NLP获取词向量的方法(Glove、n-gram、word2vec、fastText、ELMo 对比分析)
1 Glove - 基于统计方法
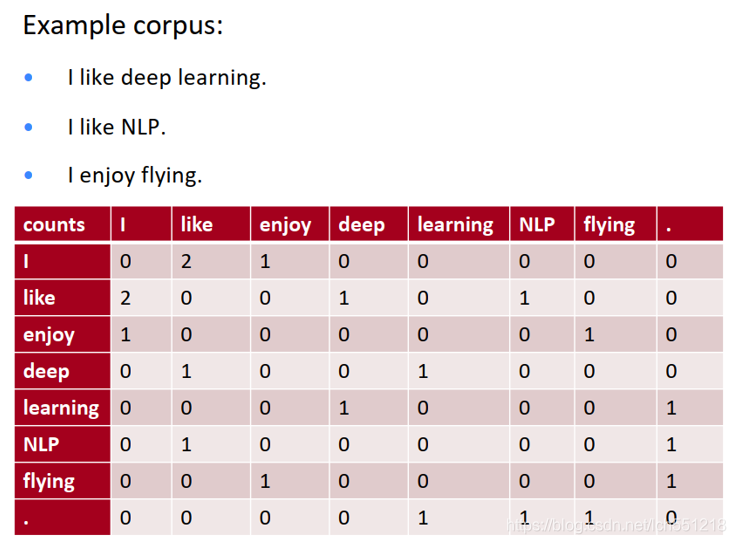
1.1 实现步骤
- 统计所有语料当中任意两个单词出现在同一个窗口中的频率,结果表现为共现矩阵 X
- 直接统计得到的共现矩阵 X,大小为 |V| x |V|(V=词库容量)
- 实践当中通常对原始统计矩阵施加 SVD(Singular Value Decomposition)来降低矩阵维度,同时降低矩阵的稀疏性
1.2 优点
- 训练速度快
- 充分利用了全局的统计信息
1.3 存在的问题
- 对于单一词语,只有少部分词与其同时出现,导致矩阵极其稀疏,因此需要对词频做额外处理来达到好的矩阵分解效果
- 矩阵非常大,维度太高
- 需要手动去掉停用词(如although, a,...),不然这些频繁出现的词也会影响矩阵分解的效果
2 基于语言模型的方法
2.1 基于 n-gram 的语言模型
- 参数空间过大,概率
的参数有 O(n)O(n)O(n) 个。
- 数据稀疏严重,有些词同时出现的情况可能没有,组合阶数高时尤其明显。
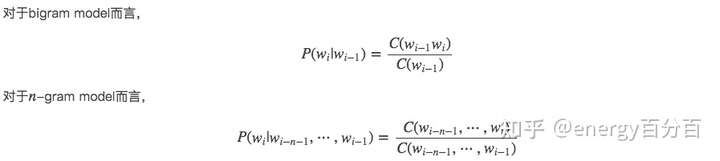
- 简单来说,n阶马尔可夫假设的意思就是:符合马尔科夫过程的随机变量,当前状态只和前n-1个状态有关,即N阶马尔可夫假设认为,当前词出现的概率只依赖于前 n-1 个词
- 1阶马尔科夫假设当前状态只和当前状态有关,1阶马尔科夫假设不会考虑上下和当前次的关系,因此 n 一般大于1
这里插一嘴,笔者认为 虽然 n-gram 只用到了前 n-1 个数据,但是这前 n-1 个数据也是由前边数据得出的,因此 n-gram 也间接用到了前边的数据
2.2 基于神经网络的语言模型
2.2.1 word2vec
