OpenMp之false sharing
关于false sharing的文章,网上一大堆了,不过觉得都不太系统,那么下面着重系统说明一下。
先看看外国佬下的定义:
In symmetric multiprocessor (SMP) systems, each processor has a local cache. The memory system must guarantee cache coherence. False sharing occurs when threads on different processors modify variables that reside on the same cache line. This invalidates the cache line and forces an update, which hurts performance。
在多核系统上,每一个处理器都有自己的缓存。计算机体系结构中,必须要保证内存数据的一致性,当某个处理器对属于的它自己的缓存的变量执行更新操作时,糟糕的是那个变量所在的块也被其他的核放在了缓存里面,那么就会发生 false sharing,听起来比较难懂。
1.首先,什么是cache line?
CPU处理指令时,由于“Locality of Reference”原因,需要决定哪些数据需要加载到CPU的缓存中,以及如何预加载。
因为不同的处理器有不同的规范,导致这部分工作具有不确定性。在加载的过程中,涉及到一个非常关键的术语:cache line。
cache line是能被cache处理的内存chunks,chunk的大小即为cache line size,典型的大小为32,64及128 bytes. cache能处理的内存大小除以cache line size即为cache line。
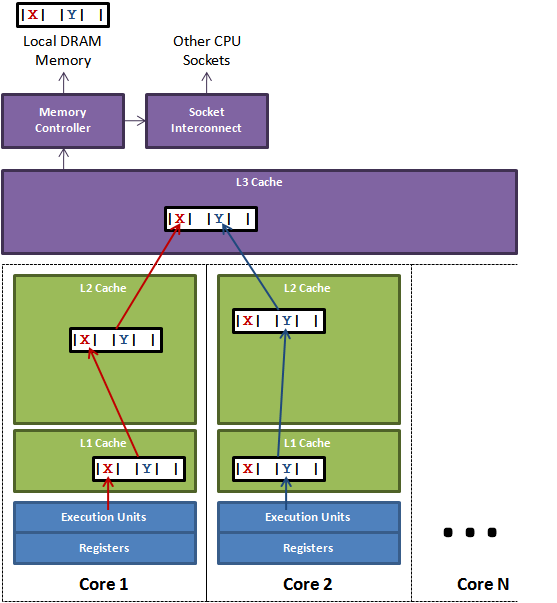
1) L1 Cache(一级缓存)是CPU第一层高速缓存,分为数据缓存和指令缓存。内置的L1高速缓存的容量和结构对CPU的性能影响较大,不过高速缓冲存储器均由静态RAM组成,结构较复杂,在CPU管芯面积不能太大的情况下,L1级高速缓存的容量不可能做得太大。
2) L2 Cache由于L1级高速缓存容量的限制,为了再次提高CPU的运算速度,在CPU外部放置一高速存储器,即二级缓存。工作主频比较灵活,可与CPU同 频,也可不同。CPU在读取数据时,先在L1中寻找,再从L2寻找,然后是内存,在后是外存储器。所以L2对系统的影响也不容忽视。
3) L3 Cache 现在的都是内置的。而它的实际作用即是,L3缓存的应用可以进一步降低内存延迟,同时提升大数据量计算时处理器的性能。降低内存延迟和提升大数据量计算能 力对游戏都很有帮助。而在服务器领域增加L3缓存在性能方面仍然有显著的提升。比方具有较大L3缓存的配置利用物理内存会更有效,故它比较慢的磁盘I/O 子系统可以处理更多的数据请求。具有较大L3缓存的处理器提供更有效的文件系统缓存行为及较短消息和处理器队列长度。
增加多级缓存的好处就是提高命中率,三级缓存的机器总体的命中率大约为95%,也就是大约有5%的数据从内存中读取,这样就大大提高了cpu的使用率。
2.cpu上cache的策略
cache entry (cache条目)
包含如下部分
1) cache line : 从主存一次copy的数据大小)
2) tag : 标记cache line对应的主存的地址
3) falg : 标记当前cache line是否invalid, 如果是数据cache, 还有是否dirty
cpu访问主存的规律
1) cpu从来都不直接访问主存, 都是通过cache间接访问主存
2) 每次需要访问主存时, 遍历一遍全部cache line, 查找主存的地址是否在某个cache line中.
