ActiveMQ基础教程(二):安装与配置(单机与集群)
因为本文会用到集群介绍,因此准备了三台虚拟机(当然读者也可以使用一个虚拟机,然后使用不同的端口来模拟实现伪集群):
192.168.209.133 test1
192.168.209.134 test2
192.168.209.135 test3
因为ActiveMQ是java编写,因此需要java的运行环境,这个不做介绍,网上有一堆的教程。
其次,下载ActiveMQ包,官网下载地址:https://archive.apache.org/dist/activemq/ ,读者可以选择一个版本下载使用,比如,当前最新版是5.16.1,下载地址:https://archive.apache.org/dist/activemq/5.16.1/

官网下载速度比较慢,可能需要一两个小时,有百度网盘会员的可以移步百度网盘:https://pan.baidu.com/s/1-ToyzCqo_ypk7FXcjgI3yg (提取码: jcd7 )
单机安装与配置
首先将tar包传到linux上去(我这里使用的是Ubuntu16.04),然后在tar包所在目录进行解压:
# -C 表示解压出来的文件保存目录,默认是tar包所在目录,这里我选择的是/opt目录,注意修改权限,如果你是root用户,则不需要修改
sudo tar -zxf apache-activemq-5.16.1-bin.tar.gz -C /opt
其实我们下载好的tar包是编译打包好的,只需解压就可以启动了:
# 使用后台线程启动
sudo ./bin/activemq start
# 使用控制台方式启动,这种方式会造成当前shell阻塞,如果想使用服务单元或者supervisor这样的工具做守护进程,那么应该采用这种启动方式
sudo ./bin/activemq console
# 停止应用
sudo ./bin/activemq stop
# 重启应用
sudo ./bin/activemq restart
第一次建议采用控制台console的形式启动,看时候会报错,报错则会打印异常信息,方便我们排查,启动后大概是这样的:
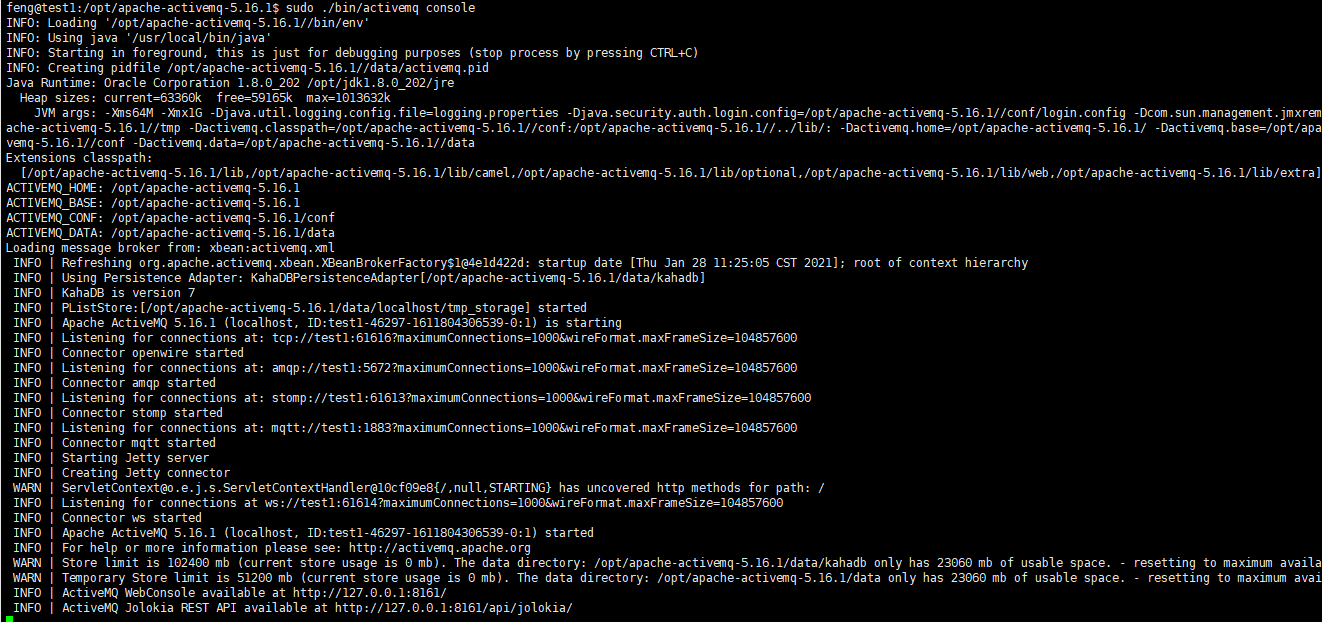
注意输出的信息,可以看到:
1、ActiveMQ版本是5.16.1,使用KahaDB做持久化,版本7
2、openwire方式连接启动,监听:tcp://test1:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600,还有ampq、stomp、mqtt、ws等分别在不同端口启动监听(注,这里的test1是在hosts中添加的,看我上面提供的三个虚拟机)
3、Jetty服务启动,其实就是启动ActiveMQ的管理后台
4、ActiveMQ管理后台地址:http://127.0.0.1:8161/,ActiveMQ的Jolokia API地址:http://127.0.0.1:8161/api/jolokia/,Jolokia API主要是通过API接口获取ActiveMQ的状态信息,方便第三方程序进行监控
主要到,上面服务启动后,管理后台启动在127.0.0.1:8161,这表明我们只能在本地访问,虚拟机以外的主机是访问不了的,所以我需要修改相关配置。
配置文件在 conf 目录下,我们常用到的配置文件就是activemq.xml以及jetty.xml,里面全是一些 java bean(有点少见的东西)。activemq.xml主要是ActiveMQ相关配置,而jetty.xml主要是管理后台的一些配置,接下来介绍一些常用的几个配置:
1、修改Connector
打开conf/activemq.xml,找到 transportConnectors 节点配置,注释掉多余的连接协议,只留自己需要的就行了,比如我一般用openwire,那我就将其它的注释掉。
说明一下,为什么要这么做,主要是没必要,也可以避免端口冲突,比如,rabbitmq默认采用ampq监听5672端口,这时你会发现activemq启动不了,因为端口冲突。
<transportConnectors>
<!-- DOS protection, limit concurrent connections to 1000 and frame size to 100MB -->
<transportConnector name="openwire" uri="tcp://0.0.0.0:61616?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<!--<transportConnector name="amqp" uri="amqp://0.0.0.0:5672?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="stomp" uri="stomp://0.0.0.0:61613?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="mqtt" uri="mqtt://0.0.0.0:1883?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>
