梯度下降之随机梯度下降 -minibatch 与并行化方法
问题的引入:
考虑一个典型的有监督机器学习问题,给定m个训练样本S={x(i),y(i)},通过经验风险最小化来得到一组权值w,则现在对于整个训练集待优化目标函数为:
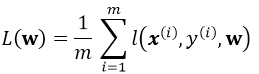
其中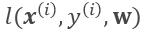 为单个训练样本(x(i),y(i))的损失函数,单个样本的损失表示如下:
为单个训练样本(x(i),y(i))的损失函数,单个样本的损失表示如下:
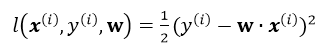
引入L2正则,即在损失函数中引入 ,那么最终的损失为:
,那么最终的损失为:
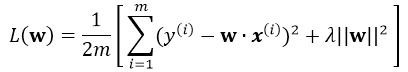
注意单个样本引入损失为(并不用除以m):
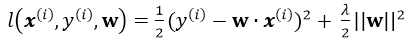
正则化的解释
这里的正则化项可以防止过拟合,注意是在整体的损失函数中引入正则项,一般的引入正则化的形式如下:
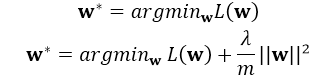
其中L(w)为整体损失,这里其实有:

这里的 C即可代表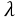 ,比如以下两种不同的正则方式:
,比如以下两种不同的正则方式:
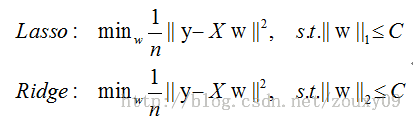
下面给一个二维的示例图:我们将模型空间限制在w的一个L1-ball 中。为了便于可视化,我们考虑两维的情况,在(w1, w2)平面上可以画出目标函数的等高线,而约束条件则成为平面上半径为C的一个 norm ball 。等高线与 norm ball 首次相交的地方就是最优解
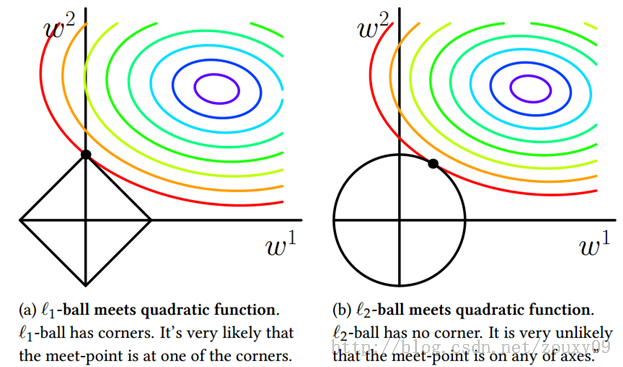
可以看到,L1-ball 与L2-ball 的不同就在于L1在和每个坐标轴相交的地方都有“角”出现,而目标函数的测地线除非位置摆得非常好,大部分时候都会在角的地方相交。注意到在角的位置就会产生稀疏性,例如图中的相交点就有w1=0,而更高维的时候(想象一下三维的L1-ball 是什么样的?)除了角点以外,还有很多边的轮廓也是既有很大的概率成为第一次相交的地方,又会产生稀疏性,相比之下,L2-ball 就没有这样的性质,因为没有角,所以第一次相交的地方出现在具有稀疏性的位置的概率就变得非常小了。
因此,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
Batch Gradient Descent
有了以上基本的优化公式,就可以用Gradient Descent 来对公式进行求解,假设w的维度为n,首先来看标准的Batch Gradient Descent算法:
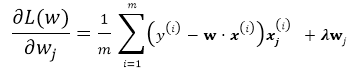
repeat until convergency{
for j=1;j<n ; j++:
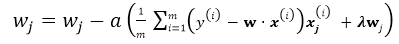
}
这里的批梯度下降算法是每次迭代都遍历所有样本,由所有样本共同决定最优的方向。
stochastic Gradient Descent
随机梯度下降就是每次从所有训练样例中抽取一个样本进行更新,这样每次都不用遍历所有数据集,迭代速度会很快,但是会增加很多迭代次数,因为每次选取的方向不一定是最优的方向.
repeat until convergency{
random choice j from all m training example:
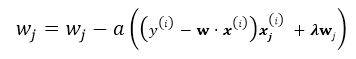
}
mini-batch Gradient Descent
这是介于以上两种方法的折中,每次随机选取大小为b的mini-batch(b<m), b通常取10,或者(2...100),这样既节省了计算整个批量的时间,同时用mini-batch计算的方向也会更加准确。
repeat until convergency{
for j=1;j<n ; j+=b:

}
最后看并行化的SGD:

若最后的v达到收敛条件则结束执行,否则回到第一个for循环继续执行,该方法同样适用于minibatch gradient descent。
梯度下降之随机梯度下降 -minibatch 与并行化方法的更多相关文章
- NN优化方法对照:梯度下降、随机梯度下降和批量梯度下降
1.前言 这几种方法呢都是在求最优解中常常出现的方法,主要是应用迭代的思想来逼近.在梯度下降算法中.都是环绕下面这个式子展开: 当中在上面的式子中hθ(x)代表.输入为x的时候的其当时θ參数下的输出值 ...
- 对数几率回归法(梯度下降法,随机梯度下降与牛顿法)与线性判别法(LDA)
本文主要使用了对数几率回归法与线性判别法(LDA)对数据集(西瓜3.0)进行分类.其中在对数几率回归法中,求解最优权重W时,分别使用梯度下降法,随机梯度下降与牛顿法. 代码如下: #!/usr/bin ...
- 机器学习算法(优化)之一:梯度下降算法、随机梯度下降(应用于线性回归、Logistic回归等等)
本文介绍了机器学习中基本的优化算法—梯度下降算法和随机梯度下降算法,以及实际应用到线性回归.Logistic回归.矩阵分解推荐算法等ML中. 梯度下降算法基本公式 常见的符号说明和损失函数 X :所有 ...
- 机器学习(ML)十五之梯度下降和随机梯度下降
梯度下降和随机梯度下降 梯度下降在深度学习中很少被直接使用,但理解梯度的意义以及沿着梯度反方向更新自变量可能降低目标函数值的原因是学习后续优化算法的基础.随后,将引出随机梯度下降(stochastic ...
- 梯度下降VS随机梯度下降
样本个数m,x为n维向量.h_theta(x) = theta^t * x梯度下降需要把m个样本全部带入计算,迭代一次计算量为m*n^2 随机梯度下降每次只使用一个样本,迭代一次计算量为n^2,当m很 ...
- 梯度下降、随机梯度下降、方差减小的梯度下降(matlab实现)
梯度下降代码: function [ theta, J_history ] = GradinentDecent( X, y, theta, alpha, num_iter ) m = length(y ...
- online learning,batch learning&批量梯度下降,随机梯度下降
以上几个概念之前没有完全弄清其含义及区别,容易混淆概念,在本文浅析一下: 一.online learning vs batch learning online learning强调的是学习是实时的,流 ...
- L20 梯度下降、随机梯度下降和小批量梯度下降
airfoil4755 下载 链接:https://pan.baidu.com/s/1YEtNjJ0_G9eeH6A6vHXhnA 提取码:dwjq 梯度下降 (Boyd & Vandenbe ...
- 梯度下降法VS随机梯度下降法 (Python的实现)
# -*- coding: cp936 -*- import numpy as np from scipy import stats import matplotlib.pyplot as plt # ...
随机推荐
- sqoop导入hdfs上的数据到oracle
/opt/sqoop-/bin/sqoop export --table mytablename --connect jdbc:oracle:thin:@**.**.**.**:***:dbasena ...
- java基础知识回顾之javaIO类---FileInputStream和FileOutputStream字节流复制图片
package com.lp.ecjtu; import java.io.FileInputStream; import java.io.FileNotFoundException; import j ...
- 控制台console输出信息原理理解
Eclipse控制台输出信息的控制 标签: Eclipse控制台输出信息 2015-01-02 14:11 22454人阅读 评论(1) 收藏 举报 分类: Some Tips(15) 版权声明: ...
- soa思想,就是远程服务调用
dubbo是Java下的一套RPC框架(soa思想)
- iOS App 唤醒另一个App
网上也有讲这块的,感觉讲得都不是很好.而且有一些细节根本没有讲清楚.这里重写整理一下相关知识点. 主要内容 URL Scheme 是什么? 项目中关键的配置 注意事项 URL Scheme 是什么? ...
- DXT纹理压缩
转:http://blog.csdn.net/lhc717/article/details/6802951 我们知道游戏中对于3D物体表面细节的表现最重要的还是靠贴图来实现的,那么越是高分辨率越是真彩 ...
- DB2 基本概念
DB2基本概念——实例,数据库,模式,表空间 DB2支持以下两种类型的表空间: 1. 系统管理存储器表空间(SMS-SYSTEM MANAGED STORAGE) 2. 数 ...
- USACO Section 4.2: Drainage Ditches
最大流的模板题 /* ID: yingzho1 LANG: C++ TASK: ditch */ #include <iostream> #include <fstream> ...
- AE 栅格图分级渲染
ArcEngine对矢量数据进行风格化实在是得心应手,同样的对于栅格图像也能进行风格化!以前没接触过,今天正好需要,做出了栅格图像的渲染!下面实现的思路: 1.定义渲染的一系列接口 2.判断图像是否建 ...
- R.id.layout等不能识别:cannot be resolved or is not a field
Do not modify the R class. The error means there's something syntactically wrong with your XML layou ...