3) 如果cache中没有找到, 则分配一个新的cache entry, 把主存的内存copy到cache line中, 再从cache line中读取.
cache中包含的cache entry条目有限, 所以, 必须有合适的cache淘汰策略
一般使用的是LRU策略.
将一些主存区域标记为non-cacheble, 可以提高cache命中率, 降低没用的cache
回写策略
cache中的数据更新后,需要回写到主存, 回写的时机有多种
1) 每次更新都回写. write-through cache
2) 更新后不回写,标记为dirty, 仅当cache entry被evict时才回写
3) 更新后, 把cache entry送如回写队列, 待队列收集到多个entry时批量回写.
cache一致性问题
有两种情况可能导致cache中的数据过期
1) DMA, 有其他设备直接更新主存的数据
2) SMP, 同一个cache line存在多个CPU各自的cache中. 其中一个CPU对其进行了更新.
3. false sharing是怎么产生的呢?
拿上面那个图为例子,core1拥有包含X和Y的数据块,core1会将其标记为“Exclusive”,就是专用的意思,当core2加载了相同的数据
块后(这点一点也不奇怪,因为操作系统的各个核之间的缓存调度是独立的),core1会将相同的块标记为“shared”,那么core2里面的在加载的
时候就会被标记“shared”。如果core1要对X进行修改(如果core2也要对X进行修改,那么会发生冲突,需要原子操作进行隔离,否则会发生错
误),core1就对XY数据块标记为“Modified”,并发送“Invalid”通知其他拥有相同数据块的处理器。如果此时core2要使用XY数
据块,那么被core1得知之后,core1就把它自己Cache里面的XY数据块回写到内存中,并将core1
cache里面的XY数据块重新标记为“shared”,而core2
cache里的XY数据块是“Invalid”,也就会产生一个miss,需要重新加载XY数据块,加载完成后将其标记为“shared”。
4. 怎么防止false sharing呢?
1)
字节对齐。因为缓存遵循”Locality of
Reference“,所以只要避免多个处理器Cache里面的数据块尽量不要”shared“就行了。如果上述的例子core1只有X数据
块,core2只有Y数据块,那么就不会存在false sharing。在windows的程序中使用__declspec(align(64))
加在变量核结构体之前,就能把变量或者结构体扩展成64个字节的数据,如果Cache的一个数据块是64byte的话,就只会加载一个变量,那么就不会发
生false sharing了,不过会造成一定的资源浪费。
__declspec (align(64)) int thread1_global_variable;
__declspec (align(64)) int thread2_global_variable
linux中可以使用__attribute__((aligned(64)))。两者的用法存在差异,具体怎么用下面会给一个linux的例子。
2)结构体填充。类似于上面的方法,不过是自己手动去填充数据块。下面是一个将结构体填充成64byte的例子:
struct ThreadParams
{
// For the following 4 variables: 4*4 = 16 bytes
unsigned long thread_id;
unsigned long v; // Frequent read/write access variable
unsigned long start;
unsigned long end;
// expand to 64 bytes
// (4 unsigned long variables + 12 padding)*4 = 64
int padding[];
}
3) 将数据线程私有化。也就是把可能会产生false sharing的数据块对每个线程copy一份,并重新命名,作为每个线程私有的东西,并在线程的最后一步同步到主线程中去。下面是一个例子:
struct ThreadParams
{
// For the following 4 variables: 4*4 = 16 bytes
unsigned long thread_id;
unsigned long v; //Frequent read/write access variable
unsigned long start;
unsigned long end;
};
void threadFunc(void *parameter)
{
ThreadParams *p = (ThreadParams*) parameter;
// local copy for read/write access variable
unsigned long local_v = p->v;
for(local_v = p->start; local_v < p->end; local_v++)
{
// Functional computation
}
p->v = local_v; // Update shared data structure only once
}
下面给出一个false sharing的例子,以及按照上面改进的方法:
#include<time.h>
#include<stdio.h>
#include<stdlib.h>
#include<omp.h> #define THREAD_NUM 4
int test(int i,int n,int* data);