<transportConnector name="ws" uri="ws://0.0.0.0:61614?maximumConnections=1000&wireFormat.maxFrameSize=104857600"/>-->
</transportConnectors>
需要注意的是,连接端口也是在上面的uri中去配置。
2、查看持久化方式配置
在conf/activemq.xml找到 persistenceAdapter 节点,这时消息持久化模式配置,可以看到默认的方式是kahaDB,数据目录是data/kahadb
<persistenceAdapter>
<kahaDB directory="${activemq.data}/kahadb"/>
</persistenceAdapter>
这个节点只是说明一下,因为后续介绍ActiveMQ集群模式就是修改这个节点kahaDB为replicatedLevelDB进行配置,所以这个暂时可以不用动,当然如果你愿意,可以修改成AMQ、JDBC等其他方式。
3、死信队列配置
ActiveMQ提供了众多的策略,这里以死信队列策略配置为例来介绍。
在conf/activemq.xml找到 destinationPolicy 节点,这里配置的是一些队列和topic的策略,当然包括死信队列了,默认策略配置如下:
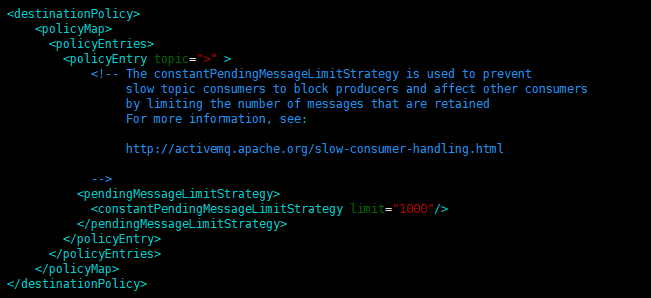
说明:
policyEntry 节点是配置入口
topic=">" 表示对所有的topic生效,我们也可以增加一个policyEntry节点,用途queue属性来表示对队列生效,如下文介绍
pendingMessageLimitStrategy 消息限制策略,只对Topic且非持久化订阅者有效,用于当通道中有大量的消息积压时,broker可以保留的消息量,这是为了防止Topic中有慢速消费者,导致整个通道消息积压
constantPendingMessageLimitStrategy保留固定条数的消息,如果消息量超过了限制,将使用消息剔除策略移除消息
ActiveMQ死信队列配置策略主要有两种:共享的死信策略(SharedDeadLetterStrategy)、单独的死信策略(IndividualDeadLetterStrategy)
共享的死信策略(SharedDeadLetterStrategy)
共享的死信策略(SharedDeadLetterStrategy)表示将所有的死信消息保存在一个共享队列中,这是ActiveMQ的默认策略
常用配置属性:
deadLetterQueue:共享队列名称,默认的队列名为 ActiveMQ.DLQ
processExpired:表示是否将过期消息放入死信队列,默认为true
processNonPersistent:表示是否将“非持久化”消息放入死信队列,默认为false
需要注意的是,之前共享的死信策略配置可以是这样子:
<deadLetterStrategy>
<sharedDeadLetterStrategy deadLetterQueue="DLQ.Queue"/>
</deadLetterStrategy>
但是不知道从什么时候起,这样配置会抛出异常:
Caused by: java.lang.IllegalStateException: Cannot convert value of type 'java.lang.String' to required type 'org.apache.activemq.command.ActiveMQDestination' for property 'deadLetterQueue': no matching editors or conversion strategy found
at org.springframework.beans.TypeConverterDelegate.convertIfNecessary(TypeConverterDelegate.java:307)
at org.springframework.beans.AbstractNestablePropertyAccessor.convertIfNecessary(AbstractNestablePropertyAccessor.java:588)
... 52 more
但是我们可以使用bean去配置,如:
<bean id="deadLetterQueue" class="org.apache.activemq.command.ActiveMQQueue">
<constructor-arg name="name" value="DLQ.Queue"/>
</bean>
......
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="localhost" dataDirectory="${activemq.data}">
