Caffe-windows上训练自己的数据
1.数据获取
在网上选择特定类别,下载相应的若干张图片。可以网页另存或者图片下载器。本例中保存了小狗、菊花、梅花三类各两百多张。

2.重命名
import os
import os.path
rootdir = "jh"
i=1
for parent,dirnames,filenames in os.walk(rootdir):
for filename in filenames:
newName=a+str(i)+".jpg"
print filename+" -> "+newName
os.rename(os.path.join(parent,filename), os.path.join(parent, newName))
i+=1
3.更改分辨率
from PIL import Image
import glob, os
w,h = 256,256
def timage():
for files in glob.glob('jh\*.jpg'):
filepath,filename = os.path.split(files)
filterame,exts = os.path.splitext(filename)
opfile = r'jh\jhout\\'
if (os.path.isdir(opfile)==False):
os.mkdir(opfile)
im=Image.open(files)
im_ss=im.resize((int(w), int(h)))
try:
im_ss.save(opfile+filterame+'.jpg')
except:
print filterame
os.remove(opfile+filterame+'.jpg') if __name__=='__main__':
timage()
4.获取标签
import glob, os, shutil
def timage():
names=["gg","jh"]
t=open("train.txt",'a')
v=open("val.txt",'a')
for files in glob.glob('jh\jhout\*.jpg'):
filepath,filename = os.path.split(files)
filterame,exts = os.path.splitext(filename)
oldfile = r'jh\jhout\\'
opfile = r'val\\'
if (os.path.isdir(opfile)==False):
os.mkdir(opfile)
if 200< int(filterame[2:]): # test data
shutil.move(oldfile+filterame+'.jpg',opfile+filterame+'.jpg')
v.write(filterame+'.jpg '+str(names.index("jh"))+'\n')
else: # train data
t.write('jhout/'+filterame+'.jpg '+str(names.index("jh"))+'\n')
t.close()
