图的存储结构(邻接矩阵与邻接表)及其C++实现
一、图的定义
图是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:
G=(V,E)
其中:G表示一个图,V是图G中顶点的集合,E是图G中顶点之间边的集合。
注:
在线性表中,元素个数可以为零,称为空表;
在树中,结点个数可以为零,称为空树;
在图中,顶点个数不能为零,但可以没有边。
二、图的基本术语
略。
三、图的遍历
图的遍历是在从图中某一顶点出发,对图中所有顶点访问一次且仅访问一次。
图的遍历操作要解决的关键问题:
① 在图中,如何选取遍历的起始顶点?
解决方案:从编号小的顶点开始 。
在线性表中,数据元素在表中的编号就是元素在序列中的位置,因而其编号是唯一的; 在树中,将结点按层序编号,由于树具有层次性,因而其层序编号也是唯一的; 在图中,任何两个顶点之间都可能存在边,顶点是没有确定的先后次序的,所以,顶点的编号不唯一。 为了定义操作的方便,将图中的顶点按任意顺序排列起来,比如,按顶点的存储顺序。
② 从某个起点始可能到达不了所有其它顶点,怎么办?
解决方案:多次调用从某顶点出发遍历图的算法。
③ 因图中可能存在回路,某些顶点可能会被重复访问,那么如何避免遍历不会因回路而陷入死循环。
解决方案:附设访问标志数组visited[n] 。
④ 在图中,一个顶点可以和其它多个顶点相连,当这样的顶点访问过后,如何选取下一个要访问的顶点?
解决方案:深度优先遍历和广度优先遍历。
1、深度优先遍历
基本思想 :
⑴ 访问顶点v;
⑵ 从v的未被访问的邻接点中选取一个顶点w,从w出发进行深度优先遍历;
⑶ 重复上述两步,直至图中所有和v有路径相通的顶点都被访问到。
2、广度优先遍历
基本思想:
⑴ 访问顶点v;
⑵ 依次访问v的各个未被访问的邻接点v1, v2, …, vk;
⑶ 分别从v1,v2,…,vk出发依次访问它们未被访问的邻接点,并使“先被访问顶点的邻接点”先于“后被访问顶点的邻接点”被访问。直至图中所有与顶点v有路径相通的顶点都被访问到。
四、图的存储结构
 是否可以采用顺序存储结构存储图?
是否可以采用顺序存储结构存储图?
图的特点:顶点之间的关系是m:n,即任何两个顶点之间都可能存在关系(边),无法通过存储位置表示这种任意的逻辑关系,所以,图无法采用顺序存储结构。
如何存储图?
考虑图的定义,图是由顶点和边组成的,分别考虑如何存储顶点、如何存储边。
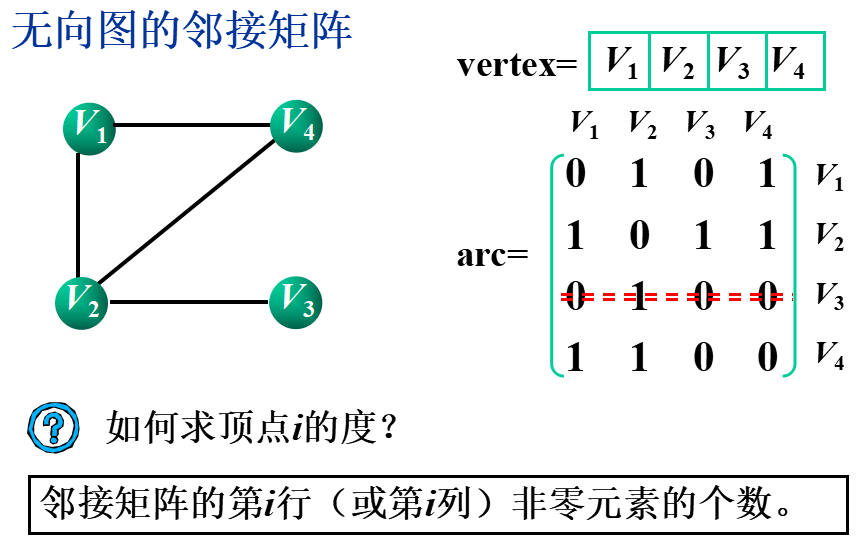
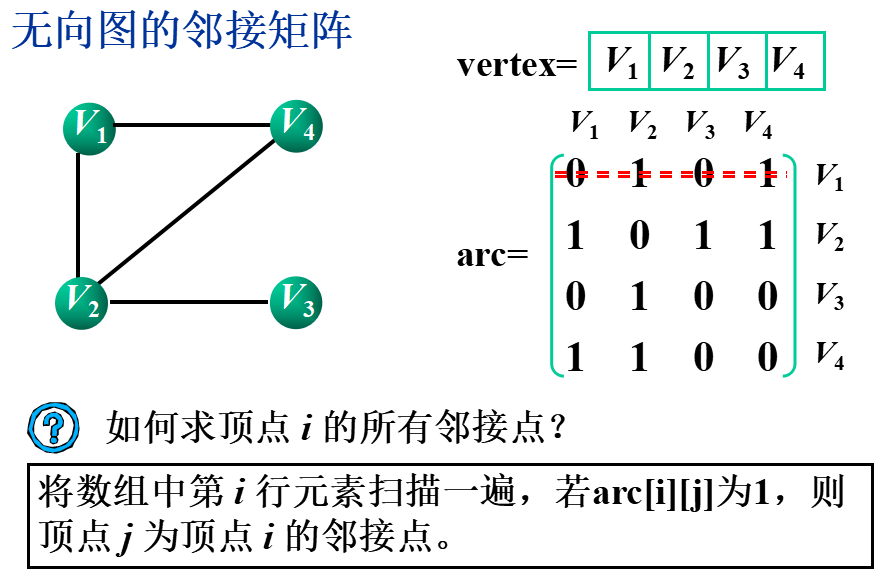
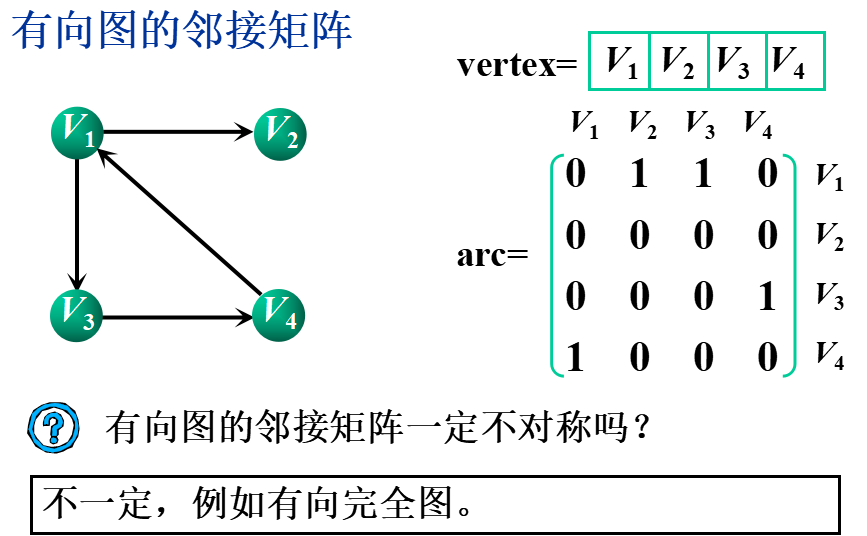
①邻接矩阵(数组表示法)
