Scrapy入门到放弃06:Spider中间件
前言
写一写Spider中间件吧,都凌晨了,一点都不想写,主要是也没啥用...哦不,是平时用得少。因为工作上的事情,已经拖更好久了,这次就趁着半夜写一篇。
Scrapy-deltafetch插件是在Spider中间件实现的去重逻辑,开发过程中个人用的还是比较少一些的。
作用
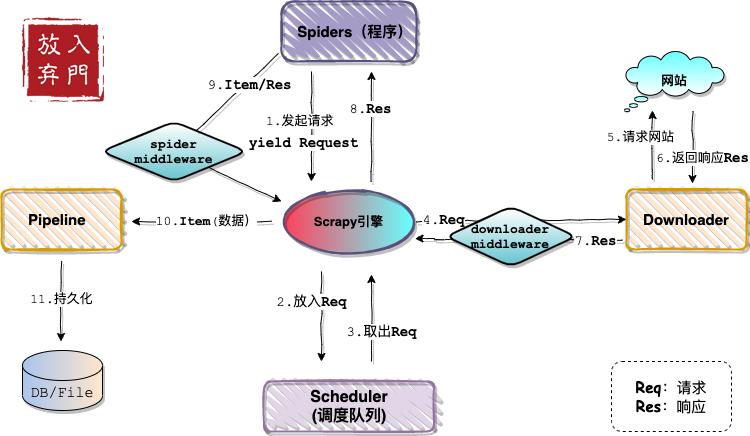
依旧是那张熟悉的架构图,不出意外,这张图是最后一次出现在Scrapy系列文章中了。
如架构图所示,Spider中间件位于Spiders(程序)和engine之间,在Item即将拥抱Pipeline之前,对Item和Response进行处理。官方定义如下:
Spider中间件是介入Scrapy的spider处理机制的钩子框架,可以添加代码来处理发送给 Spiders 的response及spider产生的item和request。
Spider中间件
当我们启动爬虫程序的时候,Scrapy自动帮我们激活启用一些内置的Spider中间件。
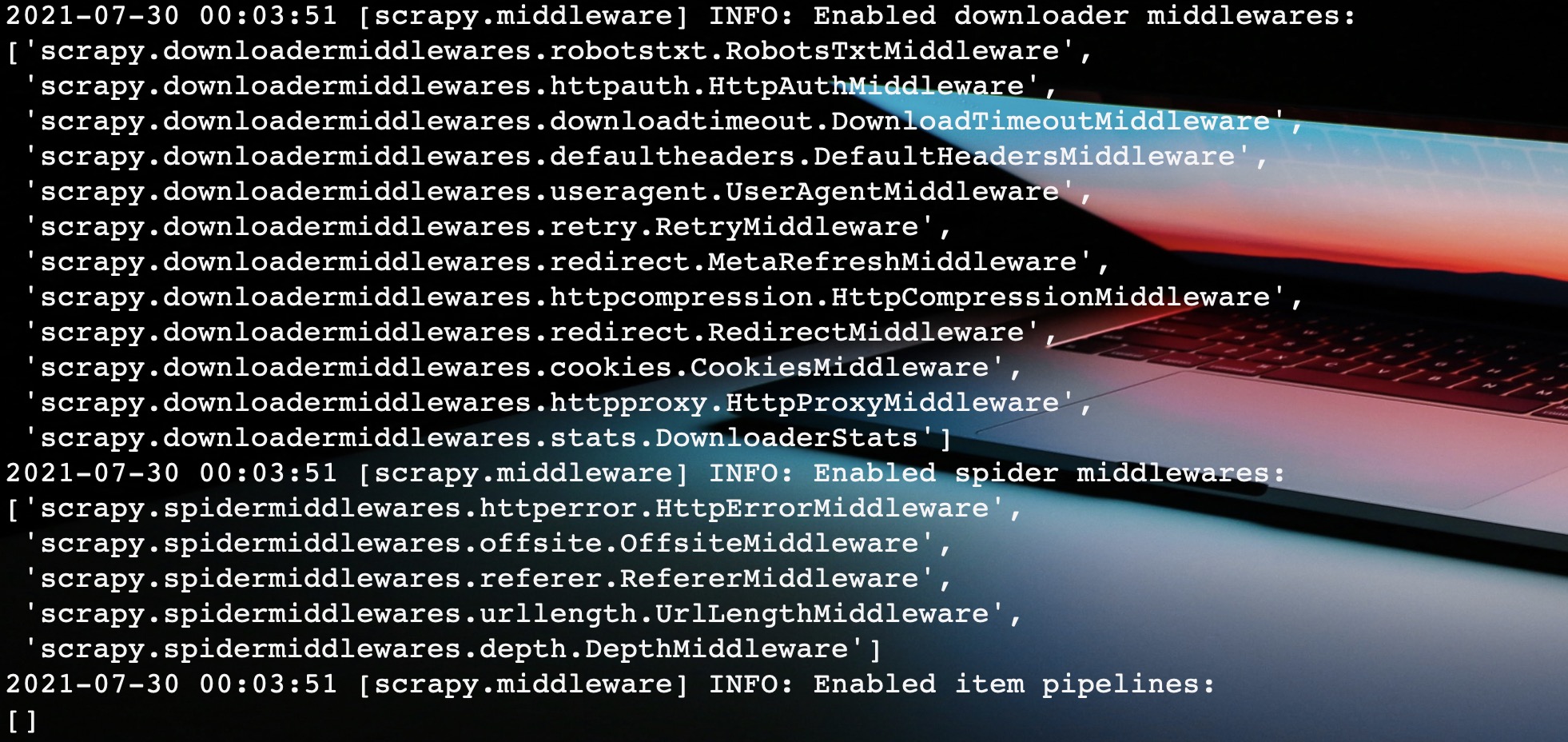
如图所示,这里帮我们启用了五个Spider中间件,这里我们依次分析一波。
内置Spider中间件
之前在下载器中间件也说了:大部分内置中间件是和settings中的配置配套使用的。Spider中间件也不例外。这里就想将
1. HttpErrorMiddleware
