一步一步理解word2Vec
一、概述
关于word2vec,首先需要弄清楚它并不是一个模型或者DL算法,而是描述从自然语言到词向量转换的技术。词向量化的方法有很多种,最简单的是one-hot编码,但是one-hot会有维度灾难的缺点,而且one-hot编码中每个单词都是互相独立的,不能刻画词与词之间的相似性。目前最具有代表性的词向量化方法是Mikolov基于skip-gram和negative sampling开发的,也是大家通常所认为的word2vec。这种方法基于分布假设(Distributed Hypothesis)理论,认为不同的词语如果出现在相同的上下文环境中就会有的相似的语义。word2vec最终将向量表示为低维的向量,具有相似语义的单词的向量之间的距离会比较小,部分词语之间的关系能够用向量的运算表示。例如 vec("Germany")+vec("capital")=vec("Berlin")。tensorflow官网中有关于word2vec的教程,可视化的结果非常直接的表现了word2vec的优点。这篇笔记尝试一步一步梳理word2vec,主要是skip-gram和negative sampling,大部分的内容来自于参考资料1,资料1是国外MIT博士word2vec的解读,最为总结学习非常适合。
二、skip-gram 模型
skip-gram是简单的三层网络模型,由输入、映射和输出三层组成。skip-gram是神经网络语言模型的一种,与CBOW相反,skip-gram是由目标词汇来预测上下文词汇,最终目标是最大化语料库Text出现的概率。例如:语料库为“the quick brown fox jumped over the lazy dog”(实际语料库中单词的数量会很非常大),当上下文窗口为1时,skip-gram的任务是从‘quick’预测‘the’和‘brown’,从‘brown’预测‘quick’和‘fox’...因此训练skip-gram的输入输出对(input,output)为:(quick, the), (quick, brown), (brown, quick), (brown, fox), ...
假设给定语料库Text,w是Text中的一个单词,c是w的上下文,skip-gram的目标是最大化语料库Text的概率。theta 是模型的参数,C(w)是单词w的上下文,skip-gram的目标函数如下:
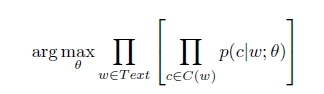
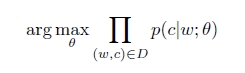
使用softmax表示条件概率p(c|w),Vc,Vw分别表示单词c和w的向量表示,C表示所有可能的上下文,就是语料库Text中所有不同的单词。
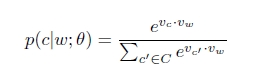
取对数,最终得到skip-gram的目标函数:
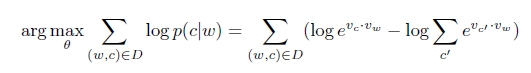
这个目标函数由于需要对所有可能的c‘求和,c’的数量为整个语料库Text中的词,一般会非常大,因此优化上述的目标是的计算代价是非常大的。有两种方法解决这个问题,一是使用层级softmax(Hierarchy softmax)代替softmax,另一种使用Negative sampling。看paper发现两种方法的效果都挺不错的,但是Mikolov挺推荐使用Negative sampling的。
三、Negative sampling
Mikolov 在paper证实了Negative sampling 非常高效。实际上,negative sampling 基于skip-gram模型的,但是使用了另一个优化函数。它的基本思想是考虑(w,c)对是不是来自训练数据,p(D=1|w,c)表示这个(w,c)队来自于语料库,p(D=0|w,c)=1-p(D=1|w,c)表示(w,c)队不是来自于语料库Text。现在优化的目标是:
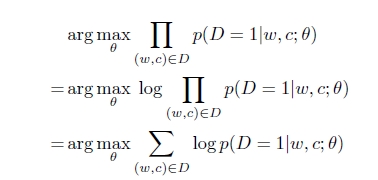
p(D=1|w,c)可以使用sofmax,准确的来说是逻辑回归表示:
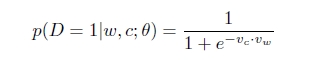
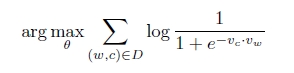
这个目标函数有一个非常简单的解,迭代调整theta使得Vc=Vw,Vc.Vw=k,当比较大的时候k≈40时,p(D=1|w,c)=1,很显然这并不是我们所要的解。我们需要一种机制去防止所有的向量都相等,一种方法是给模型提供一些(w,c)对,使得p(D=1|w,c)=1很小,例如这些(w,c)对并不是Text中真实存在的,而是随机产生的,这就称之为“Negative sampling”。这些随机产生的(w,c)对组成集合D‘。因此最终的Negative sampling 的优化函数如下所示,可以看出求解的计算量并不是很大。Mikolov 在论文中提到,对高频词汇做二次抽样(subsampling)和去除出现次数非常少的词(pruning rare-word)不仅能加快训练的速度,而且能提高模型的准确度,效果会更好。
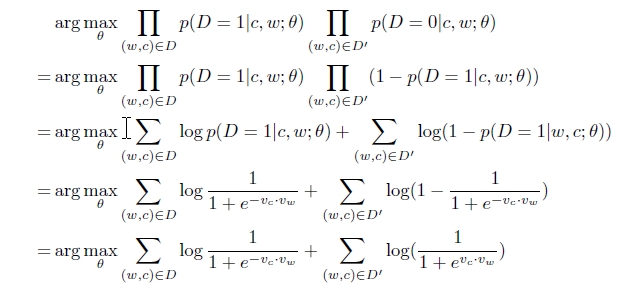
四、实现
参考tennsorflow官方教程:https://www.tensorflow.org/versions/r0.9/tutorials/word2vec/index.html
reference:
[1]. word2vec Explained: Deriving Mikolov et al.'s Negative-Sampling Word-Embedding Method
[2]. Distributed Representations of Words and Phrases and their Compositionality
[3]. Vector Representations of Words
[4]. 深度学习word2Vec笔记
一步一步理解word2Vec的更多相关文章
- 一步一步理解GB、GBDT、xgboost
GBDT和xgboost在竞赛和工业界使用都非常频繁,能有效的应用到分类.回归.排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的.本文尝试一步一步梳理GB.GBDT.xgboost,它们 ...
