【系统设计】432. 全 O(1) 的数据结构
题目:
使用栈实现队列的下列操作: push(x) -- 将一个元素放入队列的尾部。
pop() -- 从队列首部移除元素。
peek() -- 返回队列首部的元素。
empty() -- 返回队列是否为空。
注意: 你只能使用标准的栈操作-- 也就是只有push to top, peek/pop from top, size, 和 is empty 操作是合法的。
你所使用的语言也许不支持栈。你可以使用 list 或者 deque (双端队列) 来模拟一个栈,只要是标准的栈操作即可。
假设所有操作都是有效的 (例如,一个空的队列不会调用 pop 或者 peek 操作)。
本题解题思路:
思考过程中考虑到可以用两个map来解决该问题,但发现比较麻烦,后自己写了一个解决方案:
核心数据结构:
struct DoubleListNode{
void * val;
DoubleListNode * pre;
DoubleListNode * next;
DoubleListNode(void * x):val(x){
pre = NULL;
next = NULL;
}
};
struct StrToken{
int counter;
set<string> strs;
};
用一个排序的双向链表来存储所有的key和key的计数,数列的计数从小到大。
如果返回最小计数的key,则返回队列中的头元素,如果返回最大计数的key,则返回队列的最末位的元素;
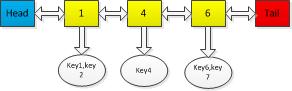
插入元素:
如果发现该key已经存在map中,则找到该节点,将该key插入到其计算加1的链表节点中去,同时更新map映射;如果发现该key不存在,则将该key插入到计算为1的节点中去,同时更新map映射。
删除元素:
如果发现该key已经存在map中,则找到该节点,将该key插入到其计算减一的链表节点中去同时更新MAP映射。
返回最大值:
由于链表是按照计算的大小排列的,返回链表中的最后端的元素即可。
返回最小值:
由于链表是按照计算的大小排列的,返回链表中的最前端的元素即可。
源代码如下,leetcode执行时间为40ms
struct DoubleListNode{
void * val;
DoubleListNode * pre;
DoubleListNode * next;
DoubleListNode(void * x):val(x){
pre = NULL;
next = NULL;
}
};
struct StrToken{
int counter;
set<string> strs;
};
class DoubleLinkList{
public:
DoubleLinkList(){
head = new DoubleListNode(NULL);
tail = new DoubleListNode(NULL);
head->next = tail;
tail->pre = head;
cnt = ;
}
bool insertHead(DoubleListNode * node){
if(NULL == node || NULL == head){
return false;
}
node->next = head->next;
node->pre = head;
head->next->pre = node;
head->next = node;
cnt++;
return true;
}
bool insertTail(DoubleListNode * node){
if(NULL == node || NULL == tail){
return false;
}
node->next = tail;
node->pre = tail->pre;
tail->pre->next = node;
tail->pre = node;
cnt++;
return true;
}
DoubleListNode * getHead(){
return this->head;
}
DoubleListNode * getTail(){
return this->tail;
}
DoubleListNode * getNext(const DoubleListNode * target){
if(NULL == target){
return NULL;
}
return target->next;
}
DoubleListNode * getPrev(const DoubleListNode * target){
if(NULL == target){
return NULL;
}
return target->pre;
}
bool isHead(const DoubleListNode * target){
if(head == target){
return true;
}else{
return false;
}
}
bool isTail(const DoubleListNode * target){
if(tail == target){
return true;
}else{
return false;
}
}
bool deleteTarget(DoubleListNode * node){
if(NULL == node || node == head || node == tail){
return false;
}
if(!node->pre || !node->next){
return false;
}
node->pre->next = node->next;
node->next->pre = node->pre;
node->next = NULL;
node->pre = NULL;
if(node->val){
delete node->val;
node->val = NULL;
}
delete node;
node = NULL;
return true;
}
bool insertBefore(DoubleListNode * target,DoubleListNode * node){
if(NULL == target || NULL == node){
return false;
}
node->pre = target->pre;
node->next = target;
target->pre->next = node;
target->pre = node;
cnt++;
return true;
}
bool insertAfter(DoubleListNode * target,DoubleListNode * node){
if(NULL == target || NULL == node){
return false;
}
node->pre = target;
node->next = target->next;
target->next->pre = node;
target->next = node;
cnt++;
return true;
}
int length(){
return cnt;
}
bool isEmpty(){
if(head->next == tail){
return true;
}else{
return false;
}
}
private:
struct DoubleListNode * head;
struct DoubleListNode * tail;
int cnt;
};
class AllOne {
public:
/** Initialize your data structure here. */
AllOne() {
}
/** Inserts a new key <Key> with value 1. Or increments an existing key by 1. */
void inc(string key) {
if(keyMap.find(key) == keyMap.end()){
/*we wiil insert the first node*/
DoubleListNode * head = keyList.getHead();
