Python爬虫教程-23-数据提取-BeautifulSoup4(一)
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据,查看文档
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
Python爬虫教程-23-数据提取-BeautifulSoup4(一)
- Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能
- 它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序
- Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了
常用数据提取工具的比较
- 1.正则:很快,不好用,不需要安装
https://blog.csdn.net/qq_40147863/article/details/82181151 - 2.lxml:比较快,使用简单,需要安装
https://blog.csdn.net/qq_40147863/article/details/82192119 - 3.BeautifulSoup4(建议):慢,使用简单,需要安装
BeautifulSoup4 的安装
- 【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】 >【BeautifulSoup4】>【install】
- 具体操作截图:
BeautifulSoup 的简单使用案例
- 代码27bs.py文件:https://xpwi.github.io/py/py爬虫/py27bs.py
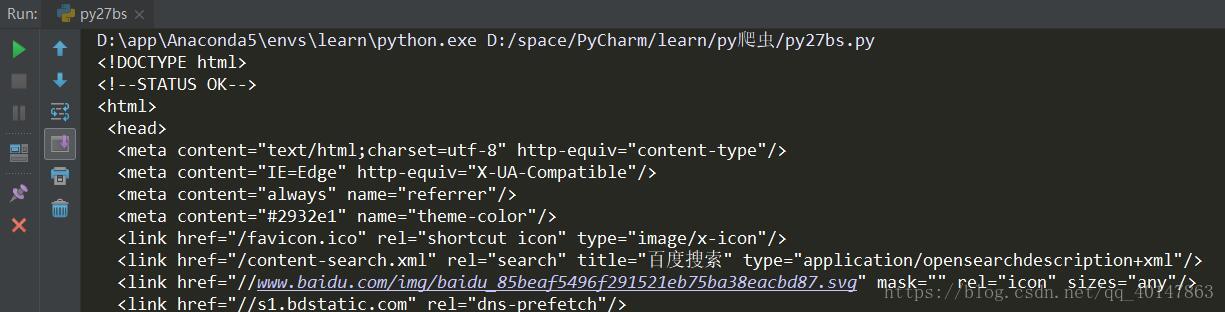
# BeautifulSoup 的使用案例
from urllib import request
from bs4 import BeautifulSoup
url = 'http://www.baidu.com/'
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content, 'lxml')
# bs 自动解码
content = soup.prettify()
print(content)
运行结果
BeautifulSoup 四大对象
- 1.Tag
- 2.NavigableString
- 3.BeautifulSoup
- 4.Comment
(1)Tag
- 对应HTML中的标签
- 可以通过soup.tag_name(例如:soup.head;soup.link )
- tag 的属性:
- name :例:soup.meta.name(对应下面案例代码)
- attrs :例:soup.meta.attrs
- attrs['属性名']:例:soup.meta.attrs['content']
- 案例代码27bs2.py文件:https://xpwi.github.io/py/py爬虫/py27bs2.py
# BeautifulSoup 的使用案例
from urllib import request
from bs4 import BeautifulSoup
url = 'http://www.baidu.com/'
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content, 'lxml')
# bs 自动解码
content = soup.prettify()
# 虽然原文中有多个 meta 但是使用 soup.meta 只会打印出以第一个
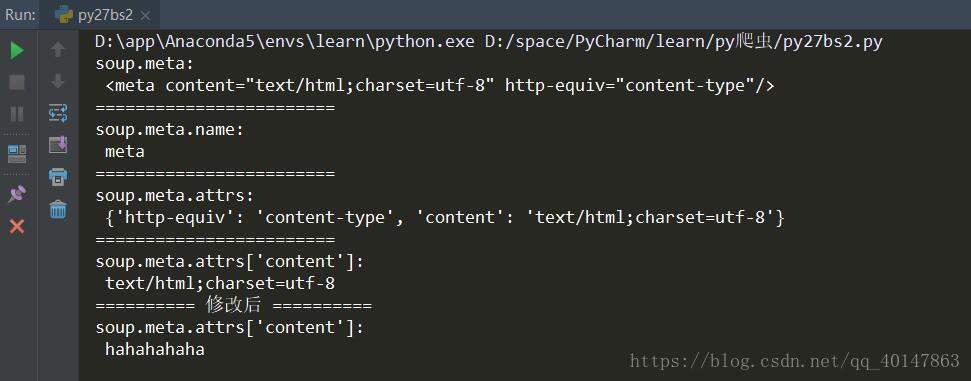
print("soup.meta:\n", soup.meta)
print("=="*12)
print("soup.meta.name:\n",soup.meta.name)
print("=="*12)
print("soup.meta.attrs:\n",soup.meta.attrs)
print("=="*12)
print("soup.meta.attrs['content']:\n",soup.meta.attrs['content'])
# 当然我们也可以对获取到的数据进行修改
soup.meta.attrs['content'] = 'hahahahaha'
print("=="*5, "修改后","=="*5)
print("soup.meta.attrs['content']:\n",soup.meta.attrs['content'])
运行结果
这里结果我们看到,只有一个 meta 标签,而源文档有多个,不是出错,而是这里使用 soup.meta 这种方式,只会打印出以第一个,也就是说数据提取时,1次匹配成功即退出
怎样打印多个 meta 标签呢?使用遍历的方式,具体代码写在下一篇
(2)NavigableString
- 对应内容值
(3)BeautifulSoup
- 表示的是一个文档的内容,大部分可以把它当做 tag 对象
- 不常用
(4)Comment
- 特殊类型的 NavigableString 对象
- 对其输出,则内容不包括注释符号
本篇就介绍到这里了,剩下的写在下一篇
拜拜
- 本笔记不允许任何个人和组织转载
Python爬虫教程-23-数据提取-BeautifulSoup4(一)的更多相关文章
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
Python爬虫教程-25-数据提取-BeautifulSoup4(三) 本篇介绍 BeautifulSoup 中的 css 选择器 css 选择器 使用 soup.select 返回一个列表 通过标 ...
