ElasticSearch、Kibana 介绍&安装
ElasticSearch 介绍
基于数据库查询的问题
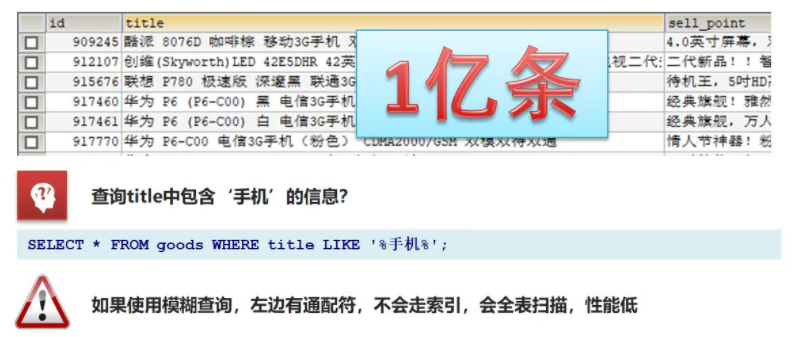
倒排(反向)索引
倒排索引:将一段文本按照一定的规则,拆分为不同的词条(term),形成词条和 id 的对应关系。
以唐诗为例,所处包含“前”的诗句:
- 正向索引:《静夜思》--> 窗前明月光 ---> “前”字
- 反向索引:“前”字 --> 窗前明月光 --> 《静夜思》
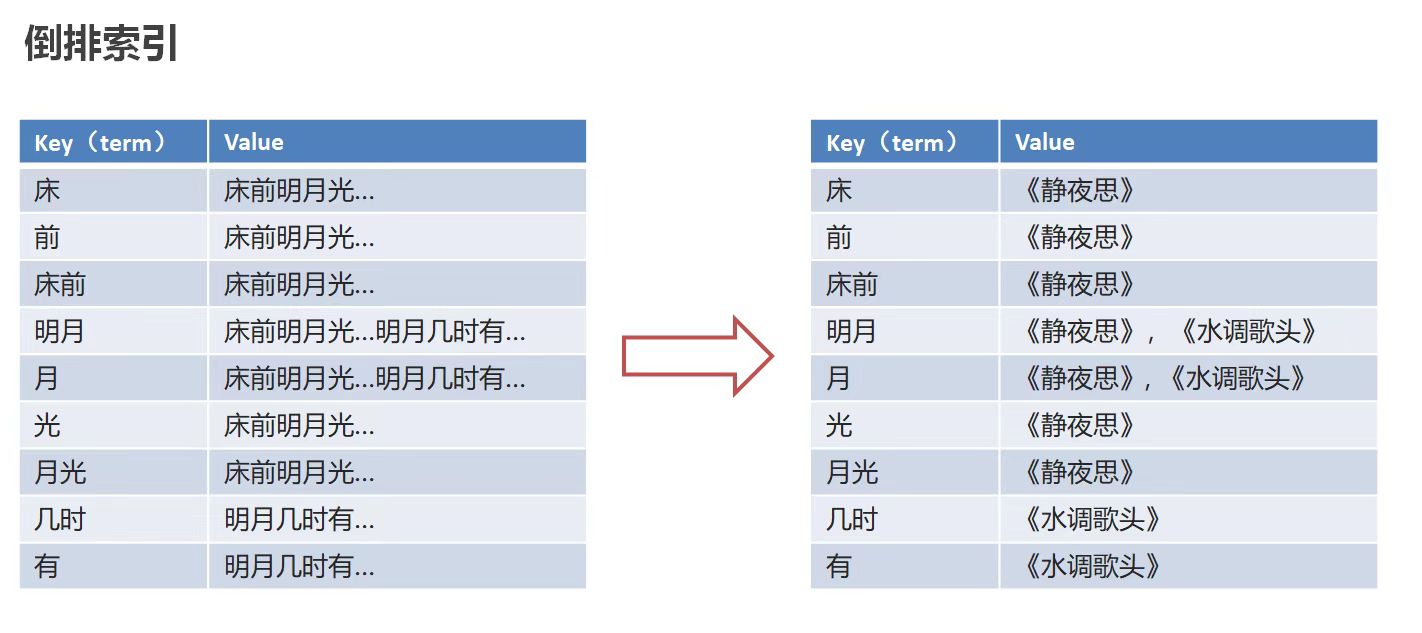
ES 存储和查询的原理
index(索引):相当于 mysql 的库
mapping(映射):相当于 mysql 的表结构
document(文档):相当于 mysql 表中的数据
以下图为例:ES 使用倒排索引,对 title 进行分词
使用“手机”作为关键字查询:
- 生成的倒排索引中,
词条会排序,形成一棵树形结构,以提升词条的查询速度
- 生成的倒排索引中,
使用“华为手机”作为关键字查询:
- 华为:1, 3
- 手机:1, 2, 3
ES 核心概念
什么是 ES ?