基本思想:用一个一维数组存储图中顶点的信息,用一个二维数组(称为邻接矩阵)存储图中各顶点之间的邻接关系。
假设图G=(V,E)有n个顶点,则邻接矩阵是一个n×n的方阵,定义为:
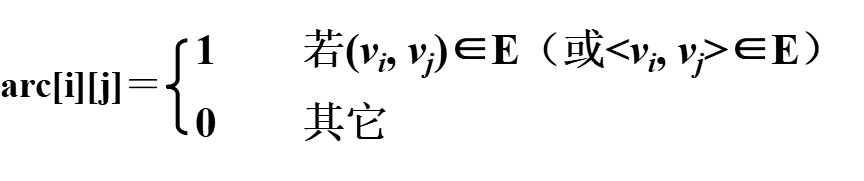


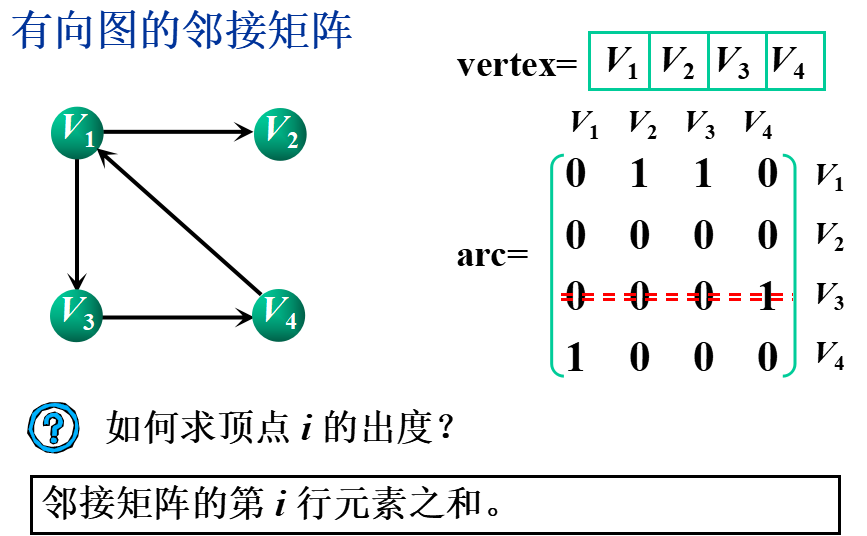
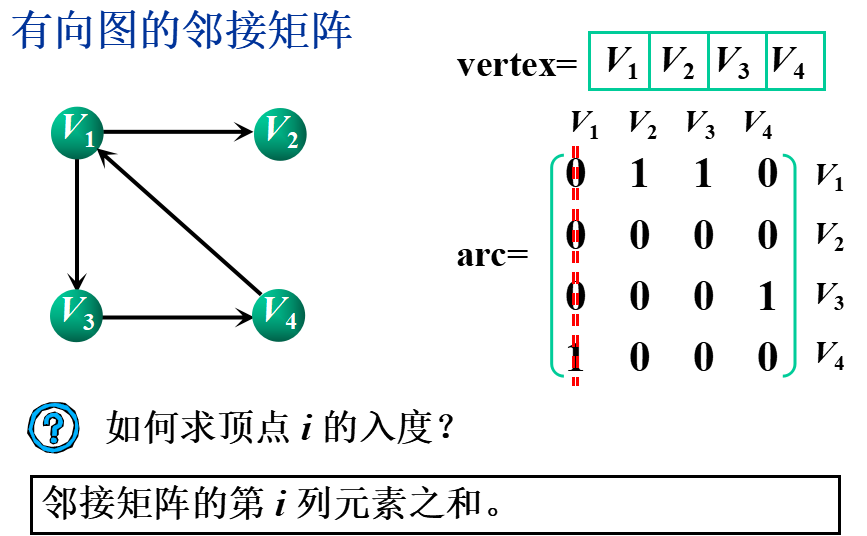
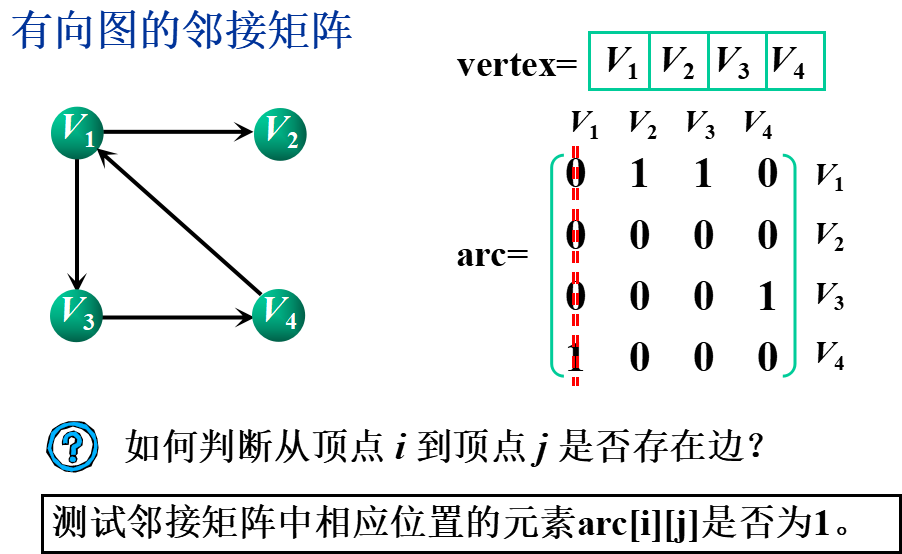
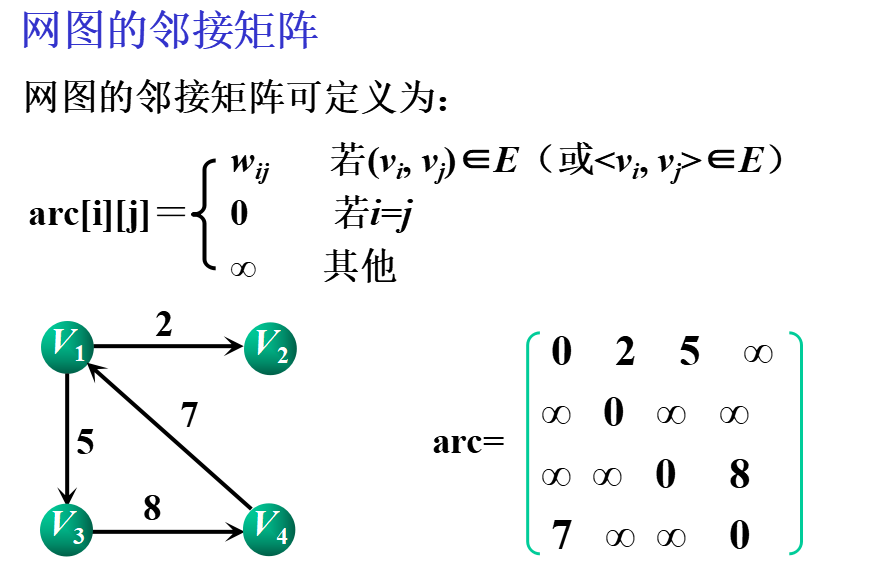
②邻接表
邻接表存储的基本思想:对于图的每个顶点vi,将所有邻接于vi的顶点链成一个单链表,称为顶点vi的边表(对于有向图则称为出边表),所有边表的头指针和存储顶点信息的一维数组构成了顶点表。
邻接表有两种结点结构:顶点表结点和边表结点.。

顶点表 边表
其中:vertex:数据域,存放顶点信息。 firstedge:指针域,指向边表中第一个结点。 adjvex:邻接点域,边的终点在顶点表中的下标。 next:指针域,指向边表中的下一个结点。
定义邻接表的结点:
// 边表顶点
struct ArcNode
{ int adjvex;
ArcNode *next;
};
// 顶点表
template <class T>
struct VertexNode
{
T vertex;
ArcNode *firstedge;
};
五、C++代码实现
Ⅰ、邻接矩阵
// queue.h
#pragma once
#include <iostream>
const int queueSize = ;
template<class T>
class queue
{
public:
T data[queueSize];
int front, rear;
};
// graph.h
#pragma once
#include<iostream>
#include"queue.h"
// 基于邻接矩阵存储结构的图的类实现
const int MaxSize = ;
int visited[MaxSize] = { };// 顶点是否被访问的标记
template<class T>
class MGraph
{
public:
MGraph(T a[], int n, int e);// 构造函数建立具有N个定点e条边的图
~MGraph(){}// 析构函数
void DFSTraaverse(int v);// 深度优先遍历图
void BFSTraverse(int v);// 广度优先遍历图
private:
T vertex[MaxSize];// 存放图中顶点的数组
int arc[MaxSize][MaxSize];// 存放图中边的数组
