脚本 --> 放命令行里运行 ...
- Django学习笔记之使用 Django项目开发框架
Django 项目是一个定制框架,它源自一个在线新闻 Web 站点,于 2005 年以开源的形式被释放出来.Django 框架的核心组件有: 用于创建模型的对象关系映射 为最终用户设计的完美管理界面 ...
- 修改AdminLTE左侧菜单展开延迟
AdminLTE左侧菜单展开会有半秒钟的延迟. 看起来会慢半拍. 可修改 admin/dist/js/app.min.js中的 animationSpeed值(默认为500) 如下:
- 单元测试框架unittest,ddt
unittest case.py 测试用例 suite.py 测试套件 loader.py 加载测试用例 run.py 执行测试用例 result.py 测试结果,测试报告 main mock 模拟测 ...
- ping主机脚本
#!/bin/bash #ping net='172.16.1' uphosts=0 downhosts=0 for i in {1..254};do ping -c 1 -w 1 ${net}.${ ...
- Oracle 数据库比较日期大小
在今天或者今天之前作比较:select * from JN_BUS_KJLWSBJBXX where dqsj < to_date('2007-09-07 00:00:00','yyyy-mm- ...
- Mysql 语句单表查询
一基本查询 -- 创建商品表 CREATE TABLE products( pid INT PRIMARY KEY AUTO_INCREMENT, pname VARCHAR(20), price D ...
- Steema TeeChart Pro VCL FMX 2017.20 Full Suorce在Delphi XE10下的安装
一.首先将压缩包TeeChart Pro VCL FMX 2017.20 FS.rar解压到一个目录,比如 E:\Application\Steema TeeChart Pro VCL FMX 201 ...
- Spark Configuration配置
Spark可以通过三种方式配置系统: 通过SparkConf对象, 或者Java系统属性配置Spark的应用参数 通过每个节点上的conf/spark-env.sh脚本为每台机器配置环境变量 通过lo ...