ElasticSearch 是一个基于 Lucene 的搜索服务器。
是一个分布式、高扩展、高实时的搜索与数据分析引擎。
基于 RESTful Web 接口。
ElasticSearch 由 Java 语言开发,并作为 Apache 许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
ES 应用场景:
搜索:海量数据的查询
日志数据分析
实时数据分析
核心概念:
**索引(index)**:ElasticSearch 存储数据的地方,可以理解成关系型数据库中的数据库概念。**映射(mapping)**:Mapping 定义了每个字段的类型、字段所使用的分词器等。相当于关系型数据库中的表结构。**文档(document)**:ElasticSearch 中的最小数据单元,常以 json 格式显示。一个 document 相当于关系型数据库中的一行数据。倒排索引:一个倒排索引由文档中所有不重复词的列表构成。对于其中每个词,对应一个包含它的文档 id 的列表。
类型(type):一种 type 就像一类表。如用户表、角色表等。
- ES 5.x 中一个 index 可以有多种 type。
- ES 6.x 中一个 index 只能有一种 type。
- ES 7.x 以后,将逐步移除 type 这个概念,现在的操作已经不再使用,默认 type 为 _doc 。
ES 安装
1)官网下载地址:https://www.elastic.co/cn/downloads/
2)解压
# 将 elasticsearch-7.4.0-linux-x86_64.tar.gz 解压到如 /opt 目录下
tar -zxvf elasticsearch-7.4.0-linux-x86_64.tar.gz -C /opt
3)创建普通用户
- 因为安全问题,Elasticsearch 不允许 root 用户直接运行,所以要创建新用户,在 root 用户中创建新用户:
useradd es # 新增 es 普通用户
passwd es # 为 es 用户设置密码
# 为新用户授权
chown -R es:es /opt/elasticsearch-7.4.0
chmod 777 -R /opt/elasticsearch-7.4.0
4)修改 elasticsearch.yml 启动配置
# vi /opt/elasticsearch-7.4.0/config/elasticsearch.yml
# 配置 ES 的集群名称,默认是 elasticsearch
cluster.name: my-application
# 配置节点名称(elasticsearch 会默认随机指定一个名字)
node.name: node-1
# 配置为 0.0.0.0 表示允许外网访问
network.host: 0.0.0.0
# 配置 ES 的访问端口
http.port: 9200
# 初始化新的集群时,需要此配置来选举 master
cluster.initial_master_nodes: ["node-1"]
5)修改参数配置
- 新创建用户(ES)的默认最大可创建文件数和最大虚拟内存均太小,因此可以进行如下配置:
# ===最大可创建文件数=======
# vi /etc/security/limits.conf
# 在文件末尾中增加下面内容
es soft nproc 5000
es hard nproc 5000
# 重启服务器后生效
# ===最大虚拟内存=======
# vi /etc/sysctl.conf
# 在文件中增加下面内容
vm.max_map_count=655360
# 重新加载虚拟内存
# sysctl -p
6)启动 elasticsearch
- 注意:启动时确认 jdk 使用的是 ES 安装目录中自带的,否则容易报 jdk 不兼容的问题。

su es
cd /opt/elasticsearch-7.4.0/bin
./elasticsearch
- 如下图可以看到 ES 启动成功:

7)访问 ES
- 在访问 ES 前,请确保防火墙是关闭的:
# 暂时关闭防火墙
systemctl stop firewalld
# 永久设置防火墙状态
systemctl enable firewalld.service # 打开
systemctl disable firewalld.service # 关闭
- 浏览器访问 http://虚拟机IP:9200/ :
Kibana
1)什么是 Kibana ?
