SQL Server-聚焦LEFT JOIN...IS NULL AND NOT EXISTS性能分析(十七)
前言
本节我们来分析LEFT JOIN和NOT EXISTS,简短的内容,深入的理解,Always to review the basics。
LEFT JOIN...IS NULL和NOT EXISTS分析
之前我们已经分析过IN查询在处理空值时是基于三值逻辑,只要子查询中存在空值此时则没有任何数据返回,而LEFT JOIN和NOT EXISTS无论子查询中有无空值上处理都是一样的,当然比较重要的是利用LEFT JOIN...IS NULL来检查NULL。基于二者返回的结果集是一样的,下面我们开始直接用前面节所创建表来进行测试。在BigTable和SmallerTable上首先未创建索引
USE TSQL2012
GO DBCC FREEPROCCACHE
DBCC DROPCLEANBUFFERS SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT BigTable.ID, SomeColumn
FROM BigTable LEFT OUTER JOIN SmallerTable ON BigTable.SomeColumn = SmallerTable.LookupColumn
WHERE LookupColumn IS NULL SELECT ID, SomeColumn FROM BigTable
WHERE NOT EXISTS (SELECT LookupColumn FROM SmallerTable WHERE SmallerTable.LookupColumn = BigTable.SomeColumn)
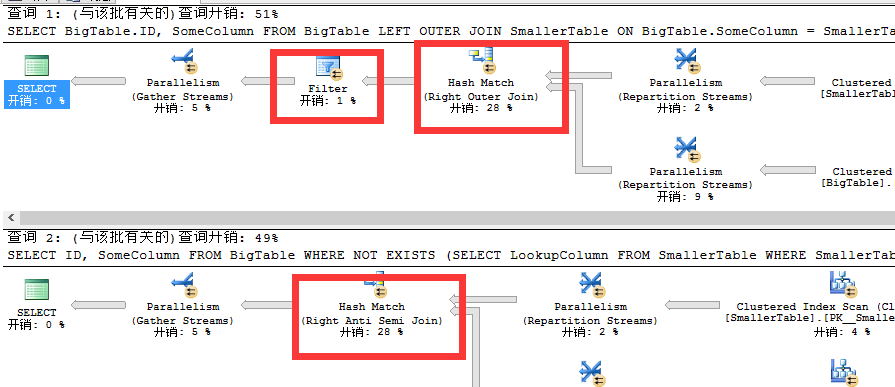
二者执行CPU Time和elapsed Time如下

我们看到上述查询计划未创建索引之前二者在开销上接近一致,而LEFT JOIN....IS NULL则首先进行哈希匹配中的右外部联接,然后就是过滤,换句话说是LEFT JOIN....IS NULL会直接完全JOIN,然后再对重复数据进行过滤,而NOT EXISTS则是直接利用哈希匹配中的右半联接,关于半联接我们在前面也已经说过,此时若有重复数据直接只取一个。所以LEFT JOIN....IS NULL和NOT EXISTS二者对于重复数据一个通过两部操作完成先完全JOIN后进行过滤,而另外一个则是直接通过右半联接过滤。所以对于此二者最大的不同在于:当使用LEFT JOIN.....IS NULL时,SQL还没有那么聪明,仅仅只检查一次,因此它需要通过完全JOIN和过滤来完成,而NOT EXISTS则是在JOIN时就进行过滤。
在看二者执行CPU TIME和elapsed TIME时间,没有太大的差异。接下来我们再来创建索引看看。
CREATE INDEX idx_BigTable_SomeColumn
ON BigTable (SomeColumn) CREATE INDEX idx_SmallerTable_LookupColumn
ON SmallerTable (LookupColumn)
看看二者的查询执行计划
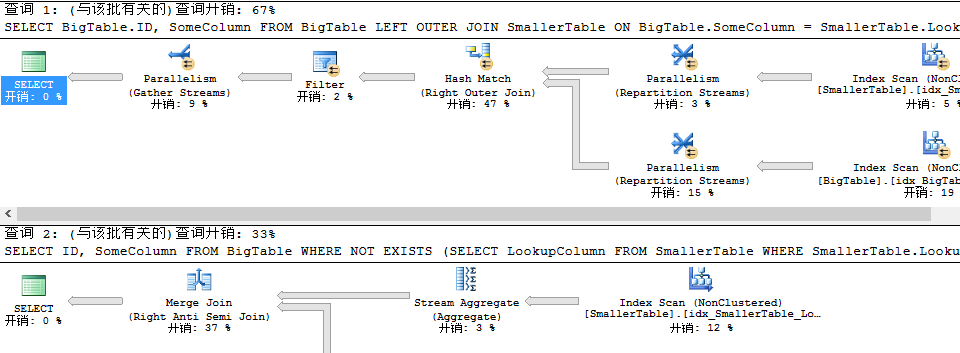