<destinationPolicy>
<policyMap>
<policyEntries>
<policyEntry queue=">" >
<deadLetterStrategy>
<bean xmlns="http://www.springframework.org/schema/beans" class="org.apache.activemq.broker.region.policy.SharedDeadLetterStrategy">
<property name="deadLetterQueue" ref="deadLetterQueue" />
</bean>
</deadLetterStrategy>
</policyEntry>
</policyEntries>
</policyMap>
</destinationPolicy>
....
</broker>
上面的配置中,定义了一个id为deadLetterQueue的bean,然后在策略中,queue=">" 表示对所有队列生效,如果想对topic生效,改成 topic=“>” 即可,而策略时一个bean,class指向SharedDeadLetterStrategy,它的属性deadLetterQueue指向我们前面定义的那个bean的id
其实,上面的配置就是说,对于所有的队列的死信消息,通通发到一个名为DQL.Queue的队列中去。
单独的死信策略(IndividualDeadLetterStrategy)
单独的死信策略(IndividualDeadLetterStrategy)表示把死信消息放入各自的死信通道中,区分的条件时使用不同的前缀,死信通道可以是队列,也可以是topic
常用配置属性:
queuePrefix:当死信队列是queue时使用的前缀,默认是 ActiveMQ.DLQ.Queue.
topicPrefix:当死信队列是topic是使用的前缀,默认是 ActiveMQ.DLQ.Topic.
useQueueForTopicMessages:表示是否将Topic的死信消息保存在Queue中,默认为true,表示Topic的死信消息保存至Queue中
processExpired:表示是否将过期消息放入死信队列,默认为true
processNonPersistent:表示是否将“非持久化”消息放入死信队列,默认为false
例如:
<destinationPolicy>
<policyMap>
<policyEntries>
<policyEntry queue=">" >
<deadLetterStrategy>
<individualDeadLetterStrategy queuePrefix="queue.DLQ." useQueueForQueueMessages="false"/>
</deadLetterStrategy>
</policyEntry>
<policyEntry topic=">" >
<pendingMessageLimitStrategy>
<constantPendingMessageLimitStrategy limit="1000"/>
</pendingMessageLimitStrategy>
<deadLetterStrategy>
<individualDeadLetterStrategy topicPrefix="topic.DLQ." useQueueForQueueMessages="true"/>
</deadLetterStrategy>
</policyEntry>
</policyEntries>
</policyMap>
</destinationPolicy>
上面的例子中,queue=">" 表示对所有队列启用策略,即对每个的队列的死信消息,保存到一个以queue.DLQ.[队列名]的topic中,比如一个名为demo的队列对应的死信通道是一个名称是queue.DLQ.demo的topic。
同理,topic=">"表示对所有topic生效,表示将每个topic的死信消息保存在一个已topic.DLQ.[topic名]的队列中,比如一个名称为demo的topic对应的死信通道是一个名称为topic.DLQ.demo的队列
4、管理后台启动配置
前面说到默认情况下启动时,ActiveMQ管理后台绑定到127.0.01:8161,这表示我们只能在本地访问,这肯定是不能接受的,我们需要修改这个地址。
打开conf/jetty.xml,找到id="jettyPort"的bean,

修改这里的host成0.0.0.0,端口随意,也可以使用默认的8161:
<bean id="jettyPort" class="org.apache.activemq.web.WebConsolePort" init-method="start">
<!-- the default port number for the web console -->
