【RL系列】Multi-Armed Bandit笔记——UCB策略与Gradient策略
本篇主要是为了记录UCB策略与Gradient策略在解决Multi-Armed Bandit问题时的实现方法,涉及理论部分较少,所以请先阅读Reinforcement Learning: An Introduction (Drfit) 的2.7,2.8的内容。为了更深入一点了解UCB策略,可以随后阅读下面这篇文章:
【RL系列】Multi-Armed Bandit笔记补充(二)—— UCB策略
UCB策略需要进行初始化工作,也就是说通常都会在进入训练之前先将每个动作都测试一变,保证每个动作被选择的次数都不为0且都会有一个初始的收益均值和置信上限,一般不会进行冷启动(冷启动的话,需要在开始时有一定的随机动作,会降低动作选择的效率)。我们可以设初始化函数UCBinitial,将其表现为Matlab:
function [Q UCBq] = UCBInitial(Q, Reward, UCBq)
% CurrentR: Current Reward
% CurrentA: Current Action
% RandK: K-Armed Bandit
% Q: Step-size Average Reward
% UCBq: Q + Upper Confidence Bound RandK = length(Reward);
for n = 1:RandK
CurrentA = n;
CurrentR = normrnd(Reward(CurrentA), 1); Q(CurrentA) = (CurrentR - Q(CurrentA))*0.1 + Q(CurrentA);
UCBq(CurrentA) = Q(CurrentA) + c*(2*log(n))^0.5;