v.close() if __name__=='__main__':
timage()
5.生成对应的leveldb格式数据
SET GLOG_logtostderr=
Build\x64\Release\convert_imageset.exe examples/t/train/ examples/t/train/train.txt examples/t/trainldb
pause
SET GLOG_logtostderr=
Build\x64\Release\convert_imageset.exe examples/t/val/ examples/t/val/val.txt examples/t/valldb
pause
6.计算均值
SET GLOG_logtostderr=
Build\x64\Release\compute_image_mean.exe examples/t/trainldb examples/t/tmean.binaryproto
pause
7.修改网络
models/bvlc_alexnet/train_val.prototxt
修改其中的num_output, batch_size和相应的路径
solver.prototxt如下,其中gamma指的是在学习率为step模式化下,每400次迭代变为原来的0.9倍。
net: "examples/t/train_val.prototxt"
test_iter:
test_interval:
base_lr: 0.0001
lr_policy: "step"
gamma: 0.9
stepsize:
display:
max_iter:
momentum: 0.9
weight_decay: 0.001
snapshot:
snapshot_prefix: "caffe_train"
solver_mode: GPU
8.训练网络
cd ../../
"Build/x64/Release/caffe.exe" train --solver=examples/t/solver.prototxt
pause
9.运行结果
在仅使用小狗和菊花两类,训练200张测试50张,可以达到98%的正确率。
使用小狗、菊花、梅花三类,可以达到89%的正确率。
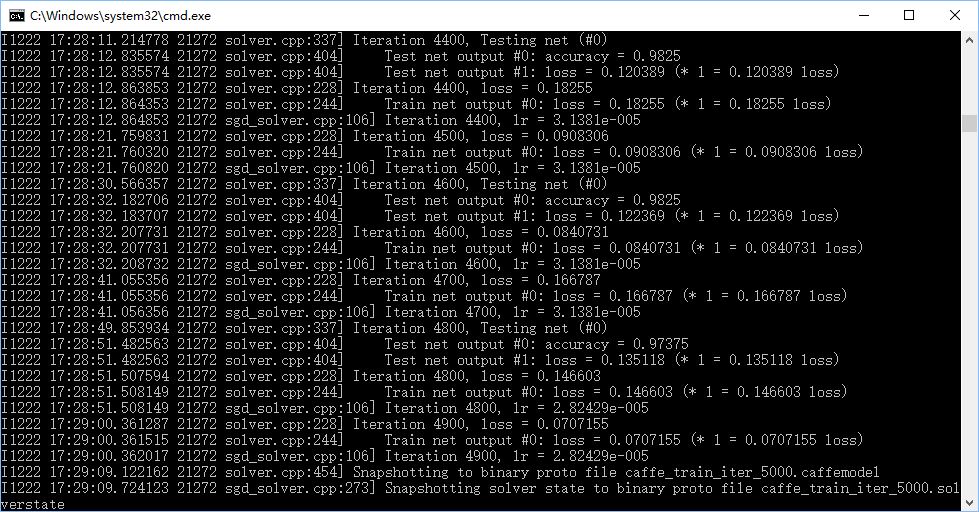
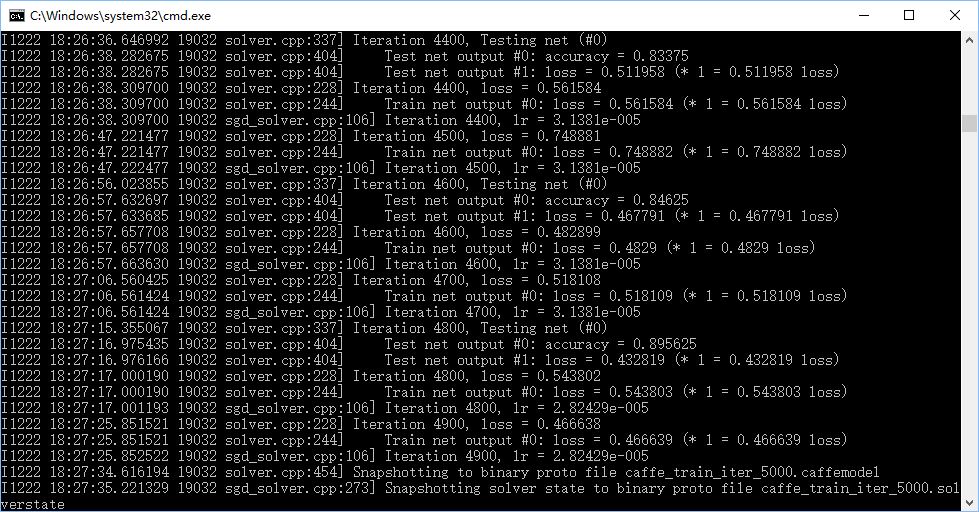
10.优化
之前将train_val.prototxt中的crop_size: 227改成了128,速度相对快很多。
在三类分类中改回227,正确率在92%左右波动,进一步修改base_lr: 0.00015,gamma: 0.93,正确率可以达到94.6%。
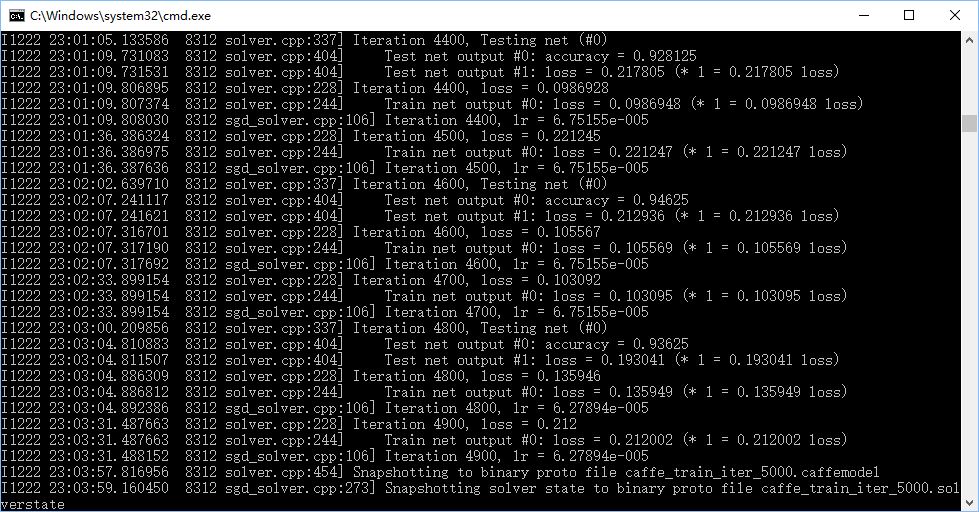
Caffe-windows上训练自己的数据的更多相关文章
- 【神经网络与深度学习】深度学习实战——caffe windows 下训练自己的网络模型
1.相关准备 1.1 手写数字数据集 这篇博客上有.jpg格式的图片下载,附带标签信息,有需要的自行下载,博客附带百度云盘下载地址(手写数字.jpg 格式):http://blog.csdn.net/ ...