int vertexNum, arcNum;// 图中顶点数和边数
}; template<class T>
inline MGraph<T>::MGraph(T a[], int n, int e)
{
vertexNum = n;
arcNum = e;
for (int i = ; i < vertexNum; i++) // 顶点初始化
vertex[i] = a[i];
for (int i = ; i < vertexNum; i++) // 邻接矩阵初始化
for (int j = ; j < vertexNum; j++)
arc[i][j] = ;
for (int k = ; k < arcNum; k++)
{
int i, j;
std::cin >> i >> j; // 输入边依附的顶点的编号
arc[i][j] = ; // 置有边标记
arc[j][i] = ;
}
} template<class T>
inline void MGraph<T>::DFSTraaverse(int v)
{
cout << vertex[v]<<" ";
visited[v] = ;
for (int j = ; j < vertexNum; j++)
{
if (arc[v][j] == && visited[j] == )
DFSTraaverse(j);
}
} template<class T>
inline void MGraph<T>::BFSTraverse(int v)
{
int visited[MaxSize] = { };// 顶点是否被访问的标记
queue<T> Q;
Q.front = Q.rear = -; // 初始化队列
cout << vertex[v]<<" ";
visited[v] = ;
Q.data[++Q.rear] = v; // 被访问顶点入队
while (Q.front != Q.rear)
{
v = Q.data[++Q.front]; // 对头元素出队
for (int j = ; j < vertexNum; j++)
{
if (arc[v][j] == && visited[j] == )
{
std::cout << vertex[j]<<" ";
visited[j] = ;
Q.data[++Q.rear] = j; // 邻接点入队
}
}
}
}
// main.cpp
#include"graph.h"
using namespace std;
int main()
{
int arry[] = { ,,,,, };
MGraph<int> graph(arry, , );
graph.BFSTraverse();
cout << endl;