作用:默认过滤出所有失败,即响应值不在200-300之间)的response。
使用:方式很多,只讲两个,选一即可。
- 程序内属性定义
class MySpider(CrawlSpider):
handle_httpstatus_list = [404]
这个和custom_settings有异曲同工之妙,都是只在当前爬虫生效,但是这里作为属性出现的。
- settings.py全局定义
HTTPERROR_ALLOWED_CODES = [400, 404]
如果使用custom_settings定义此配置时,和方法1一样,都是在当前程序生效。话到此处,不妨看看HttpError中间件的源码是如何处理响应码的。
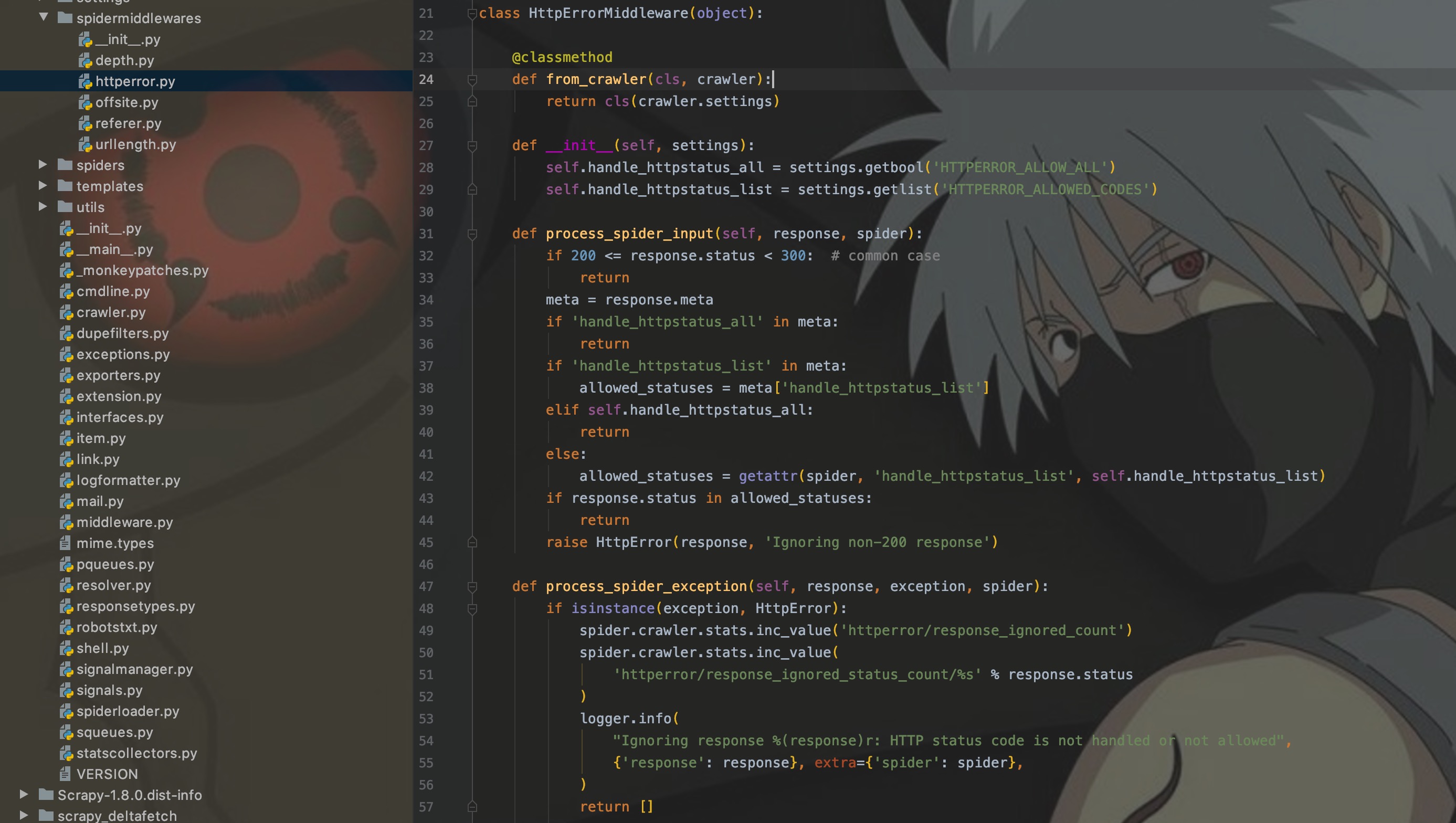
上图为HttpError中间件的源码,可以看出通过response的status来获取响应码,然后进行过滤判断,如果响应码在[200, 300)区间,则直接通过;否则就要查看配置,再次进行判断。
2. OffsiteMiddleware
该中间件过滤出所有主机名不在spider属性 allowed_domains 的request,request设置了 dont_filter,则就算不在也不过滤pider的 handle_httpstatus_list 属性或 HTTPERROR_ALLOWED_CODES 设置来指定spider能处理的response返回值
3. RefererMiddleware