2.2.2 fastText
- 输入增加了n-gram特征
- 使用 层次softmax做多分类
- 通过文本分类的方式来训练模型
2.2.3 ELMO
- 用通用语言模型(如word2vec、fastText、glove等)去训练一个静态词向量,ELMO内部使用 CNN-BIG-LSTM 语言模型得到的词向量,得到词向量的维度为 512
- 使用得到的静态词向量去训练ELMO网络
- 下游任务中使用词向量时,加载预训练的ELMO网络参数,根据当前上下文去动态调整词向量,从而得到一个动态的词向量。
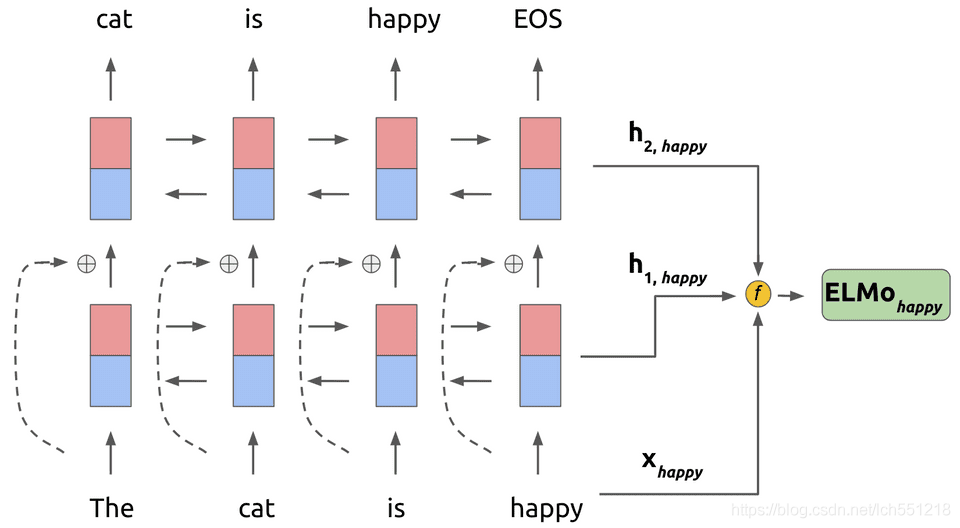
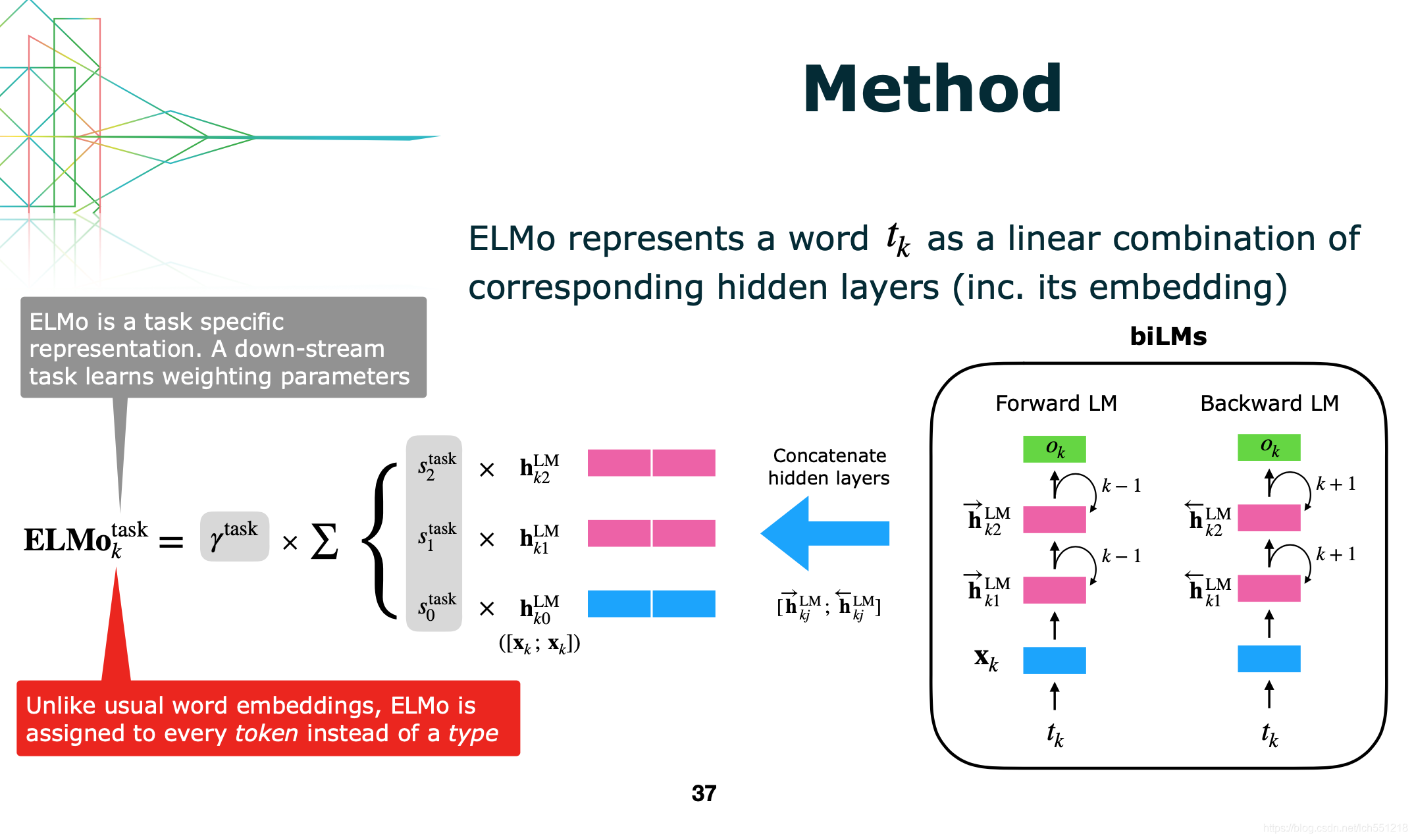
上图展示的就是ELMO的网络结构,ELMO由两层网络组成,每层网络用于提取不同层级的特征;其中每层由两个方向相反的RNN网络构成(双向LSTM,简称BiLSTM),分别记录上文信息和下文信息
- $h(i,0)$:将两个输入的静态词(复制一份)向量拼接在一起,维度是512+512=1024,拼接的目的是为了和后边两个词向量的维度统一。
- $h(i,1)$:将ELMO第1层两个反向LSTM的输出拼接,维度是512+512=1024。
- $h(i,2)$:将ELMO第2层两个反向LSTM的输出拼接,维度是512+512=1024。
- 是直接使用最后一层 biLSTM 的输出作为词向量,即 $h(i,2)$ 。
- 更加通用的做法,将 $h(i,0)$ 、$h(i,1)$ 、$h(i,2)$ 三个输出加权融合在一起,公式如下。其中γ 是一个与任务相关的系数,允许不同的 NLP 任务缩放 ELMO 的向量,可以增加模型的灵活性。 $s_{j}^{task}$是使用 softmax 归一化的权重系数;此方法得到的elmo词向量可以看成是各层向量与初始静态词向量的ensemble