- 一步一步理解Paxos算法
一步一步理解Paxos算法 背景 Paxos 算法是Lamport于1990年提出的一种基于消息传递的一致性算法.由于算法难以理解起初并没有引起人们的重视,使Lamport在八年后重新发表到 TOCS ...
- 一步一步的理解C++STL迭代器
一步一步的理解C++STL迭代器 "指针"对全部C/C++的程序猿来说,一点都不陌生. 在接触到C语言中的malloc函数和C++中的new函数后.我们也知道这两个函数返回的都是一 ...
- 一步一步理解 python web 框架,才不会从入门到放弃 -- 开始使用 Django
背景知识 要使用 Django,首先必须先安装 Django. 下图是 Django 官网的版本支持,我们可以看到上面有一个 LTS 存在.什么是 LTS 呢?LTS ,long-term suppo ...
- 一步一步理解线段树——转载自JustDoIT
一步一步理解线段树 目录 一.概述 二.从一个例子理解线段树 创建线段树 线段树区间查询 单节点更新 区间更新 三.线段树实战 -------------------------- 一 概述 线段 ...
- NLP(二十九)一步一步,理解Self-Attention
本文大部分内容翻译自Illustrated Self-Attention, Step-by-step guide to self-attention with illustrations and ...
- 如何一步一步用DDD设计一个电商网站(九)—— 小心陷入值对象持久化的坑
阅读目录 前言 场景1的思考 场景2的思考 避坑方式 实践 结语 一.前言 在上一篇中(如何一步一步用DDD设计一个电商网站(八)—— 会员价的集成),有一行注释的代码: public interfa ...
- 如何一步一步用DDD设计一个电商网站(八)—— 会员价的集成
阅读目录 前言 建模 实现 结语 一.前言 前面几篇已经实现了一个基本的购买+售价计算的过程,这次再让售价丰满一些,增加一个会员价的概念.会员价在现在的主流电商中,是一个不大常见的模式,其带来的问题是 ...
- 如何一步一步用DDD设计一个电商网站(十)—— 一个完整的购物车
阅读目录 前言 回顾 梳理 实现 结语 一.前言 之前的文章中已经涉及到了购买商品加入购物车,购物车内购物项的金额计算等功能.本篇准备把剩下的购物车的基本概念一次处理完. 二.回顾 在动手之前我对之 ...
随机推荐
- Zookeeper注册节点的掉线自动重新注册及测试方法
转载:http://www.codelast.com/ 在一套分布式的online services系统中,各service通常不会放在一台服务器上,而是通过Zookeeper这样的东西,将自己的se ...
- __attribute__特性介绍以及变量和函数特定布局设置
ARM的MDK编译__attribute__介绍:http://infocenter.arm.com/help/index.jsp?topic=/com.arm.doc.dui0348bc/Ciafc ...
- BZOJ1579 [Usaco2009 Feb]Revamping Trails 道路升级
各种神作不解释QAQQQ 先是写了个作死的spfa本机过了交上去T了... 然后不想写Dijkstra各种自暴自弃... 最后改了一下步骤加了个SLF过了... 首先一个trivial的想法是$dis ...
- 警卫安排(dp好题)
警卫安排(guard)[题目描述]一个重要的基地被分为 n 个连通的区域.出于某种神秘的原因,这些区域以一个区域为核心,呈一颗树形分布.在每个区域安排警卫所需要的费用是不同的,而每个区域的警卫都可以望 ...
- 基于K2 BPM的大型连锁企业开关店选址管理解决方案
业内有句名言:“门店最重要的是什么?第一是选址,第二是选址,第三还是选址” 选址是一个很复杂的综合性商业决策过程,需要定性考虑和定向分析.K2开关店&选址管理方案重点关注:如何开出更好的店?在 ...
- 蓝桥杯 BASIC_17 矩阵乘法 (矩阵快速幂)
问题描述 给定一个N阶矩阵A,输出A的M次幂(M是非负整数) 例如: A = 1 2 3 4 A的2次幂 7 10 15 22 输入格式 第一行是一个正整数N.M(1<=N<=30, 0& ...
- 启用jboss热部署
Please make sure to add <configuration> <jsp-configuration deve ...
- JVM-class文件完全解析-字段表集合
字段表集合 这个class文件的解析,分析得有点太久了.前面介绍类魔数,次版本号,主板本号,常量池入口,常量池,访问标志,类索引,父类索引和接口索引集合.下面就应该到字段表集合了. 紧接着接口索引 ...
- 根据username查找user
返回的是一个list<User>,不过验证密码的时候,要求返回是一个user对象,如果用uniqueresult,这个是过时的方法,如果用getResultList 会得到一个列表,get ...
- 提交自己的插件包(package)
安装 把下列命令粘贴到终端上: mkdir -p ~/Library/Application\ Support/Developer/Shared/Xcode/Plug-ins; curl -L htt ...