int main(){ clock_t start,finish;
int n=40000000; int sum=0;
start=clock();
for(int i=0;i<n;i++)
{
sum+=2;
sum-=1;
} finish=clock();
printf("Serial computation\n");
printf("time:%lf,sum=%d\n",(double)(finish-start)/CLOCKS_PER_SEC,sum); printf("Parallel computation\n");
start=clock();
int sumarray[THREAD_NUM] ={0};
printf("sumarray bytes=%d\n",(int)(THREAD_NUM*sizeof(int)));
#pragma omp parallel num_threads(THREAD_NUM)
{
int nth=omp_get_num_threads();
int me=omp_get_thread_num();
clock_t t1,t2; t1=clock();
for(int i=me;i<n;i+=nth)
{
sumarray[me]+=2;
sumarray[me]-=1;
}
t2=clock();
printf("time:%lf\n",(double)(t2-t1)/CLOCKS_PER_SEC);
} finish=clock();
sum=0;
for(int i=0;i<THREAD_NUM;i++)
sum+=sumarray[i];
printf("Total time:%lf,sum=%d\n",(double)(finish-start)/CLOCKS_PER_SEC,sum); return 0;
}
运行结果:
Serial computation
time:0.201041,sum=40000000
Parallel computation
sumarray bytes=16
time:0.875622
time:0.904432
time:0.933348
time:0.939942
Total time:0.940346,sum=
效果真的惨不忍睹啊!因为存储结果的sumarray的字节只有16字节,所以每一个处理器下的cache line都会存储这个数据块,所以造成了false sharing,并行的效果比串行的要糟糕好多。
使用填充的方式进行改进,首先每一个数组中的int是4个字节,扩充成64字节,就要有60个字节的无用区域,很好办,把数组长度乘以16就行了,下面是改进的代码:
#include<time.h>
#include<stdio.h>
#include<stdlib.h>
#include<omp.h> #define THREAD_NUM 4
#define EXPAND 16
int test(int i,int n,int* data);
int main(){ clock_t start,finish;
int n=40000000; int sum=0;
start=clock();
for(int i=0;i<n;i++)
{
sum+=2;
sum-=1;
} finish=clock();
printf("Serial computation\n");
printf("time:%lf,sum=%d\n",(double)(finish-start)/CLOCKS_PER_SEC,sum); printf("Parallel computation\n");
start=clock();
int sumarray[THREAD_NUM*EXPAND] ={0};
printf("sumarray bytes=%d\n",(int)(EXPAND*THREAD_NUM*sizeof(int)));
#pragma omp parallel num_threads(THREAD_NUM)
{
int nth=omp_get_num_threads();
int me=omp_get_thread_num();
clock_t t1,t2; t1=clock();
for(int i=me;i<n;i+=nth)
{
sumarray[me*EXPAND]+=2;
sumarray[me*EXPAND]-=1;
}
t2=clock();
printf("time:%lf\n",(double)(t2-t1)/CLOCKS_PER_SEC);
} finish=clock();
sum=0;
for(int i=0;i<THREAD_NUM*EXPAND;i+=EXPAND)
sum+=sumarray[i];
printf("Total time:%lf,sum=%d\n",(double)(finish-start)/CLOCKS_PER_SEC,sum); return 0;
}
运行结果:
Serial computation
time:0.203828,sum=40000000
Parallel computation
sumarray bytes=256
time:0.158469
time:0.168066
time:0.173716
time:0.173987
Total time:0.184376,sum=
另外运行过程中,有时还是会出现很糟糕的情况,这个要看实际的Cache更新方法。
对字节进行扩展的方法:
#include<time.h>
#include<stdio.h>
#include<stdlib.h>
#include<omp.h> #define THREAD_NUM 4 struct A{
int i;