end
在训练中,UCB动作选择策略和置信上限值的更新策略可以写为:
% UCBq: Q + Upper Confidence Bound
% TotalCalls(Action): The Cumulative call times of Action
% c: Standard Deviation of reward in theorical analysis [MAX CurrentA] = max(UCBq);
MAXq(CurrentA) = Q(CurrentA) + c*(2*log(n)/TotalCalls(CurrentA))^0.5;
注意公式里的c应为理论上收益的标准差,但因为收益分布是一个黑箱,所以这个参数只能从实际实验中测试推断出来。这里我们假设收益标准差为1,所以为了实验效果,设c=1
接下来,我们就看一看UCB策略的测试效果吧。这里我们将其与epsilon-greedy策略进行对比(epsilon = 0.1),首先是Average Reward的测试结果:
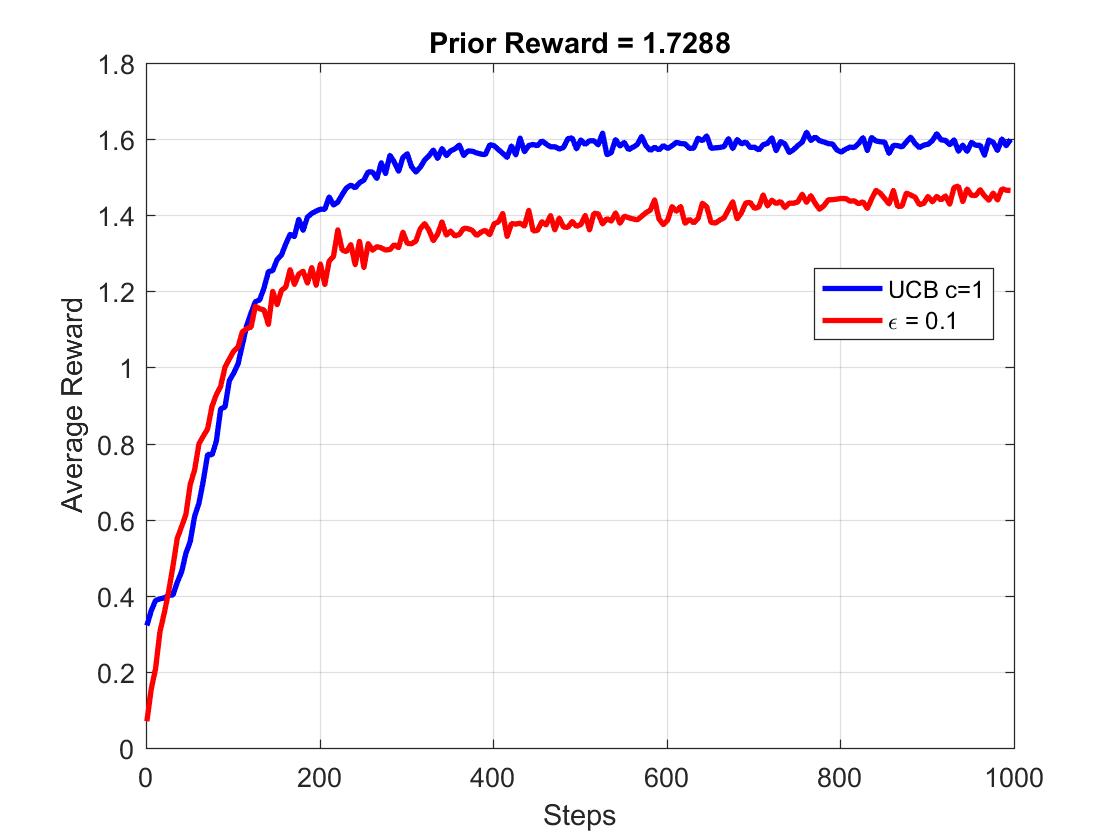
UCB算法在前1000次的学习中可以得到比epsilon-greedy更高的均值收益评价。那么这是否就代表了UCB策略可以更高概率的选取最优动作?下面我们看Optimal Action Rate的测试结果:
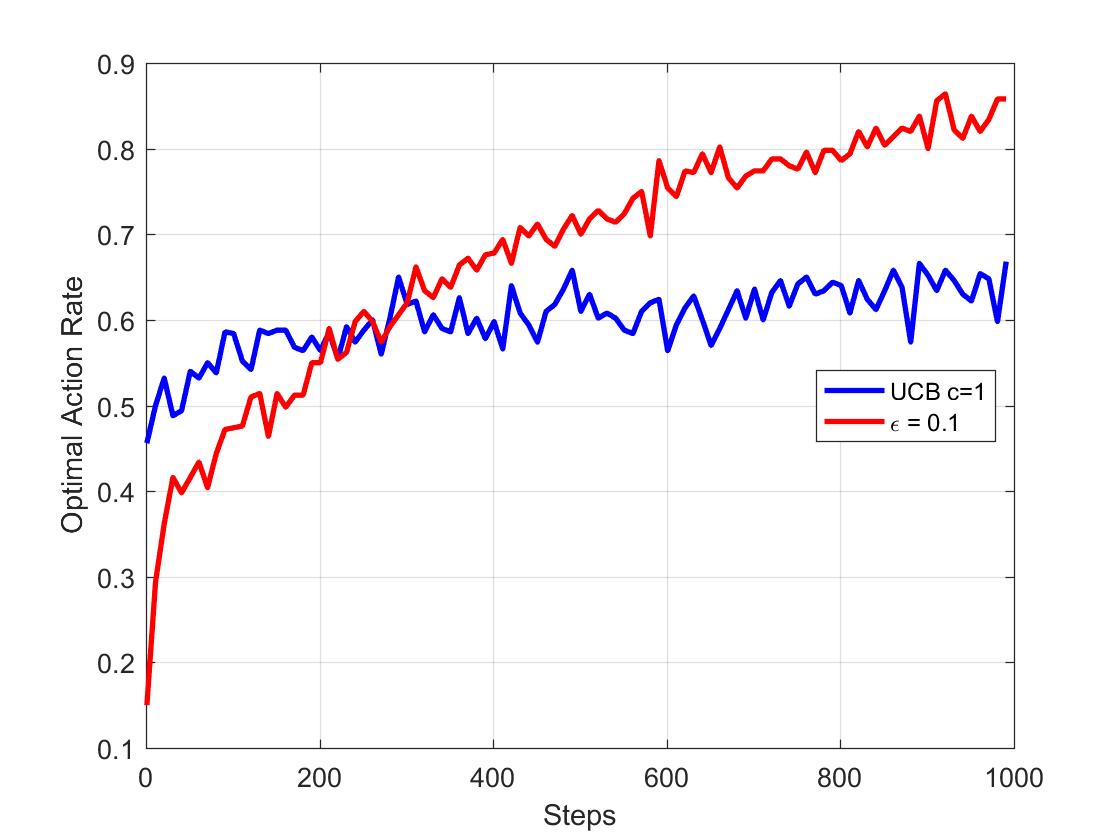