Kibana 是一个针对 ElasticSearch 的开源分析及可视化平台,用来搜索、查看交互存储在 ElasticSearch 索引中的数据。使用 Kibana,可以通过各种图表进行高级数据分析及展示。
Kibana 让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(DashBoard)实时显示 ElasticSearch 查询动态。
2)解压 Kibana
tar -xzf kibana-7.4.0-linux-x86_64.tar.gz -C /opt
3)修改 Kibana 配置
# vi /opt/kibana-7.4.0-linux-x86_64/config/kibana.yml
# 访问端口
server.port: 5601
# 表示可通过外网访问
server.host: "0.0.0.0"
# kibana服务名
server.name: "kibana-itcast"
# ES 地址
elasticsearch.hosts: ["http://127.0.0.1:9200"]
# ES 请求超时时间(默认30000ms)
elasticsearch.requestTimeout: 99999
4)启动 Kibana
- Kibana 不建议使用 root 用户启动,若要用 root 启动,需要加 --allow-root 参数
# 切换到kibana的bin目录
cd /opt/kibana-7.4.0-linux-x86_64/bin
# 启动
./kibana --allow-root
- 如下表示启动成功:

5)访问 kibana
浏览器访问 http://虚拟机IP:5601/ :
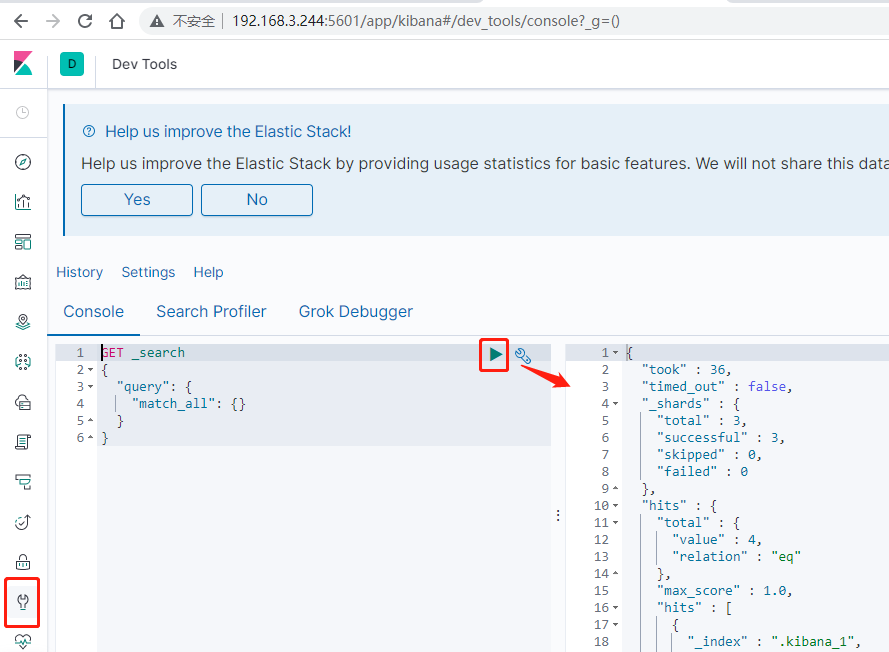
左侧菜单栏说明:
- Discover:可视化查询分析器
- Visualize:统计分析图表
- Dashboard:自定义主面板(添加图表)
- Timelion:Timelion 是一个 kibana 时间序列展示组件(暂时不用)
- Dev Tools:Console 控制台(同 CURL/POSTER,操作 ES 代码工具。有代码提示,因此很方便)
- Management:管理索引库(index)、已保存的搜索和可视化结果(save objects)、设置 kibana 服务器属性等
ElasticSearch、Kibana 介绍&安装的更多相关文章
- elasticsearch+kibana+metricbeat安装部署方法
elasticsearch+kibana+metricbeat安装部署方法 本文是elasticsearch + kibana + metricbeat,没有涉及到logstash部分.通过beat收 ...
