再论EM算法的收敛性和K-Means的收敛性
标签(空格分隔): 机器学习
(最近被一波波的笔试+面试淹没了,但是在有两次面试时被问到了同一个问题:K-Means算法的收敛性。在网上查阅了很多资料,并没有看到很清晰的解释,所以希望可以从K-Means与EM算法的关系,以及EM算法本身的收敛性证明中找到蛛丝马迹,下次不要再掉坑啊。。)
EM算法的收敛性
1.通过极大似然估计建立目标函数:
\(l(\theta) = \sum_{i=1}^{m}log\ p(x;\theta) = \sum_{i=1}^{m}log\sum_{z}p(x,z;\theta)\)
通过EM算法来找到似然函数的极大值,思路如下:
希望找到最好的参数\(\theta\),能够使最大似然目标函数取最大值。但是直接计算 \(l(\theta) = \sum_{i=1}^{m}log\sum_{z}p(x,z;\theta)\)比较困难,所以我们希望能够找到一个不带隐变量\(z\)的函数\(\gamma(x|\theta) \leq l(x,z;\theta)\)恒成立,并用\(\gamma(x|\theta)\)逼近目标函数。
如下图所示:
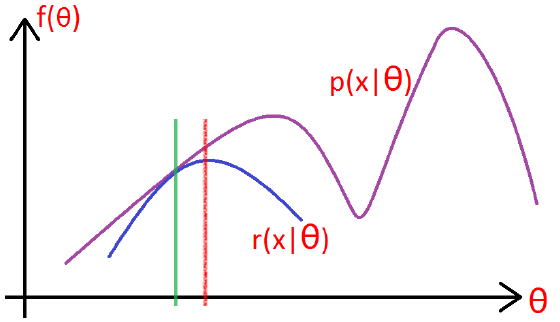
- 在绿色线位置,找到一个\(\gamma\)函数,能够使得该函数最接近目标函数,
- 固定\(\gamma\)函数,找到最大值,然后更新\(\theta\),得到红线;
- 对于红线位置的参数\(\theta\):
- 固定\(\theta\),找到一个最好的函数\(\gamma\),使得该函数更接近目标函数。
重复该过程,直到收敛到局部最大值。
2. 从Jensen不等式的角度来推导
令\(Q_{i}\)是\(z\)的一个分布,\(Q_{i} \geq 0\),则:
$l(\theta) = \sum_{i=1}^{m}log\sum_{z^{(i)}}p(x^{(i)},z^{(i)};\theta) $
$ = \sum_{i=1}^{m}log\sum_{z^{(i)}}Q_{i}(z^{(i)})\frac{p(x^{(i)},z^{(i)};\theta)}{Q_{i}(z^{(i)})}$
\(\geq \sum_{i=1}^{m}\sum_{z^{(i)}}Q_{i}(z^{(i)})log\frac{p(x^{(i)},z^{(i)};\theta)}{Q_{i}(z^{(i)})}\)
(对于log函数的Jensen不等式)
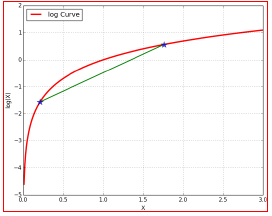
3.使等号成立的Q
尽量使\(\geq\)取等号,相当于找到一个最逼近的下界:也就是Jensen不等式中,\(\frac{f(x_{1})+f(x_{2})}{2} \geq f(\frac{x_{1}+x_{2}}{2})\),当且仅当\(x_{1} = x_{2}\)时等号成立(很关键)。
对于EM的目标来说:应该使得\(log\)函数的自变量恒为常数,即:
\(\frac{p(x^{(i)},z^{(i)};\theta)}{Q_{i}(z^{(i)})} = C\)
也就是分子的联合概率与分母的z的分布应该成正比,而由于\(Q\)是z的一个分布,所以应该保证\(\sum_{z}Q_{i}(z^{(i)}) = 1\)
故\(Q = \frac{p}{p对z的归一化因子}\)
\(Q_{i}(z^{(i)}) = \frac{p(x^{(i)},z^{(i)};\theta)}{\sum_{z}p(x^{(i)},z^{(i)};\theta)}\)
\(= \frac{p(x^{(i)},z^{(i)};\theta)}{p(x^{(i)};\theta)} = p(z^{(i)}|x^{(i)};\theta)\)
4.EM算法的框架
由上面的推导,可以得出EM的框架:
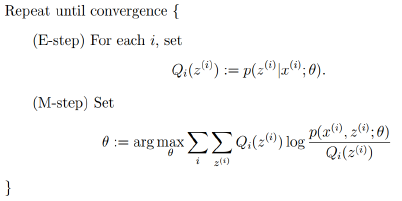
回到最初的思路,寻找一个最好的\(\gamma\)函数来逼近目标函数,然后找\(\gamma\)函数的最大值来更新参数\(\theta\):
- E-step: 根据当前的参数\(\theta\)找到一个最优的函数\(\gamma\)能够在当前位置最好的逼近目标函数;
- M-step: 对于当前找到的\(\gamma\)函数,求函数取最大值时的参数\(\theta\)的值。
K-Means的收敛性
通过上面的分析,我们可以知道,在EM框架下,求得的参数\(\theta\)一定是收敛的,能够找到似然函数的最大值。那么K-Means是如何来保证收敛的呢?
