k-means聚类算法python实现
K-means聚类算法
算法优缺点:
优点:容易实现
缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢
使用数据类型:数值型数据
算法思想
k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去。
1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好。另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚类你可能就会考虑分成三类(L,M,S)等
2.然后我们需要选择最初的聚类点(或者叫质心),这里的选择一般是随机选择的,代码中的是在数据范围内随机选择,另一种是随机选择数据中的点。这些点的选择会很大程度上影响到最终的结果,也就是说运气不好的话就到局部最小值去了。这里有两种处理方法,一种是多次取均值,另一种则是后面的改进算法(bisecting K-means)
3.终于我们开始进入正题了,接下来我们会把数据集中所有的点都计算下与这些质心的距离,把它们分到离它们质心最近的那一类中去。完成后我们则需要将每个簇算出平均值,用这个点作为新的质心。反复重复这两步,直到收敛我们就得到了最终的结果。
函数
loadDataSet(fileName)
从文件中读取数据集distEclud(vecA, vecB)
计算距离,这里用的是欧氏距离,当然其他合理的距离都是可以的randCent(dataSet, k)
随机生成初始的质心,这里是虽具选取数据范围内的点kMeans(dataSet, k, distMeas=distEclud, createCent=randCent)
kmeans算法,输入数据和k值。后面两个事可选的距离计算方式和初始质心的选择方式show(dataSet, k, centroids, clusterAssment)
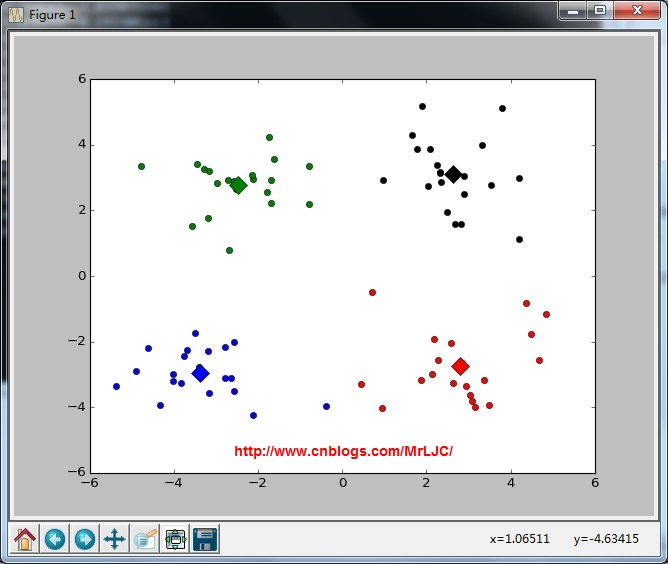
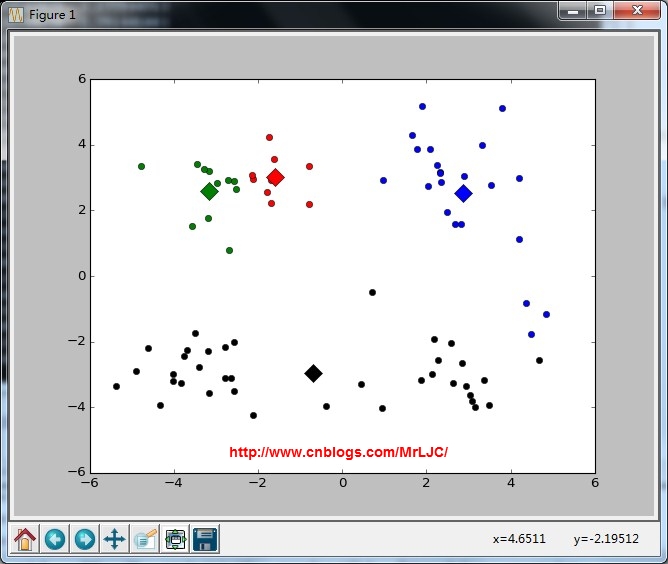
可视化结果
#coding=utf-
from numpy import * def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = map(float, curLine)
dataMat.append(fltLine)
return dataMat #计算两个向量的距离,用的是欧几里得距离
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, ))) #随机生成初始的质心(ng的课说的初始方式是随机选K个点)
def randCent(dataSet, k):
n = shape(dataSet)[]
centroids = mat(zeros((k,n)))
for j in range(n):
minJ = min(dataSet[:,j])
rangeJ = float(max(array(dataSet)[:,j]) - minJ)
centroids[:,j] = minJ + rangeJ * random.rand(k,)
return centroids def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[]
clusterAssment = mat(zeros((m,)))#create mat to assign data points
#to a centroid, also holds SE of each point
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):#for each data point assign it to the closest centroid
minDist = inf
minIndex = -
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
if clusterAssment[i,] != minIndex:
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**
print centroids
for cent in range(k):#recalculate centroids
ptsInClust = dataSet[nonzero(clusterAssment[:,].A==cent)[]]#get all the point in this cluster
centroids[cent,:] = mean(ptsInClust, axis=) #assign centroid to mean
return centroids, clusterAssment def show(dataSet, k, centroids, clusterAssment):
from matplotlib import pyplot as plt
numSamples, dim = dataSet.shape
mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
for i in xrange(numSamples):