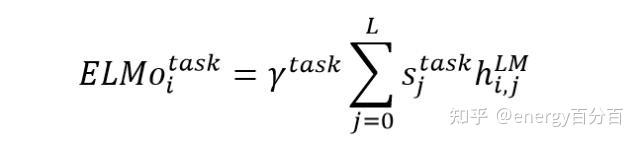
4. ELMO优点
- ELMO的各层参数实际上就是为各种有监督的下游任务准备的,因此ELMO可以被认为是一种迁移学习(transfer learning)。
- 通过这样的迁移策略,那些对词义消歧有需求的任务就更容易通过训练给第二隐层一个很大的权重,而对词性、句法有明显需求的任务则可能对第一隐层的参数学习到比较大的值(实验结论)。总之,这样便得到了一份”可以被下游任务定制“的特征更为丰富的词向量。
5. ELMO缺点
- lstm是串行机制,训练时间长,从这一点来看ELMO注定成为不了大哥,
- 相比于Transformer,lstm提取特征的能力还是不够的,我觉得未来lstm可能会被淘汰,毕竟屁股决定脑袋,时间为上!
- ELMO 的两个RNN网络是分别计算的,导致计算时上下文的信息不会相互通信,进而导致ELMO得到的词向量有一定的局限性
- 输出的结果只是讲两个RNN网络得到的结果拼接在一起,上下文信息并不会相互影响
转载于:https://blog.csdn.net/lch551218/article/details/114836207
NLP获取词向量的方法(Glove、n-gram、word2vec、fastText、ELMo 对比分析)的更多相关文章
- 深度学习之NLP获取词向量
1.代码 def clean_text(text, remove_stopwords=False): """ 数据清洗 """ text = ...
- NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
有很多改进版的word2vec,但是目前还是word2vec最流行,但是Glove也有很多在提及,笔者在自己实验的时候,发现Glove也还是有很多优点以及可以深入研究对比的地方的,所以对其进行了一定的 ...