- caffe 利用VGG训练自己的数据
写这个是因为有童鞋在跑VGG的时候遇到各种问题,供参考一下. 网络结构 以VGG16为例,自己跑的细胞数据 solver.prototxt: net: "/media/dl/source/E ...
- caffe 如何训练自己的数据图片
申明:此教程加工于caffe 如何训练自己的数据图片 一.准备数据 有条件的同学,可以去imagenet的官网http://www.image-net.org/download-images,下载im ...
- rsync (windows 服务端,linux客户端)将windows上的数据同步到linux服务器,反之也可
一:总体概述. 1.windows上面首先装CW_rsync_Server.4.1.0_installer,安装时要输入的用户名密码要记住哦!接下来就是找到rsyncd.conf进入配置细节 2.li ...
- 大数据高性能数据库Redis在Windows上的使用教程
Redis学习笔记----Redis在windows上的安装配置和使用 Redis简介 redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括s ...
- Windows上快速编译caffe CPU版本
windows上快速安装配置Caffe的 cpu_only环境. 一:安装环境: 1.windows10: 2.Visual Studio2013: 3.Caffe版本:http://github.c ...
- caffe学习三:使用Faster RCNN训练自己的数据
本文假设你已经完成了安装,并可以运行demo.py 不会安装且用PASCAL VOC数据集的请看另来两篇博客. caffe学习一:ubuntu16.04下跑Faster R-CNN demo (基于c ...
- 在GPU上训练数据
在GPU上训练数据 模型搬到GPU上 数据搬到GPU上 损失函数计算搬到GPU上
- caffe 用faster rcnn 训练自己的数据 遇到的问题
1 . 怎么处理那些pyx和.c .h文件 在lib下有一些文件为.pyx文件,遇到不能import可以cython 那个文件,然后把lib文件夹重新make一下. 遇到.c 和 .h一样的操作. 2 ...
随机推荐
- C# 展开和折叠代码的快捷键(总结)
C# 展开和折叠代码的快捷键 VS2005代码编辑器的展开和折叠代码确实很方便和实用.以下是展开代码和折叠代码所用到的快捷键,很常用: Ctrl + M + O: 折叠所有方法 Ctrl + M + ...
- IOS 用keychain(钥匙串)保存用户名和密码
IOS系统中,获取设备唯一标识的方法有很多: 一.UDID(Unique Device Identifier) UDID的全称是Unique Device Identifier,顾名思义,它就是苹果I ...
- iOS 关于UIWindow 的认识
UIWindow是一种特殊的UIView,通常在一个app中只会有一个UIWindow iOS程序启动完毕后,创建的第一个视图控件就是UIWindow,接着创建控制器的view,最后将控制器的view ...
- "This connection is untrusted" - Firefox error message
Error Messages I am receiving the following error message in Firefox: After selecting Cancel to clos ...
- python数据分析入门——matplotlib的中文显示问题&最小二乘法
正在学习<用python做科学计算>,在练习最小二乘法时遇到matplotlib无法显示中文的问题.查资料,感觉动态的加上几条语句是最好,这里贴上全部的代码. # -*- coding: ...
- Python运算符与表达式
Python运算符包括赋值运算符.算术运算符.关系运算符.逻辑运算符.位运算符.成员运算符和身份运算符. 表达式是将不同类型的数据(常亮.变量.函数)用运算符按照一定得规则连接起来的式子. 算术运算符 ...
- 【LeetCode】Best Time to Buy and Sell Stock IV
Best Time to Buy and Sell Stock IV Say you have an array for which the ith element is the price of a ...
- sqlserver中自定义函数+存储过程实现批量删除
由于项目的需要,很多模块都要实现批量删除的功能.为了方便模块的调用,把批量删除方法写成自定义函数.直接上代码. 自定义函数: ALTER FUNCTION [dbo].[func_SplitById] ...
- simple grammer
<?phpecho strlen("Hello world!"); // outputs 12?> <?phpecho str_word_count(" ...
- 测试题1 IOS面试基础题
免责声明:答案来自本人,错误之处敬请谅解 1.用变量a写出以下定义 a.一个整型数 int a=5; b.一个指向整型数的指针 int *a; c.一个指向指针的指针,它指向的指针是指向一个整 ...