可以发现学习次数较少时,UCB策略可以比epsilon-greedy策略更快的获得较高概率的最优解,但最优动作选择率始终维持在60%左右,是低于epsilon-greedy策略在1000次学习时接近90%的数值的。这也直接的反映出UCB并不适合求解最优。那为什么最优动作选择率不高,但平均收益却较高呢?UCB大概率选择的优先动作通常是排名靠前的动作,也就是说动作选择并不一定是最优,但大概率是最佳的3个或2个动作中的一个,所以UCB也可用作二元分类策略,将表现较好的(大概率选择的动作)分为一类,表现较差的动作分为一类。
我们来看看UCB在分类中的表现,用80%分类准确度来进行评价。如果经过UCB策略学习后得到的估计收益均值中的前5位中有超过或等于4位与实际的收益均值相符的频率,以此近似为分类的准确度。也就是说,如果有10个bandit,我们将其分为两类,收益高的一类(前5个bandit)与收益低的一类(后5个bandit),80%分类准确度可以以此计算:估计的前5个bandit与实际的有超过4个相符的概率。用数学表述出来就是,如果有一个Reward集合R:
将其分为两类,按数值大小排序,前五名为一类,归为集合G,G是R的子集。通过学习估计出的G,称为AG 。那么80%分类准确度可以表示为:
那么我们直接看结论吧:
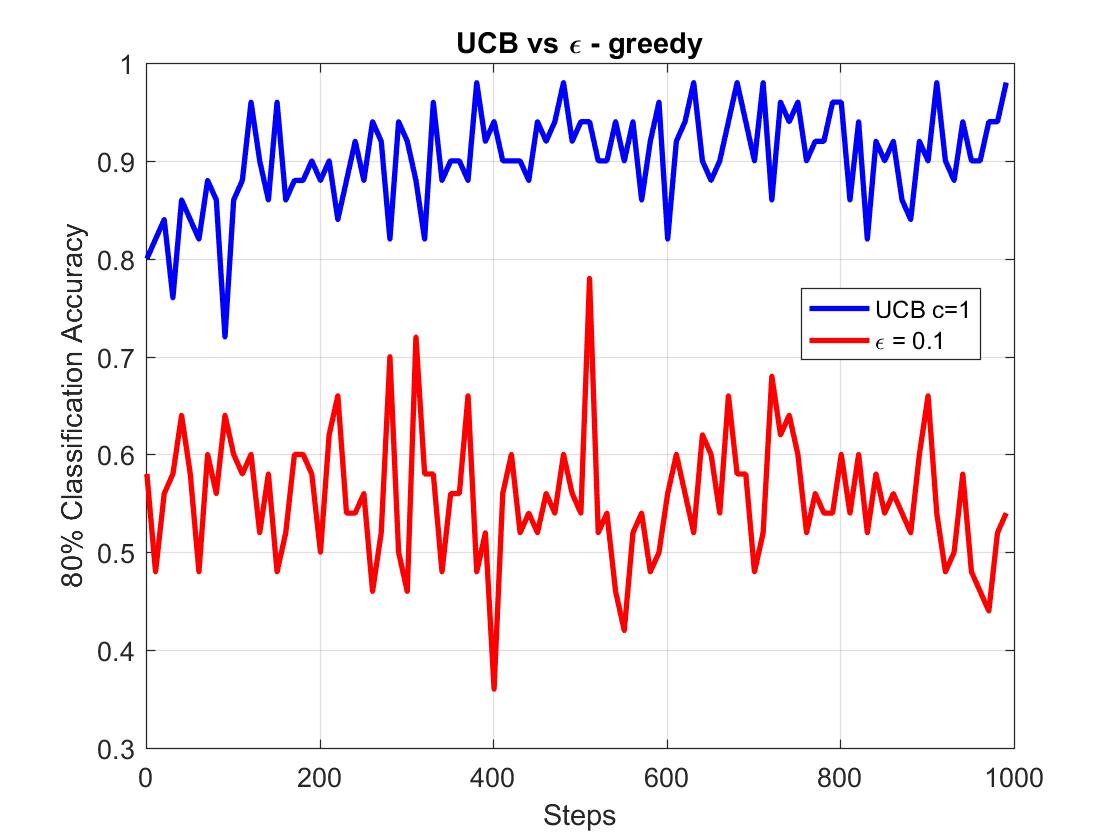
UCB的80%分类准确度始终在90%上下,而epsilon-greedy却只有50%左右。显然,UCB在这方面做的要好于epsilon-greedy。
【RL系列】Multi-Armed Bandit笔记——UCB策略与Gradient策略的更多相关文章
- 【RL系列】Multi-Armed Bandit笔记补充(一)
在此之前,请先阅读上一篇文章:[RL系列]Multi-Armed Bandit笔记 本篇的主题就如标题所示,只是上一篇文章的补充,主要关注两道来自于Reinforcement Learning: An ...