}__attribute__((aligned(64))); int test(int i,int n,int* data);
int main(){ clock_t start,finish;
int n=40000000; A sum={0};
start=clock();
for(int i=0;i<n;i++)
{
sum.i+=2;
sum.i-=1;
} finish=clock();
printf("Serial computation\n");
printf("time:%lf,sum=%d\n",(double)(finish-start)/CLOCKS_PER_SEC,sum.i); printf("Parallel computation\n");
start=clock();
A sumarray[THREAD_NUM] ={0};
printf("sumarray bytes=%d\n",(int)(THREAD_NUM*sizeof(A)));
#pragma omp parallel num_threads(THREAD_NUM)
{
int nth=omp_get_num_threads();
int me=omp_get_thread_num();
clock_t t1,t2; t1=clock();
for(int i=me;i<n;i+=nth)
{
sumarray[me].i+=2;
sumarray[me].i-=1;
}
t2=clock();
printf("time:%lf\n",(double)(t2-t1)/CLOCKS_PER_SEC);
} finish=clock(); int sum2=0;
for(int i=0;i<THREAD_NUM;i++)
sum2+=sumarray[i].i; printf("Total time:%lf,sum=%d\n",(double)(finish-start)/CLOCKS_PER_SEC,sum2); return 0;
}
运行结果:
Serial computation
time:0.216687,sum=40000000
Parallel computation
sumarray bytes=256
time:0.164040
time:0.195033
time:0.200804
time:0.201481
Total time:0.204139,sum=
再者就是私有化线程变量,例子如下:
#include<time.h>
#include<stdio.h>
#include<stdlib.h>
#include<omp.h> #define THREAD_NUM 4 int main(){ clock_t start,finish;
int n=40000000; int sum={0};
start=clock();
for(int i=0;i<n;i++)
{
sum+=2;
sum-=1;
} finish=clock();
printf("Serial computation\n");
printf("time:%lf,sum=%d\n",(double)(finish-start)/CLOCKS_PER_SEC,sum); printf("Parallel computation\n");
start=clock();
sum=0;
#pragma omp parallel num_threads(THREAD_NUM)
{
int nth=omp_get_num_threads();
int me=omp_get_thread_num();
clock_t t1,t2;
int mysum=0;
t1=clock();
for(int i=me;i<n;i+=nth)
{
mysum+=2;
mysum-=1;
}
t2=clock();
printf("time:%lf\n",(double)(t2-t1)/CLOCKS_PER_SEC);
#pragma omp atomic
sum+=mysum;
} finish=clock();
printf("Total time:%lf,sum=%d\n",(double)(finish-start)/CLOCKS_PER_SEC,sum); return 0;
}
#pragma omp atomic 是为了防止冲突而调用的omp的命令。
输出结果:
Serial computation
time:0.206015,sum=40000000
Parallel computation
time:0.152098
time:0.160297
time:0.161239
time:0.169079
Total time:0.174484,sum=
OpenMp之false sharing的更多相关文章
- 伪共享(false sharing),并发编程无声的性能杀手
在并发编程过程中,我们大部分的焦点都放在如何控制共享变量的访问控制上(代码层面),但是很少人会关注系统硬件及 JVM 底层相关的影响因素.前段时间学习了一个牛X的高性能异步处理框架 Disruptor ...
- 由一道淘宝面试题到False sharing问题
今天在看淘宝之前的一道面试题目,内容是 在高性能服务器的代码中经常会看到类似这样的代码: typedef union { erts_smp_rwmtx_t rwmtx; byte cache_line ...
- 并发性能的隐形杀手之伪共享(false sharing)
在并发编程过程中,我们大部分的焦点都放在如何控制共享变量的访问控制上(代码层面),但是很少人会关注系统硬件及 JVM 底层相关的影响因素.前段时间学习了一个牛X的高性能异步处理框架 Disruptor ...
