kafka基础知识梳理
一.Kafka的基本概念
关键字: 分布式发布订阅消息系统;分布式的,分区的消息服务
Kafka是一种高吞吐量的分布式发布订阅消息系统,使用Scala编写。
对于熟悉JMS(Java Message Service)规范的同学来说,消息系统已经不是什么新概念了(例如ActiveMQ,RabbitMQ等)。
Kafka拥有作为一个消息系统应该具备的功能,但是确有着独特的设计。可以这样来说,Kafka借鉴了JMS规范的思想,但是确并没有完全遵循JMS规范。
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。它提供一个消息系统应该具备的功能,但是确有着独特的设计。
二.基础的消息(Message)相关术语
1.Topic
Kafka按照Topic分类来维护消息
2.Producer
我们将发布(publish)消息到Topic的进程称之为生产者(producer)
3.Consumer
我们将订阅(subscribe)Topic并且处理Topic中消息的进程称之为消费者(consumer)
4.Broker
Kafka以集群的方式运行,集群中的每一台服务器称之为一个代理(broker)。
因此,从一个较高的层面上来看,producers通过网络发送消息到Kafka集群,然后consumers来进行消费,如下图
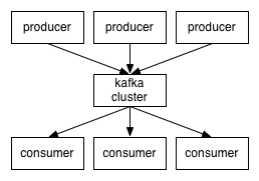
服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。我们为Kafka提供了一个Java客户端,但是也可以使用其他语言编写的客户端。
5.Topic和Log
我们首先深入理解Kafka提出一个高层次的抽象概念-Topic。
可以理解Topic是一个类别的名称,所有的message发送到Topic下面。对于每一个Topic,kafka集群按照如下方式维护一个分区(Partition,可以就理解为一个队列Queue)日志文件:
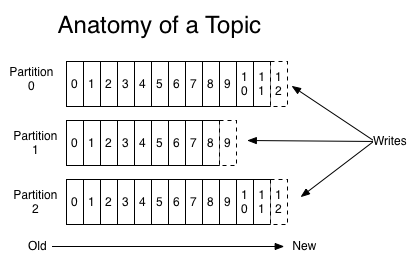
6.partition
partition是一个有序的message序列,这些message按顺序添加到一个叫做commit log的文件中。每个partition中的消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的message。
提示:每个partition,都对应一个commit-log。一个partition中的message的offset都是唯一的,但是不同的partition中的message的offset可能是相同的。
6.1 对log进行分区的目的
对log进行分区(partitioned),有以下目的。首先,当log文件大小超过系统文件系统的限制时,可以自动拆分。每个partition对应的log都受到所在机器的文件系统大小的限制,但是一个Topic中是可以有很多分区的,因此可以处理任意数量的数据。另一个方面,是为了提高并行度。
7.offset
7.1 consumer有自己的offset
每个consumer是基于自己在commit log中的消费进度(offset)来进行工作的。在kafka中,offset由consumer来维护:一般情况下我们按照顺序逐条消费commit log中的消息,当然我可以通过指定offset来重复消费某些消息,或者跳过某些消息。
这意味kafka中的consumer对集群的影响是非常小的,添加一个或者减少一个consumer,对于集群或者其他consumer来说,都是没有影响的,因此每个consumer维护各自的offset。
8.Distribution
log的partitions分布在kafka集群中不同的broker上,每个broker可以请求备份其他broker上partition上的数据。kafka集群支持配置一个partition备份的数量。
针对每个partition,都有一个broker起到“leader”的作用,0个多个其他的broker作为“follwers”的作用。leader处理所有的针对这个partition的读写请求,而followers被动复制leader的结果。如果这个leader失效了,其中的一个follower将会自动的变成新的leader。每个broker都是自己所管理的partition的leader,同时又是其他broker所管理partitions的followers,kafka通过这种方式来达到负载均衡。
9.Producers