graph.DFSTraaverse();
system("pause");
return ;
}
Ⅱ、邻接表
// queue.h
#pragma once
#include <iostream>
const int queueSize = ;
template<class T>
class queue
{
public:
T data[queueSize];
int front, rear;
};
// graph.h
#pragma once
#include<iostream>
#include"queue.h"
// 定义边表结点
struct ArcNode
{
int adjvex;// 邻接点域
ArcNode* next;
};
// 定义顶点表结点
struct VertexNode
{
int vertex;
ArcNode* firstedge;
}; // 基于邻接表存储结构的图的类实现
const int MaxSize = ;
int visited[MaxSize] = { };// 顶点是否被访问的标记
//typedef VertexNode AdjList[MaxSize]; //邻接表
template<class T>
class ALGraph
{
public:
ALGraph(T a[], int n, int e);// 构造函数建立具有N个定点e条边的图
~ALGraph() {}// 析构函数
void DFSTraaverse(int v);// 深度优先遍历图
void BFSTraverse(int v);// 广度优先遍历图
private:
VertexNode adjlist[MaxSize];// 存放顶点的数组
int vertexNum, arcNum;// 图中顶点数和边数
}; template<class T>
ALGraph<T>::ALGraph(T a[], int n, int e)
{
vertexNum = n;
arcNum = e;
for (int i = ; i <vertexNum; i++)
{
adjlist[i].vertex = a[i];
adjlist[i].firstedge = NULL;
}
for (int k = ; k < arcNum; k++)
{
int i, j;
std::cin >> i >> j;
ArcNode* s = new ArcNode;
s->adjvex = j;
s->next = adjlist[i].firstedge;
adjlist[i].firstedge = s;
}
} template<class T>
inline void ALGraph<T>::DFSTraaverse(int v)
{