此时我们通过看到上述查询执行计划,我们能够清楚的看到LEFT JOIN....IS NULL还是完全JOIN然后在过滤,只是创建了索引之后性能改善了一点而已,但是不同于LEFT JOIN...IS NULL的NOT EXISTS的计划执行情况不同于未创建索引,此时首先利用了流聚合然后哈希匹配中的右半联接变成了合并联接中的右半联接,我们一个个来看,这个Stream Aggregate(流聚合)是什么鬼,对于此流聚合我是不了解的,不能装懂,我们接下来具体讲讲流聚合,至于为什么每当查询计划出现一个新的名词都要去详细了解下的原因,相信看过我SQL Server本系列的童鞋知道,每一节的内容都非常短,不会出现阅读疲劳,而且是精讲,我重头系统学习SQL Server是为了对SQL Server中所有涉及到对性能调优有关的地方以及一些基础知识都会去过一遍,以便后续再出现性能调优不至于束手无策。好了,回到话题,我们看看Stream Aggregate。
Stream Aggregate
msdn上有关概念如下:Stream Aggregate运算符按一列或多列对行分组,然后计算查询返回的一个或多个聚合表达式。此运算符的输出可供查询中的后续运算符引用和/或返回到客户端。Stream Aggregate 运算符要求输入在组中按列进行排序。如果由于前面的 Sort 运算符或已排序的索引查找或扫描导致数据尚未排序,优化器将在此运算符前面使用一个 Sort 运算符。在 SHOWPLAN_ALL 语句或 SQL Server Management Studio 的图形执行计划中,GROUP BY 谓词中的列会列在 Argument 列中,而聚合表达式列在 Defined Values 列中。
通过上述定义仅仅只是知道Stream Aggregate是用对行或者列进行聚合,至于什么时候在查询计划中出现流聚合,什么时候利用流聚合来提高查询性能都是不得而知,我们接下来一起探讨下。上述着重在于【分组】然后进行【聚合】计算,基于这点我们来看看使用Stream Aggregate的三种场景。
(1)聚合汇总
USE TSQL2012
GO SELECT COUNT(custid) AS cutid, SUM(empid) AS empid
FROM Sales.Orders

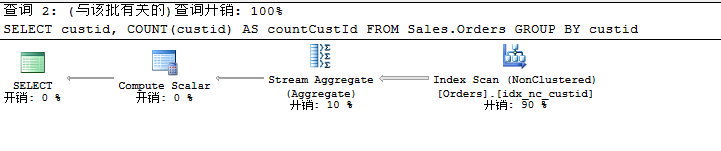
(2)先分组,再聚合汇总
USE TSQL2012
GO SELECT custid, COUNT(custid) AS countCustId
FROM Sales.Orders
GROUP BY custid
(3)DISTINCT汇总
USE TSQL2012
GO SELECT DISTINCT custid
FROM Sales.Orders

上述查询使用通过DISTINCT,实际上是对cutid进行了分组。以上是用到了Stream Aggregate的场景,当然聚合还有另外一种就是哈希匹配聚合,后续会再进行补充。我们再来理解Stream Aggregate定义,我们将定义概括为对输入进行排序后,接下来进行分组然后再进行聚合计算。在上述(2)和(3)中都是进行了分组,但是没有排序,实际上内部已经默认实现了排序,我们看下在(3)中表中custid数据,如下
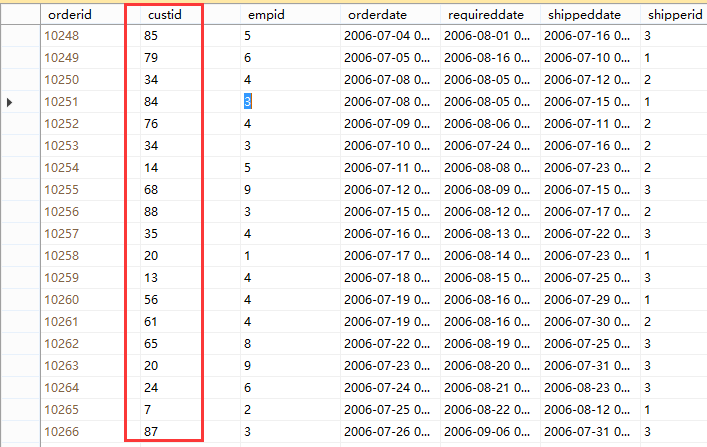
当进行DISTINCT之后