- elasticsearch kibana的安装部署与简单使用(一)
1.先说说es 我早两年使用过es5.x的版本,记得当时部署还是很麻烦,因为es是java写的,要先在机器上部署java环境jvm之类的一堆东西,然后才能安装es 但是现在我使用的是目前最新的7.6版 ...
- Elasticsearch+Kibana+Logstash安装
安装环境: [root@node- src]# cat /etc/redhat-release CentOS Linux release (Core) 安装之前关闭防火墙 firewalld 和 se ...
- Elasticsearch + Kibana 简单安装使用
1.资料来源官网,参考: https://www.elastic.co/cn/downloads/elasticsearch https://www.elastic.co/cn/downloads/k ...
- elasticsearch kibana的安装部署与简单使用(二)
介绍一下elasticsearch和kibana的简单使用 es其实我理解为一个数据库,一个数据库无非就是增删改查, Delete PUT GET POST 这些接口关键字完美对应 比如,我想查一张 ...
- 分布式搜索引擎ElasticSearch+Kibana (Marvel插件安装详解)
在安装插件的过程中,尤其是安装Marvel插件遇到了很多问题,要下载license.Marvel-agent,又要下载安装Kibana 版本需求 Java 7 or later Elasticsear ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 【ELK】【docker】【elasticsearch】1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安装ik分词器
系列文章:[建议从第二章开始] [ELK][docker][elasticsearch]1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安 ...
- 三十八 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
随机推荐
- list通过比较器进行排序
Collections.sort(dataList,new Comparator<BaseTransitData>(){ public int compare(Bas ...
- Spring Boot 自动扫描组件
使用@ComponentScan自动扫描组件 案例准备 1.创建一个配置类,在配置类上添加 @ComponentScan 注解.该注解默认会扫描该类所在的包下所有的配置类,相当于之前的 <con ...
- 解决PLSQL查不到带中文条件的记录
原因: PLSQL乱码问题皆是ORACLE服务端字符集编码与PLSQL端字符集编码不一致引起.类似乱码问题都可以从编码是否一致上面去考虑. 解决: 1. 查询Oracle服务端字符集编码,获取NLS_ ...
- 二进制转换为ip地址
#include <stdio.h> #include<math.h> int power(int b)//定义幂函数 { int i = 2, j = 1; if (b == ...
- 莫烦python教程学习笔记——使用波士顿数据集、生成用于回归的数据集
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- Nginx配置FTP
目录 一.简介 二.配置 一.简介 ftp有单独的服务,但配置并不轻松.相对于比较熟悉的nginx,做ftp要容易很多. 二.配置 添加一个server字段 server { listen 8888; ...
- [BUUCTF]PWN——ciscn_2019_es_7[详解]
ciscn_2019_es_7 附件 步骤: 例行检查,64位程序,开启了nx保护 本地试运行一下看看大概的情况 64位ida载入,关键函数很简单,两个系统调用,buf存在溢出 看到系统调用和溢出,想 ...
- libevent源码学习(17):缓冲管理框架
目录Libevent缓冲区类型Libevent缓冲区结构缓冲区的读出与写入缓冲区的读入与写出缓冲区水位机制缓冲区回调机制延迟回调机制Libevent缓冲区类型 Libevent中提供了多种 ...
- Spring学习(二)三种方式的依赖注入
1.前言 上一篇讲到第一个Spring项目的创建.以及bean的注入.当然.注入的方式一共有三种.本文将展开细说. 1.set注入:本质是通过set方法赋值 1.创建老师类和课程类 1.Course ...
- Flutter学习(9)——Flutter插件实现(Flutter调用Android原生
原文地址: Flutter学习(9)--Flutter插件实现(Flutter调用Android原生) | Stars-One的杂货小窝 最近需要给一个Flutter项目加个apk完整性检测,需要去拿 ...