生产者将消息发送到topic中去,同时负责选择将message发送到topic的哪一个partition中。通过round-robin做简单的负载均衡。也可以根据消息中的某一个关键字来进行区分。通常第二种方式使用的更多。
10.Consumers
consumer实例可以运行在不同的进程上,也可以在不同的物理机器上。
如果所有的consumer都位于同一个consumer group 下,这就类似于传统的queue模式,并在众多的consumer instance之间进行负载均衡。
10.1 consumer group概念
Kafka基于这2种模式提供了一种consumer的抽象概念:consumer group。
每个consumer都要标记自己属于哪一个consumer group。
如果所有的consumer都有着自己唯一的consumer group,这就类似于传统的publish-subscribe模型。
10.2 队列(queuing)模式
在queuing模式中,多个consumer从服务器中读取数据,消息只会到达一个consumer。
10.3 发布订阅(publish-subscribe)模式
在 publish-subscribe模型中,消息会被广播给所有的consumer。
通常一个topic会有几个consumer group,每个consumer group都是一个逻辑上的订阅者(logical subscriber)。每个consumer group由多个consumer instance组成,从而达到可扩展和容灾的功能。这并没有什么特殊的地方,仅仅是将publish-subscribe模型中的运行在单个进程上的consumers中的consumer替换成一个consumer group。如下图所示
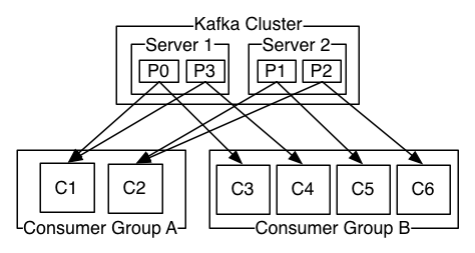
说明:由2个broker组成的kafka集群,总共有4个Parition(P0-P3)。这个集群由2个Consumer Group, A有2个 consumer instances ,而B有四个
三.Kafka的消费顺序
Kafka比传统的消息系统有着更强的顺序保证。
在传统的情况下,服务器按照顺序保留消息到队列,如果有多个consumer来消费队列中的消息,服务器 会接受消息的顺序向外提供消息。但是,尽管服务器是按照顺序提供消息,但是消息传递到每一个consumer是异步的,这可能会导致先消费的consumer获取到消息时间可能比后消费的consumer获取到消息的时间长,导致不能保证顺序性。这表明,当进行并行的消费的时候,消息在多个 consumer之间可能会失去顺序性。
消息系统通常会采取一种“exclusive consumer”的概念,来确保同一时间内只有一个consumer能够从队列中进行消费,但是这实际上意味着在消息处理的过程中是不支持并行的。
Kafka partition保证局部顺序
Kafka比传统方式做得更好:通过Topic中并行度的概念,即partition,Kafka可以同时提供顺序性保证和多个consumer同时消费时的负载均衡。
实现的原理是通过将一个topic中的partition分配给一个consumer group中的不同consumer instance。通过这种方式,我们可以保证一个partition在同一个时刻只有一个consumer instance在消息,从而保证顺序。虽然一个topic中有多个partition,但是一个consumer group中同时也有多个consumer instance,通过合理的分配依然能够保证负载均衡。需要注意的是,一个consumer group中的consumer instance的数量不能比一个Topic中的partition的数量多。
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性。通常来说,这已经可以满足大部分应用的需求。但是,如果的确有在总体上保证消费的顺序的需求的话,那么我们可以通过将topic的partition数量设置为1,将consumer group中的consumer instance数量也设置为1.
kafka基础知识梳理的更多相关文章
- kafka 基础知识梳理及集群环境部署记录
一.kafka基础介绍 Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特 ...
- kafka 基础知识梳理-kafka是一种高吞吐量的分布式发布订阅消息系统
一.kafka 简介 今社会各种应用系统诸如商业.社交.搜索.浏览等像信息工厂一样不断的生产出各种信息,在大数据时代,我们面临如下几个挑战: 如何收集这些巨大的信息 如何分析它 如何及时做到如上两点 ...