<property name="host" value="0.0.0.0"/>
<property name="port" value="8161"/>
</bean>
保存后启动ActiveMQ,然后就可以在浏览器上访问管理后台了,比如我部署的服务器IP是192.168.209.133,那么就访问http://192.168.209.133:8161,接着会要求输入账号和密码,默认都是admin(至于怎么添加用户及管理权限,这就不在本文范围内了,有空再单独用博文介绍),登录后进入欢迎也,然后在点击Manage ActiveMQ broker进入管理后台:
展示的管理界面如下,至于相关页面的操作信息等等,就不做介绍了:

集群部署及配置
说起ActiveMQ的集群,其实它是一种主从架构,是一种和redis集群中的主从模式很像,就是集群只有主节点提供服务,子节点只是备用,当主节点挂了,就会选用一个子节点作为主节点继续提供服务,如:
1、正常情况下是主节点提供服务,子节点作为备用只从主节点同步数据
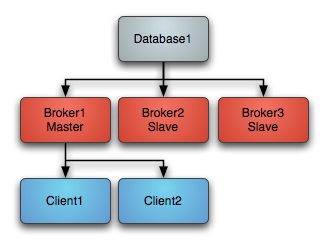
2、当主节点挂了,就会重新选择一个子节点作为主节点重新提供服务
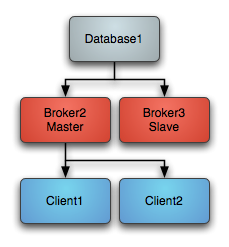
3、如果之后主节点又起来了,此时它将变作为子节点留作备用
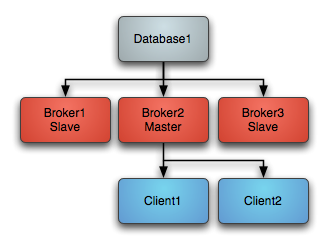
根据ActiveMQ官网的介绍,ActiveMQ集群有三种部署方式:基于共享文件系统的主从架构(文件系统如:SAN)、基于数据库的主从架构,基于Zookeeper的主从架构(http://activemq.apache.org/masterslave.html)
这里介绍基于Zookeeper的主从架构。
准备部署
1、因为是基于Zookeeper的主从架构,因此我们需要一个Zookeeper集群服务,可以参考博文:Zookeeper基础教程(二):Zookeeper安装
我这里采用集群地址就是 192.168.209.133:2181,192.168.209.134:2181,192.168.209.135:2181 (其实就是在当前准备部署ActiveMQ的三台虚拟机上部署的Zookeeper集群)
2、安装上面介绍的单机部署的方式,先在三个节点都安装部署完成ActiveMQ
3、接着就到最重要的环节了。
打开conf/activemq.xml,修改 persistenceAdapter 节点中的持久化方式为 replicatedLevelDB ,如:
test1节点
<persistenceAdapter>
<!--<kahaDB directory="${activemq.data}/kahadb"/>-->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:61619"
zkAddress="192.168.209.133:2181,192.168.209.134:2181,192.168.209.135:2181"
zkPath="/activemq"
hostname="test1"
/>
</persistenceAdapter>
test2节点
<persistenceAdapter>
<!--<kahaDB directory="${activemq.data}/kahadb"/>-->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:61619"
zkAddress="192.168.209.133:2181,192.168.209.134:2181,192.168.209.135:2181"
zkPath="/activemq"
hostname="test2"
/>
</persistenceAdapter>
test3节点
<persistenceAdapter>
<!--<kahaDB directory="${activemq.data}/kahadb"/>-->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:61619"
zkAddress="192.168.209.133:2181,192.168.209.134:2181,192.168.209.135:2181"
zkPath="/activemq"
hostname="test3"
/>
</persistenceAdapter>
说明一下:
directory:表示的是当前节点数据文件保存的目录,不存在就会自动创建,默认值是LevelDB,注意,这个目录是根据ActiveMQ的根目录来设置,比如上面的配置,是将数据文件保存在ActiveMQ的根目录下的 data/leveldb 目录下
replicas:集群节点数,因为采用Zookeeper,要求这个值至少为3
bind:集群通信地址端口配置,就是说如果当前节点变成了master节点,然后slave节点会根据这个地址端口进行数据同步。