根据生成Request的Response的URL来设置Request的Referer字段
4. UrlLengthMiddleware
过滤URLLENGTH_LIMIT - 允许爬取URL最长的长度
5. DepthMiddleware
用来限制爬取深度的最大深度或类似,
DEPTH_LIMIT - 爬取所允许的最大深度,如果为0,则没有限制。
DEPTH_STATS - 是否收集爬取状态。
DEPTH_PRIORITY - 是否根据其深度对requet安排优先级
自定义Spider中间件
Spider中间件也是在middlewares.py中进行定义,通过SPIDER_MIDDLEWARES进行激活启用配置。
这里我们先看看Scrapy给定的自定义模板是怎么样的。
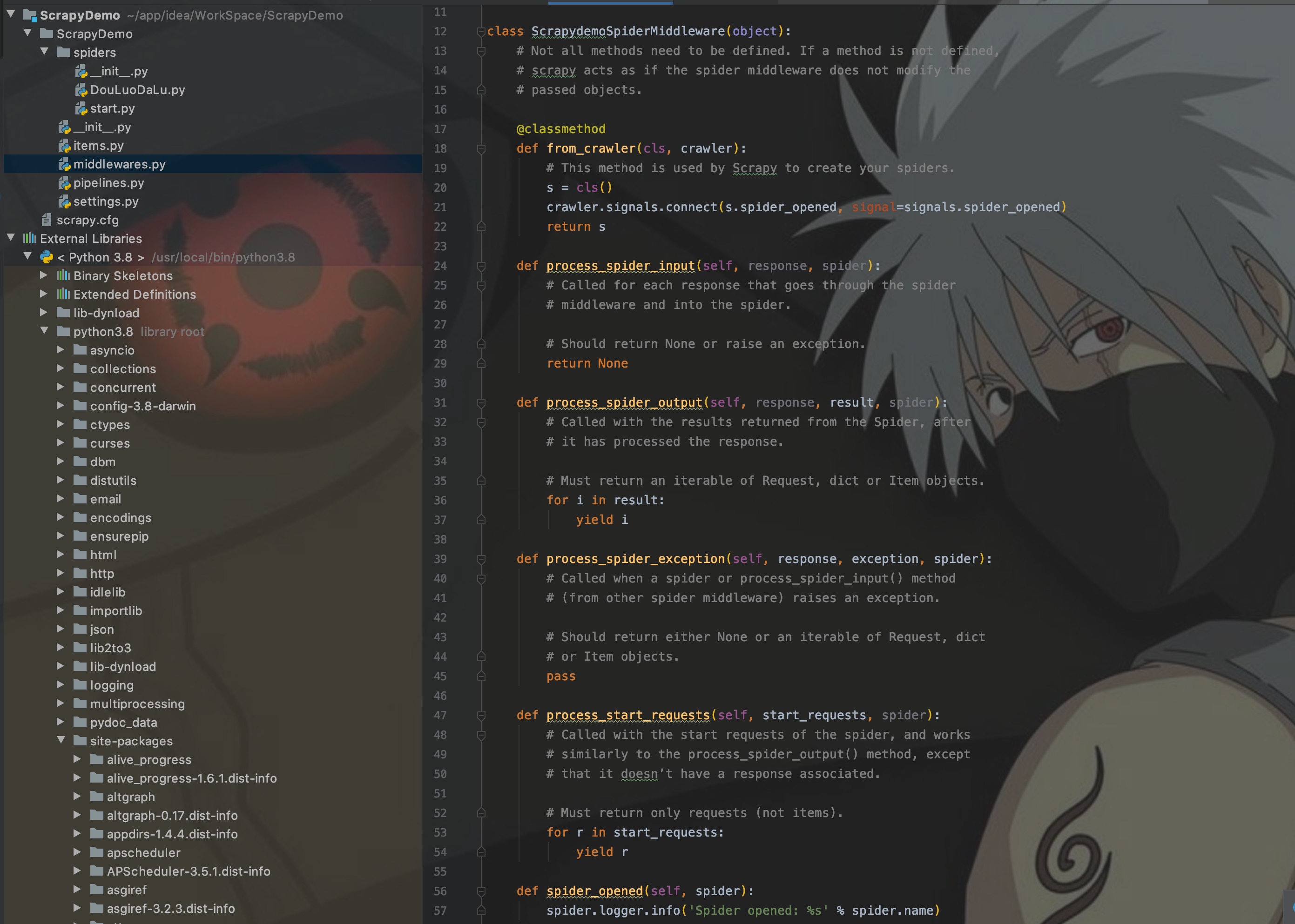
如图,主要需要实现以下几个方法:
- from_crawler:类方法,用于初始化中间件
- process_spider_input:当response通过spider中间件时,该方法被调用,处理该response
- process_spider_output:当Spider处理response返回result时,该方法被调用
- process_spider_exception:异常时, 该方法被调用
- process_start_requests:该方法以spider 启动的request为参数被调用,执行的过程类似于 process_spider_outpu ,只不过其没有相关联的response并且必须返回request(不是item)。