- NLP︱高级词向量表达(三)——WordRank(简述)
如果说FastText的词向量在表达句子时候很在行的话,GloVe在多义词方面表现出色,那么wordRank在相似词寻找方面表现地不错. 其是通过Robust Ranking来进行词向量定义. 相关p ...
- NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,不过这个项目其实是有两部分组成的,一部分是这篇文章介绍的 fastText 文本分类(paper: ...
- NLP之词向量
1.对词用独热编码进行表示的缺点 向量的维度会随着句子中词的类型的增大而增大,最后可能会造成维度灾难2.任意两个词之间都是孤立的,仅仅将词符号化,不包含任何语义信息,根本无法表示出在语义层面上词与词之 ...
- pytroch 权重初始化和加载词向量的方法
1.几种不同的初始化方法 import torch.nn as nn embedding = torch.Tensor(3, 5) #如下6种初始化方法 #正态分布 nn.init.normal_(e ...
- 【paddle学习】词向量
http://spaces.ac.cn/archives/4122/ 关于词向量讲的很好 上边的形式表明,这是一个以2x6的one hot矩阵的为输入.中间层节点数为3的全连接神经网络层,但你看右 ...
- NLP教程(2) | GloVe及词向量的训练与评估
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www.showmeai.tech/article-det ...
- NLP学习(1)---Glove模型---词向量模型
一.简介: 1.概念:glove是一种无监督的Word representation方法. Count-based模型,如GloVe,本质上是对共现矩阵进行降维.首先,构建一个词汇的共现矩阵,每一行是 ...
随机推荐
- 2021.5.22 vj补题
A - Marks CodeForces - 152A 题意:给出一个学生人数n,每个学生的m个学科成绩(成绩从1到9)没有空格排列给出.在每科中都有成绩最好的人或者并列,求出最好成绩的人数 思路:求 ...
- 利用ps在光污染地图上寻找最近的观星地区
城市灯光对于天文观测和天文摄影是有害的,进行这两类活动之前应提前规划地点,下面是笔者尝试的一种利用ps在光污染地图上进行规划的方法. 目前大部分的光污染地图都是基于WA 2015绘制的,可以结合VII ...
- k8s学习笔记(3)- kubectl高可用部署,扩容,升级,回滚springboot应用
前言:上一篇通过rancher管理k8s,部署服务应用扩容,高可用,本篇介绍kubectl命令行部署高可用集群节点,测试升级.扩容等 1.测试环境:3节点k3s,使用其中2节点(ubuntunode1 ...
- Spring启动过程源码分析基本概念
Spring启动过程源码分析基本概念 本文是通过AnnotationConfigApplicationContext读取配置类来一步一步去了解Spring的启动过程. 在看源码之前,我们要知道某些类的 ...
- 函数返回值为 const 指针、const 引用
函数返回值为 const 指针,可以使得外部在得到这个指针后,不能修改其指向的内容.返回值为 const 引用同理. class CString { private: char* str; publi ...
- 华为在HDC2021发布全新HMS Core 6 宣布跨OS能力开放
[2021年10月22日·东莞]华为开发者大会 2021(Together)于今天正式开幕,华为在主题演讲中正式发布全新的HMS Core 6,向全球开发者开放7大领域的69个Kit和21,738个A ...
- sql递归查询部门数据
1 with cte as 2 ( 3 select a.DepartCode,a.DepartName,a.ParentDepartCode from tbDeparts a where Paren ...
- python redis自带门神 lock 方法
redis 支持的数据结构比较丰富,自制一个锁也很方便,所以极少提到其原生锁的方法.但是在单机版redis的使用时,自带锁的使用还是非常方便的.自己有车还打啥滴滴顺风车是吧,本篇主要介绍redis-p ...
- 上拉电阻大小对i2c总线的影响
漏极开路上拉电阻取值为何不能很大或很小? 如果上拉电阻值过小,Vcc灌入端口的电流(Ic)将较大,这样会导致MOS管V2(三极管)不完全导通(Ib*β<Ic),有饱和状态变成放大状态,这样端口输 ...
- 与 Python 之父聊天:更快的 Python!
Python猫注: 在今年 5 月的 Python 语言峰会上,Guido van Rossum 作了一场<Making CPython Faster>的分享(材料在此),宣告他加入了激动 ...