但是在(3)中没有进行聚合,为什么会进行流聚合呢?实际上在流聚合中存在状态变量,状态变量具体个数根据聚合个数而定,此状态变量用来设置结果集,当进行分组后对应的数据进行保存,此时对应的状态变量为0,当匹配到对应数据时此时状态变量加1,所以上述(3)中可以说隐式进行了聚合计算,只是每条数据对应的状态变量为0而已,到了这里就不难解释,只进行了排序,分组而没有进行聚合计算的原因。关于Stream Aggregate都知道的一个例子则是我们在利用SqlDataReader记性读取数据时,可以说是读取流记录,如果我们需要汇总结果集时,此时每当Read时,其内部的状态变量都会加1最终返回汇总和到客户端。在这里我们只是简单讲讲Stream Aggregate,后续会一并讲讲Hash Aggregate。我们继续回到LEFT JOIN....IS NULL和NOT EXISTS话题,当我们创建索引之后此时LEFT JOIN....IS ISNULL执行时间是NOT EXISITS的两倍多。到此,关于LEFT JOIN...IS NULL和NOT EXISTS就此结束,我们同样下个基本结论。
LEFT JOIN...IS NULL和NOT EXISTS性能分析结论:当我们需要找到子查询中不匹配的行并且列为可空时,此时用NOT EXISTS,当需要找到子查询中不匹配的行,此时列不为空时可以用NOT EXISTS或者NOT IN。
由于LEFT JOIN..IS NULL对于不匹配的行不会立即进行返回而先需要完全JOIN后过滤,尤其是当有多个条件时,LEFT JOIN...IS NULL可能会更加影响查询性能。
总结
本节我们学习了LEFT JOIN..IS NULL和NOT EXISTS的性能分析,下节我们进入这几节内容的综合篇,综合比较NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL终极篇。简短的内容,深入的理解,我们下节再会。
SQL Server-聚焦LEFT JOIN...IS NULL AND NOT EXISTS性能分析(十七)的更多相关文章
- sql server几种Join的区别测试方法与union表的合并
/* sql server几种Join的区别测试方法 主要来介绍下Inner Join , Full Out Join , Cross Join , Left Join , Right Join的区别 ...
- SQL Server中INNER JOIN与子查询IN的性能测试
这个月碰到几个人问我关于"SQL SERVER中INNER JOIN 与 IN两种写法的性能孰优孰劣?"这个问题.其实这个概括起来就是SQL Server中INNER JOIN与子 ...
- SQL Server 排序的时候使 null 值排在最后
https://www.cnblogs.com/Brambling/p/7046148.html 最近遇到一个 SQL Server 排序的问题,以前也没了解过,然后这次碰到了. 才发现 SQL Se ...
- SQL Server nested loop join 效率试验
从很多网页上都看到,SQL Server有三种Join的算法, nested loop join, merge join, hash join. 其中最常用的就是nested loop join. 在 ...
- SQL Server 的字段不为NULL时唯一
CREATE UNIQUE NONCLUSTERED INDEX 索引名称ON 表名(字段) WHERE 字段 is not null SQL Server 2008+ 支持
- Excel数据导入Sql Server,部分数字为Null
在Excel中,我们时常会碰到这样的字段(最常见的就是电话号码),即有纯数字的(如没有带区号的电话号码),又有数字和其它字符混合 (如“区号-电 话号码”)的数据,在导入SQLServer过程中,会发 ...
- SQL Server中多表连接时驱动顺序对性能的影响
本文出处:http://www.cnblogs.com/wy123/p/7106861.html (保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错 ...
- 复习一下sql server的inner join left join 和right join
1.left join sql语句如下: select * from A left join B on A.aID = B.bID 结果如下:aID aNum ...
- SQL Server之LEFT JOIN、RIGHT LOIN、INNER JOIN的区别
很多人刚入门的时候分不清LEFT JOIN.RIGHT LOIN 和 INNER JOIN的区别,对它们的定义比较模糊,今天就简单的介绍一下它们的区别,对于入门的人来说,应该能够帮助你们理解. lef ...
随机推荐
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
- javascript之活灵活现的Array
前言 就如同标题一样,这篇文章将会灵活的运行Array对象的一些方法来实现看上去较复杂的应用. 大家都知道Array实例有这四个方法:push.pop.shift.unshift.大家也都知道 pus ...
- C++11特性——变量部分(using类型别名、constexpr常量表达式、auto类型推断、nullptr空指针等)
#include <iostream> using namespace std; int main() { using cullptr = const unsigned long long ...
- 【原创分享·微信支付】C# MVC 微信支付之微信模板消息推送
微信支付之微信模板消息推送 今天我要跟大家分享的是“模板消息”的推送,这玩意呢,你说用途嘛,那还是真真的牛逼呐.原因在哪?就是因为它是依赖微信生存的呀,所以他能不 ...
- input标签中button在iPhone中圆角的问题
1.问题 使用H5编写微信页面时,使用<input type="button"/>时,在Android手机中显示正常,但是在iPhone手机中则显示不正常,显示为圆角样 ...
- Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 一.传统方式 这种方式就是常用的TableInputFormat和TableOutputForm ...
- [译]处理文本数据(scikit-learn 教程3)
原文网址:http://scikit-learn.org/stable/tutorial/text_analytics/working_with_text_data.html 翻译:Tacey Won ...
- web 前端(轮番插件)
<!DOCTYPE html> <html lang="zh-cn"> <head> <meta charset="UTF-8& ...
- JavaScript基础
JavaScript基础 JavaScript是一门编程语言,浏览器内置了JavaScript语言的解释器,所以在浏览器上按照JavaScript语言的规则编写相应代码之,浏览器可以解释并做出相应的处 ...
- 移动BPM解决方案分享
畅通开放 无边界的渠道 效率倍增 更高效的处理方式 即时共享 更强大的决策能力 各种终端应用 帮您实现:新任务通知.任务预警.催办.任务审批.任何数据汇总提醒消息通知...... 短信 客户端: ...