std::cout << adjlist[v].vertex;
visited[v] = ;
ArcNode* p = adjlist[v].firstedge;
while (p != NULL)
{
int j = p->adjvex;
if (visited[j] == )
DFSTraaverse(j);
p = p->next;
}
} template<class T>
inline void ALGraph<T>::BFSTraverse(int v)
{
int visited[MaxSize] = { };// 顶点是否被访问的标记
queue<T> Q;
Q.front = Q.rear = -; // 初始化队列
std::cout << adjlist[v].vertex;
visited[v] = ;
Q.data[++Q.rear] = v;// 被访问顶点入队
while (Q.front != Q.rear)
{
v = Q.data[++Q.front]; // 对头元素出队
ArcNode* p = adjlist[v].firstedge;
while (p != NULL)
{
int j = p->adjvex;
if (visited[j] == )
{
std::cout << adjlist[j].vertex;
visited[j] = ;
Q.data[++Q.rear] = j;
}
p = p->next;
}
}
}
// main.cpp
#include"graph.h"
using namespace std;
int main()
{
int arry[] = { ,,,, };
ALGraph<int> graph(arry, , );
graph.BFSTraverse();
cout << endl;
graph.DFSTraaverse();
system("pause");
return ;
}
参考文献:
[1]王红梅, 胡明, 王涛. 数据结构(C++版)[M]. 北京:清华大学出版社。
2018-01-07
图的存储结构(邻接矩阵与邻接表)及其C++实现的更多相关文章
- 【数据结构】图的基本操作——图的构造(邻接矩阵,邻接表),遍历(DFS,BFS)
邻接矩阵实现如下: /* 主题:用邻接矩阵实现 DFS(递归) 与 BFS(非递归) 作者:Laugh 语言:C++ ***************************************** ...
- 图的存储结构:邻接矩阵(邻接表)&链式前向星
[概念]疏松图&稠密图: 疏松图指,点连接的边不多的图,反之(点连接的边多)则为稠密图. Tips:邻接矩阵与邻接表相比,疏松图多用邻接表,稠密图多用邻接矩阵. 邻接矩阵: 开一个二维数组gr ...