DoubleListNode * next = keyList.getNext(head);
StrToken * toke = (StrToken *)(next->val);
/*we will add a new node in to the linklist*/
if(keyList.isEmpty() || (toke != NULL && toke->counter > )){
StrToken * newToke = new StrToken();
newToke->counter = ;
newToke->strs.insert(key);
DoubleListNode * newNode = new DoubleListNode(newToke);
keyList.insertHead(newNode);
keyMap[key] = newNode;
}else{/*we add the key in to the token*/
if( NULL != toke && toke->counter == ){
toke->strs.insert(key);
keyMap[key] = next;
}
}
}else{
map<string,DoubleListNode *>::iterator it = keyMap.find(key);
DoubleListNode * node = it->second;
StrToken * toke = (StrToken *)(node->val);
toke->strs.erase(key);
DoubleListNode * next = keyList.getNext(node);
StrToken * nextToke = NULL;
if(next != keyList.getTail()){
nextToke = (StrToken *)(next->val);
}
if(next == keyList.getTail() ||
(nextToke!=NULL && nextToke->counter > (toke->counter+))){
StrToken * newToke = new StrToken();
newToke->counter = toke->counter+;
newToke->strs.insert(key);
DoubleListNode * newNode = new DoubleListNode(newToke);
keyList.insertAfter(node,newNode);
keyMap[key] = newNode;
}else{
if(nextToke){
nextToke->strs.insert(key);
keyMap[key] = next;
}
}
if(toke->strs.empty()){
keyList.deleteTarget(node);
}
}
//debug();
}
/** Decrements an existing key by 1. If Key's value is 1, remove it from the data structure. */
void dec(string key) {
if(keyMap.find(key) == keyMap.end()){
return;
}
map<string,DoubleListNode *>::iterator it = keyMap.find(key);
DoubleListNode * node = it->second;
StrToken * toke = (StrToken *)(node->val);
toke->strs.erase(key);
DoubleListNode * prev = keyList.getPrev(node);
StrToken * prevToke = NULL;
if(prev != keyList.getHead()){
prevToke = (StrToken *)(prev->val);
}
if(toke->counter > ){
if(prev == keyList.getHead() ||
(prevToke!=NULL && prevToke->counter < (toke->counter - ))){
StrToken * newToke = new StrToken();
newToke->counter = toke->counter - ;
newToke->strs.insert(key);
DoubleListNode * newNode = new DoubleListNode(newToke);
keyList.insertBefore(node,newNode);
keyMap[key] = newNode;
}else{
if(prevToke){
prevToke->strs.insert(key);
keyMap[key] = prev;
}
}
}else{
keyMap.erase(key);
}
if(toke->strs.empty()){
keyList.deleteTarget(node);
}
//debug();
}
/** Returns one of the keys with maximal value. */
string getMaxKey() {
string res;
if(keyList.isEmpty()){
return res;
}
DoubleListNode * node = keyList.getPrev(keyList.getTail());
StrToken * toke = (StrToken *)(node->val);
return *(toke->strs.begin());
}
/** Returns one of the keys with Minimal value. */
string getMinKey() {
string res;
if(keyList.isEmpty()){
return res;
}
DoubleListNode * node = keyList.getNext(keyList.getHead());
StrToken * toke = (StrToken *)(node->val);
return *(toke->strs.begin());
}
void debug(){
cout<<endl;
DoubleListNode * node = keyList.getNext(keyList.getHead());
for(;node!=keyList.getTail();node = keyList.getNext(node)){
StrToken * toke = (StrToken *)(node->val);
cout<<"cnt:"<<toke->counter<<endl;
set<string>::iterator it = toke->strs.begin();
for(;it!=toke->strs.end();++it){
cout<<*it<<" ";
}
cout<<endl;
}
}
private:
map<string,DoubleListNode *> keyMap;
DoubleLinkList keyList;
};
/**
* Your AllOne object will be instantiated and called as such:
* AllOne obj = new AllOne();
* obj.inc(key);
* obj.dec(key);
* string param_3 = obj.getMaxKey();
* string param_4 = obj.getMinKey();
*/
【系统设计】432. 全 O(1) 的数据结构的更多相关文章
- Java实现 LeetCode 432 全 O(1) 的数据结构
432. 全 O(1) 的数据结构 实现一个数据结构支持以下操作: Inc(key) - 插入一个新的值为 1 的 key.或者使一个存在的 key 增加一,保证 key 不为空字符串. Dec(ke ...
