Windows下基于python3使用word2vec训练中文维基百科语料(二)
在上一篇对中文维基百科语料处理将其转换成.txt的文本文档的基础上,我们要将为文本转换成向量,首先都要对文本进行预处理
步骤四:由于得到的中文维基百科中有许多繁体字,所以我们现在就是将繁体字转换成简体字
下载完成之后解压即可,随后使用命令:
opencc -i wiki.zh.text -o wiki.zh.jian.text -c t2s.json进行转换
#文章分词
import jieba
import jieba.analyse
import codecs
def cut_words(sentence):
#print sentence
return " ".join(jieba.cut(sentence)).encode('utf-8')
f=codecs.open('wiki.zh.jian.text','r',encoding="utf8")
target = codecs.open("wiki.zh.jian.seg.txt", 'w',encoding="utf8")
print ('open files')
line_num=1
line = f.readline()
while line:
print('---- processing', line_num, 'article----------------')
line_seg = " ".join(jieba.cut(line))
target.writelines(line_seg)
line_num = line_num + 1
line = f.readline()
f.close()
target.close()
exit()
while line:
curr = []
for oneline in line:
#print(oneline)
curr.append(oneline)
after_cut = map(cut_words, curr)
target.writelines(after_cut)
print ('saved',line_num,'articles')
exit()
line = f.readline1()
f.close()
target.close()
如图:分词完毕
步骤六:分词结束,就可以训练词向量啦
参数说明:
class gensim.models.word2vec.Word2Vec(sentences=None,size=100,alpha=0.025,window=5, min_count=5, max_vocab_size=None, sample=0.001,seed=1, workers=3,min_alpha=0.0001, sg=0, hs=0, negative=5, cbow_mean=1, hashfxn=<built-in function hash>,iter=5,null_word=0, trim_rule=None, sorted_vocab=1, batch_words=10000)
· sentences:可以是一个·ist,对于大语料集,建议使用BrownCorpus,Text8Corpus或·ineSentence构建。
· sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
· size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
· window:表示当前词与预测词在一个句子中的最大距离是多少
· alpha: 是学习速率
· seed:用于随机数发生器。与初始化词向量有关。
· min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
· max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
· sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)
· workers参数控制训练的并行数。
· hs: 如果为1则会采用hierarchica·softmax技巧。如果设置为0(defau·t),则negative sampling会被使用。
· negative: 如果>0,则会采用negativesamp·ing,用于设置多少个noise words
· cbow_mean: 如果为0,则采用上下文词向量的和,如果为1(defau·t)则采用均值。只有使用CBOW的时候才起作用。
· hashfxn: hash函数来初始化权重。默认使用python的hash函数
· iter: 迭代次数,默认为5
· trim_rule: 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RU·E_DISCARD,uti·s.RU·E_KEEP或者uti·s.RU·E_DEFAU·T的函数。
· sorted_vocab: 如果为1(defau·t),则在分配word index 的时候会先对单词基于频率降序排序。
· batch_words:每一批的传递给线程的单词的数量,默认为10000
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import logging
import os
import sys
import multiprocessing
wiki.zh.text.model wiki.zh.text.vector
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program) logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv)) # check and process input arguments
if len(sys.argv) < 4:
print(globals()['__doc__'] % locals())
sys.exit(1)
inp, outp1, outp2 = sys.argv[1:4] model = Word2Vec(LineSentence(inp), size=400, window=5, min_count=5,
workers=multiprocessing.cpu_count(),iter=100)#向量维度是400维,迭代100次 # trim unneeded model memory = use(much) less RAM
# model.init_sims(replace=True)
model.save(outp1)
model.wv.save_word2vec_format(outp2, binary=False)
使用命令开始训练
python train_word2vec_model.py wiki.zh.jian.seg.txt wiki.zh.text.model wiki.zh.text.vector
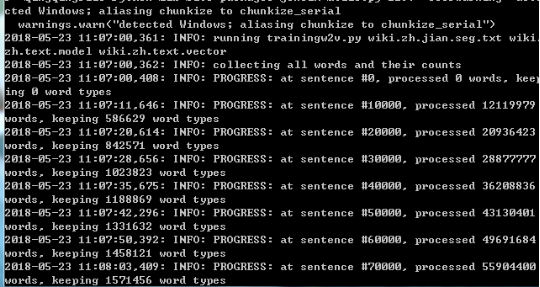
训练过程如下图:
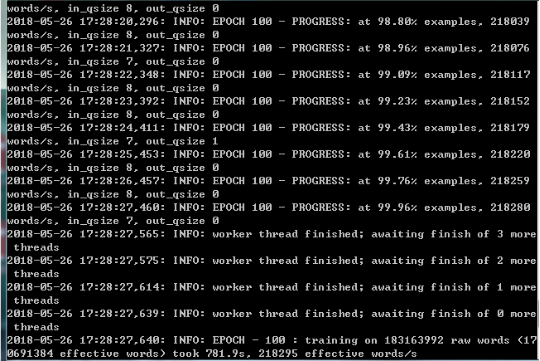
迭代到100轮:
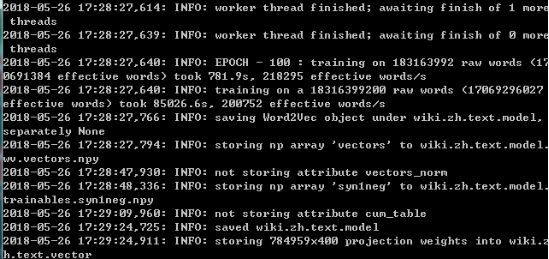
保存结果如图,表示结束:
这时候就表示训练好了,现在就可以开始使用啦!!!