这里具体如何实现就不写了,参考上面HttpErrorMiddleware的代码实现即可。
区别
Spider中间件和下载器中间件有什么区别?
- Spider中间件可以获取到Item,即爬取数据的封装结构。
- Spider中间件是单向的,处理请求和响应。下载器中间件是双向的,第一次处理请求,第二次处理请求和响应。
- Spider中间件主要对请求后的响应结果进行处理;下载器中间件主要是对在请求前构造请求,例如添加请求头、代理IP等。
结语
这篇文章主要是作一个知识扩展,对于Spider中间件来说,了解并会使用内置中间件即可,至于自定义真的很少会用到。
写这种基础理论篇是最磨人性子的了,其实可能自己一看就懂,但是就是很难很好的讲出来。所幸的是,后面应该就快要到实操的环节了。期待下一次相遇。
95后小程序员,写的都是日常工作中的亲身实践,置身于初学者的角度从0写到1,详细且认真。文章会在公众号 [入门到放弃之路] 首发,期待你的关注。

Scrapy入门到放弃06:Spider中间件的更多相关文章
- Scrapy入门到放弃04:下载器中间件,让爬虫更完美
前言 MiddleWare,顾名思义,中间件.主要处理请求(例如添加代理IP.添加请求头等)和处理响应 本篇文章主要讲述下载器中间件的概念,以及如何使用中间件和自定义中间件. MiddleWare分类 ...