- Java8使用@sun.misc.Contended避免伪共享(False Sharing)
伪共享(False Sharing) Java8中用sun.misc.Contended避免伪共享(false sharing) Java8使用@sun.misc.Contended避免伪共享
- 从缓存行出发理解volatile变量、伪共享False sharing、disruptor
volatilekeyword 当变量被某个线程A改动值之后.其他线程比方B若读取此变量的话,立马能够看到原来线程A改动后的值 注:普通变量与volatile变量的差别是volatile的特殊规则保证 ...
- 伪共享(False Sharing)和缓存行(Cache Line)
转载:https://www.jianshu.com/p/a9b1d32403ea https://www.toutiao.com/a6644375612146319886/ 前言 在上篇介绍Long ...
- Linux -- 在多线程程序中避免False Sharing
1.什么是false sharing 在对称多处理器(SMP)系统中,每个处理器均有属于自己的本地高速缓存区. 如图,CPU0和CPU1有各自的本地高速缓存区(cache).线程0和线程1会用到不同的 ...
- 并发刺客(False Sharing)——并发程序的隐藏杀手
并发刺客(False Sharing)--并发程序的隐藏杀手 前言 前段时间在各种社交平台"雪糕刺客"这个词比较火,简单的来说就是雪糕的价格非常高!其实在并发程序当中也有一个刺客, ...
- False 'Sharing Violation' Xcopy error message
今天想要将QC的新工具自动拷贝到p4 用户机器上使用,为了避免每次通知大家升级啊!!! 于是,我在程序里调用了bat文件,执行拷贝操作,想在默默的情况下替换更新新版本工具,结果我测试发现没能成功更新版 ...
随机推荐
- shell编程之数组和关联数组
一.数组类似c语言的数组 1.两种赋值方式 可以整体定义数组:ARRAY_NAME=(value0 value1 value2 value3 ...) 此时数组的下标默认是从0开始的 还可以单独定义数 ...
- Discuz! X3.1去除内置门户导航/portal.php尾巴的方法
方法: 打开文件 /source/admincp/admincp_domain.php 查找 [php] if(!empty($domain) && in_array($domain, ...
- 彻底理解js中this的指向
首先必须要说的是,this的指向在函数定义的时候是确定不了的,只有函数执行的时候才能确定this到底指向谁,实际上this的最终指向的是那个调用它的对象(这句话有些问题,后面会解释为什么会有问题,虽然 ...
- HDU 2529 Shot (物理数学题)
题目 解题过程: //物理数学题 #include<stdio.h> #include<string.h> #include<algorithm> using na ...
- uva 10564
Problem FPaths through the HourglassInput: Standard Input Output: Standard Output Time Limit: 2 Seco ...
- Twitter注册
Twitter注册 - (一般分享不了是回调地址不对) 1.打开twitter的官网https://dev.twitter.com,如果还没有注册账号的,需要注册账号,已经注册账号的,请先登录: 2. ...
- To Use Ubuntuubunt
1.rename PC; modify the /etc/hostname. 2.Use root account; 1.set the password for root account: sudo ...
- 神器——Chrome开发者工具(一)
这里我假设你用的是Chrome浏览器,如果恰好你做web开发,或者是比较好奇网页中的一些渲染效果并且喜欢折腾,那么你一定知道Chrome的开发者工具了.其实其他浏览器也有类似工具,比如Firefox下 ...
- 传说中的WCF(6):数据协定(b)
我们继续,上一回我们了解了数据协定的一部分内容,今天我们接着来做实验.好的,实验之前先说一句:实验有风险,写代码须谨慎. 实验开始!现在,我们定义两个带数据协定的类——Student和AddrInfo ...
- (转)两分钟彻底让你明白Android Activity生命周期(图文)!
转自: http://blog.csdn.net/android_tutor/article/details/5772285 大家好,今天给大家详解一下Android中Activity的生命周期,我在 ...