目标函数
假设使用平方误差作为目标函数:
\(J(\mu_{1},\mu_{2},...,\mu_{k}) = \frac{1}{2}\sum_{j=1}^{K}\sum_{i=1}^{N}(x_{i}-\mu_{j})^{2}\)
E-Step
固定参数\(\mu_{k}\), 将每个数据点分配到距离它本身最近的一个簇类中:
\[
\gamma_{nk} =
\begin{cases}
1, & \text{if $k = argmin_{j}||x_{n}-\mu_{j}||^{2}$ } \\
0, & \text{otherwise}
\end{cases}
\]
M-Step
固定数据点的分配,更新参数(中心点)\(\mu_{k}\):
\(\mu_{k} = \frac{\sum_{n}\gamma_{nk}x_{n}}{\sum_{n}\gamma_{nk}}\)
所以,答案有了吧。为啥K-means会收敛呢?目标是使损失函数最小,在E-step时,找到一个最逼近目标的函数\(\gamma\);在M-step时,固定函数\(\gamma\),更新均值\(\mu\)(找到当前函数下的最好的值)。所以一定会收敛了~
再论EM算法的收敛性和K-Means的收敛性的更多相关文章
- EM算法总结
EM算法总结 - The EM Algorithm EM是我一直想深入学习的算法之一,第一次听说是在NLP课中的HMM那一节,为了解决HMM的参数估计问题,使用了EM算法.在之后的MT中的词对齐中也用 ...
- EM算法(Expectation Maximization Algorithm)初探
1. 通过一个简单的例子直观上理解EM的核心思想 0x1: 问题背景 假设现在有两枚硬币Coin_a和Coin_b,随机抛掷后正面朝上/反面朝上的概率分别是 Coin_a:P1:-P1 Coin_b: ...
- 机器学习之高斯混合模型及EM算法
第一部分: 这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与k-means一样,给定的训练样本是,我们将隐含类 ...
- EM算法【转】
混合高斯模型和EM算法 这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与K-means一样,给定的训练样本是, ...
- 【转】EM算法原理
EM是我一直想深入学习的算法之一,第一次听说是在NLP课中的HMM那一节,为了解决HMM的参数估计问题,使用了EM算法.在之后的MT中的词对齐中也用到了.在Mitchell的书中也提到EM可以用于贝叶 ...
- EM 算法求解高斯混合模型python实现
注:本文是对<统计学习方法>EM算法的一个简单总结. 1. 什么是EM算法? 引用书上的话: 概率模型有时既含有观测变量,又含有隐变量或者潜在变量.如果概率模型的变量都是观测变量,可以直接 ...
- EM算法原理详解
1.引言 以前我们讨论的概率模型都是只含观测变量(observable variable), 即这些变量都是可以观测出来的,那么给定数据,可以直接使用极大似然估计的方法或者贝叶斯估计的方法:但是当模型 ...
- EM算法及其推广
概述 EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计. EM算法的每次迭代由两步组成:E步,求期望(expectation): ...
- EM算法定义及推导
EM算法是一种迭代算法,传说中的上帝算法,俗人可望不可及.用以含有隐变量的概率模型参数的极大似然估计,或极大后验概率估计 EM算法定义 输入:观测变量数据X,隐变量数据Z,联合分布\(P(X,Z|\t ...
随机推荐
- java 网络编程(三)---TCP的基础级示例
下面是TCP java网络编程的基础示例: tcp传输:客户端建立过程的思路:1.创建TCP客户端的Socket服务,使用的是socket对象,建议在创建的过程中,就明确了目的地和要连接的主机2.如果 ...
- SQL SERVER: 合并相关操作(Union,Except,Intersect) - 转载
SQL Server 中对于结果集有几个处理,值得讲解一下 1. 并集(union,Union all) 这个很简单,是把两个结果集水平合并起来.例如 SELECT * FROM A UNION SE ...
- NOIP201208同余方程
NOIP201208同余方程 描述 求关于x的同余方程ax ≡ 1 (mod b)的最小正整数解. 格式 输入格式 输入只有一行,包含两个正整数a, b,用一个空格隔开. 输出格式 输出只有一行,包含 ...
- 字符串核对之Boyer-Moore算法
算法说明: 在计算机科学里,Boyer-Moore字符串搜索算法是一种非常高效的字符串搜索算法.它由Bob Boyer和J Strother Moore设计于1977年.此算法仅对搜索目标字符串(关键 ...
- ubuntu硬件配置查看命令
主板:sudo dmidecode |grep -A16 "System Information$"
- Linux之awk命令详解
简介 awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再 ...
- Backup: Numbers in Perl6
Perl6 is a new language, not a improved version of Perl5. Perl6 inherits many good features from man ...
- FormData对象实现文件Ajax上传
后台: import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; imp ...
- IE11打不开网页, 所有菜单都被禁用了。
估计是安装完PPS之后,PPS安装程序附加了一些加载项到浏览器,而我在安装时强制禁用了它的加载项引起的. 解决方法是重置IE设置,命令为:inetcpl.cpl,点击高级选项卡的重置即可.
- 4.1HTML和Bootstrap css精华
1.HTML 2.理解Bootstrap HTML元素告诉浏览器,他要表现的是什么类型的内容,当他们不提供任何关于如何显示内容的信息.如何显示内容的信息,由CSS提供. 本书仅包含足够的信息,让你查看 ...