- PAT1013. Battle Over Cities(邻接矩阵、邻接表分别dfs)
//采用不同的图存储结构结构邻接矩阵.邻接表分别dfs,我想我是寂寞了吧,应该试试并查集,看见可以用并查集的就用dfs,bfs代替......怕了并查集了 //邻接矩阵dfs #include< ...
- 【PHP数据结构】图的存储结构
图的概念介绍得差不多了,大家可以消化消化再继续学习后面的内容.如果没有什么问题的话,我们就继续学习接下来的内容.当然,这还不是最麻烦的地方,因为今天我们只是介绍图的存储结构而已. 图的顺序存储结构:邻 ...
- C++编程练习(9)----“图的存储结构以及图的遍历“(邻接矩阵、深度优先遍历、广度优先遍历)
图的存储结构 1)邻接矩阵 用两个数组来表示图,一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中边或弧的信息. 2)邻接表 3)十字链表 4)邻接多重表 5)边集数组 本文只用代码实现用 ...
- DS实验题 Old_Driver UnionFindSet结构 指针实现邻接表存储
题目见前文:DS实验题 Old_Driver UnionFindSet结构 这里使用邻接表存储敌人之间的关系,邻接表用指针实现: // // main.cpp // Old_Driver3 // // ...
- K:图的存储结构
常用的图的存储结构主要有两种,一种是采用数组链表(邻接表)的方式,一种是采用邻接矩阵的方式.当然,图也可以采用十字链表或者边集数组的方式来进行表示,但由于不常用,为此,本博文不对其进行介绍. 邻接 ...
- 【algo&ds】6.图及其存储结构、遍历
1.什么是图 图表示"多对多"的关系 包含 一组顶点:通常用 V(Vertex)表示顶点集合 一组边:通常用 E(Edge)表示边的集合 边是顶点对:(v,w)∈ E,其中 v,w ...
- 图的存储结构大赏------数据结构C语言(图)
图的存储结构大赏------数据结构C语言(图) 本次所讲的是常有的四种结构: 邻接矩阵 邻接表 十字链表 邻接多重表 邻接矩阵 概念 两个数组,一个表示顶点的信息,一个用来表示关联的关系. 如果是无 ...
随机推荐
- Revit二次开发_快速显示隐藏剖面框
最近遇到一种状况需要经常切换剖面框的可见性,于是想将剖面框的显示与隐藏做成一个按钮,方便切换. 其他类似元素想做成快速切换可见性应该可以使用类似做法. 这次的隐藏对象是剖面框,所以我直接就隐藏元素了. ...
- openerp学习笔记 数据合法性约束(对象约束+数据库约束)
#检测同一时间段内是否存在相同的请假单,False 是存在,不允许创建 def _check_date(self, cr, uid, ids): for rec in self.b ...
- Python数据类型(数字)
文章内容参考了教程:http://www.runoob.com/python/python-basic-syntax.html#commentform Python 变量类型 变量存储在内存中的值.这 ...
- ruby中的retry和redo
# retry用于处理异常中的begin/end代码块中,如果发生异常会重新运行 begin 和 rescue 之间的代码#当retry 被调用的话,begin 和 rescue 之间所有的代码都会被 ...
- Node.js des加密
常见的加密算法基本分为这几类,1 :线性散列算法.2:对称性加密算法.3.非对称性加密算法 (记记记) 线性散列算法(签名算法):MD5,SHA1,HMAC比如MD5:即Message-Digest ...
- ES6基本语法之let和const
1.var可以重复声明 var a = 12; var a = 5; alert(a) //5 2.var无法限制修改 如:PI = 3.1415: 3.var没有块级作用域 { } 像: if(){ ...
- Java Collection.Map
/** * Map集合的特点: * 将键映射到值的对象,一个映射不能包含重复的键,每个键最多只能映射到一个值. * * Map集合的功能和概述: * 1.添加功能 * V put(K key , V ...
- 在centos linux上安装docker
前置条件 64-bit 系统 kernel 3.10+ 1.检查内核版本,返回的值大于3.10即可. $ uname -r 2.确保yum是最新的 $ yum update 3.安装 Docker y ...
- Linux文件夹和文件创建删除命令
Linux删除文件夹命令 linux删除目录很简单,很多人还是习惯用rmdir,不过一旦目录非空,就陷入深深的苦恼之中,现在使用rm -rf命令即可.直接rm就可以了,不过要加两个参数-rf 即:rm ...
- ssm框架文件上传
有两种方法 导包和上传配置自己搞: 第一种: 上传单个文件: @RequestMapping("/addfile1") public String addfile(@Request ...