- 【RL系列】Multi-Armed Bandit笔记补充(二)
本篇的主题是对Upper Conference Bound(UCB)策略进行一个理论上的解释补充,主要探讨UCB方法的由来与相关公式的推导. UCB是一种动作选择策略,主要用来解决epsilon-gr ...
- 【RL系列】Multi-Armed Bandit问题笔记
这是我学习Reinforcement Learning的一篇记录总结,参考了这本介绍RL比较经典的Reinforcement Learning: An Introduction (Drfit) .这本 ...
- 【RL系列】MDP与DP问题
推荐阅读顺序: Reinforcement Learning: An Introduction (Drfit) 有限马尔可夫决策过程 动态编程笔记 Dynamic programming in Py ...
- 【RL系列】从蒙特卡罗方法步入真正的强化学习
蒙特卡罗方法给我的感觉是和Reinforcement Learning: An Introduction的第二章中Bandit问题的解法比较相似,两者皆是通过大量的实验然后估计每个状态动作的平均收益. ...
- 【RL系列】马尔可夫决策过程——状态价值评价与动作价值评价
请先阅读上两篇文章: [RL系列]马尔可夫决策过程中状态价值函数的一般形式 [RL系列]马尔可夫决策过程与动态编程 状态价值函数,顾名思义,就是用于状态价值评价(SVE)的.典型的问题有“格子世界(G ...
- (zhuan) 一些RL的文献(及笔记)
一些RL的文献(及笔记) copy from: https://zhuanlan.zhihu.com/p/25770890 Introductions Introduction to reinfor ...
- 【RL系列】马尔可夫决策过程中状态价值函数的一般形式
请先阅读上一篇文章:[RL系列]马尔可夫决策过程与动态编程 在上一篇文章里,主要讨论了马尔可夫决策过程模型的来源和基本思想,并以MAB问题为例简单的介绍了动态编程的基本方法.虽然上一篇文章中的马尔可夫 ...
- Hibernate学习笔记二:Hibernate缓存策略详解
一:为什么使用Hibernate缓存: Hibernate是一个持久层框架,经常访问物理数据库. 为了降低应用程序访问物理数据库的频次,从而提高应用程序的性能. 缓存内的数据是对物理数据源的复制,应用 ...
随机推荐
- Hibernate连接各种数据库的配置
转自CSDN shl7765856的专栏:http://blog.csdn.net/shl7765856/article/details/7411987 目录: 1.MySql连接配置 2.Sql S ...
- iOS:绘图(18-01-25更)
目录 1.UIBezierPath(贝塞尔曲线) 1).在重写 drawRect: 方法里使用 2).在普通方法里使用,需要画布. 3). 切圆角.指定位置圆角.任意形状. 4).彩色的动画加载圆圈. ...
- JavaScript字符串的处理方法
1.字符方法charAt()和charCodeAt();这两个方法都接收一个参数 var stringValue = "hello world"; stringValue.char ...
- 浅谈React和VDom关系
组件化 组件的封装 组件的复用 组件的封装 视图 数据 视图和数据之间的变化逻辑 import React, {Component} from 'react'; export default clas ...
- chromium之message_pump_win之二
接下来分析 MessagePumpForUI上一篇分析MessagePumpWin,可以参考chromium之message_pump_win之一 根据对MessagePumpWin的分析,Messa ...
- morphia 框架 mongodb内嵌查询
mongodb中存储的文档格式如下,实现查询fromdata下did和dvid为指定值的数据 { "_id": { "$oid": "553f4a9f ...
- 笔记: js构造函数与原型
目录 构造函数与原型介绍 涉及三种引用的操作 有关原型及原型链的一些相关方法总结 @ 构造函数与原型介绍 1.函数与函数的原型对象(prototype object): 在JavaScript中,创建 ...
- mqtt使用一
最近做的一个项目用到了mqtt协议,我需要从第三方订阅主题接受消息,还需要自己搭建,mqtt服务器去发布主题.下面就详细介绍一下环境的搭建和使用. 1.mqtt介绍 MQTT是一个基于客户端-服务器的 ...
- php 算法(冒泡排序)
//冒泡排序(从小到大) (从大到小改变for循环中的大于号为小于号即可) public function index(){ $arr = array(1,8,3, ...
- Python编程从入门到实践,个人笔记
3-9 晚餐嘉宾:在完场练习3-6时编写的程序之一中,使用len()打印一条消息,指出有多少位嘉宾来与你共进晚餐. 自己先写的程序如下: # coding=gbk #邀请一些人吃饭 per_list= ...