- Python爬虫教程-24-数据提取-BeautifulSoup4(二)
Python爬虫教程-24-数据提取-BeautifulSoup4(二) 本篇介绍 bs 如何遍历一个文档对象 遍历文档对象 contents:tag 的子节点以列表的方式输出 children:子节 ...
- Python爬虫教程-19-数据提取-正则表达式(re)
本篇主页内容:match的基本使用,search的基本使用,findall,finditer的基本使用,匹配中文,贪婪与非贪婪模式 Python爬虫教程-19-数据提取-正则表达式(re) 正则表达式 ...
- Python爬虫教程-01-爬虫介绍
Spider-01-爬虫介绍 Python 爬虫的知识量不是特别大,但是需要不停和网页打交道,每个网页情况都有所差异,所以对应变能力有些要求 爬虫准备工作 参考资料 精通Python爬虫框架Scrap ...
- Python爬虫教程-00-写在前面
鉴于好多人想学Python爬虫,缺没有简单易学的教程,我将在CSDN和大家分享Python爬虫的学习笔记,不定期更新 基础要求 Python 基础知识 Python 的基础知识,大家可以去菜鸟教程进行 ...
- Python爬虫教程-18-页面解析和数据提取
本篇针对的数据是已经存在在页面上的数据,不包括动态生成的数据,今天是对HTML中提取对我们有用的数据,去除无用的数据 Python爬虫教程-18-页面解析和数据提取 结构化数据:先有的结构,再谈数据 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- Python爬虫教程-34-分布式爬虫介绍
Python爬虫教程-34-分布式爬虫介绍 分布式爬虫在实际应用中还算是多的,本篇简单介绍一下分布式爬虫 什么是分布式爬虫 分布式爬虫就是多台计算机上都安装爬虫程序,重点是联合采集.单机爬虫就是只在一 ...
- Python爬虫教程-33-scrapy shell 的使用
本篇详细介绍 scrapy shell 的使用,也介绍了使用 xpath 进行精确查找 Python爬虫教程-33-scrapy shell 的使用 scrapy shell 的使用 条件:我们需要先 ...
随机推荐
- L2-3 名人堂与代金券 (25 分)
#include<cstdio> #include<algorithm> #include<cstring> using namespace std; int N, ...
- 认识CSS中高级技巧之元素的显示与隐藏
前端之HTML,CSS(八) CSS高级技巧 元素的显示与隐藏 CSS中有三个属性可以设置元素的显示于隐藏,分别是:display.visibility和overflow. display 隐藏元素: ...
- Ubuntu安装google-chrome
原文地址:http://www.linuxidc.com/Linux/2013-10/91857.htm安装谷歌浏览器,只需要三行代码: 打开终端,输入 cd /tmp 对于谷歌Chrome32位版本 ...
- Web测试注意事项
参考文章:http://www.51testing.com/html/07/n-3723307.html 总结下遇到的web测试的时候需要注意的地方: 页面分辨率: 通常是计算机的默认分辨率,但是还 ...
- 011-filter模板
1 模板一 package ${enclosing_package}; import java.io.IOException; import javax.servlet.FilterChain; im ...
- Class and Instance Variables In Ruby
https://github.com/unixc3t/mydoc/blob/master/blog/caiv.md
- lua默认是double类型
把c#的float类型传给lua ,lua自己换转成double ,一转就出精度问题 lua只有double没有float ===================================== ...
- linux系统下图片的路径
1. 图片跟网页或者程序在同一目录下 直接 src="abc.jpg" 如果不行 就加多一个斜杠 src="/abc.jpg"
- shell之“>/dev/null 2>&1” 详解
shell中可能经常能看到:>/dev/null 2>&1 命令的结果可以通过 %> 的形式来定义输出,其中 %> 代表文件描述符 我们将这个命令组合:"& ...
- 100行代码搞定抖音短视频App,终于可以和美女合唱了。
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由视频咖 发表于云+社区专栏 本文作者,shengcui,腾讯云高级开发工程师,负责移动客户端开发 最近抖音最近又带了一波合唱的节奏,老 ...