Windows下基于python3使用word2vec训练中文维基百科语料(二)的更多相关文章
- Windows下基于python3使用word2vec训练中文维基百科语料(一)
在进行自然语言处理之前,首先需要一个语料,这里选择维基百科中文语料,由于维基百科是 .xml.bz2文件,所以要将其转换成.txt文件,下面就是相关步骤: 步骤一:下载维基百科中文语料 https:/ ...
- Windows下基于python3使用word2vec训练中文维基百科语料(三)
对前两篇获取到的词向量模型进行使用: 代码如下: import gensim model = gensim.models.Word2Vec.load('wiki.zh.text.model') fla ...
- 使用word2vec对中文维基百科数据进行处理
一.下载中文维基百科数据https://dumps.wikimedia.org/zhwiki/并使用gensim中的wikicorpus解析提取xml中的内容 二.利用opencc繁体转简体 三.利用 ...
- Windows下基于Python3安装Ipython Notebook(即Jupyter)。python –m pip install XXX
1.安装Python3.x,注意修改环境变量path(追加上python安装目录,如:D:\Program Files\Python\Python36-32) 2.查看当前安装的第三方包:python ...
- windows下基于sublime text3的nodejs环境搭建
第一步:先安装sublime text3.详细教程可自行百度,这边不具体介绍了. 第二步.安装nodejs插件,有两种方式 第一种方式:直接下载https://github.com/tanepiper ...
- Windows下安装Python3.4.2
一.Windows下安装Python3.4.2 1.下载Windows下的Python3.4.2.exe 2.指定一个目录安装,然后下一步 3.配置环境变量包括Python.exe的文件.目录如下图所 ...
- 环境搭建文档——Windows下的Python3环境搭建
前言 背景介绍: 自己用Python开发了一些安卓性能自动化测试的脚本, 但是想要运行这些脚本的话, 本地需要Python的环境. 测试组的同事基本都没有安装Python环境, 于是乎, 我就想直接在 ...
- word2vec训练中文模型
-- 这篇文章是一个学习.分析的博客 --- 1.准备数据与预处理 首先需要一份比较大的中文语料数据,可以考虑中文的维基百科(也可以试试搜狗的新闻语料库).中文维基百科的打包文件地址为 https: ...
- Windows下基于http的git服务器搭建-gitstack
版权声明:若无来源注明,Techie亮博客文章均为原创. 转载请以链接形式标明本文标题和地址: 本文标题:Windows下基于http的git服务器搭建-gitstack 本文地址:http: ...
随机推荐
- perf打印调用栈的过程
perf_prepare_sample-->perf_callchain-->get_perf_callchain 上面的调用栈会使用 perf_event_output--> 0x ...
- asp.net中缓存的使用
刚学到asp.net怎么缓存,这里推荐学习一下 www.cnblogs.com/wang726zq/archive/2012/09/06/cache.html http://blog.csdn.net ...
- HTML5拖拽练习
HTML5提供专门的拖拽与拖放的API,以后实现这类效果就不必乱折腾了 相关属性和事件如下: 1.DataTransfer 对象:退拽对象用来传递的媒介,使用一般为Event.dataTransfer ...
- 【bzoj1334】[Baltic2008]Elect 背包dp
题目描述 N个政党要组成一个联合内阁,每个党都有自己的席位数. 现在希望你找出一种方案,你选中的党的席位数要大于总数的一半,并且联合内阁的席位数越多越好. 对于一个联合内阁,如果某个政党退出后,其它党 ...
- Luogu3147 USACO16OPEN 262144(动态规划)
感觉上这个题是可以直接暴力的,每次根据一段连续最小值个数的奇偶性决定是否划分区间,递归处理.然而写起来实在太麻烦了. 设f[i][j]为以i为左端点合并出j时的右端点.则有f[i][j]=f[f[i] ...
- hdu 1142 A Walk Through the Forest (最短路径)
A Walk Through the Forest Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Jav ...
- 算法语言Scheme修订6报告 R6RS简体中文翻译
算法语言Scheme修订6报告 R6RS简体中文翻译 来源 https://r6rs.mrliu.org/ MICHAEL SPERBERR. KENT DYBVIG, MATTHEW FLATT ...
- redux的bindActionCreators
bindActionCreators是redux的一个API,作用是将单个或多个ActionCreator转化为dispatch(action)的函数集合形式. 开发者不用再手动dispatch(ac ...
- 两年Java的面试经验
前言:从过年前就萌生出要跳槽的想法,到过年来公司从3月初提出离职到23号正式离职,上班的时间也出去面试过几家公司,后来总觉的在职找工作总是得请假,便决心离职后找工作.到4月10号找到了一家互联网公司成 ...
- android 应用使用Root权限执行linux命令
要让Android应用使用Root权限,首先Android设备必须已经获得Root权限.之后可以通过下面的代码取得process对象. Process process = Runtime.getRun ...