zkAddress:Zookeeper集群地址,默认值是 127.0.0.1:2181
zkPath:根ZNode节点配置,你总不希望Zookeeper只为一个ActiveMQ集群服务吧?默认值是 /default
zkPassword:如果Zookeeper有认证,那这个就是认证信息,比如我这里没有,就可以不用配置
hostname:集群内节点通信时采用的hostname,可以认为就是节点的名字,每个节点应该设置成不一样的hostname,建议采用IP作为hostname的值,如果不设置,ActiveMQ将会自动创建一个hostname
注意,集群要求每个节点对Zookeeper的配置都一样,比如我这里,要求每个节点的 replicas、zkAddress、zkPath 配置值是一样的。replicatedLevelDB节点更多的配置可以参考官网介绍:https://activemq.apache.org/replicated-leveldb-store
在启动Zookeeper之后,在每个节点ActiveMQ的根目录下使用下面的命令启动ActiveMQ:
# 这里采用console启动,因为它会输出日志,如果报错方便我们处理,不报错的话,可以在使用start后台启动: sudo ./bin/activemq start
sudo ./bin/activemq console
启动之后,查看Zookeeper,在上面配置的zkPath节点下会有每个broker节点的配置:

管理后台
集群启动之后,我们可以查看管理后台,但是需要注意的是,ActiveMQ集群是master-slave模式,只有master节点对外提供服务,slave节点只是备份,因此,如果要访问master节点的管理后台。
比如上图,我这边test3被选为master,因此我访问的是:http://192.168.209.135:8161

那么你问,如果master节点挂了呢?那就对不起了,原master节点的管理后台地址就访问不了了,你必须访问新的master节点的管理后台才行,如果嫌麻烦,可以自行使用nginx做处理。
另外,如果集群部署启动报错:java.io.IOException: com/google/common/util/concurrent/internal/InternalFutureFailureAccess
结语
ActiveMQ安装好了,我们也可以使用程序访问试试,提示一下,单机部署的ActiveMQ和集群部署的ActiveMQ在代码中的访问地址形式可能不一样,比如我用的C#使用 Apache.NMS.ActiveMQ 第三方包访问ActiveMQ:
单机部署时访问地址是:
string brokerUri = "activemq:tcp://192.168.209.133:61616";
NMSConnectionFactory factory = new NMSConnectionFactory(brokerUri);
集群部署时访问地址是:
string brokerUri = "activemq:failover:(tcp://192.168.209.133:61616,tcp://192.168.209.134:61616,tcp://192.168.209.135:61616)";
NMSConnectionFactory factory = new NMSConnectionFactory(brokerUri);
注意:集群部署时访问地址中的端口是conf/activemq.xml中transportConnectors节点下配置的端口,不是replicatedLevelDB节点bind属性配置的节点,bind属性配置的节点是如果当前节点是master时,它与其它slave的通信端口。
另外,知道怎么部署了,我们还可以试下ActiveMQ众多的策略配置及用法,还可以尝试基于共享文件系统的主从架构(文件系统如:SAN)、基于数据库的主从架构搭建集群,想更深入点的话可以看看集群的负载均衡配置原理。
ActiveMQ的安装部署就介绍到这里吧,主要是还有安装启动过程中还有几个报错,等之后再写吧。
ActiveMQ基础教程(二):安装与配置(单机与集群)的更多相关文章
- zookeeper安装和配置(单机+伪集群+集群)
#单机模式 解压到合适目录. 进入zookeeper目录下的conf子目录, 复制zoo_sample.cfg-->zoo.cfg(如果没有data和logs就新建):tickTime=2000 ...
- ZooKeeper 的安装和配置---单机和集群
如题本文介绍的是ZooKeeper 的安装和配置过程,此过程非常简单,关键是如何应用(将放在下节及相关节中介绍). 单机安装.配置: 安装非常简单,只要获取到 Zookeeper 的压缩包并解压到某个 ...
- 如何安装一个高可用K3s集群?
作者介绍 Janakiram MSV是Janakiram & Associates的首席分析师,也是国际信息技术学院的兼职教师.他也是Google Qualified Developer.亚马 ...