- kafka 基础知识梳理
一.kafka 简介 kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据.这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因 ...
- kafka 基础知识梳理(转载)
一.kafka 简介 kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据.这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因 ...
- [SQL] SQL 基础知识梳理(一)- 数据库与 SQL
SQL 基础知识梳理(一)- 数据库与 SQL [博主]反骨仔 [原文地址]http://www.cnblogs.com/liqingwen/p/5902856.html 目录 What's 数据库 ...
- [SQL] SQL 基础知识梳理(二) - 查询基础
SQL 基础知识梳理(二) - 查询基础 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5904824.html 序 这是<SQL 基础知识梳理( ...
- [SQL] SQL 基础知识梳理(三) - 聚合和排序
SQL 基础知识梳理(三) - 聚合和排序 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5926689.html 序 这是<SQL 基础知识梳理 ...
- [SQL] SQL 基础知识梳理(四) - 数据更新
SQL 基础知识梳理(四) - 数据更新 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5929786.html 序 这是<SQL 基础知识梳理( ...
- [SQL] SQL 基础知识梳理(五) - 复杂查询
SQL 基础知识梳理(五) - 复杂查询 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5939796.html 序 这是<SQL 基础知识梳理( ...
随机推荐
- ConcurrentHashMap源码解读三
今天首先讲解helpTransfer方法 final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) ...
- 有趣的css—简单的下雨效果
简单的下雨效果 前言 最近在b站上看到一个下雨效果的视频,感觉思路很清奇,我也按照自己的思路做了一个简单的下雨效果. 由于我制作GIF图片的工具最多只支持制作33FPS的GIF图,所以看起来可能有一点 ...
- CSS中margin负值巧布局
margin负值实现细边框 我们先准备五个div盒子,并设置好浮动和2px的实线黑色边框,看看效果 中间的边框线挨在了一起致使边框变粗成了4px,这时使用margin负值就可以解决这个问题 <s ...
- CRM数据分析的重要作用
优秀的管理者都知道企业想要实现业务大幅增长不是一件容易的事情.这往往需要通过明智的决策和正确的时机才能够实现.所以,您需要有洞察正确的时间和制定正确决策的能力,这样才能确保您做出正确的决定. CRM系 ...
- JAVA基础——运算符号
运算符(java) 算数运算符:+,-,*,/,%(取余),++,-- 赋值运算符:= 关系运算符:<, >, >= ,<= ,== , != 逻辑运算符:&& ...
- [bug] Nginx:src/os/unix/ngx_user.c:36:7: 错误:‘struct crypt_data’没有名为‘current_salt’的成员
参考 https://blog.csdn.net/yu_pan_love_cat/article/details/103035513 https://www.cnblogs.com/hxlinux/p ...
- [java] 转型
A为父类,子类B.C 第20行发生向上转型,a对象调用C覆写过的print()方法 若为A a = new B(); 则调用B覆写过的print()方法 创建对象时使用向上转型,能够统一参数类型(23 ...
- 删除所有空白列 cat yum.log | awk '{$1=$2=$3=$4=null;print $0}'>>yum.log1 sed ‘s/[ \t]*$//g' 删除所有空格 sed -i s/[[:space:]]//g yum.log
2.删除行末空格 代码如下: 删除所有空白列 cat yum.log | awk '{$1=$2=$3=$4=null;print $0}'>>yum.log1 sed 's/[ \t]* ...
- mysql基础之帮助信息
在mysql中获取帮助 1.当连接到mysql数据库以后,使用help命令或者\?表示获取帮助信息: MariaDB [ren]> help General information about ...
- rm删除破折号开头的文件或目录
转载地址:http://blog.chinaunix.net/uid-25266990-id-3458755.html rm删除(清除)一个或多个文件 -f 选项将强制删除文件,即使这个文件是只读的. ...