- scrapy入门到放弃02:整一张架构图,开发一个程序
前言 Scrapy开门篇写了一些纯理论知识,这第二篇就要直奔主题了.先来讲讲Scrapy的架构,并从零开始开发一个Scrapy爬虫程序. 本篇文章主要阐述Scrapy架构,理清开发流程,掌握基本操作. ...
- Scrapy入门到放弃03:理解settings配置,监控Scrapy引擎
前言 代码未动,配置先行.本篇文章主要讲述一下Scrapy中的配置文件settings.py的参数含义,以及如何去获取一个爬虫程序的运行性能指标. 这篇文章无聊的一匹,没有代码,都是配置化的东西,但是 ...
- Scrapy入门到放弃05:让Item在Pipeline中飞一会儿
前言 "又回到最初的起点,呆呆地站在镜子前". 本来这篇是打算写Spider中间件的,但是因为这一块涉及到Item,所以这篇文章先将Item讲完,顺便再讲讲Pipeline,然后再 ...
- Scrapy入门到放弃01:开启爬虫2.0时代
前言 Scrapy is coming!! 在写了七篇爬虫基础文章之后,终于写到心心念念的Scrapy了.Scrapy开启了爬虫2.0的时代,让爬虫以一种崭新的形式呈现在开发者面前. 在18年实习的时 ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫从入门到放弃(十七)之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
- Python爬虫从入门到放弃 之 Scrapy框架中Download Middleware用法
这篇文章中写了常用的下载中间件的用法和例子.Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以 ...
随机推荐
- 多项目如何高效协同合作 | springcloud系列之bus消息总线
前言 在springcloud config章节中我们完成了配种中心的搭建,以及通过配置中心完成配置的抽离通过springcloud config模块我们将配置抽离到git仓库中我们不必要每次为了改配 ...
- openlayer 4326与3857坐标互转之Java版
public class Transform { private static final double PI = Math.PI; private static final double merca ...
- break和continue关键字
什么是break break 跳出最里层的循环,并且继续执行该循环下面的语句 就是强制退出循环 示例 package struct; public class ForDemo05 { public s ...
- 模拟赛T2 交换 解题报告
模拟赛T2 交换 解题报告 题目大意: 给定一个序列和若干个区间,每次从区间中选择两个数修改使字典序最小. \(n,m\) 同阶 \(10^6\) 2.1 算法 1 按照题意模拟,枚举交换位置并比较. ...
- 不会SQL也能做数据分析?浅谈语义解析领域的机会与挑战
笔者按: 在第5次AI TIME PhD Debate上,笔者邀请了部分国内外语义解析领域的杰出华人学者共话语义解析的过去,现状和未来.本博客为笔者根据视频讨论总结的干货整理.对原视频感兴趣的同学可以 ...
- C#开发BIMFACE系列53 WinForm程序中使用CefSharp加载模型图纸1 简单应用
BIMFACE二次开发系列目录 [已更新最新开发文章,点击查看详细] 在我的博客<C#开发BIMFACE系列52 CS客户端集成BIMFACE应用的技术方案>中介绍了多种集成BIM ...
- HttpClient.PatchAsJsonAsync - dotnet/runtime 项目贡献小记
TL;DR 迫于 PatchAsJsonAsync 方法缺失,我给 dotnet/runtime 项目贡献了相关的 API,可惜要到 .NET7 才能用上. https://github.com/do ...
- ffmpeg剪视频
ffmpeg裁剪合并视频 ffmpeg提供简单的命令参数: ffmpeg -ss START -t DURATION -i INPUT -vcodec copy -acodec copy OUTP ...
- Java:volatile笔记
Java:volatile笔记 本笔记是根据bilibili上 尚硅谷 的课程 Java大厂面试题第二季 而做的笔记 1. volatile 和 JMM 内存模型的可见性 JUC 下的三个包 java ...
- 【二食堂】Beta - Scrum Meeting 4
Scrum Meeting 4 例会时间:5.17 18:30~18:50 进度情况 组员 当前进度 今日任务 李健 1. 继续完成文本区域划词添加的功能 issue 1. 划词功能已经实现,继续开发 ...