- [LeetCode] All O`one Data Structure 全O(1)的数据结构
Implement a data structure supporting the following operations: Inc(Key) - Inserts a new key with va ...
- leetcode难题
4 寻找两个有序数组的中位数 35.9% 困难 10 正则表达式匹配 24.6% 困难 23 合并K个排序链表 47.4% 困难 25 K ...
- C#LeetCode刷题-设计
设计篇 # 题名 刷题 通过率 难度 146 LRU缓存机制 33.1% 困难 155 最小栈 C#LeetCode刷题之#155-最小栈(Min Stack) 44.9% 简单 173 二叉搜索 ...
- Pandas_基础_全
Pandas基础(全) 引言 Pandas是基于Numpy的库,但功能更加强大,Numpy专注于数值型数据的操作,而Pandas对数值型,字符串型等多种格式的表格数据都有很好的支持. 关于Numpy的 ...
- Python全栈之路----目录
Module1 Python基本语法 Python全栈之路----编程基本情况介绍 Python全栈之路----常用数据类型--集合 Module2 数据类型.字符编码.文件操作 Python全栈之路 ...
- 《数据结构-C语言版》(严蔚敏,吴伟民版)课本源码+习题集解析使用说明
<数据结构-C语言版>(严蔚敏,吴伟民版)课本源码+习题集解析使用说明 先附上文档归类目录: 课本源码合辑 链接☛☛☛ <数据结构>课本源码合辑 习题集全解析 链接☛☛☛ ...
- 9-11-Trie树/字典树/前缀树-查找-第9章-《数据结构》课本源码-严蔚敏吴伟民版
课本源码部分 第9章 查找 - Trie树/字典树/前缀树(键树) ——<数据结构>-严蔚敏.吴伟民版 源码使用说明 链接☛☛☛ <数据结构-C语言版>(严蔚 ...
- 9-9-B+树-查找-第9章-《数据结构》课本源码-严蔚敏吴伟民版
课本源码部分 第9章 查找 - B+树 ——<数据结构>-严蔚敏.吴伟民版 源码使用说明 链接☛☛☛ <数据结构-C语言版>(严蔚敏,吴伟民版)课本源码+习题 ...
随机推荐
- 180602-nginx多域名配置
文章链接:https://liuyueyi.github.io/hexblog/2018/06/02/180602-nginx多域名配置/ nginx多域名配置 原来的域名过期了,重新买了一个hhui ...
- 【WXS全局对象】JSON
方法: 原型:JSON.stringify( Object ) 说明:将 object 对象转换为 JSON 字符串,并返回该字符串. 返回:[String] 原型:JSON.parse( [Stri ...
- vector的基础使用
vector是一个容器,实现动态数组. 相似点:下标从0开始. 不同点:vector创建对象后,容器大小会随着元素的增多或减少而变化. 基础操作: 1.使用vector需要添加头文件,#include ...
- Python入门(5)
导览: 函数 集合 迭代器与生成器 模块 一.函数 只要学过其他编程语言应该对函数不太陌生,函数在面向过程的编程语言中占据了极重要的地位,可以说没有函数,就没有面向过程编程,而在面向对象语言中,对象的 ...
- Case 降序升序排列
select nc.Class_Name,hn.home_news_id,hn.hemo_id,hn.hemo_Date, hn.hemo_title,hemo_order from Hemo_New ...
- Python3 标准库:sys
import sys print(sys.argv[0]) print(sys.argv[1]) print(len(sys.argv)) print(str(sys.argv)) print(sys ...
- iis 10 重新注册iis
iis 10 使用该命令 提示 版本不支持 C:\WINDOWS\system32>c:\windows\microsoft.net\framework64\v4.0.30319\aspnet_ ...
- LintCode-105.复制带随机指针的链表
复制带随机指针的链表 给出一个链表,每个节点包含一个额外增加的随机指针可以指向链表中的任何节点或空的节点. 返回一个深拷贝的链表. 挑战 可否使用O(1)的空间 标签 哈希表 链表 优步 code / ...
- PHP利用pcntl_exec突破disable_functions
http://fuck.0day5.com/?p=563 PHP突破Disable_functions执行Linux命令 利用dl函数突破disable_functions执行命令 http://ww ...
- Scala快速入门-基本数据结构
模式匹配 使用用模式匹配实现斐波那契 def fibonacci(in: Any): Int = in match { case 0 => 0 case 1 => 1 case n: In ...