markIndex = int(clusterAssment[i, ])
plt.plot(dataSet[i, ], dataSet[i, ], mark[markIndex])
mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']
for i in range(k):
plt.plot(centroids[i, ], centroids[i, ], mark[i], markersize = )
plt.show() def main():
dataMat = mat(loadDataSet('testSet.txt'))
myCentroids, clustAssing= kMeans(dataMat,)
print myCentroids
show(dataMat, , myCentroids, clustAssing) if __name__ == '__main__':
main()
机器学习笔记索引
k-means聚类算法python实现的更多相关文章
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- (数据科学学习手札09)系统聚类算法Python与R的比较
上一篇笔者以自己编写代码的方式实现了重心法下的系统聚类(又称层次聚类)算法,通过与Scipy和R中各自自带的系统聚类方法进行比较,显然这些权威的快捷方法更为高效,那么本篇就系统地介绍一下Python与 ...
- 转载 | Python AI 教学│k-means聚类算法及应用
关注我们的公众号哦!获取更多精彩哦! 1.问题导入 假如有这样一种情况,在一天你想去某个城市旅游,这个城市里你想去的有70个地方,现在你只有每一个地方的地址,这个地址列表很长,有70个位置.事先肯定要 ...
- K-means聚类算法及python代码实现
K-means聚类算法(事先数据并没有类别之分!所有的数据都是一样的) 1.概述 K-means算法是集简单和经典于一身的基于距离的聚类算法 采用距离作为相似性的评价指标,即认为两个对象的距离越近,其 ...
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
随机推荐
- ORB-SLAM(三)地图初始化
单目SLAM地图初始化的目标是构建初始的三维点云.由于不能仅仅从单帧得到深度信息,因此需要从图像序列中选取两帧以上的图像,估计摄像机姿态并重建出初始的三维点云. ORB-SLAM中提到,地图初始化常见 ...
- PyChram中同目录下import引包报错的解决办法?
相信很多同学和我一样在PyChram工具中新建python项目的同目录下import引包会报错提示找不到,这是因为该项目找不到python的环境导致的: 如果文件开始的时候包引包的错误可以,都可以用用 ...
- nginx平滑升级
1.查询原来安装配置信息 [root@t-scrmap1-v-szzb local]# netstat -unlatp | grep nginx tcp 0 0 0.0.0.0:80 0.0.0.0: ...
- 使用 zssh 进行 Zmodem 文件传输
Zmodem 最早是设计用来在串行连接(uart.rs232.rs485)上进行数据传输的,比如,在 minicom 下,我们就可以方便的用 Zmodem (说 sz .rz 可能大家更熟悉)传输文件 ...
- BZOJ1483: [HNOI2009]梦幻布丁
传送门 名字起得很高端实际上很简单的算法hhh 启发式合并 简单讲就是一些合并一堆队列的题可以用启发式合并,或者说这是一个思想.每次把小的合并到大的部分,均摊复杂度$O(MlogN)$. //BZOJ ...
- ionic ios发布图标启动也不能正确加载问题
前两天发布ios的时候发现ios安装的图标和启动页的时候不能正确显示,重新发布也不能正确显示,修改方法 在ionic build ios --release之前执行ionic resources即可
- 如何扩大LVM 逻辑分区的大小?
参考: (http://blog.csdn.net/t0nsha/article/details/7296851) LVM (Logical volume management) 执行 df 指令查看 ...
- JDK Collection 源码分析(1)—— Collection
JDK Collection JDK Collection作为一个最顶层的接口(root interface),JDK并不提供该接口的直接实现,而是通过更加具体的子接口(sub interface ...
- jsp页面中引用其他页面的方法
初看这个标题....大家的感觉一定是好2啊.....博主一定要说jsp的动态引用(jsp:include)和静态引用(@include)了.介绍这两者区别的文章已经烂大街了..一搜一大把..博主竟然还 ...
- maven project中,在main方法上右键Run as Java Application时,提示错误:找不到或无法加载主类XXX.XXXX.XXX
新建了一个maven project项目,经过一大堆的修改操作之后,突然发现在main方法上右键运行时,竟然提示:错误:找不到或无法加载主类xxx.xxx.xxx可能原因1.eclipse出问题了,在 ...