- Zookeeper集群搭建(多节点,单机伪集群,Docker集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- Kafka 教程(二)-安装与基础操作
单机安装 1. 安装 java 2. 安装 zookeeper [这一步可以没有,因为 kafka 自带了 zookeeper] 3. 安装 kafka 下载链接 kafka kafka 是 scal ...
- ActiveMQ基础教程(三):C#连接使用ActiveMQ消息队列
接上一篇:ActiveMQ基础教程(二):安装与配置(单机与集群) 安装部署好集群环境:192.168.209.133:61616,192.168.209.134:61616,192.168.209. ...
- ActiveMQ基础教程----简单介绍与基础使用
概述 ActiveMQ是由Apache出品的,一款最流行的,能力强劲的开源消息总线.ActiveMQ是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,它非常快速,支持多 ...
- ActiveMQ基础教程(一):认识ActiveMQ
ActiveMQ是Apache软件基金会所研发开源的消息中间件,为应用程序提供高效的.可扩展的.稳定的和安全的企业级消息通信. 现在的消息队列有不少,RabbitMQ.Kafka.RocketMQ,Z ...
- Xamarin.Forms教程下载安装JDK配置环境变量
Xamarin.Forms教程下载安装JDK配置环境变量 Xamarin.Form环境配置下载安装JDK JDK是编程Java程序必须的软件.也许有人会问我们用的C#为什么还有Java呢?这是因为我们 ...
- 原创 | 手摸手带您学会 Elasticsearch 单机、集群、插件安装(图文教程)
欢迎关注笔者的公众号: 小哈学Java, 每日推送 Java 领域干货文章,关注即免费无套路附送 100G 海量学习.面试资源哟!! 个人网站: https://www.exception.site/ ...
随机推荐
- 【Linux】【Services】【VersionControl】Git基础概念及使用
1. 简介 1.1. 版本控制工具: 本地版本控制系统: 集中化版本控制系统:CVS,SVN 分布式版本控制系统: BitKeeper,Git 1.2. 官方网站: https://git-scm.c ...
- spring boot druid数据源
pom.xml配置 <!-- druid --> <dependency> <groupId>com.alibaba</groupId> <art ...
- 【编程思想】【设计模式】【结构模式Structural】代理模式Proxy
Python版 https://github.com/faif/python-patterns/blob/master/structural/proxy.py #!/usr/bin/env pytho ...
- 【JavaWeb】【Eclipse】使用Eclipse创建我的第一个网页
使用Eclipse创建我的第一个网页 哔哩哔哩 萌狼蓝天 你可以直接点击Finish,也可以点击Next,到下面这个界面后,勾选生成web.xml然后Finish(你不这样做就会没有Web.xml文件 ...
- 联盛德 HLK-W806 (七): 兼容开发板 LuatOS Air103
目录 联盛德 HLK-W806 (一): Ubuntu20.04下的开发环境配置, 编译和烧录说明 联盛德 HLK-W806 (二): Win10下的开发环境配置, 编译和烧录说明 联盛德 HLK-W ...
- C语言实现鼠标绘图
使用C语言+EGE图形库(Easy Graphics Engine).思路是通过不断绘制直线来实现鼠标绘图的功能,前一个时刻鼠标的坐标作为直线的起点,现在时刻的坐标作为终点(严格意义是线段而不是直线) ...
- <转>网络爬虫原理
网络爬虫是捜索引擎抓取系统的重要组成部分.爬虫的主要目的是将互联网上的网页下载到本地形成一个或联网内容的镜像备份.这篇博客主要对爬虫以及抓取系统进行一个简单的概述. 一.网络爬虫的基本结构及工作流程 ...
- CF116B Little Pigs and Wolves 题解
Content 有一张 \(n\times m\) 的地图,其中,\(\texttt{P}\) 代表小猪,\(\texttt{W}\) 代表狼.如果狼的上下左右有一头以上的小猪,那么它会吃掉其中相邻的 ...
- Dockerfile使用OracleJDK创建自定义tomcat8镜像
我们默认下载的tomcat镜像是用的openjdk ,但是我们有些项目必须使用oraclejdk 那就不能使用官方的tomcat镜像,只能重新自定义一个镜像 Dockerfile文件 FROM cen ...
- java类型转换拓展
数据类型拓展 在Java中二进制用0b开头,八进制用0开头,十六进制用0x表示 整数拓展 int i=10; int i2=010;//八进制 int i3=0x10;//十六进制0x,0-9,A- ...